数据有了,如何构建数据资产?
本次分享从以下四个环节展开:
-
场景介绍
-
架构设计
-
数据开发
-
应用开发
01场景介绍

为了让大家更好的了解这些产品的应用,首先模拟一个企业应用场景demo:
有一家中型的零售商,客户和销售数据分散在不同系统中。希望通过一个项目打通并实现标准化、集中化的管理。管理好了之后同时希望能把数据实现价值发挥,为高层提供多维度的销售报表,维度包括:客户、产品、地域和时间。度量包括:销售额和净利润。
企业在技术层面上有如下需求:
-
原始数据存储于MySQL数据库或者其他的文件中。
-
为了保护原始生态系统的稳定性,不用查询源数据直接访问生产主库。
-
最大处理TB级数据,需要2小时完成数据全链路处理。
-
报表查询秒级响应。
业务需求分析
业务解读:
-
数据打通及标准化,通常按照数仓/数据集市方式实现数据治理。
-
高层使用多维报表需要考虑页面效果以及需求高效响应,客户高层的需求除了常用的东西之外还需要快速的响应需求。
技术解读:
-
TB级别在大数据领域属于数据量中等规模,针对大数据处理从TB到PB的数据增量的过程当中,需要考虑底层未来的扩展性。
-
大数据量报表秒级响应依赖高性能分析型数据库。
设计方案:
-
依托多行业实践经验方法论进行构建,实现数据资产管理的集中化、标准化、稳定、历史资产保护
-
为保障大规模数据处理的性能、稳定性、扩展性,使用分布式大数据基础平台BMR
-
为提高数据治理效率,降低数据资产构建过程门槛,使用一站式大数据开发治理平台EDAP
-
为保障TB级明细数据多维数据查询性能,使用MPP数据库Doris
-
为加速报表开发效率以及可视化渲染效果,使用可视化报表开发平台sugar Bl
02架构设计
技术架构与数据架构
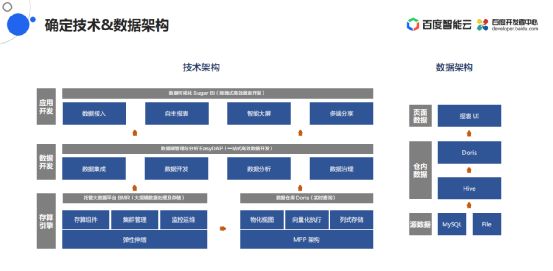
基于这个业务需求,首先就要进行架构设计。技术架构其中分了三层:
-
最底层有存算引擎,包括托管大数据平台BMR和数据仓库Doris。
-
开发平台是面向开发者提高开发效率的工具——数据湖管理与分析EasyDAP。
-
面向高管驾驶舱报表的Sugar BI。
这就是产品层面的技术架构。
右侧是数据架构,数据要从原始的生产系统里面数据库拿出来,所以数据架构的源数据在MySQL或者文件里。
在构建数仓的过程中要进行大规模的ETL处理,一部分要进行基于数仓的实时查询,所以使用了BMR里面的Hive以及Doris这两款存储引擎来完成数据的存储和数据的加工。
最上层生成的报表有UI层面的页面数据。
整体的数据架构也是分三层:源数据、仓内数据、页面数据。
数仓构建
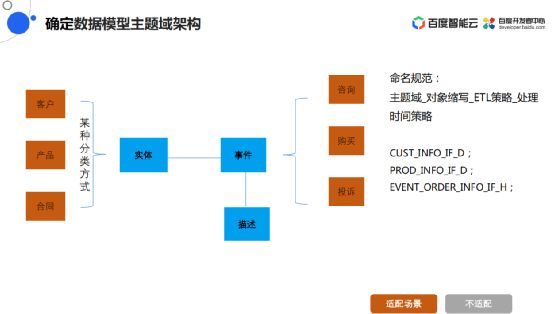
技术架构之外,还需要进行数仓构建。
数仓构建的核心就是数据要以一种标准化、规范化、统一化的形式把数据管理起来。
这里引入主体域的概念:什么数据应该存在哪个主题下,具体到不同的业务里面应该怎么划分主题。
划分方案是:实体、事件和描述,可以客观的把日常生活中各种各样的业务用这三个关系表达出来。
举例一个业务场景,比如某人去超市购物,商品或者人就是一个实体,在购物的过程中比如刷卡这是事件,所谓事件就是什么时间什么地点什么人做了什么事,它是一条事务性的记录,它在做这些事情的过程当中有这样一些定语相关的对他进行描述。
回到构建的场景里面来,这是一家中型的零售商在进行产品的售卖,实体有客户实体、产品实体和合同实体。事件是在购买产品的过程当中有咨询、购买和投诉,按照这样的分类方式就把主题域划分清楚了。
数据模型分层架构

把模型划分好了之后需要对ETL中数据进行分层。
左边是最通用的分层方式:从ODS层,到DWD层,再到DWA层,最后到ADS应用层,这也是市面上主流的厂商提供的数据分层的结构。我们认为这样的分层方式虽然通用,但是不够细化,对于一些精细化的数据管理应该是按照7层的数据流架构,这样能够涵盖所有的加工过程。
在数据流架构之中,SRC是元数据层。ODS是贴源层,贴源层和SRC实际上就是实现数据上的解耦,数据层面是一个镜像级的拷贝,目的是完成对所有生产型业务系统的备份。
DWD是标准明细层,从数据粒度上讲是类似的,从数据的定义上是实现了统一化。
DWA是将数据进行加工汇总。DMA存放个性化的使用。之后将不同指标的计算方式拆分成两层比如报表层和分析层以及最外层的展示层,在构建当中可以灵活的选择需要哪一层。
03数据开发
开发顺序
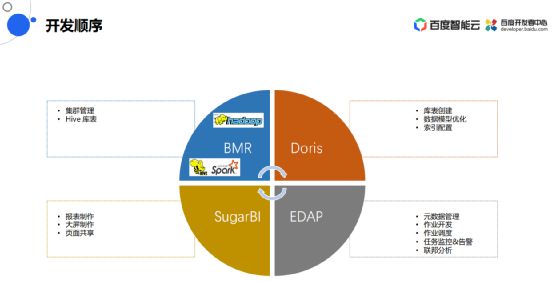
开发过程当中,需要进行大规模数据的存储和计算,所以需要一款大数据引擎BMR,建数仓的核心是BMR里面的Hive,基于Hive数据在应用层需要做多维的秒级的实时响应查询,所以需要一款高性能的分析型数据库Doris,开发过程中使用EasyDAP,报表制作使用Sugar BI。
为什么要用BMR?
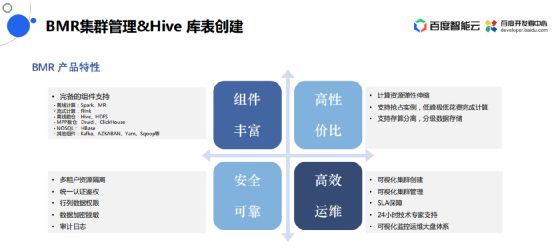
有非常丰富的组件,不仅是可以完成结构化的数仓,还可以支持完成数据湖的搭建。
高性价比的产品,可以使用更小的资源进行更大规模数据的处理,用更少的存储来存更大量级的数据,同等规模下成本会越来越低。
可以高效运维,整个平台就是页面是全托管的使用方式,不需要在底层写命令来做运维监控,所有的东西都能通过控制台来完成。
非常安全可靠,有各种各样的安全认证,有行列级别的数据权限,在数据的加密脱敏方面有固定的组件支撑,用户的所有操作都可以通过审计。
Hive库表创建

进行BMR的集群构建和库表的创建,需要把Hive表建立起来。在建Hive表的过程当中,需要把Hive表的集群搭建起来,其中有这么几个步骤:
-
第一步是集群创建,过程当中要选择一些必要的组件比如Hive、Spark。选好之后需要进行队列的管理,能够最大力度保证核心任务快速跑完,所有的队列创建好了之后,在实际运行过程中是需要去检测有没有一些运行中出现的服务异常,或者服务异常之后的报警功能。
-
第二步要进行Hive库表的创建,建立一些数据库如ODS库、DWD库和DWA库,建表过程当中,每一层的库都遵循建表的规范。
Doris产品特性

Doris产品其实是高性能的MPP数仓,它的特性有以上几点。
Doris建库建表

在Doris上需要建立好DMA,建库的过程只需要creat_database 命令,然后通过可视化的页面就完成了,建完库之后需要把DMA里面的表创建好,建表规范与DWA和DWD一致,都是按照主题域然后特定的业务实体来表达。
在这个建表的过程当中可以指定哪些表是维度,所谓维度就是说可以用来做聚合,把聚合的字段定义好之后,那么在这张表的写入过程当中,程序就会默认帮你把底层多维交叉的分组数据在指标层面做了分组和统计,当我们去查询这两个维度下对应的指标数据的时候,这已经不是一个实时计算的过程而只是一个实时查询的过程,所以它能实现数据的快速响应。
最后建完表之后要把数据快速导入,Doris和主流的Hadoop生态是兼容的,Hive建完仓之后,数据其实是放在HDFS中,所以只需要把HDFS导入就可以了。
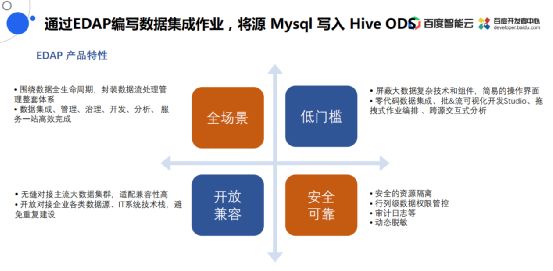
EasyDAP产品特性
用这些基础的引擎构建完之后,在开发的过程中是需要把ETL工作流通过一款产品来完成,这款产品就是EasyDAP。
-
能做数据集成、数据开放、数据分析和数据服务。它的特性就是可以把Doris的Hive当作数据源引入进来,把BMR的计算引擎当作计算资源引入进来。
-
提供了一个低门槛的开发方式,在开发的过程当中不需要写代码,通过拖拉组件就可以完成。
-
非常安全可靠,在这个平台内所有的操作都是通过审计日志的,表的访问也都是有授权的。
-
非常开放兼容,除了能够对接百度的Doris、Hadoop,还能够对接市面上其他厂商开源的Hadoop生态。
数据源配置

在EasyDAP进行数据开发的过程当中,第一步就是要把原始数据引入到数仓里面,在平台上创建一个计算资源,然后再把源MySQL的JDBC配置好,把目标的Hive JDBC配置好,就可以完成一些基础的操作。从权限上来讲,这些操作都应该是管理员来操作的,开发人员进来之后只需要进行开发就行,由管理人员来进行这些基础的配置。
数据开发阶段

把以上基础配置好之后就进入数据开发阶段。首先创建开发项目,然后绑定项目需要使用的资源,最后需要把开发人员进行授权管理。
编写数据集作业,数据写入Hive ODS库表中
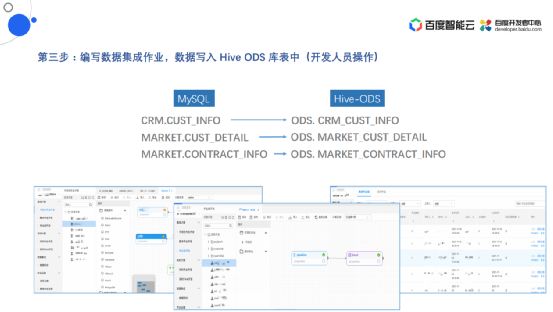
把基础的管理相关的工作做完之后,就是实际开发人员进入平台进行ETL开发。图中的例子里想要把MySQL里面的数据集成到Hive里,第一步就是要把MySQL里面的原始数据放入到Hive的ODS层。
举例说明:MySQL里面有两个库,一个是CRM库,一个是MARKET库,CRM库里面有一种表是客户基本信息(CUST_INFO),MARKET库里面也有一种表是客户明细信息(CUST_DETAIL),同时MARKET库里面还有合同信息(CONTRACT_INFO)。在Hive里面的话就是按照Hive的命名规范,原始库名+原始系统名+原始表名。
加工的过程当中,可以有几种加工模式,第一个用可视化开发工具,第二用脚本开发。
线上监控以及告警处理

配置调动实际上就是来执行异常告警,失败重做,以及日常的日志排查,同时也支持手工的执行。
Hive仓内开发

把原始数据库里的数据写入到Hive的ODS层后,需要在Hive里面做仓内开发,也就是要把数据从ODS层写入DWD层写入DWA层,因为Hive支持丰富的数据生态,所以使用HQL来实现。
左边这张图,ODS中有三张表,在加工进入DWD中是要把两个客户的基本信息做统一,写入到DWD的客户主题下的信息表,然后销售合同里面的合同信息在主题域里面认为是一个订单,所以在事件主题下面有一个订单表。
加工好了之后就要做汇总层,其中包括天级、月级、季级和年级。
写入Doris

到了DWA之后,下一步要写入Doris,在DWA和DMA里面其实只是做数据的转储,目标是为了响应实时的数据查询。只需要将数据源选择Hive,将数据目标选择Doris,然后把图配好之后,就可以把数据生成了,也可以使用底层脚本的方式,使用Doris的命令也可以把Hive里面的数据写入Doris里面。