推荐系统中模型训练及使用流程的标准化

文章作者:梁超 腾讯 高级工程师
编辑整理:Hoh Xil
内容来源:DataFun AI Talk
出品社区:DataFun
导读:本次分享的主题为推荐系统中模型训练及使用流程的标准化。在整个推荐系统中,点击率 ( CTR ) 预估模型是最为重要,也是最为复杂的部分。无论是使用线性模型还是当前流行的深度模型,在模型结构确定后,模型的迭代主要在于特征的选择及处理方面。因而,如何科学地管理特征,就显得尤为重要。在实践中,我们对特征的采集、配置、处理流程以及输出形式进行了标准化:通过配置文件和代码模板管理特征的声明及追加,特征的选取及预处理等流程。由于使用哪些特征、如何处理特征等流程均在同一份配置文件中定义,因而,该方案可以保证离线训练和在线预测时特征处理使用方式的代码级一致性。
▌一. 推荐系统
1. 业务简介
这是我们的产品天天快报,会涉及首页以及数十个子频道,对于这些频道我们都需要做召回以及排序模型。如何高效的管理这么多的频道呢?我们就需要一个很好的系统来管理所有的特征和模型。
2. 推荐系统流程
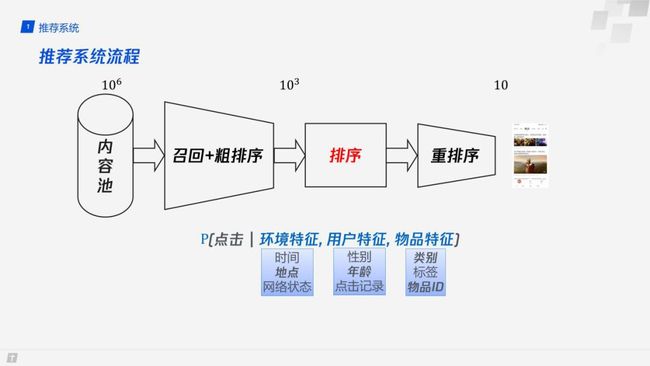
简单回顾下推荐系统的流程,整个推荐系统需要从数以百万计的内容池中筛选出数以十计的文章推荐给最终的用户。在这个过程中主要涉及三个步骤:
第一步,从百万量级中通过环境特征,用户特征,物品特征等信息来找出千级别的文章。
第二步,通过排序模型来预估点击率或者预估用户对这篇文章的偏好程度。
最后,通过一些运营规则和多样性方面的考量 ( 比如用户喜欢王者荣耀,但不能推荐给用户都是这类的视频或文章 ),最终呈现给用户10篇左右的文章。
3. 常用推荐模型

常用的推荐模型有 LR、FM、DNN、W&D、DeepFM、DIN 等模型,对于推荐系统,无论使用哪种模型,都需要以下几个模块:
样本搜集:训练模型离不开大量的训练样本,所以需要进行样本 ( 特征和标签 ) 的搜集;
特征配置:实际的推荐系统中会有上百个特征供模型选择,在模型版本迭代的过程中,有些特征会被舍弃,有些特征会新加进来;因而,我们就需要配置搜集哪些特征、使用哪些特征,在迭代过程中,还需要保证现有模型训练和预测服务的稳定性;
特征处理:对于每个特征,比如用户 ID,该如何离散化成一个最终使用的int型的数字,就需要经过一定的特征处理;
模型训练&模型预测:特征处理完之后,如何喂给模型训练程序以及线上的预测模型,如何在修改了特征配置之后,无需人工修改训练和预测代码,从而降低工作量、减少 bug 的引入,都是我们需要考虑的工作。
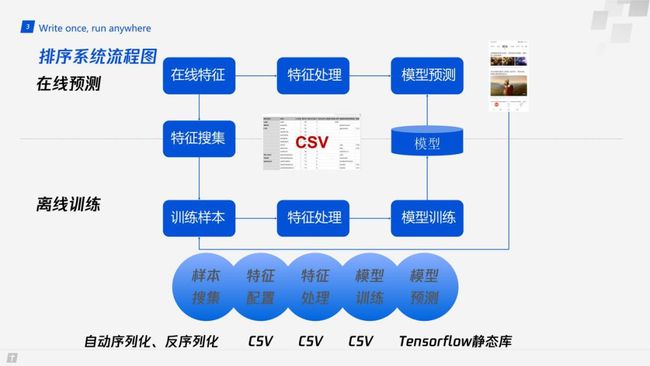
4. 排序流程图
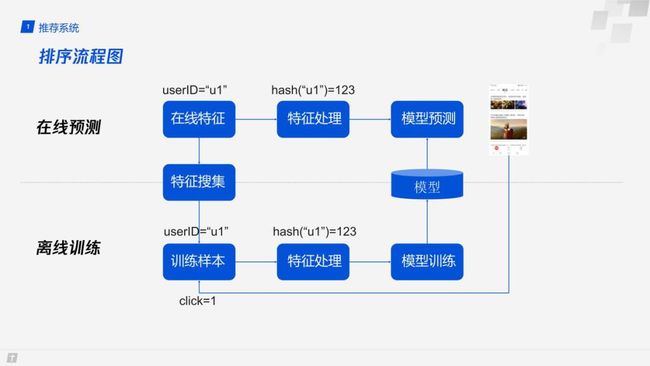
上图为排序系统的流程图:
以用户 ID 特征 ( userID ) 为例,在线预测时,会首先把 userID 填入某一个变量中,并通过某种 hash 函数把它变成整数类型 ( 比如 C++ long 类型 ),再输入到模型中;与此同时,我们需要把在线的特征记录到日志中,作为模型训练的样本。
离线训练:将特征日志和用户行为 ( 是否点击、是否点赞、消费时长等 ) 日志结合起来,形成最终带有标签的训练样本,再通过同样的特征处理流程,形成训练样本进行模型的训练。
▌二. 推荐系统中模型迭代的痛点
与研究中给定的数据集不同,推荐系统中的模型需要不断地迭代调优。在日常的工作中,我们常常需要在保证现有模型服务稳定的前提下,不断地增加新的特征,训练新的模型。于是,我们会面临下图所示的诸多问题。

▌三. Write once,run anywhere 的特征处理标准
要设计一套特征处理的标准,我们首要面临的问题是如何描述特征处理的流程 ( C++ 代码?protobuf?XML?)。基于以下几点考虑:
1. 尽量减少人工写代码的量;
2. 易于查看和维护;
3. 易于迭代,我们设计了一套基于 CSV 格式的特征处理框架。
首先,我们来看一下,在模型训练方面,业界是怎么做的。
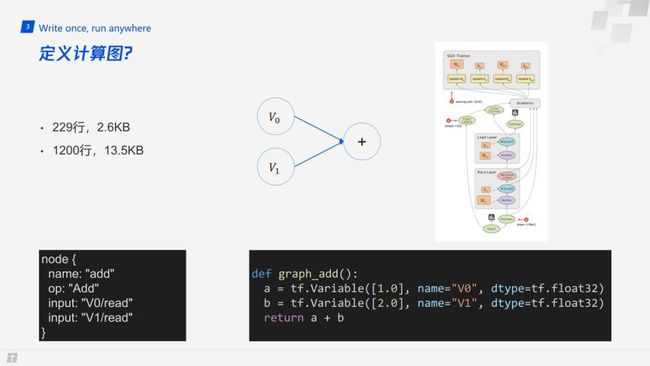
在工业界,对于的模型训练和预测部分,TensorFlow 等框架已经做得比较完善了。那么,TensorFlow 是如何定义整个数据流的呢?它是用计算图来定义的,以两个变量相加为例,代码非常简单,如果转化为 pb ( 上图左下角 ) 也只有这几行。但实际上呢?这里给出两组数据:229行,2.6KB;1200行,13.5KB。229行,2.6KB 为上面的加法操作转化为实际的 pb 的大小,而如果有10个加法操作的计算图,则需要1200行,13.5KB。所以,用通用的计算图来定义特征的处理流程,虽然很灵活,但却非常不利于人来阅读和管理。在系统设计的过程中,我们期望所有的特征定义及其处理流程都可以一目了然的看到。
如上图所示,在考虑到样本搜集、特征配置、特征处理、模型训练、模型预测等需求后,我们选用了 CSV 来管理整个过程,CSV 中的每一行定义了一个特征,包含了特征的名称、类型、序列化后的位置、处理方式等信息,且可以灵活地增加列来定义新的功能。
下面沿着之前提到模型迭代的痛点,依次看下我们是如何通过一个 CSV 来解决的:
痛点1:快速增加特征

首先旧的流程中,我们都需要声明一个变量来临时存储在线所需要的特征,编写特征填充代码,同时还需要编写特征变换代码、特征序列化代码、特征反序列化代码以及特征监控代码。以上种种功能,都需要针对每一个变量进行独立的编写。
我们新的流程中,只有在 CSV 中定义变量处理方式和编写特征填充代码两个部分:
如上图右下角有4个特征,假设用户 ID,用户性别以及 itemID 是已有的特征。现在,我们需要新加一个特征,我们就会在这个表格第四行新加用户 Tag 特征,同时定义下这个特征的类型以及在日志中的位置,是属于用户特征还是物品特征,剩下的步骤则通过一个 python 脚本和一个代码模板来生成新的 C++ 程序自动完成。增加了这个变量后,特征日志中会增加上图右上角所示的 tag 信息。
痛点2:在线、离线特征的一致性

模型训练所需的特征需要和在线预测时的特征完全一致。在工业界中,一般会将在线特征 dump 到日志中,训练时结合标签生成完整的训练样本,从而保证在线、离线特征的一致性。然而,旧的流程中,针对每个特征的序列化,都需要手写代码,反序列化亦然,这就大大增加了算法工程师的工作量,且容易引人 bug。
我们的做法是把特征的类型进行了标准化,抽象出4种标准的类型 ( 整形、稀疏整形、字符串、稀疏字符串 ),它们都继承自基类 Feature,这个类会包含特征处理的方方面面,如生成特征、序列化、反序列化。我们只需要保证每种特征类型的特征的序列化和反序列化函数是正确的,就可以保证在线的特征和离线特征是完全一致的。
痛点3:特征配置及特征处理
① 特征配置

特征的配置包含两方面的内容:搜集哪些特征及模型使用哪些特征。
在实践中,我们需要保证已有模型的稳定性,并不断地搜集新的特征。为此,我们将特征搜集服务与 ranking 服务相分离,但复用特征填充代码。服务分离有两个好处:
1. 在特征搜集服务中新增所需搜集的特征无需更改 ranking 服务;
2. 在 ranking 阶段,一般有数千个物品,而我们的特征搜集服务只搜集返回给用户的十来个物品的特征,大大减小了日志量。
搜集到的特征是模型训练和预测所需特征的超集。当需要进行模型的训练或预测时,我们只需在 CSV 中使用 is_using 列来控制是否使用某一特征。需要进行模型迭代时,只需要 CSV 中的配置,并重新生成一份代码即可。此外,交叉特征也只需要在 CSV 中进行配置即可,并且,由于对特征类进行了标准化,我们可以轻松支持任意个特征的交叉。
② 特征处理

如果我们像 TensorFlow 那样定义一个非常灵活的计算图的话,虽然是很好的,但是不利于模型的管理。因此,我们把单个特征的处理抽象成了3步:特征填充 ( 手工编写代码或经由其他特征变换而来 );特征值和特征权重变换;特征值和特征权重向量联合变换 ( 支持多次变换 )。
仍以 tag 特征为例:
如上图所示,一般情况下,每个特征都会有 tag 值 ( key ) 和权重 ( value ),我们会先将 key 进行离散化,比如 hash;并对权重做一定的变换,比如设为1;之后,对整个 key、value 向量进行联合变换,比如,key 乘以10,value 不变 ( 举例用,一般不做变换 )。
此外,有时我们需要一些统计信息,比如 tag 分数大于0.5的 tag 数量。那么,就可以真正用到特征值和特征权重向量联合变换,我们只需要在这一步统计整个 key、value 向量中 value>0.5 的个数即可。

那么,如果我们既需要保留 tag 信息 ( 第一种变换 ),又需要 tag 分>0.5的个数作为特征呢?我们只需要在 CSV 中重新声明一个变量,并在特征赋值部分将其特征设为第一个变量的内容,并进行相应变换即可 ( 实际中,可以直接在赋值部分写统计函数即可 )。
痛点4:支持多种模型

我们的系统支持两种训练样本格式:libsvm 和 sparse tensor 数组。
其中,libsvm 是线性模型的主流格式;而 sparse tensor 则是 tensorflow 中的支持稀疏特征的主流格式 ( tensor 可以视为 sparse tensor 的特例 )。
以上图中的样本 ( 省略了标签部分 ) 变换过程为例,该样本中包含两个物品信息,因而会生成两条样本。对于 libsvm 格式,只需要将每个特征变换后的结果存储到一个向量中即可。对于 TensorFlow 等框架,内部都是用矩阵来进行运算的。矩阵又会分为两种:稠密的矩阵和稀疏的矩阵。同时,稠密矩阵又是稀疏矩阵的特例。所以,我们会将所有的特征全部以稀疏矩阵的形式喂到模型中,方便程序统一的处理。还是以稀疏特征 tag 为例,该特征会用户两个稀疏矩阵 ( 特征值矩阵和权重矩阵 ) 来进行表示,且共用下标和形状,特征值就是刚刚经过离散化的特征值,这里没有用到权重,所以全部设为1。我们可以看到,虽然它是一个稀疏矩阵,但是它是一个2x2的矩阵,每个都有元素,所以可以用稀疏矩阵来表示稠密矩阵。

有了训练样本之后,如何进行模型训练?我们提供了3种方式:
通过将 CSV 转换为一个 hpp 文件之后,我们会编译出一个专门用于将原始特征日志转换为训练样本的可执行程序,并通过 hadoop streaming 方式,生成 libsvm 格式的训练样本。这种方式有两个缺点:增加了流程的复杂性,且耗费存储资源。原始的特征日志相当于进行了压缩 ( 多个物品共用一组用户特征 ),展开之后相当于每条样本对应的用户特征是重复的,且会生成大量的交叉特征,这会导致文件的大小增加10倍以上。
第二种形式,则是将生成的 hpp 文件通过 JNI 编译成一个 SO,可以直接在 Spark 上调用,生成 libsvm 格式的 RDD 进行训练,该方案避免了训练样本占用磁盘空间的问题,但流程仍较为复杂。
最后,则是我们目前使用的动态编译 so 的形式。由于 tensorflow 模型训练程序是 python 编写的,而我们的 CSV 转 hpp 程序也是 python 编写的,因而,我们在使用 tensorflow 训练前,会检测 CSV 是否更新,然后动态的决定是否重新编译自定义的 tensorflow 算子。在训练时,该算子会将原始特征日志转换为 sparse tensor 格式的训练样本。此外,使用配置文件还有一个好处:训练程序还会读取 CSV 中额外的配置信息,从而知道有多少个特征每个特征 embedding 的维度、大小,是否需要 attention 机制等信息,供模型训练使用。
痛点5:特征监控
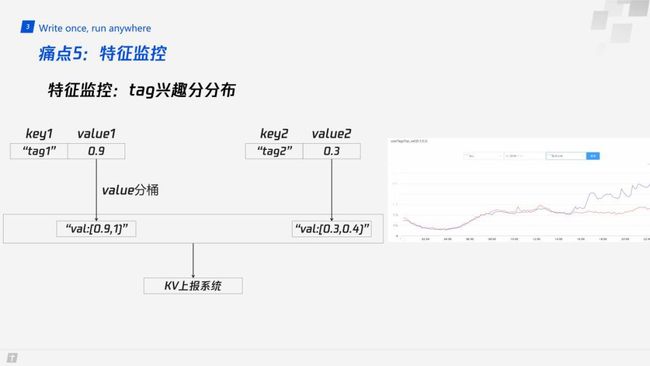
由于推荐系统的复杂性,我们需要对各个环节进行必要的监控,从而保证出现问题时可以及时知道。以 tag 兴趣分分布为例:
类似于特征的变换流程,我们会在 CSV 中配置监控函数。如上图所示,为 tag 特征的 value 分桶监控过程。
首先,对 tag 的兴趣分进行分桶,比如这里有两个兴趣分,我们可以把它们分成10段,0.9~1是一段,0~0.1是一段等等,再把这些序列化后的字符串通过上报系统进行上报,然后展示在右边的曲线中。通过这些曲线,我们可以对比同一区间内特征数量的同比、环比等信息,从而在特征分布变化剧烈时及时进行告警。
痛点6:样本过滤 & 加权
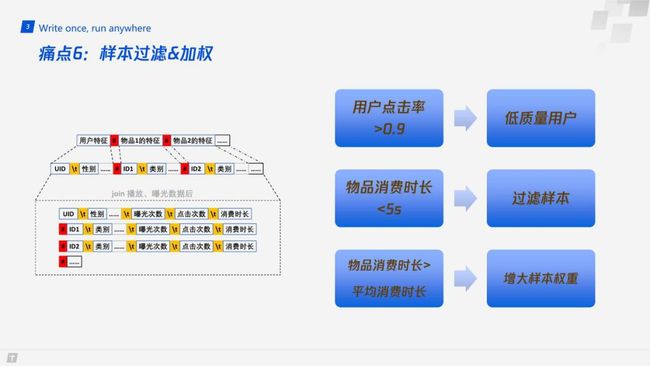
我们实际的特征格式如上图左侧所示,我们会在用户特征和物品特征后面分别加上几列,会统计某一段时间内用户或物品的曝光次数,点击次数,以及消费时长。
如果某一用户短时间内曝光超过1000次,或者消费时长特别长,或者点击率特别高,则可能是机器刷量的,我们就会将这些样本过滤掉。
此外,对于一条样本,即使用户点击了,如果消费时长过短,我们也会将其设为负样本或者过滤掉,或者设一个比较小的权重。
Ranking 流程图

最后看一下完整的系统流程图:
首先通过特征配置文件和一个代码模板,管理所有的特征。
通过脚本配置文件生成 hpp 代码,模型预测时使用该代码进行特征的变换。
在重排序确定要展示给用户哪些物品之后,重复一遍特征填充的过程,然后再把可能产生曝光的物品特征序列化到特征日志中。
在离线过程中,将特征日志通过反序列化的方法,重新填充整个特征类。通过同样的特征变换代码,变换成和线上完全一致的特征 ( 针对同一版模型 ),等到样本标签从客服端返回之后,生成最终的训练样本,供模型训练。
▌四. 总结
我们将推荐系统中特征处理的流程进行了标准化,该标准化体现在特征类型的标准化和特征处理过程的标准化两方面。我们通过一个 CSV 文件完成了特征配置、特征搜集、特征处理、模型训练 ( 部分 )、模型预测 ( 部分 ) 的管理工作,大大降低了人工的编码量,提高了工作效率、降低了人为引入 bug 的可能性。
