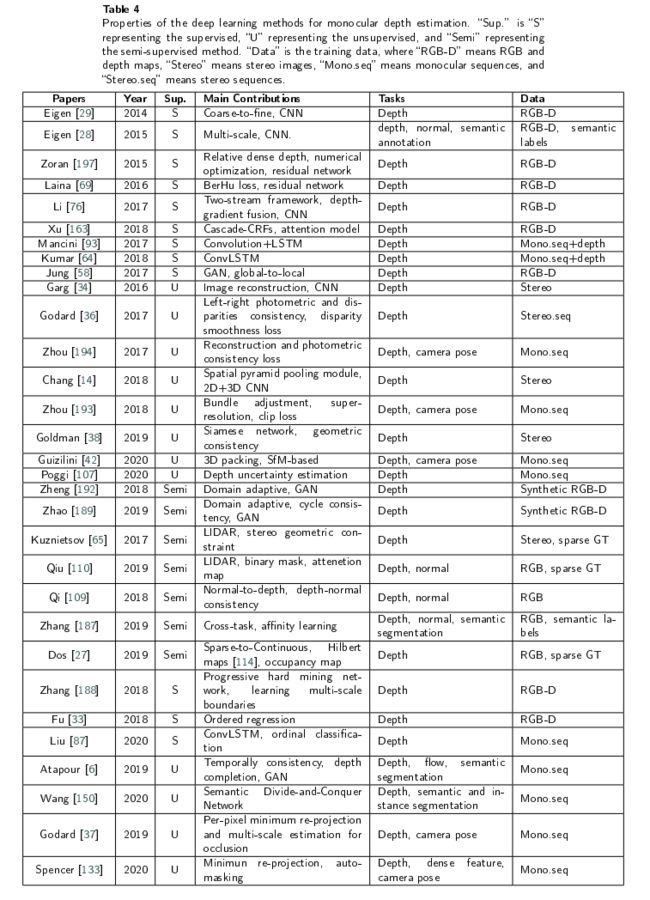
Deep Learning for Monocular Depth Estimation: A Review.基于深度学习的深度估计
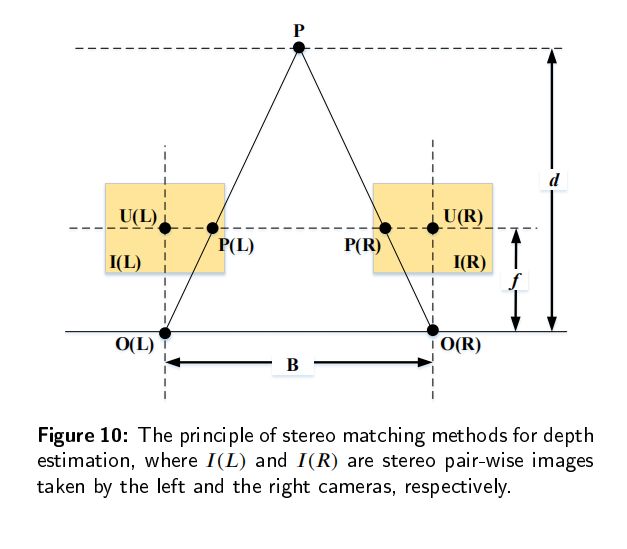
传统的深度估计方法通常是使用双目相机,计算两个2D图像的视差,然后通过立体匹配和三角剖分得到深度图。然而,双目深度估计方法至少需要两个固定的摄像机,当场景的纹理较少或者没有纹理的时候,很难从图像中捕捉足够的特征来匹配。所以最近单目深度估计发展的越来越快,但是由于单目图像缺乏可靠的立体视觉关系,因此在三维空间中回归深度本质上是一种不适定问题。
单目图像采用二维形式来重新反射三维世界,然而,有一维场景叫做深度丢失了,导致无法判断物体的大小和距离,也不能判断物体是否被其它物体遮挡,所以,我们需要恢复单目图像的深度。基于深度图,我们可以判断物体大小和距离,以满足场景理解的需要。当估计的深度图能够反应场景的三维结构的时候,我们认为深度估计是有效的。
深度估计的一些深度模型
CNN
可以自动提取场景中表示深度的空间特征。他是一种前馈神经网络,与传统方法相比,它以更少的参数同时提取深度并且重建深度图。CNN主要有一个卷积层、池化层、全连接层和激活函数(通常是一个连续可微的非线性函数,以避免纯线性组合),用来使CNN可以学习输入图像的两维空间特征。CNN比较有代表性的网络有AlexNet, VGG, GoogLeNet,ResNet, DenseNet , and some lightweight network,such as MobileNet ,ShuffleNet ,and GhostNet通常用作CNN的骨干网络。
RNN
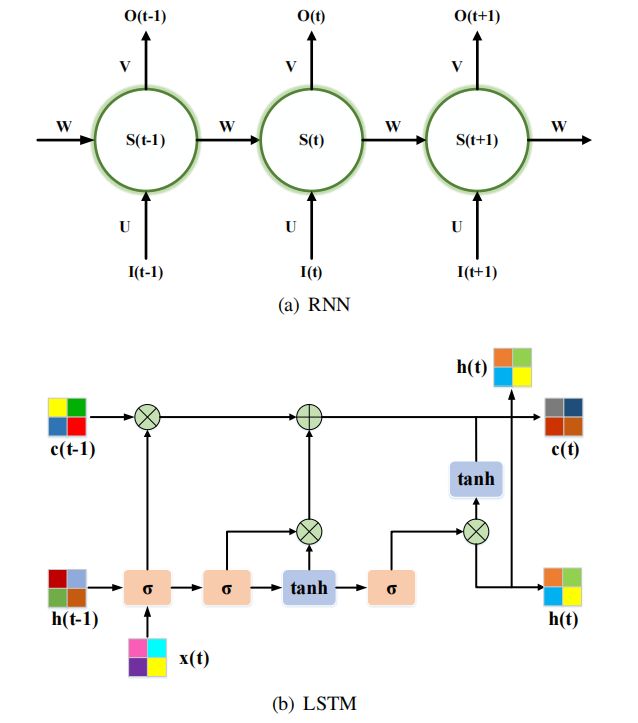
RNN是一个具有记忆能力的序列到序列模型,并将其引入单目深度估计中,从视频序列中学习时间特征。RNN是由三个单元组成的:输入层、隐藏层、输出层。隐藏层的输入是由当前输入单元和之前隐藏单元的输出组成。此外,有一个长短期记忆LSTM单元,可以通过三门结构学习长期依赖关系:输入门层、遗忘门层和输出门层。代表的RNN网络有BIRNN,GRU,ConvLSTM,ON-LSTM,Mogrifier LSTM 。通常与CNN结合来提取时空特征恢复深度。
GAN
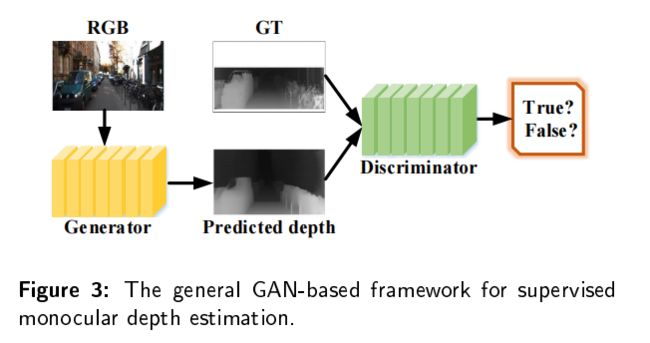
有监督的深度估计需要从地面真实值深度图中学习三维映射和尺度信息。但是要在真实场景中或者groundtruth图比较困难,所以研究人员引入了GAN来生成更加清晰、更加真实的深度图。GAN包括两个模块:生成器将深度图预测为一个深度估计网络;鉴别器确定输入的深度图是真的还是假的。比较有名的模型包括:conditional GAN,DCGAN,WGAN,stacked GAN,SimGAN,Cycle GAN。GAN可以为估计的深度图和真实深度图提供生成对抗性约束。
深度估计的方法
第一篇文章是Depth map prediction from a single image using a multi-scale deep network,他有两个CNN,一个提取粗糙的全局深度,一个是学习局部特征来细化深度图,是一个有粗到戏的框架。
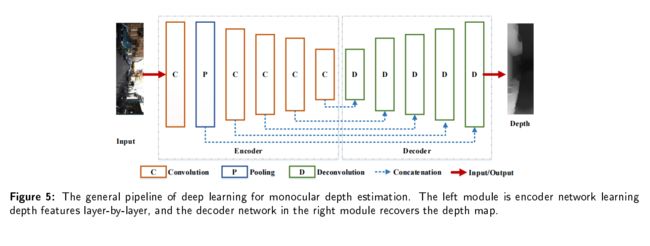
深度估计主要的流程
基于深度学习的单目深度估计是一个编码-解码工作,输入RGB图像,然后输出深度图。编码器由卷积层和池化层来捕获深度特征,解码器包括反卷积层用来回归估计的像素级深度,与输入大小相同,此外,为了保持每个尺度的特征,将编码器和解码器与跳跃连接连起来,整个网络受到深度损失函数的约束和训练,并在生成所需的深度图时收敛。
- 深度估计的训练
基于深度学习的深度估计通常使用梯度下降来训练深度神经网络,然后得到一个局部最小值。最佳的局部最小值取决于初始化和特定的参数设置。在初始化阶段,通常需要调整图像大小来满足网络学习的需要,此外,还需要设置初始学习速率、优化器参数、batch大小和minibatch大小来学习和保存图像特征。常用 的学习方法是随机梯度下降,优化器是Adam,当梯度不再改变的时候,损失函数变得稳定的时候,网络收敛。
与传统方法的比较
基于深度学习的方法构建了多层神经网络来学习深度特征,具有更高的精度,更加强壮的鲁棒性。
1、当单目图像中存在较小的遮挡或者部分地面真实值深度缺失的时候,深度学习的方法仍然可以估计场景的深度;
2、当场景中有大的遮挡物或者没有地面真实深度值的时候,深度学习可以通过添加网络条件约束来学习场景。
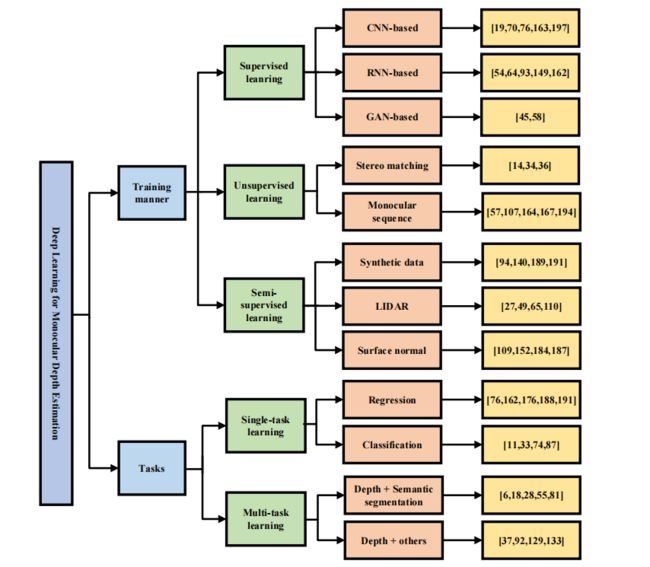
训练方式
有监督的单目深度估计是通过地面真实值的信息来学习场景结构的,这样成本太高了,所以就会使用一些半监督或者无监督学习。
有监督学习
有监督学习就是使用真实地面的深度图来进行训练,如下图所示。学习的目的就是通过损失函数来约束预测的深度图和真实地面深度图之间的误差。
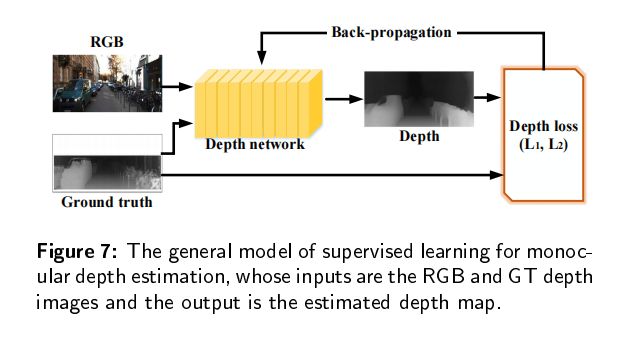
损失函数如下:

CNN-based
通过卷积核逐层学习深度特征并且通过反卷积恢复深度图来达到场景理解的要求。又本节又可以将深度估计分为相对深度估计和绝对深度估计。绝对深度学习一般都有更高的准确性;相对深度学习一般都有更强壮的鲁棒性,不受数据同质性的影响。
一方面,通过设计更深、更复杂的网络来学习和拟合深度特征来重建场景深度图;另一方面,与CRF结合,对深度网络的预测进行分析和优化,得到精细的深度图。如何重建新的网络以适应单目深度估计是一个重要的研究方向。
绝对深度学习
A two-streamed network for estimating fine-scaled depth maps from single rgb images提出一种基于VGG16网络的双链框架:一个用于深度回归,另一个用于深度梯度,通过深度梯度融合模块组合来获得相关的深度图。整个模型受到深度损失和梯度损失的约束,增强每个stream之间的泛化能力,以获得更加丰富的三维投影。除此之外还有很多方法基于更加复杂的CNN来学习像素级的深度比如VGG-based models,ResNet-based models,DenseNet-based models。
相对深度学习
Learning ordinal relationships for mid-level vision提出了一种采用图像中点对之间的关系来推断深度信息。他们输出了点对之间的相对关系,并且利用数值优化的方法来获得密集深度图。
Single-image depth perception in the wild提出了一种通过学习相对深度来预测像素级深度的多尺度网络。利用相对深度损失对网络进行训练,并且在没有约束的环境下对单目深度图像进行恢复,均方根误差与绝对深度估计模型相比为1.10.
Monocular depth estimation using relative depth maps设计了一个CNN来估计不同尺度下的相对深度,经过最优重组来重建最终深度图。他们的RMSE均方根误差优于上述大多数绝对深度方法。
与条件随机场结合
条件随机场是在给定输入序列下的条件概率分布模型。CRF可以在输入和输出之间建立一个结构化连接,关键是构建一个合理的、正确的深度估计特征。为了提高连续深度,首先构建具有固定和共享权值的深度估计网络来学习不同的patch,然后,这些估计被传播到CRF模块来获得最终的深度。

Structured attention guided convolutional neural fields for monocular depth estimation提出了一种通过综合注意力机制来学习自动学习鲁棒多尺特征的注意模型,与基于ResNet50的基线相比,级联CRF模块将RMSE降低为0.088.
Monocular depth estimation using multi-scale continuous crfs as sequential deep networks提出了两种单目深度估计模型,一种基于多个CRF级联,另一种基于同义的图模型。多尺度特征通过CRF继承、多层级联进行合并。
RNN-based
这种方法从单目图像序列中获取空间特征和时间信息。与CNN不同的是,这种方法使用LSTM或者ConvLSTM层,或者由卷积和LSTM(ConvLSTM)层组成,来提取和保留时空特征。

Depthnet: A recurrent neural network architecture for monocular depth prediction提出了带有ConvLSTM层的深度网络来预测单目深度图,并且隐式学习了平滑的时间变化。编码器由8个ConvLSTM层组成,使得网络充分利用序列中的时间信息,卷积有助于维持单元之间的空间几何关系。
Toward domain independence for learningbased monocular depth estimation采用LSTM单元来利用输入流序列行,预测场景深度,编码器中,LSTM层跟在卷积层后面。
GAN-based

基于GAN的神经网络可以生成接近地面真实值的深度图。
Depth prediction from a single image with conditional adversarial networks在单目深度估计中引入了GAN,生成器是由一个全局网络提取全局特征和一个从输入图像中中估计局部结构的细化网络组成的。整个模型在估计的深度图和真实地面深度图上建立一个对抗性损失进行训练:

总结
CNN学习空间特性、RNN从视频序列中学习时间特性,GAN生成并且区分深度图。监督学习的精确率比较高,可以很有效的得出3D场景图,但是GT深度图不好获取。因此基于虚拟图像的深度估计方法吸引了很多研究人员,也出现许多无监督学习的方法。
无监督学习
无监督学习的单目深度估计通常使用立体图对成对的图像或者单目图像序列进行训练,对单目图像或者视频序列进行测试,这是用场景集合约束训练的。立体匹配的几何约束建立在左右图像上,单目序列的几何约束建立在相邻的帧上。
立体匹配
无监督学习方法的灵感来自于传统的立体匹配方法:使用左图像和右图像来计算深度
通过立体成对的图像来对模型进行训练,然后在单张图像上测试。深度网络估计左右图像之间的视差图,基于视差图和右图像可以通过图像扭曲构造新图像。
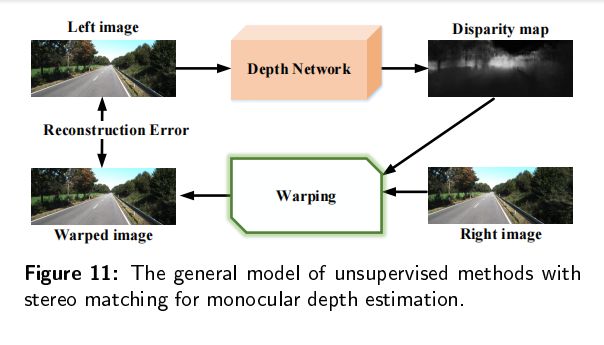
像素可以通过这种方法获取:

K是相机内部矩阵, T ( t − > s ) T(t->s) T(t−>s)是左右图像之间的转换, D ( t ) D(t) D(t)是深度估计图, p ( t ) p(t) p(t)是重建的图像中的一个其次坐标。
因此,深度网络受到源和重建图像之间的差异也就是重建误差的限制。常见的损失函数如下, I ( p ) I(p) I(p), I ω ( p ) I^\omega(p) Iω(p)分别表示原图像和从原图像重建的扭曲图像, α \alpha α是一个调整基于L1和SSIM误差的权重。

基于立体匹配的无监督学习方法通常采用CNN进行单目深度估计。
Unsupervised cnn for single view depth estimation: Geometry to the rescue采用下图的模型,通过在L1标准中重建loss的一种无监督学习方法来学习深度特征图。在这个基础上,很多研究人员开始利用左右试图来训练基于二维或者三维CNN的立体匹配网络。
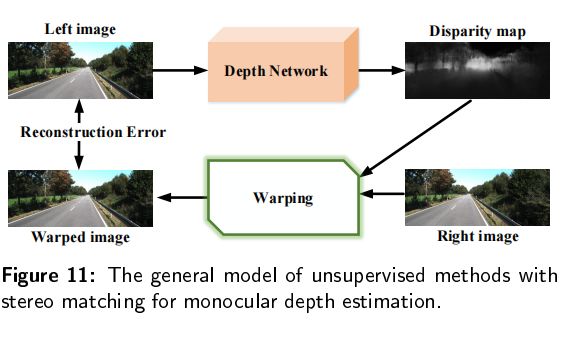
2D CNNs
Unsupervised monocular depth estimation with left-right consistency提出了左右一致性约束来训练无监督网络,同时重建左右视图。他们的模型是受到重建loss、视察平滑度loss和左右视差一致性的约束。实验证明,添加新的损失函数可以提高每个视图的的深度预测图的精度。
Xie等人在图像重构中添加了一个选择层,Wong等人设计了一个从全局到局部的网络用于特征提取,Goldman等人构建了一个孪生神经网络来学习立体图像,Andraghrtti等人利用传统的视觉测程法增强了深度估计。Waston等人通过深度提示增强了立体匹配,Ur等人应用了无监督的预训练滤波器的方法。
3D CNNs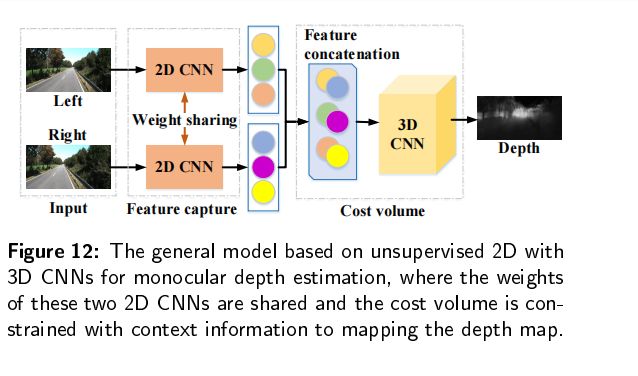
采用上下文信息在三维卷积块中约束无监督网络。训练过程中,两个具有共享权重的二维CNN分别从左右图像中学习特征图,然后,将这两组特征图连接到一个匹配代价模块中,结合上下文信息来估计最终的深度图。Chang等人提出了PSMNet,训练自上而下/自下而上的方法来执行无监督单目深度估计,空间金字塔池模块作为一个匹配代价,通过聚合半全局环境信息,和一个3D卷积模块调整匹配代价,通过结合多个堆叠的中间监督的基于沙漏网络的3D CNN。
基于立体匹配的无监督学习模型主要受到左右成对图像之间投影和映射关系的约束,仍然需要包含立体图像的数据集。因此,如何在训练的时候只用到单台摄像机,引起了研究者的关注。
单目序列
用单目序列训练的无监督学习模型同时考虑场景结构和相机运动,其中摄像机姿态估计与图像变换估计相似并且对于单目深度估计有积极作用。近年来,研究人员将视觉测程法引入到基于单目序列的深度估计中,可以通过预测摄像机的运动来学习场景深度。

基于单目序列的无监督深度估计如上图,由两个子网络组成:深度网络用来深度估计,位姿网络用来测量视觉,在训练阶段,这两个网络被联合训练,与立体匹配方法相似,整个模型都受到图像重建损失的约束,不同的是单目序列中的图像扭曲是建立在单目序列的相邻帧上的。在单目序列的无监督方法中,除了重建损失外,还采用了立体视觉匹配方法中的平滑度损失和光度一致性损失。
Unsupervised learning of depth and ego-motion from video设计了两个网络来独立估计单目视频中的深度图和相机运动,可以与重建损失和光度一致性损失函数联合或者单独训练,并在一个图像或者单目序列上进行测试。为后续工作提供许多参考,比如用三维几何约束训练的模型,用不确定性或者置信图进行估计,用自注意设计的网络等。
半监督方法
为了利用成本低的数据又提升学习性能,研究人员提出了半监督学习方法,除了从RGB图像中学习深度特征以外,还依赖虚拟数据、稀疏深度和表面法线等辅助信息。半监督学习减少模型对于地面真实图的依赖,提高规模一致性和估计精度;不过仍然增加了输入数据的数量。
结合合成数据
由图形引擎生成的合成数据为收集大量的深度数据提供了一种可能的解决方案。因此,研究人员引入了一种有深度标签的合成数据集。如何解决合成数据和真实数据的域间隙是一个问题。
随着图像样式迁移个它的域自适应发展,研究人员采用样式迁移和对抗训练来在真实场景中估计深度,这依赖于用大量的合成数据进行训练的模型。深度估计网络使用合成图像和相应的真实地面深度图训练。在测试阶段,将训练之后的网络直接应用于真实的迁移学习预测的RGB图像的深度图,以最小化真实域和合成域之间的差距。

DispNetA large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation是第一个引入图像样式迁移到深度估计中的。他使用了一个综合合成数据来训练,并根据较少可用的真实地面数据对模型进行微调。基于这个模型,zheng等人提出了一个双模块自适应网络, T 2 N e t T^2Net T2Net,一个模块用合成图像和真实图像进行训练,用重建损失和生成对抗损失相互重建,并将这些输出输入到另一个模块来预测真实深度图。此外,还有更多的自注意力、循环一致性、跨域等域自适应模型来预测单目深度图。
与激光雷达数据结合
辅助深度传感器会产生一些噪声,测量的深度值通常比地面真实值图更加稀疏。深度网络学习的不仅仅是结构特征,还有来自激光雷达捕获的稀疏数据的深度和噪声,其中,整个模式需要添加建立在稀疏数据和估计的深度图上的深度一致性约束:


Semi-supervised deep learning for monocular depth map prediction提出一种使用稀疏数据的半监督深度估计网络,输入左右图像,然后建立一个立体对齐作为一个几何约束。因此,深度一致性损失包括两个部分:一格式左深度估计图和稀疏数据之间的误差,另一个是右深度估计图和稀疏数据之间的误差。实验证明,性能比监督估计和非监督估计都好。
表面法线结合
有一些特征可以与输入RGB图像中提取深度相似的信息,有助于更加准确方便地预测深度图。
表面发现由三维点的局部切平面决定,可以从深度中估计;深度受到局部切平面决定,这是由表面法线决定的。
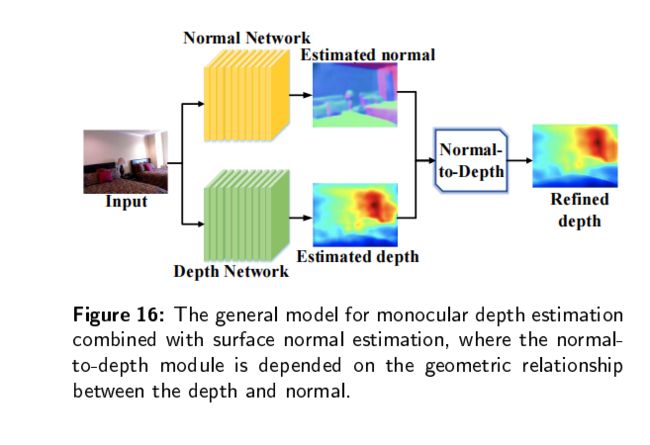
Geometric neural network for joint depth and surface normal estimation提出GeoNet,它包括一个深度到表面的网络,利用了从深度和表面到深度的网络的曲面法线的最小二乘解,在内核模块中细化初始深度的映射。他们利用“局部平面上表面法线变化较小”的理论来细化单目深度估计。此外,还有一些具有深度法线一致性,表面正则化约束,深度补全的模型,用于结合表面法态估计的单目深度估计。
总结
任务
从任务角度来看,单目深度估计可以分为两个类别:训练单一网络进行深度估计也就是单任务学习;和其他任务结合,进行特征投影,提高深度估计的性能,也就是多任务学习。
单任务
单任方法核心是构建RGB图像与深度图之间的关联模型,也就是从RGB图像中学习该模型,并恢复深度值。
根据网络返回的深度值是否连续,可以将单任务学习方法分为回归方法和分类。
回归
通常从输入中学习场景结构特征,并对连续深度值回归拟合输入。现有的MDE大多是回归,可以直接得到包含连续像素级深度值的深度图。回归方法模型大多数跟下图相似,深度值是连续的。也可以被分为CNN,RNN,GAN.

Progressive hard-mining network for monocular depth estimation提出一种端到端的渐进式难分样本挖掘网络来回归深度图。其中,一个尺度模块恢复深度信息,一个尺度间的模块融合深度线索,一个难分样本挖掘模块约束递归细化和减少误差传播,以充分学习不同尺度的边界,闭关在回归中估计深度图。
理想情况下,估计的深度值是连续的,然而,单目深度估计的回归方法通常面临着更加复杂的网络结构和约束函数,所以一些研究者开始研究离散深度值,并且引入分类方法来学习深度图。
分类

考虑场景从远到近的特征,使用分类来估计单目深度。首先,对连续的深度值离散化,然后深度估计网络学习离散深度值的分类标签,并对分割的深度图进行回归,最后这些分割的深度图合并生成最后的深度图。
主要使用的模型有全卷积模型,残差模型,顺序分类模型。
Deep ordinal regression network for monocular depth estimation提出一种深度有序分类网络来估计就深度图,他对在对数空间中的深度值进行采样,根据距离关系按照所有类别降序排列,离散深度值用于有序回归网络训练。
实验证明,将深度估计作为回归问题会导致离摄像机太远或者太近的的区域产生较大误差,分类问题可以有效避免在预测较大深度值时出现误差。回归的网络和约束函数越来越复杂就很容易产生局部最小值;分类对离散化形式和权值的设置有很强的依赖性,否则loss会增加。
多任务学习
将不同任务中提取的特征相互投影,以增强最终深度图。可以提升精度,增强对于场景的理解,但是也有一些挑战,比如带有语义标签或者缺失标签的有限数据集,由场景中的动态对象造成的运动模糊和遮挡。
语义分割
场景感知包括许多方面,深度信息描述空间几何关系,语义表示实体意义,这些任务共享类似的上下文信息。
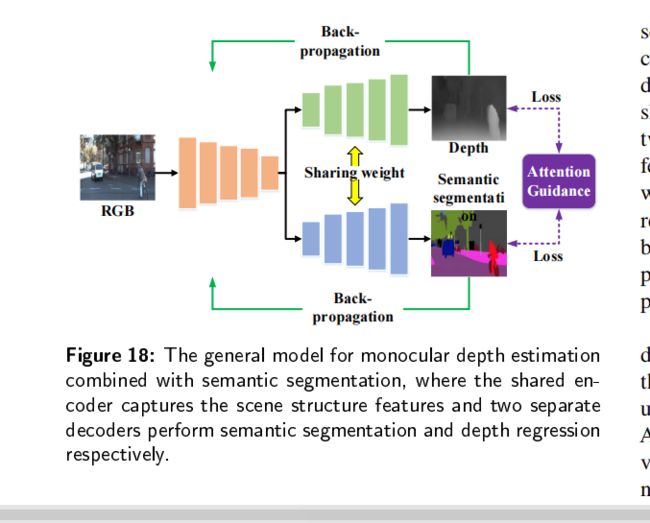
深度估计和语义分割的模型由一个编码网络和两个解码网络组成,这两个网络使用共享权重。在训练的过程中,我们可以同时训练一个或者两个任务。共享的编码曾从输入学习特征图,两个解码层恢复深度图和语义分割。此外,整个模型受到来自上下文信息注意引导的约束,预测的结果进行反向传播,更新网络参数和优化结果。
Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture首先统一了深度、表面法线和语义注释三个任务。Atapour Abarghouei等人将深度估计看作是一个利用生成网络监督图像到图像的转换问题,并应用对抗性学习使模型选择一种模式来克服导致输出模糊的多模态问题。对于语义分割,他们应用了一个交叉熵损失函数训练的完全监督生成网络。此外,还提出了基于自注意力,实例分割,多尺度学习,引导方式等模型估计单目深度估计组合语义分割。
深度估计与语义分割结合可以在上下文信息发挥优势,解决了一些边界模糊的问题,提高预测精度。
视觉测量和光流估计
视觉测程法类似于图像变换估计,精确的相机姿态估计有助于图像重建,进一步有助于深度估计。然而,大多数只是考虑静态场景。为了更好的估计动态场景的深度,研究人员引入一种光流估计。它可以捕捉场景中的动作信息,用于动态深度估计中。
在视觉测程和光流估计相结合的基础上,有大量处理场景中动态对象、遮挡、模糊的动作的工作。基于视觉测程法和光流估计的单目深度估计模型一般如下:通常是由多个子网络组成,不同的子网络有不同的任务,所有的任务联合训练每项任务的评估互相促进。
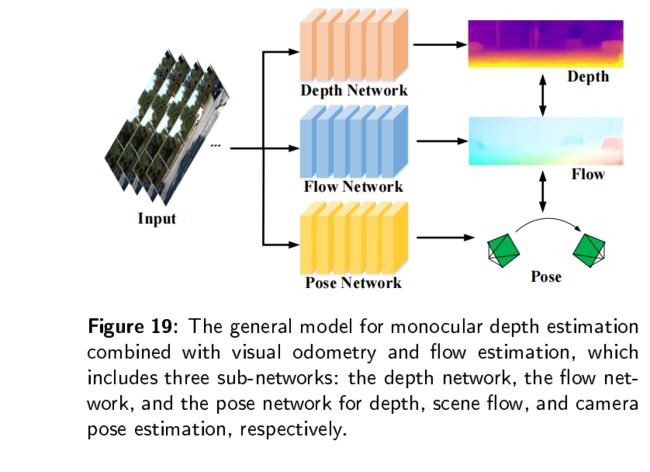
对于动态对象的遮挡,Digging into self-supervised monocular depth estimation提出一种自动闭塞法,减少光度误差从而减少物体边界的伪影,并且提高了遮挡边界的清晰度。同时,他们提出了一种自动掩码的方法来过滤一些“当动态物体以与场景中摄像机以相同速度移动时一些在外观上没有变化的像素”。
特征估计
General monocular depth via simultaneous unsupervised representation learning提出一种无监督学习框架,同时学习单目深度、密集的特征表征和自我运动。它是健壮的,可以使用已建立的像素级损失函数在很多挑战性的环境中工作,比如不断变化的天气和光照条件。
数据集
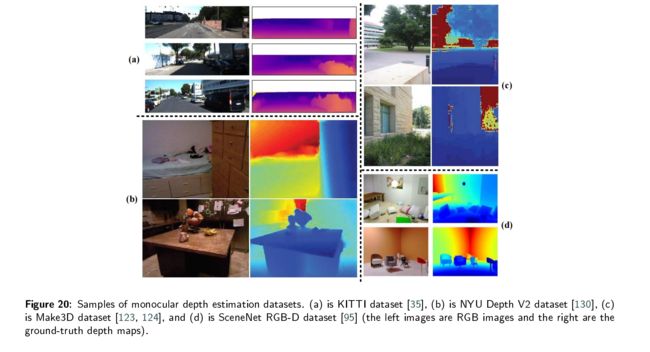
KITTI
是一个室外数据集。KITTI数据集通过一辆配备有2台高分辨率彩色相机、2台灰度相机、激光扫描仪和全球定位系统(GPS)的汽车捕获,其最大测量距离为120米。这个数据集包括93000个RGB-D训练样本:道路、城市、住宅、校园和行人。来自卡尔斯鲁厄市、野生地区和高速公路。KITTI原始图像大小为1242*375,它的真实值地面深度图是稀疏的。
kitti数据集中图像深度信息应该怎么得到,在哪一个文件分类里,是具体给出了数值还是需要另外计算?
NYU Depth V2
是一个室内环境数据集,包括407024帧的RGB-D图像对,同时手机464个不同室内场景的RGB和深度信息。NYU Depth V2原始图像大小为640*480,数据集的深度范围为0.5m~10m.由于RGB和深度摄像机之间的位置偏差,原始的深度图包含损失的部分或者噪声。因此,作者从数据集中选择1449张图像,使用着色算法填充并获得密集的深度图,并使用语义信息进行手工标记。1449个样本被分为795个训练样本和654个测试样本
Make3D
是一个户外数据。Make3D数据集包括白天的城市和自然风景,激光扫描仪收集的深度地图,深度范围为5m~81m,大于此范围的范围均匀映射为81 m。该数据集共包含534对RGB-D图像对,其中400对用于训练,134对用于测试。RGB图像的原始分辨率为2,272×1,704,深度图的分辨率为55×305像素。
Virtual Datasets
有一些由计算机生成的虚拟数据集,如SceneNet RGB-D数据集和SYNTHIA数据集。这些虚拟数据集包括在不同的天气、环境和光照条件下的各种场景类型。根据研究的具体任务选择合适的数据集。
评估指标
评估指标包括误差和准确性指标。误差指标包括相对误差,绝对误差,平方相对误差,均方根误差,对数均方根误差。准确率是越大越好包括 σ < 1.2 5 t , t = 1 , 2 , 3 \sigma<1.25^t,t=1,2,3 σ<1.25t,t=1,2,3。

- 分析与比较:

挑战与未来发展
挑战
1、深度网络层数增加,导致内存的使用和空间复杂性增加。
2、多任务学习中使用多个自网络或者子模块来处理不同的子任务,增加了计算量和内存消耗。
3、经过多层信息处理之后,深度特征严重丢失,导致估计深度图的精度较低,不能满足实际应用的要求。
未来发展
网络框架的集成与优化
在许多监督学习模型中,语义分割将添加上深度估计,但它仍然是一个处理独立任务的独立模块。在无监督学习方法中,通常有多个子网络能够分别学习深度估计、视觉测程法和流估计。然而,这些网络并没有很好的连接,这导致大量的参数增加了内存需求和计算。如何更好地整合该网络是一个研究方向,值得在未来进行探索。我们可以通过使用相同的深度学习网络同时获得不同的特征,如语义信息、光流特征和深度特征。在编码阶段,同时提取并匹配不同类型的特征;在解码阶段,分别解码以满足应用要求。
数据集建设
数据集的质量在很大程度上决定了深度学习模型的泛化能力和鲁棒性。为了提高深度估计的结果,需要更多的数据、更好的质量和更多的场景类型。然而,这些用于深度估计的现有数据集相对有限,并且构建一个新的数据集是耗时和昂贵的。目前,一些研究者利用计算机生成大量的图像进行深度估计,但质量不均匀。如何构建满足深度学习的单眼深度估计数据集是未来的研究方向。
动态对象和光遮挡问题
现实的场景通常是复杂的,如包含大量的移动物体,遮挡,照明变化,天气变化。然而,现有的深度估计模型大多只考虑了理想的条件。虽然近年来已有一些研究人员开始研究动态对象和遮挡场景,并取得了一些进展,但如何更好地估计复杂场景的深度以满足实际应用仍然是一项非常具有挑战性的任务,是未来的重要研究方向。
高分辨率的深度图输出
深度估计是增强现实(AR)和虚拟现实(VR)等实际应用的一个基本步骤,它对深度图的精度和分辨率有很高的要求。然而,为了提高计算效率,目前大多数深度估计模型所预测的深度的分辨率通常较低。目前,研究人员已经使用彩色图像超分辨率模型来细化深度地图的超分辨率。但如何直接输出高分辨率的深度图仍然是一个需要研究的方向。
实时表现
图像深度估计是SLAM的基本模块,它与自动驾驶等工业应用紧密集成。因此,实际应用对深度估计的实时性能有很高的要求。然而,为了获取提取精确度,研究者经常构建更深层次的网络,具有更多的参数和更多的约束条件,来进行深度估计,这需要更多的计算时间,因此不能满足实际应用的实时需求。因此,如何在保证预测精度的同时,应用较轻的网络进行实时估计是未来的研究方向。