容迟网络中的路由算法笔记(三)
第三章
基于地理信息的路由算法
背景:为了提高消息成功投递的可能性,一种普遍受认可的方式是采用基于洪泛的多副本策略,通过引入更多的消息副本,增大消息与目的节点相遇的机会。为了实现消息的受控洪泛,减少消息冗余的程度,许多研究学者都在尝试捕获全局网络拓扑知识或者额外的辅助信息。但是在间断性连接的容迟网络中,很难实时更新和维护整个网络的拓扑知识,即使在个别应用场景中,能够获得这些信息,也要付出很高的代价。与捕获全局拓扑知识相比,只获取局部信息的地理路由则可以有效避免这些不足。
地理路由只需要保存自己及周围邻居节点的位置信息,几乎不需要其他的额外信息,因此算法开销较少。从信息的可获得性和可靠性考虑,节点的地理位置信息可以很容易地通过GPS定位系统或者相关的定位算法获得。
研究原因:在实际的挑战性环境中,地理路由不可避免地受到一定程度的限制。由于网络节点部署不均匀或者是部分节点由于故障或者能量耗尽而失效,还有一些环境如沼泽、 水塘等会形成天然的“空洞”。在依据地理路由转发消息的过程中,数据包可能会到达没有任何邻居节点比自身更接近目的节点的区域,导致消息无法继续传输,影响了消息的成功投递。
相关研究
地理路由算法分类:
-
基于平面化拓扑结构的地理路由:
此类地理路由是基于网络平面的转发路由,即通过将网络平面化,形成由节点组成的不存在交叉的面,进而借助此平面化图的支持进行消息转发。
GPSR(greedy perimeter stateless routing)协议是一种典型的基于平面化的地理路由。在路由初始阶段,消息转发采用贪婪转发,当遇到路由空洞时,从当前节点开始进入边缘转发。GPSR按照右手法则进行边缘转发,选择顺时针或者逆时针方向沿着面转发消息。若转发时遇到一个较大的面,一旦选错了转发方向,就可能比选择正确方向的路径多出较多的跳数。
所以GLNFR (greedy and local neighbor face routing)是一种新型的用于发现移动节点间通信路径的路由协议,它利用局部构造法进行Delaunay三角剖分,保证节点间消息的顺利传输,对网络变化具有更好的可扩展性和适应性。 -
基于特征节点的地理路由:
在某些应用环境中,当节点无法精确地获得自身地理位置信息或者GPS定位系统不能正常工作时,地理路由往往需要一些特征节点进行辅助。
GLIDER (gradient landmark-based distributed routing)协议是一种典型的基于特征节点的地理路由。它通过信标节点辅助完成路由。信标节点是一些经过选择的特殊节点,它们知道自己的地理位置信息,而且均匀地分布在整个网络中。GLIDER通过这些分散性较好的信标节点构造网络的全局拓扑,并且以信标节点为中心将网络划分为不同的小区域,进而构成网络的局部拓扑。
路由选择的时候,首先寻找本地信标节点到目的信标节点的路径,当消息到达目的信标节点后,通过局部贪婪或者洪泛将消息传递给目的节点。 -
基于拓扑特性的地理路由:
地理路由除了使用特征节点外,还可以利用节点的拓扑特性获得自身地理位置信息。
一般通过构造生成树、亏格嵌入、定位边界等方法,建立具有拓扑特征的结构来辅助地理路由。GEM (graph embedding)是一种适用于数据中心存储方式的基于拓扑特征的地理路 由。其基本思想是建立一个虚拟极坐标系统,网络中的每个节点形成一个以汇聚节点为根的带环树,每个节点用到树根的跳数和角度范围来表示,节点间的消息路由通过这个带环树来实现。在消息转发过程中,如果目的节点的角度不在自己的角度范围内,就将消息传递给父节点,父节点按同样的方法处理,直到消息到达源节点或者目的节点。 -
地理位置信息辅助的多策略路由:
此类路由策略在利用节点位置信息辅助转发消息的同时,还采取其他路由措施如效用信息、能量感知、限制副本等,进一步优化路由性能。
基于邻居节点位置信息的受控传染路由算法
-
动机及网络模型假设
背景:由于拓扑变化的频繁以及高时延链路,维护和更新一张路由表是极其困难的,其原因是频繁的拓扑变化以及高时延会使得拓扑更新信息难以分发,从而降低该类路由算法的实用性。从消息的时效性以及易得性方面来考虑,一跳邻居信息较为可靠。首先,节点可以依靠周期性发送广播包以探测其邻居节点,并可在其中包含自身信息以通知其邻居节点。邻居节点可用携带信息的数据包予以响应。
网络模型做出如下假设:
(1)每个节点装有局部定位系统,节点能够获取自身的位置信息。
(2)当节点互相进入通信范围时,通过交换位置信息,能够获取对方的位置信息。
(3)位置信息只经过一跳即可到达邻居节点,因此忽略消息传递的时延。
(4)位置信息只在一跳邻居内传染,不会扩散到整个网络。并且相比于普通消息数据,位置信息具有更高的优先级。
(5)只有一跳邻居的信息可以被实时获得并利用,不假设任何已知的关于目的节点的信息,包括目的节点的坐标。
LCE两条准则:
(1)节点应该有目标的选择下一跳
(2)节点也需要做出有一定风险的选择, 即在一定程度上放宽对副本数量的限制。
中继节点的选择:
当可用邻居节点数目小于2个,可以推测网络节点的分布可能较稀疏。此时遵循准则中的第二条,向两个邻居节点都传递消息的副本,
当可用的邻居节点数目大于2个时,遵循第一条准则,对周围所有可用的邻居节点进行选择。尽可能选择与当前节点形成张角最大的两个节点,以实现副本的扩散投递。并用余弦值作为衡量标准,当其差值在£之内时,我们则转而优先考虑距离因素。 -
LC-Epidemic路由协议描述:
LCE算法釆用的受控传染策略是,当可用节点的数目小于2个时,采用传统的传染病算法,以增大消息的并行性。若可用节点的数目大于两个,为了节省网络中的缓存资源,降低能耗,采用上述介绍的下一跳选择算法,对可用节点列表AvailableHostsList进行过滤,筛选出两个节点传染消息。当传递操作结束后,向路由进程返回MSG_SENT信号。
1When节点i从节点j收到hello_msg {
2 neighborsTable.update (j, time_now)//更新其一跳邻居表neighborTable
3 messageSend (j,hello_response)// 通知邻居节点j更新操作已结束,
4}
5When节点i从节点j收到hello_response{//收到hello response消息,进行更新
6 neighborsTable.update (j, time_now)
7}
8When新消息data_msg从节点j到达节点i {
9 neighborsTable.update (j, time_now)
10 if ( messageQueue.exist (data_msg) ){ //检查数据消息data_msg是否已在其队列当中
11 丢弃 data_msg
12 return MSG_DROPPED
13 }
14 messageQueue.add (data_msg)
15 messageQueue.sort (increase, TTL) //根据消息剩余生存时间的增序对消息队列进行排序
16 AvailableHostsList=getHostsFrom (neighborsTable) //从邻居表中读取所有可用邻居节点的信息
17 if ( AvailableHostsList.length()<= 2 ) (
18 messageSend (AvailableHostsList, messageQueue)
19 }
20 else{
21 BestHostsList=filterHostsList (AvailableHostsList) //对列表进行过滤,筛选出两个节点传染消息
22 messageSend (BestHostsList, messageQueue)
23 }
24 return MSG_SENT
25}
将 LC-Epidemic 与 Epidemic、Binary Spray & Wait、First Contact (FC)三个算法进行比较,分析相关算法的性能。主要的路由评估指标有消息投递率、平均时延、网络负载和平均跳数。
(1)消息产生时间间隔下:
消息投递率:,LC-Epidemic是基于洪泛算法,其目的是最大化副本数量以增加投递率,故能够达到与Epidemic相当的较高的消息投递。First Contact算法取得较低的投递率;Binary Spray & Wait算法的投递率最低。
端到端平均时延:Epidemic无疑具有最低的端到端平均时延,因为其最大化利用了所有网络可用资源。LC-Epidemic的平均时延比Epidemic约高4倍,但仍然大大低于其他两种算法。在消息产生间隔小于20s时,由于缓存资源受限,Binary Spray & Wait和First Contact的表现要好于基于洪泛的Epidemic以及LC-Epidemic算法。随着消息产生间隔的持续增大, 固定时间内的副本数量不断减少,Epidemic和LC-Epidemic的消息端到端平均时延迅速下降,当消息产生间隔时间大于30s时,节点的缓存已不再是限制路由性能表现的瓶颈因素。Epidemic和LC-Epidemic与其他两种算法一样,端到端平均时延趋于稳定。
结果:在消息产生间隔小于30s时,缓存资源是路由性能表现的瓶颈因素,此时LC-Epidemic能够保证和Epidemic投递率几乎持平的情况下,降低一半的网络负载,代价是具有比Epidemic高的平均时延。相比传统的Epidemic对消息副本的盲目复制,LC-Epidemic基于节点分布及相对位置选择下一跳,故其路由策略更具有针对性。
Binary Spray & Wait和First Contact算法在消息投递率和端到端平均时延两项指标上,表现都差于基于洪泛的Epidemic和LC-Epidemic。
平均跳数:,First Contact具有最高的平均跳数,原因是其相比Epidemic和LC-Epidemic,只在网络中维护消息的一份副本。LC-Epidemic的平均跳数只比Epidemic略高,其原因是LC-Epidemic是受控洪泛,在一定程度上控制消息副本数目,进而控制网络资源的利用,以换来更低的负载率。
结果:,LC-Epidemic在投递率和平均跳数两项指标上都接近于最优的Epidemic,其负载率比传统的Epidemic算法低一半。不刻意强调端到端时延,可以用LC-Epidemic算法代替Epidemic。在节点移动速度较低的网络场景下,Binary Spray & Wait以及First Contact的表现不甚理想,First Contact在投递率、投递时延以及负载率三方面都要优于Binary Spray & Wait。
(2)节点缓存空间大小下:
当节点缓存容量较小时,四种算法都具有较低的端到端平均时延。随着节点缓存的增加,这种严重丢包的情况渐渐缓解,当缓存容量达到5M时四种算法的平均时延都已攀升到最高点。在节点缓存容量从0.5MB增加到5MB的这个过程中,所有算法的消息投递率都是在增长的,且当缓存容量为5MB时,Binary Spray & Wait以及First Contact的投递率也达到最大。随着缓存容量的继续增大,基于洪泛策略的Epidemic和受控传染策略的LC-Epidemic,具平均时延随着目点缓存的继续增大而逐渐降低,至缓存容量增大到30MB时趋于稳定。
结果:在缓存资源稀缺时,宜釆用单副本算法,如First Contact。因为此时洪泛策略往往会让网络资源迅速耗尽,从而降低路由性能表现。如果要将跳数控制在一定范围内,则宜采用受控传染策略的路由算法LC-Epidemic, 以降低网络负载率。
LC-Epidemic基于节点位置的下一 跳选择算法能够有效地控制网络中消息副本数量,从而降低负载,并且能够获得与Epidemic几乎持平的投递率,在一定程度上可以代替盲目的洪泛策略。
(3)消息生存周期:
当TTL小于50min时,Epidemic和LC-Epidemic的投递率远高于Binary Spray & Wait以及First Contact,因为当消息存活时间受限时,Epidemic和LC-Epidemic能够有效利用快速增加消息并行性的洪泛策略,及时完成消息的投递。而随着TTL的增大,前两者的投递率不断下降,而后两者的投递率却保持攀升,因为过大的TTL,会导致当使用洪泛策略时节点缓存中消息副本积压,从而造成丢包,降低消息投递率。
结果:试验中,当消息存活时间大于250min时,所有四种算法的投递率都趋于稳定,此时Binary Spray & Wait和First Contact要明显优于其他两个洪泛算法。所以当消息TTL较长时,宜采用严格控制副本数量的路由算法,摒弃洪泛。然而当TTL较短时,Binary Spray & Wait以及First Contact 的表现相比Epidemic 和 LC-Epidemic差很多。
基于移动方向的受控传染路由算法
-
动机及模型假设
背景:当前多数利用节点局部信息和地理位置的路由算法,例如位置感知的社会路由(location-aware social routing)等,在进行下一跳节点选择时,都依赖于节点的位置信息。然而在一些容迟网络中(例如野生动物追踪网络),节点的移动性会导致节点的实际位置在时刻改变,因而位置信息的稳定性较差。
可利用更加可靠的节点移动方向信息来进行下一跳节点选择。因为相比于节点位置的时刻改变,节点的移动方向就要相对稳定很多。相比于节点地理位置的时刻变化,节点移动方向的变化频率要明显低很多,具有更好的稳定性,更加可靠。
另外节点的位置信息只能决定当前时刻消息副本的分布,新的中继节点可能将消息副本携带到任何位置。而利用节点的移动方向,可以很好地定向引导和控制消息副本传向我们选定的方位,因为在中继节点选择后的一定时间段或者一段距离之内,中继节点仍会按照选定的方向移动。
缓存空间的管理策略在DTN路由中同样发挥着重要作用。一些典型路由算法在基于优先级的缓存管理中引入了消息经过的跳数,为跳数更少的消息赋予更高的优先级,让其获得优先转发的机会,一定程度上提高了路由性能。但是以跳数作为度量优先级的标准,存在一定的偶然性,很容易造成始终是跳数少的消息得到转发机会。
因此提出同时利用消息的跳数和已经存活的时间作为度量标准,为那些跳数和已经存活时间更少的消息赋予更高的优先级。
移动方向的容迟网络受控传染路由算法(moving direction based controlled epidemic routing, MDCE)网络模型假设:
(1)节点能够借助于GPS或者相关定位算法获得自己的位置信息,进而计算并广播其当前移动方向。
(2)相比于节点位置的时刻变化,其移动方向则要稳定很多,通常节点在沿着某 一方向移动一段距离之后才会改变方向。
(3)广播包的大小相对于网络中的数据消息来说可以忽略,并且其传输距离很短,只在节点自身的通信范围内,邻居节点在收到广播包后不会再转发,避免了在整个网络中的扩散。
(4)为了降低路由的复杂性,减少缓存资源和能量的消耗,获得更好的路由通用性,算法不去捕获网络拓扑知识或者其他辅助信息。 -
下一跳中继节点选择
利用节点的移动性将消息副本携带到Ni周围的各个方向上。这样即使无法获取最终目的节点的具体方位信息,也能确保各个方向上都存在与最终目的节点相遇的可能性,从而提高消息投递率。
输入:Ni,的移动方向:MDi
Ni邻居的移动方向:neighborsTable
角度范围:angleScope
输出:relayList
初始化relayList为空
for neighborsTable中每一个邻居节点的移动方向MDi,
计算MD和MDi,的夹角
if夹角在angleScope的范围内
确定节点具体的移动方向
if relayList中已经存在一个该方向上的中继节点
选择一个具有更小值的节点
else将该节点添加到relayList
end if
end if
end for
根据式(3.6)计算的值,将relayList按升序排序
return relayList
即:利用下面三个式子分别计算邻居节点移动方向相对于左前或右前标准方向(即与Ni移动方向夹角恰为1/4兀的方向)的夹角偏移值,还有正左和正右(即与Ni移动方向夹角恰为1/2兀的方向)的角度偏移值,相对于左后和右后标准方向(即与Ni移动方向夹角恰为3/4兀的方向)的角度偏移值。选择偏移值最小的邻居作为中继节点。按偏移值由小到大对Ni的中继节点队列relayList进行排序,让移动方向更加偏向正左或正右方向的中继节点获得优先机会。
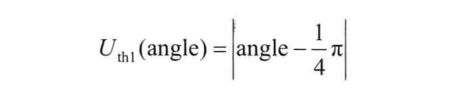
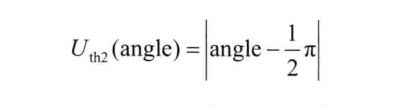
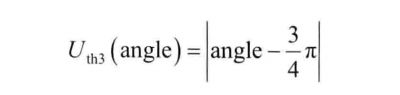
-
基于优先级的缓存管理策略
釆用消息经过的跳数和已经存活的时间作为度量优先级的综合标准,让跳数和己经存活时间更少的消息具有更高的优先级,避免了只用跳数作为度量标准的偶然性。

HOP是门限值,C(M)表示消息M的跳数。M经过的跳数越多,则优先级影响因子H(M)的值就越大,而经过的跳数越少,则优先级影响因子H(M)的值就越小。当M经过的跳数超过门限值时,H(M)的值等于1。
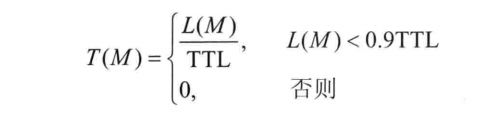 用L(M)表示消息M已经存活的时间,TTL表示消息能够存活的时间(即消息的生存周期)。用NC表示网络中的节点数量。当消息M已经存活的时间少于其生存周期的90%时,M生存时间越长,则其优先级影响因子T(M)的值也就越大。而当M的生存时间超过其生存周期的90%时,表明M即将消亡,此时若以尚未成功交付,应该尽将其快转发出去,因而此时让T(M)取最小值0。
用L(M)表示消息M已经存活的时间,TTL表示消息能够存活的时间(即消息的生存周期)。用NC表示网络中的节点数量。当消息M已经存活的时间少于其生存周期的90%时,M生存时间越长,则其优先级影响因子T(M)的值也就越大。而当M的生存时间超过其生存周期的90%时,表明M即将消亡,此时若以尚未成功交付,应该尽将其快转发出去,因而此时让T(M)取最小值0。
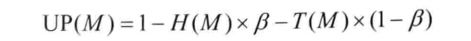
UP(M)综合利用了消息经过的跳数和已经生存的时间,并且各自赋予它们50%的权重。将消息队列按优先级UP(M)的值由大到小的顺序排序,从而在转发消息时先转发优先级高的消息,而当缓存溢出时先删除优先级最低的消息。 -
路由协议描述
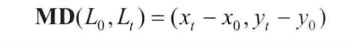
(3.11)
//节点的周期性更新操作
1.When处于更新周期内{
2. 更新当前位置信息情况
3. 计算当前移动方向
4. 广播其移动方向信息
5. 更新 neighborsTable//删除长时间未更新的邻居
6. 更新 messagesQueue //删除生存周期耗尽的消息
7.}
8.When从节点j收到方向消息束{
9. 在neighborsTable中更新节点j的移动方向信息
10. 将其移动方向信息通知节点j
11.}
12.When从节点j收到数据消息束M {
13. if该节点是M的目的节点
14. 广播确认消息束
15. else if messagesQueue中不存在M
16. 将M添加到messagesQueue
17. else
18. 丢弃M
19. 在neighborsTable中更新节点j的时间信息
20.}
//是节点收到确认包后清理缓存的操作
21.When收到message的确认消息{
22. if message 存在于 messagesQueue
23. 将其从messagesQueue中删除
24.}
25.When neighborsTable.size()!=0 并且 messagesQueue.size() !=0 {
26. 将所有可投递的消息传输给相应的目的节点
27. 从 neighborsTable 中选择 relayList
28. for relayList中的每一个节点{
29. 管理 messagesQueue//让跳数和己经存活时间更少的消息具有更高的优先级
30. 将消息复制给节点
31. }
32.}
其中邻居表neighborsTable中保存了所有邻居的移动方向及其更新时间等信息,第5行对邻居表的更新操作是删除长时间未更新的邻居,因为这表明该邻居已经不在节点的通信范围内。第6行对消息队列的更新操作是删除生存周期耗尽的消息,更新应用进程新生成的消息以及按照缓存管理策略管理消息队列。第21〜24行是节点收到确认包后清理缓存的操作。第25- 32行是整个路由的核心,利用算法3.3选择下一跳中继节点,并用式(3.8)〜(3.10) 计算出所有消息的优先级,进行高效的缓存管理。
5. 仿真实验
(1)节点缓存空间
结果:在节点随机移动的网络中,当资源很稀缺并且负载能力有限时,First Contact具有一定的实用价值;而当缓存资源不是无限时,MDCE可以代 替Epidemic和Prophet。此时,MDCE在保持较高的投递率的同时,能够取得更低的负载率,更少的平均跳数和消息丢包数,因而可以发挥更加高效的路由性能。
(2)消息生存周期
结果:在节点随机移动的网络中,当消息的生存周期很长时,First Contact负载率更低,具有一定的实用价值。而当消息的生存周期较短时,MDCE可以用来代替Epidemic和Prophet,因为其可以提供更好的路由性能,并且更加稳定。
(3)消息时间间隔
结果:在节点随机移动的网络中,Epidemic适用于消息生成频率较低的网络,而MDCE和Prophet能更好地应对消息生成频率的变化,具有更好的伸缩性,但总体上MDCE的路由性能要略优于Prophet。
**
基于局部位置信息与历史效用的路由算法
**
- 动机及模型假设
背景:由于节点移动的不可预测性及网络节点密度稀疏等原因,单纯地只依靠节点位置信息做出路由决策往往较难取得令人满意的消息投递率。而在利用位置信息对消息路由进行辅助的同时,综合利用多种效用信息可以取得更高的消息投递率,进而提高路由性能。在真实的应用场景中,进行通信的源节点对目的节点往往具有一定的认知度,相比于 中继节点,源节点可以捕获更多的关于目的节点的信息,从而针对目的节点做出更高效的路由选择。
利用位置信息和历史效用进行消息路由的同时,进一步地在消息的源节点和中继节点上釆取不同的路由策略,从而更好地控制消息冗余,降低网络负载,提高路由性能。
LPHU算法主要基于如下假设:
(1)通过GPS系统和相关的定位算法,节点可以获取自身的位置信息,并且在节点相遇时以广播的方式在其一跳邻居内扩散位置信息。
(2)节点利用每次的通信机会,主动收集节点间相遇的历史信息。
(3)节点移动缓慢并且只在局部范围内活动,即相对于整个应用场景,其位置相对稳定。
(4)当消息被成功投递时,目的节点向整个网络广播确认信息包,收到确认信息的节点主动丢弃该消息副本。 - 下一跳中继节点选择
假设节点N3距离源节点N4的距离为d1,节点N2距离源节点Ni的距离为d2。如果d1>d2,则N3是当前节点N2的外层邻居,N2可以选择N3作为下一跳的中继节点。
源节点携带的消息可以一直保持其传染能力,中继节点携带的消息副本主要经历三个阶段:传染期、携带期和转发期。传染期,该消息副本只有一次扩散消息副本的 机会。此后,消息副本处于携带期。此时,消息副本不再具备传染能力,即不再复制任何新的消息副本,而是利用节点的移动性寻找目的节点。最后,消息副本进入转发期。在转发期内,中继节点需要接该消息副本转发给一个新的中继节点,转发成功后需要删除该消息副本。
(1)消息源节点上的路由选择
源节点尽可能选取可以形成最大张角的两个一跳邻居节点来复制消息副本,以此来增加消息副本的覆盖面积,获得更广的方向分布。节点在复制消息副本之前,需要实时地将其当前的位置信息封装在每个消息内,进而将其位置信息存储在每一个消息副本内。中继节点利用存储在消息副本内的位 置信息,选择外层的邻居作为下一跳中继节点。
❤️
//消息Mi在源节点Ni上的路由策略
输入:一跳邻居列表:neigh_List
节点Ni的当前位置:position
1.if neigh_List.size()=O
2. return
3.else if neigh_List.size()<3
4. 将position封装进Mi,
5. 将Mi复制到neigh_List
6.else
7. 初始化biggestAngle 为 0
8. 初始化neighborsCombination为空
9. for neigh_List中节点组合
10. //用式计算每一种组合的夹角angle
11. if angle > biggestAngle
12. biggcstAnglc=angle
13. neighborsCombination=combination
14. end if
15. end for
16. 将 position 封装到Mi
17. 将Mi复制到 neighborsCombination
18.end if
19.return
在算法3-5行,当一跳邻居节点少于3时,源节点将消息复制给所有的一跳邻居节点。算法7~17行,当一跳邻居大于等于3时,源节点选择形成最大张角的两个邻居来复制消息副本。在算法第4行和16行,源节点Ni需要将其当前的位置信息封装在消息Mi内。
(2)消息中继节点上的路由选择。
1.基于相遇历史信息的效用:利用节点相遇的历史信息来计算节点的效用值, 预测节点之间的相遇可能性,从而选择更优的下一跳中继节点。

动态矩阵DEHM保存了节点N,在最近M个时间单元内与其他节点的相遇历史信息。
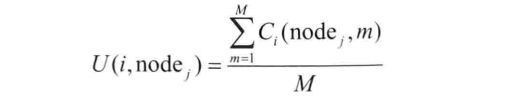
用U(i,nodej)作为选择下一跳中继节点的效用指标,以此选择效用值比当前节点更高的邻居作为下一跳中继节点。
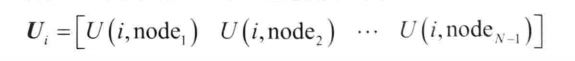
计算出一个效用向量Ui,它包含了节点与其他所有节点间的相遇计数。当节点相遇时,它们彼此交换效用向量。
2.中继节点上的路由策略
中继节点携带的消息副本的传染能力受到严格控制,并且中继节点只能选择外层的邻居作为下一跳中继节点。利用效用值来评估所有的外层邻居,进而选择效用值更高的下一跳中继节点,以此来提高消息的投递率。
//消息Mi在中继节点Ni上的路由策略
输入:一跳邻居列表:neigh_List
Mi,初始生存周期:ini_TTL
1.计算节点Ni携带Mi的时间custody_time
2.if custody_time<=0.5ini_TTL
3. if Mi仍具备传染能力
4. 从neigh_List中筛选出外层邻居(根据邻居节点到源节点的距离)
5. 再筛选出具有更高效用的邻居
6. 将Mi复制给选定的节点
7. Mi丧失传染能力
8. else //携带期
9. if Ni遇到Mi的目的节点
10. 将Mi交付给目的节点
11. 删除Mi
12. else if Ni收到Mi的确认消息
13. 删除Mi
14. end if
15. end if
16.else
17. 从neigh_List中筛选出外层邻居
18. 筛选出具有最髙效用值的一个邻居转发消息副本
19. 将Mi复制给选定的节点
20. Mi丧失传染能力
21.end if
22.return
3.仿真实验
(1)不同缓存空间下的性能表现
LPHU在利用历史信息选择史优的中继行点的同时,利用节点局部位置信息,将消息逐层地向外扩散,避免了消息的回传,并且进一步限制中继节点或携带的消息的复制能力,控制了消息冗余的程度。同时,LPHU的平均跳数最少,表明其路由策略更加高效,降低了消息的投递耗费。并且相比于Epidemic和 Prophet, LPHU在消息传输的平均时延上也能够取得一定的优势。
(2)不同消息生存周期下的路由表现
与Epidemic和Prophet不同,LPHU限制了中继节点上的消息的复制能力。因此,即使消息的生存周期在不断增加,LPHU仍然能够避免生成过多的冗余消息。此外,LPHU同样可以取得令人 满意的传输时延,尽管相对于Prophet没有绝对的优势。LPHU 可以高效地应对消息生存周期的增加,其路由性能更加稳定。
(3)不同消息生成时间间隔下的性能表现
Prophet利用节点间相遇的历史信息来选择更优的中继节点, 一定程度上控制了消息冗余,因而其路由性能要优于Epidemic,但仍然要弱于 LPHU。 LPHU通过限制中继节点携带的消息副本的复制能力,有效避免生成过多的冗余消息副本,从而提高了网络资源的利用效率。此外,LPHU借助节点的局部位置信息和历史效用信息,选择更优的中继节点,并控制消息副本的扩散方向,以此获得了更好的路由性能。
基于邻居节点位置的时间片轮转路由算法
- 动机及网络模型假设
减少资源消耗最直接有效的方法是减少网络中消息副本的数量,但增加消息投递率的最直接的方法却是增加消息副本的数量。因此如何在低资源消耗和高消息投递率之间取得更好的平衡成为提高容迟网络路由性能的关键。大部分学者都在尝试通过借助额外的辅助信息、捕获网络拓扑变化、引入摆渡节点等方式来获得更好的性能表现。虽提高了路由效率,但不可避免的增加了路由的复杂性,并且这些信息的可靠性和可获得性也会降低路由的通用性与实用性。
有文献证明源节点将消息的多个副本发送到不同的中继节点可以增强网络的通信能力,节点的移动性可以增加网络的吞吐率。
提出了“时间片”的概念来充分利用单副本路由和多副本路由各自的优势。以时间片作为周期,在每个周期内完成多副本策略与单副本策略的一次轮转:
基于邻居节点位置的时间片轮转路由算法 (time-slice based hybrid routing, TSH):
(1)每个节点只能实时获得自己的位置信息,无法捕获网络拓扑或者其他额外信息。
(2)通过广播位置信息,在节点相遇时可以捕获一跳邻居的位置信息。位置信息的大小相对于网络中消息副本来说可以忽略,且其传播距离有限,只能在节点本身的通信范围内。
(3)每个消息根据所处时间片的位置,各自独立进行路由选择。消息成功传递后,目的节点广播确认消息来清除还存在于网络内的冗余消息副本。
2. 路由算法描述
(1)计算一跳邻居之间最大角度
通过广播位置信息,当前节点可以获取其所有一跳邻居的位置信息。计算任意两个节点和当前节点形成的夹角,选取最大的夹角和形成该最大夹角的邻居组合。
(2)多副本策略
1、当最大角大于等于2/3兀时,选择形成该最大夹角的两个节点作为消息的中继节点;邻居节点随机分布,选择最大角的两个节点可以让消息副本的分布方向更广,获得更大的覆盖面积。
2、当最大角少于2/3兀时,则优先选择最远的节点作为中继节点:邻居节点分布集中,选择两个中继节点会加剧信息冗余,而只选择一个离当前节点最远的点可以很好地平衡消息冗余和投递率。
优点:多副本策略不需要捕获网络拓扑知识,只需要利用一跳邻居节点的位置信息,信息的可靠性和可获得性都非常高,提高了路由的可靠性,同时减少了路由发现的复杂性,不需要借助额外的辅助信息,因而不会限制路由的应用场景,具有更好的通用性;在中继节点的选择上综合考虑方向分布和距离分布的优势做出优化,尽量选择较少较优的节点,在不影响消息投递率的情况下进一步减少了资源消耗。
(3)单副本策略
主要完成任务: ①寻找最终的目的节点;
②将消息快速传递到更远的新区域;
③检测到消息成功传递后,删除消息副本来刷新缓存。
3.仿真实验
TSH的核心思想是改变时间片的划分,从而改变每个时间片内多副本策略所占的时间,可以更加灵活地控制负载和投递率之间的平衡。
(1)改变节点缓存空间大小。TSH具有很高的投递率和较低的负载率,并且路由性能稳定,在网络资源缺乏和充裕两种情况下都可以取得令人满意的路由性能,因而具有更好的通用性和实用性。
(2)改变消息生存周期。First Contact和Binary Spraj & Wait只适用于消息生存周期非常长的应用场景。Epidemic的只适用于消息生存周期很短的网络。TSH 可以始终维持较高的消息投递率和相对较低的负载率,因而其适用范围受消息生存周期长短的限制较弱,具有更好的通用,但其在消息生存周期不太长的情况下可以取得最好的路由性能。
(3)不同时间片划分的TSH。在节点移动性弱的网络中,当网络资源受限、负载能力有限时,将每个时间片内多副本策略所占时间比减少到50%以内,可以获得更高的投递率和令人满意的路由性能,而当缓存资源充裕和网络负载能力较强时,将多副本策略所占时间比增加到50%以上,可以获得更高的投递率和更好的路由性能。
基于一跳邻居的地理路由算法
-
动机及网络模型假设
标准的分布式路由算法分为距离向量(DV)、路径向量(PV)和链接状态(LS) 三类。但是它们需要获得多于一跳的邻居信息,然而由于网络拓扑频繁割裂及较高的端到端时延,往往导致收集到的邻居信息过时。
提出一种新的路由策略(geographical routing protocol based on one-hop information, GRONE),只依靠节点一跳邻居的位置信息做出路由选择。
需要解决的一个问题是如何在提高路由性能与降低传输成本之间取得更好的平衡。
假设:
(1)路由算法对任何节点的移动路径的有效性不作假设。
(2)消息的副本数量由某种方法来控制,避免引起广播风暴。
(3)不使用特殊受控节点和事先部署的基础设施,以此来确保整个网络的移动自组性。
(4)不作与全局拓扑知识相关的假设,因此我们的路由算法在真实场景中更为实用。 -
关键问题
(1)虽然较远的节点会暂时增加消息的覆盖范围, 但如果覆盖区域在开始时不均匀,结果将会变得越来越不均匀,从而使算法的平均性能退化。所以要让覆盖区域更接近一个圆。此外为了增加消息的覆盖范围,源节点、中继节点将消息沿着远离源节点的方向传播。S是消息的源节点,S中心的大圆表示消息的覆盖区域,我们做与直线SM垂直的线,因此得到了A和B和所在位置的向量。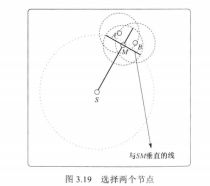
(2)此外当方向决定时,选择一个更远的中继节点可以降低消息覆盖范围的重合度, 进而更加有效地利用网络资源。
-
基于效用函数的节点选择策略
(1)无法获知关于目的节点的信息,例如距离或方向等。唯一最大化与目的节点接触概率的方法是将消息尽可能地均匀分布。
(2)为了使消息分布均匀,节点的下一跳选择应该参考它的对等节点的选择。而获知对等节点选择的唯一方法是猜测它最可能选择的方向。
(3)使消息均匀分布的明智方法是让每个节点都选择与预期方向最近的节点,正如上面计算的兀/4。
(4)GRONE也预先定义一个效用函数,并基于定义的效用选择下一跳中继节点。
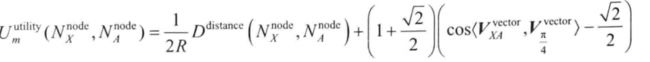
结果:当位于相同方向时,更远的中继节点会带来更大的效用值。同时当 距离相同时,与期望方向越相似则效用值越高。因此U由中继节点的方向和距离所决定。 -
k阶消息冗余度(K-MRD)
假设N是包含一个或多个节点的集合,并且所有节点持有消息,我们定义k阶消息冗余度k-MRD,并用S表示,其取值等于N中k个节点的覆盖面积之和。 -
详细的路由协议
保管传输:当节点接收到来自另一个节点的保管传输,该节点成为该bundle的保管者,这意味着该节点将永久的保存bundle的副本消息,直到保管责任被解除,这确保了逐条传输的可靠性。以此加强端到端的可靠传输。节点是否接受消息并进行保管取决于该节点的当前资源、路由情况、消息大小、剩余生存时间和优先级、安全情况及本地策略限制等。
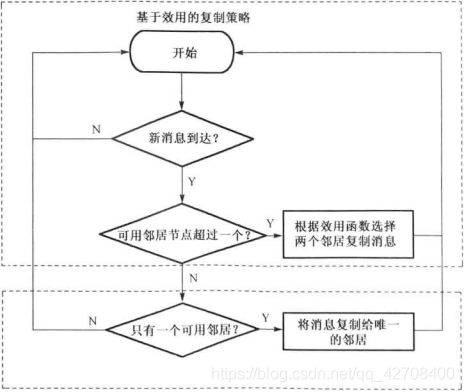
GRONE中的两个复制策略:单一复制和基于效用的复制。每个 节点首先需要逐个检查它携带的消息,并传送所有可以传送的消息。对于剩余的消 息,节点会采用两种复制策略中的一种来进行保管传输。假设N是当前做出决策的节点,N将首先检查它的邻居表,当只有一个活动的邻居时采用单一复制策略 然而当有多个邻居节点存在时,将会利用基于效用的复制策略,因此避免了消息在网络中的洪泛。
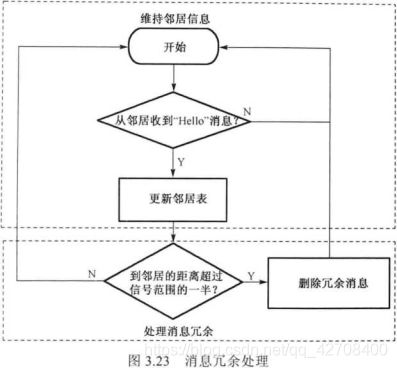
邻居表的更新过程和消息冗余处理机制。它们都依赖于节点之间交换的“Hello”消息。容迟网络中节点携带的能量有限,我们应当充分利用每个 “Hello”消息,因此我们将消息冗余处理机制绑定到“Hello”消息上。而我们倾向于从复制任务中分离出冗余处理机制,所以消息还应该被传递给距离N小于R/2的节点。
“Hello”消息可以帮助一个节点将自身信息通知其他的邻居节点,因此我们让每个节点通过交换“Hello”消息来彼此维持一个邻居表。
- 仿真实验
结果:GRONE 的投递率和Epidemic —样高。但是GRONE的负载率比Epidemic 低很多,因为GRONE釆用了基于效用函数的复制机制,并在一定程度上减少了不必要的转发操作。此外,消息冗余处理机制也帮助GRONE减少了消息副本数量。当消息间隔增加时,两个协议的负载率都减少,这是因为网络产生的消息越少,中继操作越少。同时增加缓存空间是解决高负载率的一个好方法。当节点移动速度提高时,负载率也会提高。当整个网络的连通性加强时,GRONE的负载率要远低于Epidemic。