【Nodejs 】Nodejs常见全局对象之模块对象全解析_02
目录
一、模块
二、模块分类
三、npm和包
四、查询字符串模块(querystring)
五、URL模块
六、Timer模块 定时器
1、一次定时器
2、周期性定时器
3、立即执行的定时器
七、文件系统模块(fs)
1、查看文件状态
2、读取目录
3、写入文件(覆盖写入)
4、写入文件(追加写入)
5、读取文件
6、删除文件
7、检测文件是否存在
8、拷贝文件
9、创建和移除目录
10、文件流
◼️同步和异步◼️
⬛http协议
1、通用的头信息
2、响应的头信息
3、响应主体
4、请求的头信息(Request Headers)
5、请求主体(Request Body)
八、http模块
【前文回顾】 Nodejs 概述及常见的全局对象_01

一、模块
模块是一个独立的功能体
一个模块(主模块)引入其它的模块(子模块),一个模块被其它的模块所引入。
在nodejs中一个js文件(包括目录)就是一个模块,一个模块本质是一个匿名函数
分为自定义模块(用户编写的模块)、核心模块(node提供的模块)、第三方模块
Nodejs自动给每个模块添加了一个函数,文件中的代码自动被函数所包含,里边的变量和函数都是局部的,所形成的作用域称为模块作用域
(function(){
文件中的代码
})
rquire:是一个函数(方法),用于引入其他模块
module:当前模块的对象
module.exports:当前模块的导出对象
__dirname:当前模块的绝对目录 注:dir→directory
__filename:当前模块的绝对目录和模块名称 注:下划线是2个
| module.exports 公开的内容,也就是导出的对象,引入该模块会得到这个对象 |
| require() 是一个函数,用于引入其它的模块(引入module.exports导出的对象) |
扩展:
1、module 当前的模块对象;module.exports 当前模块导出的对象,是直接导出整个对象,公开的内容,默认是一个空对象
2、如果引入一个模块,模块中定义var a = 1;在引入的页面中不能访问这个a,除非使用(global.a = 1 || module.exports)
3、node中有一个全局变量global,是node中最大的一个对象,相当于浏览器中的window对象,global中的成员在使用时,可以省略global4、nodejs中的模块系统,具有文件作用域,也具有通信规则(加载和导出规则),使用require方法加载模块,使用module.exports或是exports接口对象导出模块中的成员
练习:创建两个模块main.js(主模块)和circle.js(功能模块) ,在功能模块下创建两个函数,传递参数为半径,分别计算圆的周长和面积并返回结果;在主模块下引入功能模块,调用公开的两个函数。
circle.js
//计算周长
function getLength(r){
return 2*Math.PI*r;
}
//计算面积
function getArea(r){
return Math.PI*Math.pow(r,2);
}
//导出以上两个函数,外部才能使用
//往导出对象中添加要导出的函数
/*
module.exports={
getLength: getLength,
getArea: getArea
}
*/
let circle={
getLength: getLength,
getArea: getArea,
a:1,
b:2
}
//如果已经有一个对象,把它导出,直接赋给module.exports
module.exports=circle;main.js
//引入circle.js模块
let obj=require('./circle.js');
//console.log(obj);
//console.log( obj.getLength(5).toFixed(2) );
//console.log( obj.getArea(5).toFixed(2) );
//绝对目录
console.log(__dirname);//dir->directory 目录
//绝对目录+模块名称
console.log(__filename);//file 文件
运行结果:

二、模块分类
| 以路径开头 |
不以路径开头 |
|
| 文件模块 |
require('./circle.js') |
require('url') |
| 目录模块 |
require('./02_dong') |
require('ran') |
论述:如果执行require('mysql'),是如何引入模块的
会到当前目录下的node_modules中,寻找mysql目录,如果找不到,会一直往上一级目录下的node_modules中寻找mysql目录;找到后,接着到mysql目录下去寻找package.json中main对应的文件,如果找不到会自动去寻找index.js
扩展:关于路径的辨识问题
1、a/ 表示下一级或是兄级目录兄弟是个文件夹
2、./ 表示当前目录、同级目录
兄弟是个文件
3、../ 表示上一级或是父级目录 ../../ 表示上上级
兄弟在父亲文件夹里
4、/ 表示文件所属磁盘的根目录
练习1:以路径开头的目录模块的引入示例(找寻package.json中main指定的文件)
02_ran.js模块中,引入02_dong目录模块,目录中含有文件index.js、package.json、web.js
*02_ran.js
//引入同一级目录下的02_dong目录
require('./02_dong');*package.json
{
"main":"web.js"
}*web.js
console.log('这是web.js文件');练习2:不以路径开头的第三方目录模块的引入示例
04目录中含有04_1.js文件以及node_modules目录,node_modules目录中含有ran目录模块,ran目录中含有文件index.js,要求:在04_1.js模块中,引入然目录模块
*04_1.js
require('ran');*index.js
console.log('这是然哥模块');练习3:以路径开头的目录模块的引入示例(package.json中main未指定文件,自动找寻index.js)
03_1.js模块中,引入03_2目录模块,目录中含有文件index.js,导出一个函数,计算任意两个数字相加的和,并返回结果。最后03_1.js引入成功后调用该函数
*03_1.js
//引入同一级目录下的03_2目录模块
let obj=require('./03_2');
console.log(obj); // { add: [Function: add] }
//调用导出的函数
console.log( obj.add(2,3) ); // 5*index.js
//计算任意两个数字相加的和,返回结果
function add(a,b){
return a+b;
}
//导出函数
module.exports={
add:add
}三、npm和包
包(package):是第三方模块
npm:是用来管理包的工具,包含下载安装、更新、卸载、上传...
npm在安装nodejs的时候会附带的安装
npm -v 查看版本号
下载包时如何切换到要下载的目录,如下2种方法
(1) 切换命令行目录(2种方法)
①cd 目录的路径 回车
盘符名称:+回车 例如d: +回车 如果涉及到盘符变化需要运行这一步
②在要进入的目录下空白区域,按住shift,单击鼠标右键,选择‘在此处打开powershell窗口’(win10系统),win7系统下为‘在此处打开命令窗口’
如果运行文件,可以拖拽或是手动输入部分文件名,按table键即可自动寻找补全文件名
(2) npm 下载安装
官网:www.npmjs.com
npm install 包的名称 回车 如:npm install mysql
会将下载的包放入到node_modules中,如果node_modules 目录不存在会自动创建,同时会生成文件package-lock.json,用于记录包的版本号
nodejs中的全局对象以及系统模块
nodejs自带的全局模块(系统模块也称核心模块),无需单独下载,直接require('fs')引入即可
比如:querystring、url、Timer模块、fs、path、http、os等模块
四、查询字符串模块(querystring)
查询字符串:浏览器向服务器发请求,传递数据的一种方式。位于网址(URL)中
http://jd.com/search?kw=dell&enc=utf-8
查询字符串模块是用来操作查询字符串的工具
parse() 将查询字符串解析为对象,可以获取传递的数据了
//引入查询字符串模块
const querystring=require('querystring');
//console.log(querystring);
//查询字符串
let str='kw=dell&enc=utf-8';
//将查询字符串解析为对象
let obj=querystring.parse(str);
console.log( obj.kw,obj.enc ); // dell utf-8练习:获取以下查询字符串中的数据
lid=5&price=8000&count=10
//引入查询字符串模块
const querystring=require('querystring');
//console.log(querystring);
let str2='lid=5&price=8000&count=10';
//把查询字符串解析为对象
let obj2=querystring.parse(str2);
console.log(obj2); // { lid: '5', price: '8000', count: '10' }五、URL模块
URL:互联网上的资源都有对应的网址,这个网址就称为URL
http://www.codeboy.com:999/products.html?kw=dell
协议 域名或IP地址 端口 文件路径 查询字符串
URL模块用于操作URL
parse() 将URl解析为对象,获取各个部分 query:查询字符串部分(url中?后面的部分)
//引入URL模块
const url=require('url');
//引入查询字符串模块
const querystring=require('querystring');
let str='http://www.codeboy.com:9999/products.html?kw=dell';
//将URL解析为对象
let obj=url.parse(str);
console.log(obj.query, obj.pathname); // kw=dell /products.html
//console.log(obj.search); // ?kw=dell练习:获取以下URl中浏览器端传递的数据http://tmmooc.cn:443/web.html?cid=2007&cname=nodejs
//引入URL模块
const url=require('url');
//引入查询字符串模块
const querystring=require('querystring');
let str2='https://www.tmooc.cn:443/web.html?cid=2007&cname=nodejs';
//把URL解析为对象
let obj2=url.parse(str2);
console.log(obj2.query); // cid=2007&cname=nodejs
//把查询字符串解析为对象
let obj3=querystring.parse(obj2.query);
console.log(obj3.cid, obj3.cname); // 2007 nodejs扩展:Nodejs的URL模块提供的几个方法
url一共提供了三个方法,分别是url.parse(); url.format(); url.resolve();
1、url.parse(urlString,boolean,boolean)
parse这个方法可以将一个url的字符串解析并返回一个url的对象
参数:urlString指传入一个url地址的字符串 参数2、3可省略
第二个参数(可省)传入一个布尔值,默认为false,为true时,返回的url对象中,query的属性为一个对象。第三个参数(可省)传入一个布尔值,默认为false,为true时,额,我也不知道有什么不同,可以去看看API。
2、url.format(urlObj)
format这个方法是将传入的url对象生成一个url字符串并返回。也就是说format方法与parse方法相反,用于根据某个对象生成URL的字符串。
参数:urlObj指一个url对象
3、url.resolve(from,to)
resolve这个方法返回一个格式为"from/to"的字符串,在宝宝看来是对传入的两个参数用"/"符号进行拼接,并返回。也就是说resolve(from, to) 方法用于拼接URL, 它根据相对URL拼接成新的URL;
扩展:URL的解析——html如何获取url中各部分的参数
一图胜千言。不需要过多的文字描述,通过下面的图片你就可以理解一段 URL 的各个组成部分:
url. href 获取到完整的 URL 字符串即原始的url
url.protocol 获取到URL的协议即http
url.host 获取到主机名+端口号
url.hostname获取到主机名hostname
url.port 获取到端口号即80
url.path 和pathname一样,但是包含 ? 及之后的字符串,但是不包含hash
url.pathname 跟在host之后的整个文件路径。但是不包含 ? 及 ?之后的字符串。
url.search 获取到原生的 query 字符串(含?)
url.query 获取到 URL 当中?后面的 query 字符串
url.hash 获取 hash 值,即URL中#之后的部分,如果没有的话输出为null
番外:关于URLSearchParams()函数
URLSearchParams 接口定义了一些实用的方法来处理 URL 的查询字符串。
URLSearchParams() 返回一个 URLSearchParams 对象。该接口不继承任何属性。
方法:
1、URLSearchParams.append() 插入一个指定的键/值对作为新的搜索参数,没有返回值。
2、URLSearchParams.delete() 从搜索参数列表里删除指定的搜索参数及其对应的值。 没有返回值。
3、URLSearchParams.entries() 返回一个iterator可以遍历所有键/值对的对象。
4、URLSearchParams.keys()返回iterator 此对象包含了键/值对的所有键名。
5、URLSearchParams.values() 返回iterator 此对象包含了键/值对的所有值。
6、URLSearchParams.set() 设置一个搜索参数的新值,假如原来有多个值将删除其他所有的值。没有返回值。
7、URLSearchParams.get() 获取指定搜索参数的第一个值。 返回指定键名的值。支持自动 UTF-8 解码
8、URLSearchParams.getAll() 获取指定搜索参数的所有值,返回是一个数组。
9、URLSearchParams.has() 返回 Boolean 判断是否存在此搜索参数。
10、URLSearchParams.sort() 按键名排序。
11、URLSearchParams.toString()返回搜索参数组成的字符串,可直接使用在URL上。
方法实践操作,如下:


六、Timer模块 定时器
Timer模块是全局模块,无需我们引入,可以直接使用其下面的方法
1、一次定时器
| 开启 let timer=setTimeout(回调函数,间隔时间) 当间隔时间到了,执行一次回调函数,间隔时间单位是毫秒 清除 clearTimeout(timer) 释义:setTimeout、clearTimeout 设置延时器与清除延时器 setTimeout(callback,delay[,...args]) callback在delay毫秒后执行一次 clearTimeout则为对应取消延时器的方法 |
//1.一次性定时器
//3000毫秒后,调用一次回调函数
//开启
let timer=setTimeout(()=>{
console.log('boom!');
},3000);
//清除
clearTimeout(timer);
2、周期性定时器
| let timer=setInterval(回调函数,间隔时间) 每隔一段时间,调用一次回调函数 清除 clearInterval(timer) 释义:setInterval、clearInterval 设置定时器与清除定时器 setInterval(callback,delay[,...args]) callback每delay毫秒重复执行一次 |
//2.周期性定时器:每隔3秒钟打印boom
//开启
//声明变量,用于记录次数
let i=0;
let timer=setInterval( ()=>{
console.log('boom');
//每打印1次加1
i++;
//当i为3的时候,清除定时器
if(i===3){
clearInterval(timer);
}
},3000 );
//清除
//clearInterval(timer);3、立即执行的定时器
| 开启 |
| 开启 |
//3.立即执行的定时器
console.log(2);
setImmediate( ()=>{
console.log(1);
} );
process.nextTick( ()=>{
console.log(4);
} );
console.log(3);
立即执行的定时器会将回调函数放入到事件队列中。
事件队列:由一组回调函数组成的队列,当主程序执行完才会执行
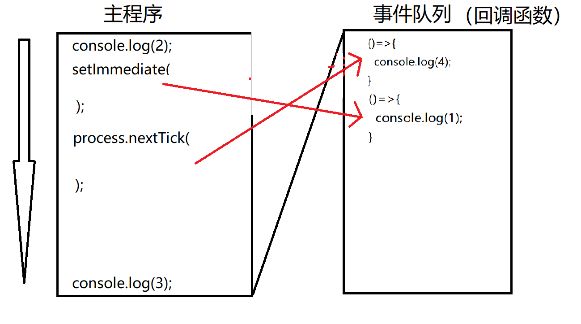
注:nextTic比setImmediate先执行,也就是说nextTick()的回调函数执行的优先级要高于setImmediate() 执行结果为:2 3 4 1
扩展:Node.js中Process.nextTick()和setImmediate()有什么区别(了解,不必深究)
1.在理解两者的区别之前要说一下轮询
nodejs中是事件驱动的,有一个循环线程一直从事件队列中取任务执行或者I/O的操作转给后台线程池来操作,把这个循环线程的每次执行的过程算是一次轮询。
2.setImmediate()的使用
即时计时器立即执行工作,它是在事件轮询之后执行,为了防止轮询阻塞,每次只会调用一个。
3.强大的异步专家process.nextTick()的使用
它和setImmediate()执行的顺序不一样,它是在事件轮询之前执行,为了防止I/O饥饿,所以有一个默认process.maxTickDepth=1000来限制事件队列的每次循环可执行的nextTick()事件的数目。也就是说nextTick 有调用深度限制 1000 个,setImmediate 就没有
4.总结
综合网上的有关于Process.nextTick()和setImmediate()的总结,大致如下:
(1) nextTick()的回调函数执行的优先级要高于setImmediate();
(2) process.nextTick()属于idle观察者,setImmediate()属于check观察者.在每一轮循环检查中,idle观察者先于I/O观察者,I/O观察者先于check观察者。(3) 在具体实现上,process.nextTick()的回调函数保存在一个数组中,setImmediate()的结果则是保存在链表中。
(4) 在行为上,process.nextTick()在每轮循环中会将数组中的回调函数全部执行完,而setImmediate()在每轮循环中执行链表中的一个回调函数。
七、文件系统模块(fs)
在nodejs下文件包含文件形式和目录形式
注意:文件系统模块操作,必须切换到相应的路径
1、查看文件的状态
fs.statSync( 文件的路径 )
isDirectory() 是否为目录
isFile() 是否为文件
2、创建目录
fs.mkdirSync( 目录的路径 )
注:mkdir Make directory 建立目录
3、移除目录
fs.rmdirSync( 目录的路径 )
注:rmdir Remove directory 删除目录
练习:把mydir目录移除
//引入文件系统模块
const fs=require('fs');
//1.查看文件状态
let stats=fs.statSync('./04');
// console.log(s);
//是否为目录
console.log( stats.isDirectory() );
//是否为文件
console.log( stats.isFile() );
//2.创建目录
//fs.mkdirSync('./mydir');
//3.移除目录
//fs.rmdirSync('./mydir');
练习:3秒钟以后一次性创建10个目录,命名为1,2,3....10;紧接着在10秒钟以后再移除这10个目录
//引入fs模块
const fs=require('fs');
//3秒钟以后执行
setTimeout( ()=>{
//创建1~10,10个目录
for(let i=1;i<=10;i++){
//console.log(i);
//i作为目录名称
// ./2
fs.mkdirSync('./'+i);
}
console.log('创建完成');
//删除创建的10个目录
//5秒后删除
setTimeout( ()=>{
//循环10次删除
for(let i=1;i<=10;i++){
fs.rmdirSync('./'+i);
}
},5000 );
},3000 );
//console.log('准备删除');总结:fs文件系统模块的10个方法,这些方法大致可以分别为两类:一类是异步+回调的;一类是同步的
1、查看文件状态
fs.stat( 文件的路径,回调函数) / fs.statSync( 文件的路径 ) 同步的方法
回调函数 用于获取结果
err 可能产生的错误
s 获取到的状态对象
//1.查看文件的状态
//引入fs模块
const fs=require('fs');
//同步方法
//let s=fs.statSync('./01_homework.js');
//console.log(s);
//异步方法
//这个操作就出现了单独的线程执行,把执行的结果以回调函数的形式返回,并放入到事件队列
//所以,异步操作的结果是回调函数,就是说执行回调函数才能获得结果,所以同步操作的结果可以
//放进变量里保存即let s=fs.statSync('./01_homework.js'),而异步操作的结果是通过回调函数获得
//(结果放进参数里),所以,也就不需要声明变量即let s=fs.stat()来保存结果。
fs.stat('./01_homework.js', (err,s)=>{
//err参数1: 放可能产生的错误
//s 参数2: 读取到的文件的状态对象
if(err){
throw err;
}
console.log(s);
});
// 由于是异步方法查看文件状态,所以主程序由上而下执行程序遇到这个异步方法fs.stat时,会独立开一个线程执行,所以,执行异步方法fs.stat()过程中,不会阻止主线程后续代码的执行,异步操作在独立线程执行完以后,将结果以回调函数的形式放入到事件队列中,待主程序执行完以后,紧接着通过执行事件队列里的回调函数来获取异步操作的结果。所以,先执行的是console.log('这是我的工作'),待主程序代码执行完之后,紧接着才会执行异步方法的回调函数来获取结果。
// 总之,一旦主程序里面,遇到了异步方法,那么这个异步方法就会在一个线程里面单独执行,当它执行完以后,会把这个结果,也就是这个回调函数放入事件队列,如果说想查看结果的话,执行回调函数即可获得这个结果。
console.log('这是我的工作');2、读取目录
fs.readdir(文件的路径,回调函数) / fs.readdirSync( 文件的路径 ) 同步的方法
回调函数 用于获取结果
err 可能产生的错误
result 读取到的目录结果,格式为数组
//2.读取目录
//引入fs模块
const fs=require('fs');
//异步
fs.readdir('./mydir',(err,result)=>{
if(err) throw err;
//result 读取到的结果
console.log(result);
});
//同步
let result=fs.readdirSync('./mydir');
console.log(result);3、写入文件(覆盖写入)
fs.writeFile(文件的路径,数据,回调函数) / fs.writeFileSync(文件的路径,数据) 同步的方法
如果文件不存在,则创建文件然后写入数据
如果文件已经存在,会覆盖原来的内容写入
//3.写入文件(覆盖写入)
//引入fs模块
const fs=require('fs');
//异步写入
fs.writeFile('./1.txt','ran',(err)=>{
if(err) throw err;
console.log('创建成功');
});
//同步写入
fs.writeFileSync('./2.txt','ran');
4、写入文件(追加写入)
fs.appendFile(文件的路径,数据,回调函数) / fs.appendFileSync(文件的路径,数据) 同步的方法
如果文件不存在,则创建文件然后写入数据
如果文件已经存在,在末尾追加写入内容
//4.追加写入
//引入fs模块
const fs=require('fs');
//异步追加写入
fs.appendFile('./3.txt','ran\n',(err)=>{
if(err) throw err;
console.log('写入成功');
});
// 同步追加写入
fs.appendFileSync('./4.txt','ran\n')练习:声明变量保存一组姓名(数组),遍历数组,得到每个数据,使用同步方法写入到文件stu.txt
var stu=['然哥','梁山','李汝钊','石卓然','梁哲'];
for(let i=0;i5、读取文件
fs.readFile(文件的路径,回调函数) / fs.readFileSync(文件的路径) 同步的方法
读取的结果为buffer数据
//5.读取文件
//引入fs模块
const fs=require('fs');
//使用异步方法读取1.txt
fs.readFile('./1.txt',(err,data)=>{
if(err) throw err;
//data 读取到的数据,格式为buffer,需要转字符串
console.log( String(data) ); // 也可以使用toString()
});
//使用同步方法读取2.txt
let data=fs.readFileSync('./2.txt');
console.log( data.toString() ); // 也可以使用String()函数,可以将任何数据转为字符串
6、删除文件
fs.unlink(文件的路径,回调函数) / fs.unlinkSync(文件的路径) 同步的方法
练习:分别使用异步和同步删除1.txt和2.txt
//6.删除文件
//引入fs模块
const fs=require('fs');
//使用异步方法删除文件1.txt
fs.unlink('./1.txt',(err)=>{
if(err) throw err;
});
//使用异步方法删除文件2.txt
fs.unlinkSync('./2.txt');7、检测文件是否存在
fs.existsSync(文件路径)fs.existsSync(文件路径)
//7.检测文件是否存在
//引入fs模块
const fs=require('fs');
let r=fs.existsSync('./mydir');
console.log(r);练习:如果文件3.txt存在,则删除该文件;如果目录a存在,则创建该目录
//引入fs模块
const fs=require('fs');
if( fs.existsSync('./3.txt') ){
fs.unlinkSync('./3.txt');
}
if( !fs.existsSync('./a') ){
fs.mkdirSync('./a');
}8、拷贝文件
fs.copyFile(源文件路径,目标文件的路径,回调函数) / fs.copyFileSync(源文件路径,目标文件的路径)同步的方法
//8.拷贝文件
//引入fs模块
// 使用异步方法拷贝文件
const fs=require('fs');
fs.copyFile('./stu.txt','./a/s.txt',(err)=>{
if(err) throw err;
});练习:拷贝02_fs.js到a目录下,名称为02_fs.txt,使用同步方法
//引入fs模块
const fs=require('fs');
// 使用同步方法拷贝文件
fs.copyFileSync('./02_fs.js','./a/02_fs.txt');
9、创建和移除目录
(1) fs.mkdir(目录的路径,回调函数) / fs.mkdirSync(目录的路径) 同步的方法
练习:使用同步和异步方法创建目录 mydir1 mydir2
//使用同步和异步方法创建目录 mydir1 mydir2
//引入fs模块
const fs=require('fs');
//使用异步方法创建目录 mydir2
fs.mkdir('./mydir2',(err)=>{
if(err) throw err;
});
//使用同步方法创建目录 mydir1
fs.mkdirSync('./mydir1');
(2) 移除目录
fs.rmdir(目录的路径,回调函数) / fs.rmdirSync( 目录的路径 ) 同步的方法
//使用同步和异步方法移除目录 mydir1 mydir2
//引入文件系统fs模块
const fs=require('fs');
//使用异步方法创建目录 mydir2
fs.rmdir('./mydir2',(err)=>{
if(err) throw err;
});
//使用同步方法创建目录 mydir1
fs.rmdirSync('./mydir1');10、文件流
fs.createReadStream(文件的路径) 创建可读取的文件流
fs.createWriteStream(文件的路径) 创建可写入的文件流
/*
* rs.on('事件名称',回调函数)
* 事件:一旦匹配事件名称,自动触发,会执行回调函数
*/
// 文件流示例demo如下:
//引入fs模块
const fs=require('fs');
//创建可读取的流对象
let rs=fs.createReadStream('./1.exe');
//事件:一旦数据流入,自动触发回调函数
//on用于添加事件
//data 数据流入事件名称,固定的
//有数据流入,调用回调函数,将数据放入到参数chunk,就是获取的某一段数据
//声明变量用于统计段数
let i=0;
rs.on('data',(chunk)=>{
//console.log(chunk);
//每读取一段加1
i++;
});
//不能在这里打印查看多少段console.log(i),因为这里读取流的过程不一定结束,因为事件
//rs.on('data',回调函数)的回调函数是异步事件,是在单独线程执行的。所以,还需要一个结束事件。第
//一个事件是用于监听是否有数据流入,第二个事件是监听数据是否读取结束,相当于一个保安角色
console.log(i)
//事件:一旦读取结束,才会执行
//end 结束的事件名称,是固定的
rs.on('end',()=>{
//结束后,打印查看有多少段
console.log(i);
});pipe() 管道,用于传输流
//管道应用示例demo如下:
//引入fs模块
const fs=require('fs');
//通过可读取的流和可写入的流完成文件的拷贝
let rs=fs.createReadStream('./1.exe');
let ws=fs.createWriteStream('./2.exe')
//把读取的流通过管道添加到写入流
rs.pipe(ws);️Tips:关于文件系统模块
来看一下nodejs的FileSystem模块提供了很多种方法,这些方法大致可以分别为两类:一类是异步+回调的;一类是同步的。其中stat就是属于前者,statSync就是属于后者。
来看一下使用区别:
1.异步版:fs.stat(path,callback):
path是一个表示路径的字符串,callback接收两个参数(err,stats),其中stats就是fs.stats的一个实例;
2.同步版:fs.statSync(path)
只接收一个path变量,fs.statSync(path)其实是一个fs.stats的一个实例;
3.再来看fs.stats有以下方法:
stats.isFile()
stats.isDirectory()
stats.isBlockDevice()
stats.isCharacterDevice()
stats.isSymbolicLink()(onlyvalidwithfs.lstat())
stats.isFIFO()
stats.isSocket()
◼️同步和异步◼️
️同步:在运行的过程中,会阻止后续代码的执行,只有运行完才能往后执行,通过返回值来获取结果
️异步:在运行的过程中,不会阻止后续代码的执行,在一个独立的线程执行,执行完以后,将结果以回调函数的形式放入到事件队列,通过回调函数来获取结果(回调函数存放在事件队列里)
扩展:关于同步与异步
Javascript语言是一门单线程的语言,JS中大部分都是同步编程,只有某些非常耗时的任务才会选择进行异步操作(异步任务都放进任务队列即事件队列里。等主线程任务执行完毕,"任务队列"开始通知主线程,请求执行任务,该任务才会进入主线程执行。)。
而同步:指的是等待一件事情完成之后才会去执行下一件事,JS中大部分都是同步编程。循环就是同步的,所以在编码过程中尽量减少循环的使用。异步:规划一件事情,但不是立即去执行,需要等待一定的事件,此时异步编程不会等待他执行,而是先去执行下面的操作,当下面的事情处理完再回过来执行这个事件
JS中异步编程只有四种情况:
1、定时器 2、事件绑定 3、ajax读取数据的时候设置为异步 4、回调函数也是异步编程的
⬛http协议
http协议是浏览器和web服务器之间的通信协议
通常,Web服务器一直使用指定端口(默认为80端口)监听客户端的请求。请求由客户端发起,创建一个到服务器指定端口的TCP连接。一旦收到请求,服务器会向客户端返回一个状态,比如“HTTP/1.1 200 OK”,以及返回的内容,如请求的文件、错误消息、或者其他信息,这就是服务器端的响应。
1、通用的头信息
request URL:请求的URL,向服务器端请求的资源
request Method:请求的方法get / post 从服务器取数据get 向服务器传数据post
Status Code:响应的状态码(响应状态)
响应信息的第一行就是响应状态,内容依次是当前HTTP版本号,三位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。状态代码的第一个数字代表当前响应的类型,xx表示两位数字。
1**:正在响应,还没有结束(请求已被服务器接收,继续处理)1xx消息
2**:成功的响应(请求已成功被服务器接收、理解、并接受)2xx成功
3**:响应的重定向,跳转到另一个URL (需要后续操作才能完成这一请求) 3xx重定向
如,访问www.baidu.cn会直接跳转到.www.baidu.com
4**:浏览器端请求错误 (请求含有词法错误或者无法被执行)4xx请求错误
如,Error 404
5**:服务器端错误 (服务器在处理某个正确请求时发生错误) 5xx服务器错误
如,网站访问量过大,服务器崩溃,无法访问网站
2、响应的头信息
响应头用于指示客户端如何处理响应体,告诉浏览器响应的类型、字符编码和字节大小等信息。
Allow:服务器支持哪些请求方法(如GET、POST等)
Content-Encoding:文档的编码(Encode)类型。只有在解码之后才可以得到Content-Type头指定的内容类型
Content-Length:内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据
Content-Type:设置响应的内容的类型(表示后面的文档属于什么MIME类型)即
服务器告诉浏览器,响应主体的数据格式 html ---> text/html
Location:跳转的URL,通常会结合着状态码3**使用
Date:当前的时间
Expires:文档过期时间
Refresh:表示浏览器应该在多少时间之后刷新文档,以秒计
Server:服务器名称
Set-Cookie:设置与页面关联的Cookie
WWW-Authenticate:客户应该在Authorization头中提供的授权信息类型
3、响应主体
响应正文,即服务器传给浏览器的数据 (返回的页面代码)
响应头之后紧跟着一个空行,然后接响应体。响应体就是Web服务器发送到客户端的实际内容。除网页外,响应体还可以是诸如Word、Excel或PDF等其他类型的文档,具体是哪种文档类型由Content-Type指定的MIME类型决定。
扩展:text/html和text/plain的区别
1) text/html的意思是将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。例如:res.writeHead(200,{ 'Content-Type':'text/html;charset=utf-8' }); res.write('这是首页
'); // 设置响应的内容。h2标签会被解析2) text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理。
扩展:node.js中的content-type(设置响应数据的类型)
①在服务器默认发送的数据,其实是utf-8编码的内容
②浏览器在不知道服务器响应内容的情况下会按照当前操作系统的默认编码去解析
③中文操作系统默认是gbk
④解决方法:正确地告诉浏览器,服务器响应的内容是什么编码的
⑤在http协议中,Content-type 就是用来告知浏览器,响应的数据类型
扩展:node.js-中文乱码解决
使用NodeJS,当有中文时,如果不做任何处理就会出现乱码。因为,NodeJS 不支持 GBK。当然,UTF-8是支持的。
所以,要确保不出现乱码,应做到以下两点:
①保证你的 JS文件是以UTF-8格式保存的。
②在你的JS文件中的 writeHead 方法中加入 "charset=utf-8" 编码
4、请求的头信息(Request Headers)
1) Host: www.tmooc.cn 浏览器告诉服务器,要访问的主机是谁
2) Connection: keep-alive 浏览器告诉服务器,请开启持久连接
3) User-Agent: Mozilla 浏览器告诉服务器,当前浏览器的版本号和系统信息
4) Accept:浏览器可接受的MIME类型
5) Accept-Encoding: gzip 浏览器告诉服务器,我这个浏览器可以接收的压缩文件类
6) Accept-Language:浏览器指定的语言
7) Accept-Charset:浏览器支持的字符编码
8) Cookie:保存的Cookie对象
Host请求头指明了请求将要发送到的服务器主机名和端口号。Host让虚拟主机托管成为了可能,也就是一个IP上提供多个Web服务。
5、请求主体(Request Body)
表单传递的数据(在formdata里),如果没有数据此项为空
八、http模块
创建web服务器
//引入http模块
const http=require('http');
//创建web服务器
const app=http.createServer();
//设置端口
app.listen(8080);
//根据浏览器的请求作出响应
//通过事件作出响应
app.on('request',(req,res)=>{
//req 请求的对象
//req.url 获取请求的URL
//req.method 获取请求的方法
console.log(req.url, req.method);
//res 响应的对象
//参数1:设置响应状态码
//参数2:可选的,设置响应的头信息
//res.writeHead(302,{
// Location:'http://www.tmooc.cn'
//});
//设置响应的内容
res.write('这是你的jianbing');
//结束并发送响应
res.end();
});注意:res.write() 括号中的内容必须加引号(变量不需要加引号),且参数类型必须是string或Buffer或Uint8Array的实例。如果是buffer数据,会隐式转换为字符串
扩展:Uint8Array 对象
该Uint8Array类型数组表示8 位无符号整数值的类型化数组。内容将初始化为 0。(如果无法分配请求数目的字节,则将引发异常。)一旦建立,您可以使用对象的方法或使用标准数组索引语法(即使用括号表示法)引用数组中的元素。
1、Uint8Array对象的语法:
new Uint8Array(); // new in ES2017new Uint8Array(length);
new Uint8Array(typedArray);
new Uint8Array(object);
new Uint8Array(buffer [, byteOffset [, length]]);
2、Uint8Array对象的参数(属性):
uint8Array
必选。 Uint8Array 对象分配到的变量名称。
length
指定数组中元素的数目。
array
该数组中包含的数组(或类型化数组)。内容将初始化为给定数组或类型化数组的内容,且每个元素均转换为 Uint8 类型。
buffer
Uint8Array 表示的 ArrayBuffer。只读。获取此数组引用的 ArrayBuffer。
byteLength
只读。此数组距离其 ArrayBuffer 开始处的长度(以字节为单位),在构造时已固定。byteOffset
可选。指定与 Uint8Array 将开始的缓冲区开始处的偏移量(以字节为单位)。
只读。此数组与其 ArrayBuffer 开始处的偏移量(以字节为单位),在构造时已固定。length
数组中的元素数即数组的长度。
参考:Uint8Array (Global Objects) - JavaScript 中文开发手册 - 开发者手册 - 云+社区 - 腾讯云
以下链接文章总结了Express中响应中常用的这4种API的用法之间的区别整理
泣血整理Express框架中res.write、res.end及res.send 、res.json方法之间的区别?
扩展:res.end()和res.write()
1、res.end()
① res.end是不允许输出多行的
res.end("Hello world"); // 输出
res.end("Hello world"); // 输出
浏览器中只输出一行结果
②res.end不能输入非字符串
此时我们输出一个数字就回报错,查看报错信息,提醒我们不能输出number类型
③ res.end可以结合HTML标签显示数据
res.end("hello world
");
2、res.write()
如果要使用res.write最后必须要有res.end,否则浏览器会一直处于处于请求状态
多条语句输出使用的是res.write(在 res.end() 之前,res.write() 可以被执行多次),并且也结合HTML标签进行使用;和res.end一样res.write()不能输入非字符串的内容。
扩展:res.json 和res.end 及res.send()的区别
①用于快速结束没有任何数据的响应,使用res.end()。简单来说就是,如果服务器端没有数据返回到客户端,那么就可以用 res.end。如果使用res.end()返回数据非常影响性能。
②响应中要发送数据,使用res.send() 。也就是说,如果服务器端有数据返回到客户端这个时候必须用res.send ,不能用 res.end(会报错)。另外,要注意header ‘content-type’参数。(ressend 返回时,数据被处理了,在请求头中被添加了,context-type 返回类型)
③响应中要发送JSON响应,使用res.json()。
扩展:express中的res.send和res.write有什么区别?
①res.send仅在Express js中。
②为简单的非流式响应执行许多有用的任务。
③能够自动分配Content-Length HTTP响应标头字段。
④能够提供自动的HEAD和HTTP缓存新鲜度支持。
⑤res.send只能被调用一次,因为它等同于res.write+res.end()
练习:创建web服务器,设置端口;根据浏览器请求的URL作出以下响应:
/list 响应 ‘this is product list’
/index 响应 ‘这是首页
’
/ 响应文件1.html (先同步读取文件,把读取到的文件作为响应的内容)
/study 跳转 http://www.tmooc.cn
其它 响应状态码404 内容 not found
◾该例子可作为nodejs原生模块http创建服务器并响应浏览器请求的数据的一个模板◾
//引入http模块
const http=require('http');
//创建web服务器
const app=http.createServer();
//设置端口
app.listen(8080);
//通过IP或者域名访问web服务器
//http://127.0.0.1:8080
//http://localhost:8080
//当浏览器发出请求,服务器端做出相应
//事件:当浏览器请求,自动执行回调函数,通过回调函数响应
app.on('request',(req,res)=>{
//req 请求的对象
//req.url 获取请求的URL
//req.method 获取请求的方法
console.log(req.url, req.method);
//res 响应的对象
//参数1:设置响应状态码
//参数2:可选的,设置响应的头信息
// 响应状态码与location共同配合才能实现一个跳转
res.writeHead(302,{
// 要跳转(重定向)的网址
// Location:'http://www.tmooc.cn',
// nodejs中出现中文乱码解决方法
'Content-Type':'text/html;charset=utf-8'
});
//设置响应的内容
res.write('这是你的jianbing');
//结束并发送响应
res.end();
});◾通过IP或者域名访问web服务器◾
http://127.0.0.1:8080 // 永远是自己的电脑
http://localhost:8080 // 永远是自己的电脑
◾端口号后是url响应的内容◾
http://127.0.0.1:8080/list
http://127.0.0.1:8080/index
http://127.0.0.1:8080/
http://127.0.0.1:8080/study
【后文传送门】【Nodejs】初识Node.js Web应用开发框:Express_03

如果这篇【文章】有帮助到你,希望可以给【青春木鱼】点个赞,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点,如果有对【前端技术】感兴趣的小可爱,也欢迎关注❤️❤️❤️【青春木鱼】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】!