算法——C++语法积累
搞计算机视觉必须要用C++吗,Python 不行么?
计算机视觉~~~
请问计算机视觉方向对C++的掌握需要到什么程度?
c++中STL库 简介 及 使用说明
C++中STL用法超详细总结
20201016
- 队列
#include
20201018
- 向量
https://blog.csdn.net/msdnwolaile/article/details/52708144
20201019
- 引用
引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
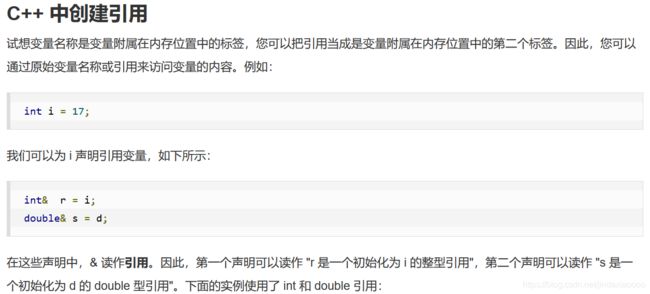 引用作为函数参数
引用作为函数参数
C++之所以增加引用类型, 主要是把它作为函数参数,以扩充函数传递数据的功能。
C++ 函数传参:
(1)将变量名作为实参和形参。这时传给形参的是变量的值,传递是单向的。如果在执行函数期间形参的值发生变化,并不传回给实参。因为在调用函数时,形参和实参不是同一个存储单元。// 同 c
(2) 传递变量的指针。形参是指针变量,实参是一个变量的地址,调用函数时,形参(指针变量)指向实参变量单元。这种通过形参指针可以改变实参的值。// 同 c
(3) C++提供了 传递变量的引用。形参是引用变量,和实参是一个变量,调用函数时,形参(引用变量)指向实参变量单元。这种通过形参引用可以改变实参的值。
#include 当上面的代码被编译和执行时,它会产生下列结果:
交换前,a 的值: 100
交换前,b 的值: 200
交换后,a 的值: 200
交换后,b 的值: 100
- 形参:
在函数声明中,参数的名称并不重要,只有参数的类型是必需的,因此下面也是有效的声明:
int max(int, int);
- 创建树
//Definition for a binary tree node.
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
TreeNode* root=new TreeNode(2);
- C++向量的长度
vector<int> nums;
nums.size();
20201019
- 递归
递归解决的问题必须满足两个条件:
1、可以通过递归调用来缩小问题规模,且新问题与原问题有着相同的形式。
2、存在一种简单情境,可以使递归在简单情境下退出。
如果一个问题不满足以上两个条件,那么它就不能用递归来解决。
//C++
/**
1. Definition for a binary tree node.
2. struct TreeNode {
3. int val;
4. TreeNode *left;
5. TreeNode *right;
6. TreeNode() : val(0), left(nullptr), right(nullptr) {}
7. TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
8. TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
9. };
*/
class Solution {
public:
int minDepth(TreeNode* root) {
if(!root) return 0;
if(minDepth(root->right) && minDepth(root->left)) return min(minDepth(root->right),minDepth(root->left))+1;
return max(minDepth(root->right),minDepth(root->left))+1;
}
}
上面的程序用递归的方法求二叉树的最小深度,其中存在错误 :
- 递归本身不要作为条件
if(minDepth(root->right) && minDepth(root->left))
改为:
if(root->right && root->left)
- || 逻辑符号取或:
1 || 0 =1 ;
0 || 1 =1;
0 || 0 =0;
1 || 1=1;
20201027
vector 详解
20201029
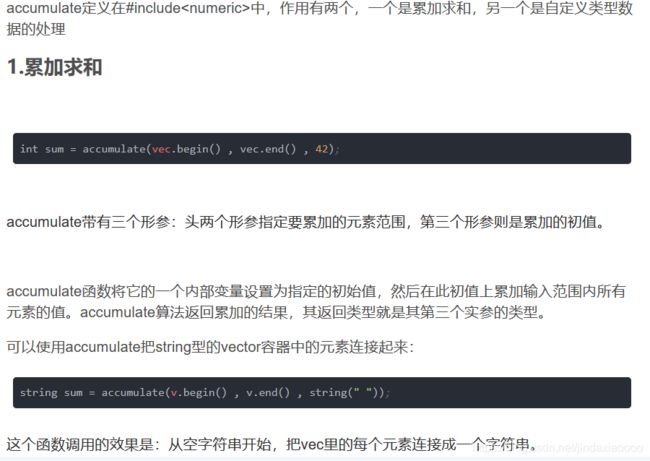
C++中accumulate的用法
20201103
vector 创建数组
c++ 创建数组
#include20201104
| 1、vector |
定义了一个vector容器,元素类型为vector,初始化为包含n个vector对象,每个对象都是一个新创立的vector对象的拷贝,而这个新创立的vector对象被初始化为包含n个0。
| 2、打印二位数组 |
错误:C2679 二进制“<<”: 没有找到接受“std::vector
改正:
for(auto temp:res) {
for(auto i:temp) {
cout << i<<" ";
}
cout<<endl;
}
| 3、有关数组的知识点 |

- 暴力解题 不一定时间消耗就非常高,关键看实现的方式,就像是二分查找时间消耗不一定就很低,是一样的。
- 很多同学会以为二维数组在内存中是一片连续的地址,其实并不是。所以二维数据在内存中不是 3*4 的连续地址空间,而是三条连续的地址空间组成!

- 「真正解决题目的代码都是简洁的,或者有原则性的」
20201109
| 1、链表的五种操作:增、删、查、改 |
#include注:C++变量前面加下划线和不加下划线都不会影响对变量的定义,只是风格问题,更喜欢将成员变量或者私有成员变量的前面加上下划线
20201110
| 1、反转链表 |
双指针法:
#include20201113
求入环节点
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode*> tmp;
while (head) {
if(tmp.count(head)) return head;
tmp.insert(head);
head=head->next;
}
return nullptr;
}
};
20201113
题意:给定两个数组,编写一个函数来计算它们的交集。
我的答案:
vector<int> Solution::intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> record;
vector<int> record1;
for (int i = 0; i < nums1.size(); i++) {
if (!record.count(nums1[i]))
record.insert(nums1[i]);
}
for (int i = 0; i < nums2.size(); i++) {
if (record.count(nums2[i])&& !count(record1.begin(), record1.end(), nums2[i]))
record1.push_back(nums2[i]);
}
return record1;
}
标准答案:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
//nums_set.find(num) != nums_set.end()代表num在nums_set中
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
std::find()函数使用方法
20201116
| 1、命名 |
| 2、整型 |
- 整数:就是没有小数的数字
- 宽度:存储整数时使用的内存量,使用内存越多,越宽
- 按宽度递增:char,short(short int),int,long(long int),都有unsigned,signed(可表正负)之分,无符号类型:unsigned short change =10;
- 位:计算机内存的基本单元是位(bit),如8位内存块可以有2222222*2=266种组合方式,所以可以表示0~255或者-128 ~ 127
- 字节:计算机内存量的度量单位
1 字节 = 8 bit (通常是这样的,但是不同的系统会不一样)
1KB = 1024 字节 - sizeof() :返回类型或者变量的字节数 ,单位为字节
- 在对变量进行初始化的时候,最好将赋值和声明放在一起,要不然会带来瞬间悬而未决的问题
int aunt =5; - 符号常量——预处理器方式
#define INT_MAX 32767
#define 预处理器编译指令 - 3中不同的计算方式
基数为10:第一位为1-9;
基数为8:第一位为0,第二位为0-7;
基数为16:前两位为0x,0X; - 在默认情况下:cout以十进制格式显示整数
cout<- 后缀是放在数字常量之后的字母:186L,被储存为long,占32位
- 输入输出字符
char M;
//输入时,将输入的字符转换成数字
cin>>M;
//输出时,将M转换成字符
cout<<M;
- c++ 对字符用单引号,对字符串用双引号
- cout.put()
通过iostream类的对象cout来使用成员函数put()
put() 是iostream的一个成员函数
‘.’代表成员操作符
| 3、返回向量 |
return [-1,0]
而是:
return {-1,0}
| 4、利用map求两数之是否等于目标值 |
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map <int,int> map;
for(int i = 0; i < nums.size(); i++) {
auto iter = map.find(target - nums[i]);
if(iter != map.end()) {
return {iter->second, i};
}
map[nums[i]]=i;
}
return {};
}
};
20201119
| 1、const 限定符 |
| 2、float |
C、C++对有效位的要求:
float至少32位
double至少48位
| 3、算术操作符 |
操作符重载:使用相同的符号进行多种操作叫做操作符重载。
9/5 int除法
9L/5L long除法
9.0/5.0 double除法
9.0f/5.0f float除法
| 4、类型转换 |
不过将值赋给范围更小的类型可能出现问题。
将浮点值赋给整数值,小数部分消失,原来的值可能超出目标类型的取值范围,结果将是不确定的
将0赋给bool类型变量,将被转换成false,而非零值则为true、
2、表达式中的转换
在同一个表达式中出现两种类型,将会是什么情况:
自动转换:
C++会将bool,char,unsigned char,signed char,short的值转换成int,这种转换叫做整型提升
short a=1;
short b=2;
short c=a+b;
执行第三条语句的时候会先将a,b转换成int型,再将加法结果转换成short型。
为什么要先把a,b转换成int型呢?因为int型是计算机最自然的类型,使用int型,计算速度最快
不同类型进行计算:
int和float进行相加,较小的类型会被转换成较大的类型。
3、强制类型转换
可是使用下面表示中的一种
(long)thorn;
long (thorn);
ststic_cast (thron)
| 5、判断数组元素是否都为0 |
这种方法是错的。
array==0
要利用遍历的方式:
for (int i = 0; i < 26; i++) {
if (array[i] != 0) {
return false;
}
}
20201120
| 1、字符串 |
C-风格字符串: 将字符串储存在char数组中,以空字符(null)结尾,空字符被写作“\0”。
1、字符串的输入
char dog[5]={'a','b','c','d','e'} //不是字符串
char fish[5]={'a','e','d','c'} //是字符串
char bird[10]="jijijij";
char fish[]="jijijiji";
char size='s';
char size="S"; //“s”表示的是两个字符‘s’,'\0',“s”表示的实际上是字符串所在的内存地址,由于地址在C++中是一种独立的类型,因此C++编译器不允许这种不合理的做法。
2、字符串的长度
cout<<sizeof(fish); //结果为5,指出整个数组的长度
cout<<strlen(fish); //结果为4,指出可见字符串的长度
3、cin的缺陷
cin 是使用空白(空格、制表符、换行符)来定字符串的界
要防止输入的字符串可能比目标数组长
20201124
| 1、结构 |
结构是一种比数组更灵活的数据结构,结构也是C++ OOP堡垒(类)的基石。
结构是用户定义的类型,而结构声明定义了这种类型的数据属性。
创建结构分两步:
- 1、定义结构描述
struct inflatable
{
char name[20]; //支持string吗?大部分编译器是支持的,如果不支持,就在前面加上std。std::string
float volume;
double price;
};
- 2、按描述创建结构变量:
inflatable hat; //C++允许在声明结构变量时省略关键字struct
inflatable woopie_cushion; //结构标记的用法与基本类型名相同,结构声明定义了一种新类型
inflatable mainframe; //由于hat的类型为inflatable,因此可以使用成员操作符(.)来访问各个成员。如:hat.volume
可以同时完成定义结构和创建结构变量的工作,为此,只需将变量名放在结束括号的后面即可:
struct perks{
int key,
char car[120]
} mer_smith,ms_jones;
struct perks{
int key,
char car[12]
} mr_smith={
7,
"packard"
};
struct { //声明没有名称的结构,不推荐
int key,
char car[120]
} mer_smith,ms_jones;
- 初始化:
inflatable guest={
"Glorious Gloria",
1.88,
29.99
}; //也可以直接放在一行中,用逗号隔开就行
- C++使用户定义的类型与内置类型尽可能相似:
比如:
可以将结构作为参数传递给函数,也可以返回一个结构
可以将一个结构赋值给另一个同类型的结构,这种赋值叫成员赋值
以上所讲的结构特性,C和C++都有,但是C++除了成员变量之外,还可以有成员函数
- 结构数组:
结构中可以包含数组,也可以创建元素为结构的数组:
struct inflatable
{
char name[20];
float volume;
double price;
};
inflatable gift[20]={
{"jing",0.2,21.22},
{"jinkk",0.3,24.22}
}; //数组的类型为结构
| 2、共用体 |
共用体是一种数据结构,它能够储存不同的数据类型,但是只能同时存储其中的一种类型。
union one4vall{
int int_val;
long long_val;
double double_val
};
one4vall pail;
pail.int_val=15; //只能一次使用一种
cout<<pail.int_val;
pail.long_val=12.2;
cout<<pail.long_val;
//共用体的用途就是当数据项使用多种格式(但是不会同时使用)时可以节省空间
struct widget{
char brand[20];
int type;
uniom id{
long id_num;
char id_char;
}id_val;
};
widget prize;
if(prize.type==1)
cin>>prize.id_val.id_num;
else
cin>>prize.id_val.id_char;
//匿名共用体没有名称,其成员位于相同的地址处的变量
struct widget{
char brand[20];
int type;
uniom id{
long id_num;
char id_char;
};
};
widget prize;
if(prize.type==1)
cin>>prize.id_num;
else
cin>>prize.id_char; //id_num和id_char是prize的两个成员,它们的地址相同,所以不需要中间标识符id_val
| 3、枚举 |
enum spectrum {red,orange,yellow,green,blue,violet,indigo,ultraviolet}; //spectrum 称为枚举,red,orange,yellow,green,blue,violet,indigo,ultraviolet 为枚举量
spectrum band;
band = blue;
band = 10; //invaild
//枚举没有算术运算
band = orange;
++band; //invalid
band = orange+red; //invalid
//枚举量是整型,可被提升为int类型,但是int类型不能自动转化为枚举类型
int color = blue;
band=3; //invaild
band = spectrum (3); //vaild
color = 3+red;
//设置枚举量的值
enum spectrum {red=0,orange=1,yellow=2,green=8}; //指定的值一定得是整数
enum spectrum {red,orange=100,yellow}; //red 默认为0,yellow为102
enum spectrum {red,orange=0,yellow,green=1}; //枚举量可以相等,red=0,yellow=1
//枚举的取值范围
//取值范围定义:上限为大于枚举量最大值(8)的最小的2的幂减去1===》 2^4 是大于8的最小的2的幂,上限为16-1=15
//下限:如果枚举量最小为0,则下限为0;否则和找上限一样,比如枚举量最小值为-6,则下限为-(2^4-1)=-7
enum spectrum {red=0,orange=1,yellow=2,green=8};
spectrum myflag;
myflag = spectrum (6); //vaild,因为6在spectrum 的范围内
| 4、指针和自由储存空间 |
指针是一种特殊类型的变量,储存的是变量的地址而不是变量本身,用&home 可以获取home变量的地址
指针名表示的是地址,*操作符称为间接值或解除引用操作符,将其应用于指针,可以得到该地址处存储的变量的值
指针变量也是储存在地址中的,如下图:ducks四个字节后,储存briddog,指向储存ducks变量的地址,值为1000(只是对象存储地址的开始)
指向不同类型变量的指针的长度通常是相同的,就好比1068可能是农村街道的地址也有可能是城市街道的地址,地址的长度并不能指示关于变量长度或者类型的任何信息。
int* p_fellow;
int fellow = 3;
p_fellow = &fellow;
cout << sizeof(fellow) << endl; //4
cout << sizeof(p_fellow) << endl; //4
- 声明和初始化指针:
int updates=6;
int *p_updates; //指针声明的时候必须指定指向的数据的类型,所以说p_updates的类型是指向int的指针或者int*,int* p_updates,int *p_updates两种形式都可以。
int* p1,p2; //创建指针变量p1,和int变量p2
p_updates=&updates;
*p_updates=*p_updates+1; //updates=7
- 指针的危险:
指针变量在使用操作符*之前,必须初始化指针变量为一个确定的、适当的地址。这是关于指针使用的金科玉律。
int* p_fellow;
*fellow = 23333; //这种写法是错误的,程序并没有告诉p_fellow导致指向哪里,你就改变p_fellow指向地址要储存的值
- 指针和整数
指针并不是整数,虽然系统会常常把指针当做整数处理,从概念上来看指针和整型是完全不同的类型。
整数可以加减乘除,但是地址相乘并没有任何意义。
因此不能简单的将整数赋给指针
int *pt;
pt = 0xB8000000; //系统并没有告诉说0xB8000000是地址,C语言允许这样的赋值方法,但是C++不允许
pt = (int*)0xB8000000; //经过强制转换就可以
- 使用new来分配内存
面向对象编程和面向过程编程的区别在于,OOP强调的是在运行阶段(而不是编译阶段)进行决策。
编译阶段:
编译器将程序组合起来时,好比必须按照预先决定的日程安排。
运行阶段:
程序正在运行时,好比度假,可以根据当天的天气和其他情况来决定玩什么,这样更具有灵活性。
比如为数组分配内存。要在C++中,声明数组时必须先指定数组的长度,这个是编译阶段的决策。但是有时会造成内存的浪费,OOP会将指定数组长度的决策推迟到运行阶段进行,这次可以告诉它只需要20个元素,下次就可以告诉它需要205个元素。
C++采用的方法是使用关键字new请求正确数量的内存以及使用指针来跟踪分配的内存的位置。
new操作符:
程序员要告诉需要为哪种数据类型分配内存,new将找到一个长度正确的内存块,并返回该内存块的地址,接下来将地址赋给指针变量。
int* pn;
pn = new int;
int higgens;
int* pt = &higgens;
pt指向higgens
pn指向为int数据项分配的内存块,在管理内存方面有更大的控制权
为一个数据对象(可以结构或者基本类型)获得并制定分配内存的通用形式
typename pointer_name = new typeName;
-
内存被耗尽
计算机可能会因为没有足够的内存二无法满足new的请求,这种情况下new可能会返回0,在C++中值为0的指针被陈伟空值指针(null point)
除了会返回0,也有可能会造成bad_alloc异常 -
使用delete来释放内存
当需要内存时,可以使用new来请求
当使用完内存,要把内存归还给内存池时,使用delete,归还的内存可供程序的其他地方使用,程序格式为delete+指向内存块的指针
int* pn;
...
delete pn; //会释放pn指向的内存,但是不会删除pn本身
注:
delete一定要和new配套使用,也就是说智能用delete释放new请求的内存,不过对于空指针,用delete是安全的
不要尝试用delete释放已经释放的内存,否则结果将不可预知
不要使用delete释放声明变量所获得的内存
delete是用于释放new请求的内存,并不是用于指向内存的指针
int* pn = new int;
int* ps = pn;
delete ps;
以上的程序已经把new请求的内存释放了,没有必要再delete pn。
在以后的编程过程中要避免创建两个或者多个指向同一个位置的指针,从而避免重复删除内存
- 使用new来创建动态数组
对于小型数据,声明一个简单变量会比new的指针更简单
但是对于大型数据(数组、字符串、结构等),应该用new,这正是new的用武之地
如果通过声明来创建数组,则在程序编译时给数组分配内存,这叫静态联编,不管数组用不用,他都会占用内存。
使用new来为数组请求内存,是在程序运行阶段给数组分配内存,这叫动态联编,这种数组叫动态数组
1、如何用new创建动态数组
int* pn = new int[10]; //pn是指向数组第一个元素的指针
//使用结束时,要是用delete释放内存
delete [] pn; //记得带[],要和new保持一致
2、如何用指针访问数组
int* pn = new int[10]; //pn指向的是数组的第一元素,*pn表示第一个元素
如何用指针访问数组?只要把指针当做数组名使用就行。
也就是说访问第一个元素用 pn[0] ,访问第二个元素用 pn[1]…
可以这样做的原因是,在C和C++内部都是用指针来处理数组,数组和指针基本等价是C 和 C++基本等价的优点之一
int* pn = new int[3];
pn[0]=0.2;
pn[1]=0.5;
pn[2]=0.8;
cout<<pn[1]; //0.5
pn = pn+1;
cout<<pn[0]; //0.5
cout<<pn[1]; //0.8
pn = pn-1;
delete pn;
这里非常值得注意的是 为什么 pn+1 之后,pn[0]会变成0.5呢?
分析:
pn是指向数组第一个元素的指针,指针是变量,所以可以改变它的值,pn + 1 代表指针算术,指针算术的特别之处在于 pn + 1 并不代表pn 所指的元素的地址加一,而是指向数组的第二个元素,再之后减去1之后,又会指向数组的第一元素。
将指针加1,增加的量等于它指向的类型字节数
20201125
| 1、指针、数组、指针算术 |
- 指针、数组
指针算术:将指针加1,增加的量等于它指向的类型字节数
C++将数组名解释为数组的第一元素的地址,对于数组表达式a[1],C++编译器将此表达式看做*(a+1)
pointname = pointname +1;
arrayname = arrayname +1; //invaild,因为数组名是常量,不能修改
double wages[3]={1,2,3};
double* pw = wages;
sizeof(wages); //数组的长度:24=3*8,这里不会把数组名解释为地址
sizeof(pw); //指针的长度:4
- 指针和字符串
在cout和多数C++的表达式中,char数组名,指向char的指针,用双引号括起的字符串常量都被解释为字符串的首字母的地址
char flower[7] = "jingui";
char* pn = flower;
//显示字符串
cout << flower << “is a gril.”<<endl;
cout << pn << endl;
//显示字符串地址
cout << (int*)flower << “is a gril.”<<endl;
cout << (int*)pn << endl;
//获取字符串副本 函数strlen、strcpy 位于头文件cstring中
pn = new char[strlen(flower)+1]; //strlen(flower) 返回字符串长度(不包括尾部的空字符),pn获取新地址
strcpy(pn,flower); //strcpy将字符串从flower指定的地址赋值到pn指定的地址,并不会改变flower的地址或者字符串的内容,只是让pn所指定的地址获得内容
cout<<pn; //jingui
cout<<flower;//jingui
cout<<(int*)pn; //0x0065fd30
cout<<(int*)flower; //0x004301c8
//c-风格的字符串,将字符串赋给数组要用strcpy;但是c++string类型的字符串更简单,直接用赋值操作符=就行
strcpy(flower,"ggg"); //flower 变成“ggg”
- 使用new创建动态结构
结构和数组一样,在运行阶段创建数组由于在编译阶段创建数组
由于结构和类非常相似,所以本小节介绍的有关结构的内容同样适合类
使用new创建一个未命名结构,并访问成员:
struct inflatable{
char name[20];
float volume;
double price;
};
//创建
inflatable* ps = new inflatable;
inflatable hat;
//访问
cin.get(ps->name,20);
cin.get(hat.name,20);
cin>>(*ps).volume;
- 自动储存、静态储存、动态储存
1、自动储存
函数内部定义的常规变量,被称为自动变量,它是一个局部变量。仅当函数活动时存在,函数不活动的时候,自动变量使用的内存将被自动释放。
2、静态储存
静态储存是在整个程序执行期间都存在的储存方式。是变量成为静态储存的方式有两种:
在函数外面定义它,
声明变量使用static
自动存储和景甜储存都严格限制了变量的寿命。
3、动态储存
new、delete管理了一个内存池,在c++中被称为自由储存空间。new、delete允许在一个函数中分配内存,在另外一个函数中释放它。这样变量的生命周期就不完全受到程序或函数的生命时间的控制了。对内存有更大的控制权。
- 堆栈、堆、内存泄漏
内存泄漏:
使用new在自由储存空间(或堆)上创建变量,但是并没有使用delete释放内存,将会导致什么呢?
即使指针的内存由于作用于规则和对象生命周期的原因而被释放,在自由储存空间上动态分配的变量或者结构都将继续存在。又因为指向这个内存的指针无效就导致无法访问这自由储存空间上的变量和结构。这就会导致内存泄漏。别泄漏的内存将在程序的整个生命周期内都不可使用,这些内存被分配出去,但是无法收回。
在严重的情况下,虽不常见,内存泄漏可能导致应用程序内存被耗尽,导致程序崩溃,也可能导致在同一内存空间中运行的应用相应奔溃。
要避免内存泄漏,就要养成同时使用new和delete的好习惯。
指针是C++中的强大工具,但也是最危险的。要不断熟悉它才能更好的使用它。以免对系统造成不友好的影响。
复习题错误整理(page 109):
//第六题
struct fish{
char kind[]; //错误,声明的时候要指定数组的长度,改成char kind[20],只有char a[]="jijiiji"才可以不写,因为计算机可以自动识别
int weight;
float length;
};
//第八题
enum Response={No,Yes,Maybe}; //错误,不要写等号
//第十一题
int a; //a 是正整数,所以类型为unsigned int
第十四题:
cin>>a 将是程序跳过空白,直到找到非空白字符为止,然后它将读取字符,直到遇到空白字符为止
同时它也跳过字符输入后的换行符

第五章
20201126
<< 的优先级高于< ,>,所以要加括号
cout<<(2>4)<<endl; //显示0
cout.self(ios_base::boolalpha);
cout<<(2>4)<<endl; //显示false
for 循环
| 1、for循环 |
设置初始值
执行测试表达式,看看循环是否应当继续进行
执行循环操作
更新用于测试的值
注:
C++并没有将测试表达式的值限定为只能为真或者为假,可以使用任何的表达式,C++将把结果强制转换为bool类型,因此值为0的表达式将被转换为false;
for是入口循环,在每次循环之前会判断测试表达式为真或者为假;
for是C++关键字,因此编译器不会将for视为一个函数,for是c++关键字,命名要防止和for重名。
| 2、表达式与语句 |
C++表达式是值或值与操作符的组合,每个C++表达式都有值
22
x=20
//从表达式到语句的转变很小,只要加一个;就行
20;
x=20;
对任何表达式加上分号都可以成为语句,但是反过来任何语句中删除分号,并不一定成为表达式
下面是一条语句:
int road;
但是int road 却不是表达式,因为它没有值,因此下列语句非法:
eggs=int road * 100;
cin>>int road;
同样不能把for循环赋给变量:
int fx = for(int i=0;i<4;i++);
C++循环允许像下面这样做:在初始化部分声明变量
for(int i=0;i<5;i++){
//循环体
}
- 副作用和顺序点
副作用:计算表达式时对某些东西(如储存在变量中的值)进行了修改;
顺序点:程序执行过程中的一个点,在进入下一步之前将确保对所有的副作用都进行了评估。在C++中,语句的分号就是一个顺序点,这意味着程序处理下一条语句之前,赋值操作符、递增操作符和递减操作符执行的所有修改都必须完成。另外,任何完整表达式的例子末尾都有一个顺序点。
请看一下代码:
while(guests++<10){ //guests++<10因为是while循环的测试条件,因此是一个完整的语句,副作用guests加1在程序进入printf()之前完成。
printf("%d \n",guests);
}
| 3、前缀格式和后缀格式 |
下面两个语句对for语句的作用是一样的,但是前缀格式的效率比后缀格式更高,一般都是用前缀格式。
for(int i = 0;i<5;i++)
for(int i = 0;i<5;++i)
| 4、递增、递减操作符和指针 |
*++pt; //前缀递增(++i)、前缀递减(i--)、解除引用操作符的优先级相同,以从右到左结合:先将++应用于pt,再将*应用于被递增后的pt
++*pt; //先取得pt指向的值,再把这个值加1
(*pt)++; //先算括号里面的
//后缀递增、后缀递减优先级相同,但是前缀操作符的优先级高,后缀递增、后缀递减从左到右的方式进行结合
*pt++; //先后缀,再指向
| 5、组合赋值操作符 |
L+=R; // L=L+R;
L-=R; // L=L-R;
L*=R; // L=L*R;
L/=R; // L=L/R;
L%=R; // L=L%R;
| 6、复合语句(语句块) |
(复合语句)代码块由一对花括号和它们包含的语句组成,被视为一条语句。
复合语句还有一种有趣的特性。如果在语句块定义一个新的变量,则仅当执行该语句块中的语句时,该变量才存在,执行完该语句时,变量将别释放。
int main(){
int x=0;
{
int y=1;
}
cout<<y; //将会提示y没有被声明
}
| 7、逗号操作符 |
逗号操作符允许将两个表达式放在C++句法只允许放一个表达式的地方
int i=0,j=0;
i++,j++;
i=20,j=2*i; //确保先计算第一个表达式、再计算第二个表达式,换句话说,逗号操作符是一个顺序点
//逗号表达式的值是第二个表达式的值
//逗号操作符的优先级是最低的
cata = 17,240;
(cats=17),240; //和上面的式子等同,cats被赋值17
cats = (17,240); //cats被赋值为括号右边的值
关系表达式
计算机不只是机械的数字计数器。它能够对值进行比较,这种能力是计算机决策的基础。
C++提供了六种关系操作符:
<
>
<=
>=
!=
== //不要混淆==和=,不要用=来比较两个量之间的大小
关系操作符的优先级低于算术操作符,意味着:
x+2 > y+1;
(x+2) > (y+1);
20201204
| 1、c-风格字符串的比较 |
word 是数组名,要判断word字符数组中的字符串是不是“mate”,下面的测试效果并不能像预期的效果一样
word == "mate"
word是数组名,代表的是字符数组的第一个元素所在的地址,“mate”表示的也是字符串的首地址,上面的式子只是判断两个字符串的首地址是否相同,所以无法用关系操作符来比较两个字符串,应使用c-风格字符串库中的strcmp()函数来比较。该函数接受两个字符串的地址作为参数:
strcmp(str1,str2)==0; //str1、str2相同
strcmp(str1,str2)!=0; //str1、str2不相同
strcmp(str1,str2)<0; //str1在str2前面
strcmp(str1,str2)>0; //str1在str2后面
| 2、比较string类字符串 |
string word = "mate";
if(word == "mate")
{
print("the same word!")
}
| 3、while:编写延时循环 |
#includeclock_t 是clock()函数返回类型的别名
c++为类型创建别名的两种方式:
#define BYTE char //使用预处理器的方式创建别名
typedef char byte; //typedef 建立别名
使用原始的cin进行输入
cin将忽略空格和换行符
发送给cin的输入被缓冲,意味着只有用户在按下回车键后,他输入的内容才会被发送给程序
char ch;
int count = 0;
cout << "enter char:\n";
cin >> ch;
while (ch != '#') {
cout << ch << endl;
++count;
cin >> ch;
}
cout << endl << count << " end\n";
enter char:
it is good#yes
itisgood //忽略空格,空格并没有回显
8 end //没有把空格计入
cin.get()
读取输入的每个字符,包括空格、制表符、换行符,并回显每个字符
char ch;
int count = 0;
cout << "enter char:\n";
//cin >> ch;
cin.get(ch);
while (ch != '#') {
cout << ch;
++count;
//cin >> ch;
cin.get(ch);
}
cout << endl << count << " end\n";
enter char:
jin gui lin# is good
jin gui lin
11 end
函数重载:同样的函数名但是功能不一样
因为cin.get() 接收的参数不一样,所以下面一共有三个版本
char name[10];
char age;
cin.get(name,10);
cin.get(); //在下面的cin.get(age)之前要加个cin.get()读取输入name最后的回车符
cin.get(age);
cout<<name<<endl;
cout<<age<<endl;
jinguilin
2
jinguilin
2
文件尾条件
怎么表示输入结束呢?
上面的程序是用“#”符号来表示输入结束,但是有这样做的问题是,有可能“#”符号是文件中的合法输入部分。
有另一种功能更加强大的技术——检测文件尾(EOF)。
很多操作系统都允许通过键盘来模拟文件尾条件:
在LINUX系统,可以在行首按下Ctrl+D来实现;
在windows系统,可以在按下Ctrl+D和回车键来实现
char ch;
int count = 0;
cin.get(ch);
while (!cin.fail()) { //检测键盘输入Ctrl+D和回车cin.fail()就为true
cout << ch;
++count;
cin.get(ch);
}
cout << count << endl;
jin gui lin
jin gui lin
is good girl
is good girl
^Z
25
二维数组初始化:
char cities[2][3]={
"ji",
"gu"
};
20201217
| 1、C++内联函数 |
常规函数调用是跳到函数起点的内存单位,执行函数代码,然后又回到函数调用处
内联函数提供了另外一选择。内联函数的编译代码和其他程序的代码内联起来了,所以无需跳到另外一个地方再跳回来,这样运行速度可以提升,但是要占用更多的内存
要使用这项特性,必须采取一下措施之一:
1、在函数声明之前加上关键字 inline
2、在函数定义前面加上关键字inline
inline是C++新增特性
| 2、引用变量 |
创建引用变量:
int b=10;
int &a=b; //a 和 b 可以互换,因为他们指向相同的值和内存单元
&并不是地址操作符,而是类型标识符的一部分,就像声明中的char* 中的*一样
int& 表示指向int的引用
#include10==10
11==11
010FFC70==010FFC70
引用和指针的区别:
int a;
int&b;
b = a; //引用不能像指针一样先声明再赋值
将引用用作函数参数:
#include输出:
20 10
10 20
如果想把引用作为函数的参数,又不想在函数里面对参数进行修改,可以在函数原型和函数头中使用const
void charge2(const int& a, const int& b)
如果编译器发现代码修改a,b的值,就会报错
如果形参是引用变量,则实参得是变量,不能是表达式:
charge2(a+1, b+3); //编译器会发出警告
20210225 :数据结构的一些基础
NULL在C++中就是0,这是因为在C++中void* 类型是不允许隐式转换成其他类型的,所以之前C++中用0来代表空指针,但是在重载整形的情况下,会出现上述的问题。所以,C++11加入了nullptr,可以保证在任何情况下都代表空指针,而不会出现上述的情况,因此,建议以后还是都用nullptr替代NULL吧,而NULL就当做0使用。
————————————————
版权声明:本文为CSDN博主「csu_zhengzy~」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_18108083/article/details/84346655
栈里面可以放这种pair结构
pair
bool hasPathSum(TreeNode* root, int targetSum) {
if(!root) return false;
stack<pair<TreeNode*,int>> stack;
stack.push(pair<TreeNode*,int>(root,targetSum-root->val));
while(!stack.empty()){
pair<TreeNode*,int> node = stack.top();
stack.pop();
if(!node.first->left && !node.first->right && node.second==0) return true;
if(node.first->left){
stack.push(pair<TreeNode*,int>(node.first->left,node.second - node.first->left->val));
}
if(node.first->right){
stack.push(pair<TreeNode*,int>(node.first->right,node.second - node.first->right->val));
}
}
return false;
}
这样写是正确的,
string str;
str+=to_string(1);
double sum = 0; //编辑器可以自动把0转换为double类型
int size = 32;
sum = sum/size; //size可以使整数
unsigned int 0~4294967295
int -2147483648~2147483647
unsigned long 0~4294967295
long -2147483648~2147483647
long long的最大值:9223372036854775807
long long的最小值:-9223372036854775808
unsigned long long的最大值:18446744073709551615
__int64的最大值:9223372036854775807
__int64的最小值:-9223372036854775808
unsigned __int64的最大值:18446744073709551615
————————————————
版权声明:本文为CSDN博主「小威学长」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gotowu/article/details/51203920
bool static camp(const pair<int,int>& a,const pair<int,int>& b){
return a.second>b.second; //从大到小排列
} //camp 函数在类中定义,要加static
vector<pair<int,int>> vec(map.begin(),map.end());
sort(vec.begin(),vec.end(),camp);
camp 函数为什么要加static
数组定义,初始化
in record[26] = {0};
record.size() //大小
向量初始化,添加元素:
vector<int> myvector;
vector<int> myvector(k); //定义大小为k的向量
myvector.push_back(1);
vector<vector<int>> result;
result.insert({1,2,3});
sort(myvector.begin(),myvector.end()); //排序
result.size() //大小
1、pop_back()
---- 向量容器vector的成员函数pop_back()可以删除最后一个元素.
---- 而函数erase()可以删除由一个iterator指出的元素,也可以删除一个指定范围的元素。
---- 还可以采用通用算法remove()来删除vector容器中的元素.
---- 不同的是:采用remove一般情况下不会改变容器的大小,而pop_back()与erase()等成员函数会改变容器的大小。
#include 0
60
2、erase()
会减小容器的容量。迭代器用于erase删除元素后,其后会失效,即不能再用该迭代器操作向量。
#include ————————————————
3、remove() 不建议使用
#include 
集合初始化,添加元素,查询:
set<int> record;
record.insert(1);
if(record.find(num)!=record.end()){};
map定义,添加,查询:
std::unordered_map<int,int> result_map;
result_map[nums[i]] = i; //result_map.insert({nums[i],i});
if(result_map.find(num)!=result_map.end()){};
//得到value
result_map.find(num)->second
result_map[num]
字符串:
字符串的长度:string.length() ,string.size() s.resize(s.size()+2*count) //扩容
定义变量记得初始化为0
string result=""; //初始化字符串
result+='a';
class Solution {
public:
string replaceSpace(string s) {
//字符串就是数组,数组的增删很难,应该怎么解决这个问题
//答案是先扩容到替换后的数组大小,那要怎么确定扩容后数组的大小
int count=0; //记得初始化,要不然会出错
for(int i=0;i<s.size();i++){
if(s[i]==' ') count++;
}
s.resize(s.size()+2*count);
for(int i=s.size()-1-2*count,j=s.size()-1;i>=0;i--,j--){
if(s[i]!=' ') s[j]=s[i];
else {
s[j--]='0';
s[j--]='2';
s[j]='%';
// j=j-2;
}
}
return s;
}
};
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词,用array
哈希值太大了,还得用set
找出四个不同的数组的元素相加等于0的情况:map
数字和字母相乘,不能直接相乘2k,要加* 2*k
c.begin(); 返回指向容器 最开始位置数据的指针
c.end(); 返回指向容器最后一个数据单元+1的指针
如果我们要输出最后一个元素的值应该是 *(–c.end());
reverse(s.begin(),s.begin()+n);
reverse(s.begin()+n,s.end());
reverse(s.begin(),s.end());
20210225
这是标准库里迭代器部分的内容,简单点说,就是用find这个函数,去找str这个序列中的i元素,如果序列中所找的这个元素不存在,就会返回end()。
那么按着这个思路去理解这两行命令就很容易了!
如果str.find(i)返回的不是str.end(),就说明在str序列中找到i元素:
str.find(i) != str.end() //说明找到了
同理,如果str.find(i)返回的是str.end(),就说明在str序列中没找到i元素:
str.find(i) == str.end() //说明没到
这个地方跟正常的理解逻辑相反,注意区分。
begin()和end()
遇到快速判断一个元素是否出现集合里的时候,就要考虑用哈希法。
数组就是简单的哈希表,但是数组的大小是受限的:
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
//有效的字母异位词
class Solution {
public:
bool isAnagram(string s, string t) {
//数组怎么表示
int record[26] = {0};
for(int i = 0; i<s.size(); i++){
record[s[i]-'a'] ++;
}
for(int i = 0; i<t.size();i++){
record[t[i]-'a']--;
if(record[t[i]-'a']<0) return false;
}
for(int i = 0; i<26;i++){
if(record[i]!=0) return false;
}
return true;
}
};
哈希值太大了,还得用set
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result;
unordered_set<int> nums_set(nums1.begin(),nums1.end());
for(int num:nums2){
if(nums_set.find(num)!=nums_set.end()) result.insert(num);
}
return vector<int>(result.begin(),result.end());
}
};
for(元素类型t 元素变量x : 遍历对象obj)
foreach语句是java5的新特征之一,在遍历数组、集合方面,foreach为开发人员提供了极大的方便。
foreach语句是for语句的特殊简化版本,但是foreach语句并不能完全取代for语句,然而,任何的foreach语句都可以改写为for语句版本。
foreach并不是一个关键字,习惯上将这种特殊的for语句格式称之为“foreach”语句。从英文字面意思理解foreach也就是“for 每一个”的意思。实际上也就是这个意思。
foreach的语句格式:
for(元素类型t 元素变量x : 遍历对象obj){
引用了x的java语句;
}
遍历对象obj:可以使数组,字符串
BF算法
目的:
解决字符串匹配问题,简单来说就是找出一个字符串(模式串)是否存在另外一个字符串(文本串,主串)中
BF的具体流程如下:
(1)将模式串的第一字符和文本串的字符对齐,上下字符之间进行比较,若出现上下字符不符的情况,则将模式串后移,首位字符和文本串的第二位字符相对,如此循环
文本串S:A B C A B C A B C D
|
模式串T:A B C D
文本串S:A B C A B C A B C D
|
模式串T: A B C D
文本串S:A B C A B C A B C D
|
模式串T: A B C D
。。。。。如此循环,直达找到匹配的位置
文本串S:A B C A B C A B C D
模式串T: A B C D
代码如下:
int BF(char S[],char T[]){
int i=j=0;
while(S[i]!='\0'&& T[j]!='\0'){
if(S[i]==T[j]){
i++;
j++;
}
else{
i=i-j+1;
j=0; //每次模式串和文本串出现不等字符,j和i都要进行回溯,这就提升了程序的运行复杂度,
}
}
if(T[j]=='\0') return i-j;
else return -1;
}
时间复杂度为O(m*n) m为文本串的长度,n为模式串的长度
每次模式串和文本串出现不等字符,j和i都要进行回溯,没有利用已经匹配的结果,这就提升了程序的运行复杂度,KMP方法能解决这个回溯的问题,让i,j不用回溯。
KMP算法
目的:
以发明者名字首字母命名
解决字符串匹配问题,简单来说就是找出一个字符串(模式串)是否存在另外一个字符串(文本串,主串)中
BF的具体流程如下:
文本串 aabaabaaf
模式串 aabaaf
KMP如何解决这样的问题
前缀:(不包括最后一个字符的各种组合)
a
aa
aab
aaba
aabaa
后缀:(不包括第一个字符的各种组合)
f
af
aaf
baaf
abaaf
最长相对前后缀(公共前后缀):
a 没有前缀和后缀 最长相等前后缀长度为0
aa 前缀为a 后缀为a 最长相等前后缀长度为1
aab 前缀为 a,aa 后缀为 b,ab 最长相等前后缀长度为0
aaba 前缀为 a,aa,aab 后缀为 a,ba,aba 最长相等前后缀长度为1
aabaa 前缀为 a,aa,aab,aaba 后缀为 a,aa,baa,abaa 最长相等前后缀长度为2
aabaaf 前缀为 a,aa,aab,aaba,aabaa 后缀为f,af,aaf,baaf,abaaf 最长相等前后缀长度为0
得到一个序列[0,1,0,1,2,0] 这个就是模式串aabaaf的前缀表,也可以称之为next数组,但是写法会有所不同,可能会把前缀表整体减1,或者把前缀表整体右移,首位补-1,这些写法都是合理的。
如何用前缀表来完成匹配呢?
a a b a a f
0 1 0 1 2 0
当把模式串和文本串进行匹配的时候,发现模式串中’f’字符和文本串中的字符‘b’不匹配,观察‘f’前的前缀表,最长相等前后缀为2,也就说明字符串aabaa 中存在后缀“aa” 和 前缀“aa” ,那我们重新匹配的时候,就可以从索引2出开始匹配,也就是对应的字符‘b’开始匹配。
这样我们就可以直接找出发生匹配冲突的字符在前缀表中前一位的字符对应的数字,这就是继续匹配的索引。
最长相对前后缀长度为3:

将模式串后移,使得前缀的位置来到后缀的位置

如何求next数组:
a a b a a f
0 1 0 1 2 0
具体代码:【伪代码】
初始化
前后缀不相同
前后缀相同
i: 后缀末尾位
j: 前缀末尾位,j还代表i之前(包括i)的子串的最长相等前后缀的长度。例子串为aabaaf,如果i指向f,则此时j应该为子串aabaa的最长相等前后缀的长度
void getNext(next,s){
j=0;
next[0]=0;
for(i=1;i<s.size();i++){
//前后缀不相同
while(j>0&&s[i]!=s[j]){
j=next[j-1]; //根据前一位的next[j]的值进行定位
}
//前后缀相同
if(s[i]==s[j]){
j++;
}
//更新next数组
next[i]=j;
}
}
C++编译错误:fatal error: variable-sized object may not be initialized
一、出错代码
int count[n+1]={0};
二、原因及解决办法
正如错误提示:可变大小的对象无法初始化,也就是在声明可变大小的对象时,不能同时进行初始化。这里n是可变大小的,在较新的编译器中用变量(如n)定义数组是被允许的,但是不能同时进行初始化,如有需要可在后续的步骤中进行初始化。
下面这样是不会出错的。
int count[n];
————————————————
版权声明:本文为CSDN博主「JacksonKim」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40765537/article/details/105612766
Line 23: Char 5: error: non-void function does not return a value in all control paths [-Werror,-Wreturn-type]
}
^
1 error generated.
只有if语句有return
int strStr(string haystack, string needle) {
int size =needle.size();
if(size==0) return 0;
int next[size];
getNext(needle,next);
int i=0;
int j=0;
while(i<haystack.size()&&j<needle.size()){
if(haystack[i]==needle[j]){ i++;j++;}
else if(j>0) j=next[j-1];
else {i++;j=0;}
}
if(j==needle.size()) return i-j;
if(i==haystack.size()) return -1; //把if判断去掉,直接写return -1;就可以避免错误
}
在for语句中定义的变量,在外部不可用:
for(int i=0;i<s.size();i++)
return i; //这样是错误的。因为i只是在for中定义
队列和栈
栈stack:先进后出
队列queue:先进先出
栈和队列是STL(C++标椎库)里面的两个数据结构。
C++ 标椎库有多个版本,三个最为普遍的版本为:HP STL,P.J.Plauger STL ,SGI STL
我们一般使用的STL是SGI STL
栈提供push,pop两种接口,所有的元素符合先进后出的原则,所以不提供走访功能,也不提供迭代器(iteration),队列也不提供迭代器。不想map,set提供迭代器来遍历所有元素。
栈是底层容器来实现其所有的功能,对外提供统一的接口,底层容器可以拔插,也就是具体使用哪种底层容器我们是可以选择的,
所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)
那么,STL中的栈是由什么底层容器实现的呢?
底层实现可以使vector,deque,list 都可以,主要是数组和链表的底层实现
在SGI STL中,栈默认的底层实现为deque
deque是一个双向队列,只要封住一端,只开通量一端就可以实现栈的逻辑了。
在SGI STL中,队列默认的底层实现为deque
我们可以指定vector为栈的底层实现,初始化语句为:
std::stack<int,std::vector<int>> third;
deque支持push_front、pop_front、push_back、pop_back。
queue支持push_back、pop_front。
栈:
stack.push(1);
int top=stack.top(); //返回栈顶的值不删除
stack.pop(); //无返回值,删除栈顶的值
int size =stack.size();
bool it=stack.empty();
队列:
queue.push(1);
int peek=queue.front(); //返回队头的值,不删除
int peek=queue.back(); //返回队尾的值,不删除
queue.pop(); //无返回值,删除栈顶的值
int size =queue.size();
bool it=stack.empty();
queue1=queue2; //可以直接赋值
双向队列:
queue.pop_front();
queue.pop_back();
queue.push_back();

用两个栈来实现队列:
class MyQueue {
public:
//栈的操作有哪些? push,pop,peek,size,is empty
//栈的操作
stack<int> stIn;
stack<int> stOut;
/** Initialize your data structure here. */
//MyQueue* obj = new MyQueue();
MyQueue() {
}
/** Push element x to the back of queue. */
void push(int x) {
stIn.push(x);
}
/** Removes the element from in front of queue and returns that element. */
int pop() {
if(stOut.empty()){
while(!stIn.empty()){
stOut.push(stIn.top());
stIn.pop();
}
}
//stack 的pop操作不会返回,top功能会
int result = stOut.top();
stOut.pop();
return result;
}
/** Get the front element. */
int peek() {
int re = this->pop(); //,因为功能相似,所以在这里直接使用pop函数
stOut.push(re);
return re;
}
/** Returns whether the queue is empty. */
bool empty() {
return stOut.empty() && stIn.empty();
}
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/
c++中的atoi()和stoi()函数的用法和区别
相同点:
①都是C++的字符处理函数,把数字字符串转换成int输出
②头文件都是#include
不同点:
①atoi()的参数是 const char& ,因此对于一个字符串str我们必须调用 c_str()的方法把这个string转换成 const char&类型的,而stoi()的参数是const strin&,不需要转化为 const char&;
②stoi()会做范围检查,默认范围是在int的范围内的,如果超出范围的话则会runtime error!
而atoi()不会做范围检查,如果超出范围的话,超出上界,则输出上界,超出下界,则输出下界;
//myfirst.cpp--displays a message
#include "stdafx.h"
#include 
在对象中再定义一个变量:
单调队列
class Solution {
private:
class MyQueue{
public:
deque<int> que;
void push(int x){
while(!que.empty()&&x>que.back()){
que.pop_back();
}
que.push_back(x);
}
void pop(int x){
if(que.front()== x) que.pop_front();
}
int front(){
return que.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MyQueue que;
vector<int> result;
for(int i=0;i<k;i++){
que.push(nums[i]);
}
result.push_back(que.front());
for(int i=k;i<nums.size();i++){
que.pop(nums[i-k]);
que.push(nums[i]);
result.push_back(que.front());
}
return result;
}
};
优先级队列
优先级队列:披着队列的外衣的堆,从队头取元素,从队尾添加元素,再去其他添加取出元素的方法,看起来就是一个队列
优先级队列是自动按照元素的权值排序的,那么它是如何有序排列的呢?
在默认情况下,priority_queue利用max_heap大顶堆完成对元素的排序,这个大顶堆是以vetcor为表现形式的complexte binary tree(完全二叉树)。
什么是堆?
堆是一颗完全二叉树,树中的每个结点都不小于(或不大于)其左右孩子的值。
如果父亲结点大于等于左右孩子就是大顶堆
如果父亲结点小于等于左右孩子就是小顶堆
树
1、树的定义
树是n个结点的有限集合,有且仅有一个根结点,其余结点可分为m个根结点的子树。

2、树的概念
结点的度:一个结点拥有子树的个数称为度。比如A的度为3,C的度为2,H的度为0。度为0的结点称为叶子节点(D,F,G,H)。树的度是树中所有结点的度的最大值,此树的度为3。
树中结点的最大层次成为树的深度或高度。此树的深度为4。
父节点A的子结点B,C,D;B,C,D也是兄弟节点
树的集合称为森林.树和森林之间有着密切的关系.删除一个树的根结点,其所有原来的子树都是树,构成森林.用一个结点连接到森林的所有树的根结点就构成树.
3、二叉树
二叉树是每个节点最多拥有两个子节点,左子树和右子树是有顺序的不能任意颠倒。

4、满二叉树
高度为h,由2^h-1个节点构成的二叉树称为满二叉树。

5、完全二叉树
完全二叉树是由满二叉树而引出来的,若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
完全二叉树的特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。需要注意的是,满二叉树肯定是完全二叉树,而完全二叉树不一定是满二叉树。
算法思路
判断一棵树是否是完全二叉树的思路
1>如果树为空,则直接返回错
2>如果树不为空:层序遍历二叉树
2.1>如果一个结点左右孩子都不为空,则pop该节点,将其左右孩子入队列;
2.1>如果遇到一个结点,左孩子为空,右孩子不为空,则该树一定不是完全二叉树;
2.2>如果遇到一个结点,左孩子不为空,右孩子为空;或者左右孩子都为空;则该节点之后的队列中的结点都为叶子节点;该树才是完全二叉树,否则就不是完全二叉树;
堆一般都是用完全二叉树来实现的。

什么是堆?
堆是一颗完全二叉树,树中的每个结点都不小于(或不大于)其左右孩子的值。
如果父亲结点大于等于左右孩子就是大顶堆
如果父亲结点小于等于左右孩子就是小顶堆
二叉搜索树
二叉搜索树是一个有序树
若左节点不为空,则左子树上所有的节点的值均小于它的根节点的值
若右节点不为空,则右子树上所有的节点的值均大于它的根节点的值
平衡二叉搜索树
它是一颗空树或者它的左右两个子树的高度差不超过1,并且左右两个子树都是一颗平衡二叉树
C++中的map,set,multimap,multiset 的底层实现都是平衡二叉搜索树,所以map,set的增删操作时间复杂度是logn。熟悉容器底层的实现方法,更能加深对容器的理解。
二叉树的储存方式
链式储存:用指针,通过指针把散落在各个地址的节点串联在一起
顺序储存:用数组,元素在内存中是连续分布的
链式储存:
二叉树遍历
数组与vector的对比
1、内存中的位置
C++中数组为内置的数据类型,存放在栈中,其内存的分配和释放完全由系统自动完成;vector,存放在堆中,由STL库中程序负责内存的分配和释放,使用方便。
2、大小能否变化
数组的大小在初始化后就固定不变,而vector可以通过push_back或pop等操作进行变化。
3、初始化
数组不能将数组的内容拷贝给其他数组作为初始值,也不能用数组为其他数组赋值;而向量可以。
4、执行效率
数组>vector向量。主要原因是vector的扩容过程要消耗大量的时间。
int nums[4]; //数组初始化
vector<int> nums1(4);
vector<int> nums1(nums.begin(),nums.end());
vector<vector<bool>> nums1(3,vector<bool>(4));
一、vector 的初始化:可以有五种方式,举例说明如下:
(1) vector a(10); //定义了10个整型元素的向量(尖括号中为元素类型名,它可以是任何合法的数据类型),但没有给出初值,其值是不确定的。
(2)vector a(10,1); //定义了10个整型元素的向量,且给出每个元素的初值为1
(3)vector a(b); //用b向量来创建a向量,整体复制性赋值
(4)vector a(b.begin(),b.begin+3); //定义了a值为b中第0个到第2个(共3个)元素
(5)int b[7]={1,2,3,4,5,9,8};
vector a(b,b+7); //从数组中获得初值
二、vector对象的几个重要操作,举例说明如下:
复制代码
(1)a.assign(b.begin(), b.begin()+3); //b为向量,将b的0~2个元素构成的向量赋给a
(2)a.assign(4,2); //是a只含4个元素,且每个元素为2
(3)a.back(); //返回a的最后一个元素
(4)a.front(); //返回a的第一个元素
(5)a[i]; //返回a的第i个元素,当且仅当a[i]存在2013-12-07
(6)a.clear(); //清空a中的元素
(7)a.empty(); //判断a是否为空,空则返回ture,不空则返回false
(8)a.pop_back(); //删除a向量的最后一个元素
(9)a.erase(a.begin()+1,a.begin()+3); //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+ 3(不包括它)
(10)a.push_back(5); //在a的最后一个向量后插入一个元素,其值为5
(11)a.insert(a.begin()+1,5); //在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4
(12)a.insert(a.begin()+1,3,5); //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
(13)a.insert(a.begin()+1,b+3,b+6); //b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8 ,插入元素后为1,4,5,9,2,3,4,5,9,8
(14)a.size(); //返回a中元素的个数;
(15)a.capacity(); //返回a在内存中总共可以容纳的元素个数
(16)a.resize(10); //将a的现有元素个数调至10个,多则删,少则补,其值随机
(17)a.resize(10,2); //将a的现有元素个数调至10个,多则删,少则补,其值为2
(18)a.reserve(100); //将a的容量(capacity)扩充至100,也就是说现在测试a.capacity();的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才 显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能)
(19)a.swap(b); //b为向量,将a中的元素和b中的元素进行整体性交换
(20)a==b; //b为向量,向量的比较操作还有!=,>=,<=,>,<