自动化测试:Selenium8种元素定位+unittest框架设计


作者简介:
笔名,软件测试君。参与过汇丰银行,国家电网,中国电信等多个大型项目的研发和管理,擅长的技术领域为安全测试,性能测试,自动化框架搭建与维护,曾受南京航空航天大学邀请分享Linux、oracle等测试技术,具备10年开发+测试实战经验,担任过高级软件测试讲师,校企软件技术分享嘉宾。
1、摘要
主要技术点:
在项目网页中,以【html分析+selenium定位+python代码+运行结果页面】的模式详解8种元素的定位方法。
可以直接套用于项目的自动化框架:以开源项目Agileone为例,讲解一个项目的自动化测试框架如何设计与实现。
关键字
Selenium自动化测试、Selenium+unittest+HTMLtestrunner框架设计、Selenium8种元素定位方法。
Selenium初识
1.Selenium 简介
selenium 是一个 web 的自动化测试工具,通过使用浏览器访问目标站点进而对一个页面上的各个控件进行操作,如对输入框输入内容,对按钮点击,对页面刷新,对单选框,复选框进行点击选择等等操作。很好的实现了用工具模拟人的操作对访问进行自动化测试。在软件测试中可以很好的完成自动化测试,在爬虫中使用,selenium通过驱动浏览器,完全模拟浏览的操作,比如跳转、输入、点击、下拉等进而进行跳转,获取页面有用信息。
2.Selenium使用环境
这个要从selenium的使用环境说起,使用selenium的过程中会加载浏览器,比如chrome,则需要在本地加载与浏览器版本匹配的驱动文件。
一、介绍
Selenium作为python的独立的第三方库使用,需要通过pip命令安装,命令如:pip install selenium,核心为webdriver驱动,在py文件中通过from selenium import webdriver导入,导入驱动后赋值给对象driver,通过driver的各种方法操作页面对象。
总结selenium使用环境:
python语言环境下
浏览器(如chrome)
浏览器对应的驱动文件(webdriverchrome.exe)
代码如下:

#导入驱动文件
from selenium import webdriver
#加载驱动文件的路径
driver=webdriver.Chrome(r’C:\webdriver\chromedriver.exe’)
Selenium 8种方法定位元素
Web页面的控件可以通过元素定位的方式获取到,在当前web页面上,鼠标右击查看源码,调出html源代码。通过html中的标签及其属性结合selenium的元素定位方法可以定位到需要的输入框、按钮、链接、图片等页面元素。

1、通过id定位元素
在agileone这个项目中,可以发现用户名的输入框,其中id的值为‘usernmae’,则可以通过find_element_by_id(“username”)获取到输入框。
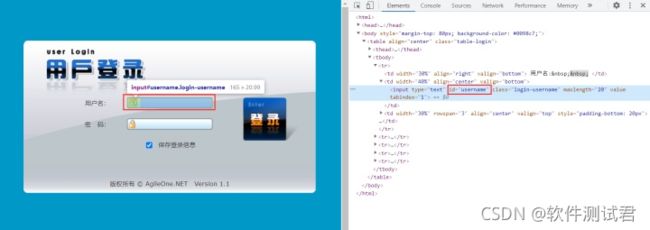
可运行代码如下:
from selenium import webdriver
import time
# 驱动文件路径
driver=webdriver.Chrome(r"E:\webdriver\chromedriver.exe")#加载chromedriver驱动
# 打开百度首页
driver.get("http://localhost:8081/agileone/")
# 等待网页打开
time.sleep(5)
# 通过id定位s输入框,并且输入内容'admin'
driver.find_element_by_id("username").send_keys("admin")
# 等待5秒
time.sleep(5)
运行结果:
在用户名输入框输入admin

2、通过name定位元素
在agileone这个项目中,可以发现用户名的输入框,其中name的值为‘username’,则可以通过find_element_by_name(“wd”)获取到输入框。
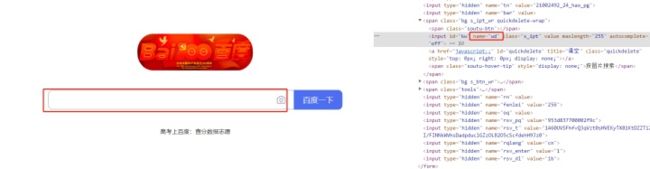
代码部分:
from selenium import webdriver
import time
driver=webdriver.Chrome(r"E:\webdriver\chromedriver.exe")
driver.get(r"https://www.baidu.com/")
time.sleep(3)
driver.find_element_by_name('wd').send_keys('建党100周年')
driver.find_element_by_id('su').click()
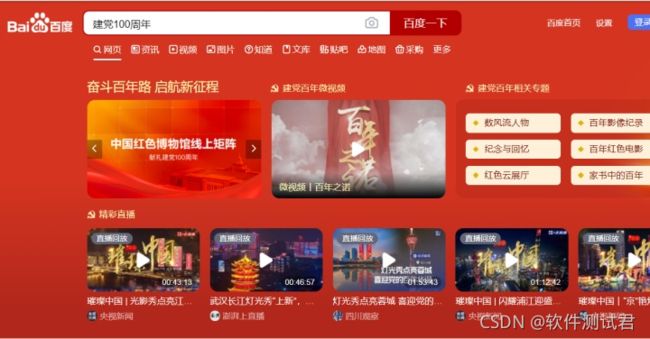
运行结果:
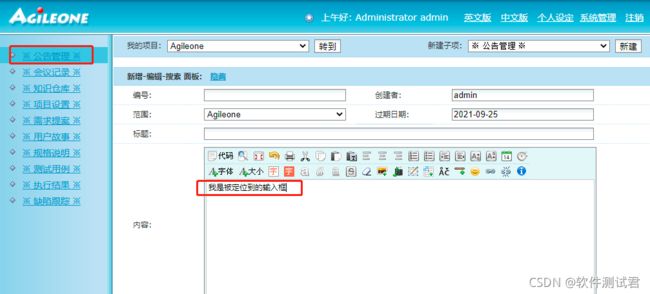
3、通过tag_name定位元素
分析公告管理页面发现,‘内容’的输入框的tag为‘iframe’。通过find_element_by_tag_name(‘iframe’)定位到输入框。

代码如下:
from selenium import webdriver
from time import sleep
# 加载驱动文件的路径
driver=webdriver.Chrome(r'C:\webdriver\chromedriver.exe')
# 打开浏览器
driver.get('http://localhost:8081/agileone/')
# 通过以下3行代码完成登录操作driver.find_element_by_id('username').send_keys('admin')
driver.find_element_by_id('password').send_keys('admin')
driver.find_element_by_id('login').click()
sleep(3)
#通过by_partial_link_text定位到公告管理,并且单击进入对应的页面
driver.find_element_by_partial_link_text('公告管理').click()
sleep(3)
#通过by_tag_name定位输入框
driver.find_element_by_tag_name('iframe').send_keys('我是iframe')
# 等待5秒
sleep(5)
代码运行结果如下:
4、通过class_name定位元素
可以通过class的值为‘login-password’唯一定位到密码输入框。
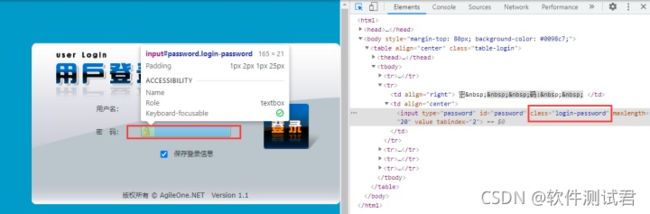
对应的代码:
from selenium import webdriver
from time import sleep
# 加载驱动文件的路径
driver=webdriver.Chrome(r'C:\webdriver\chromedriver.exe')
# 打开浏览器
driver.get('http://localhost:8081/agileone/')
# 通过class定位元素,并输入'admin'
driver.find_element_by_class_name('login-password').send_keys('admin')
# 等待5秒
sleep(5)
运行结果如下,明明框接收到了值。

5、通过link_text
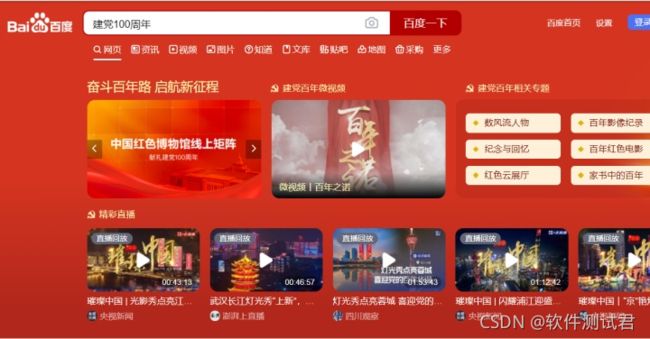
在百度页面,‘新闻’等链接有文本信息,比如可以通过文本内容为新闻,定位到新闻链接。
可以采用方法find_element_by_link_text(‘新闻’)。

from selenium import webdriver
from time import sleep
# 加载驱动文件的路径
driver=webdriver.Chrome(r'C:\webdriver\chromedriver.exe')
# 打开浏览器
driver.get(r'https://www.baidu.com/')
# 通过link_text定位元素
driver.find_element_by_link_text('新闻').click()
# 等待5秒
sleep(5)
运行结果

6、通过partial_link_text
通过部分文本也可以定位到元素,比如‘新闻’中的‘闻’字。
代码如下:
from selenium import webdriver
from time import sleep
# 加载驱动文件的路径
driver=webdriver.Chrome(r'C:\webdriver\chromedriver.exe')
# 打开浏览器
driver.get(r'https://www.baidu.com/')
# 通过partial_link_text定位元素
driver.find_element_by_partial_link_text('闻').click()
# 等待5秒
sleep(5)
运行结果如下:

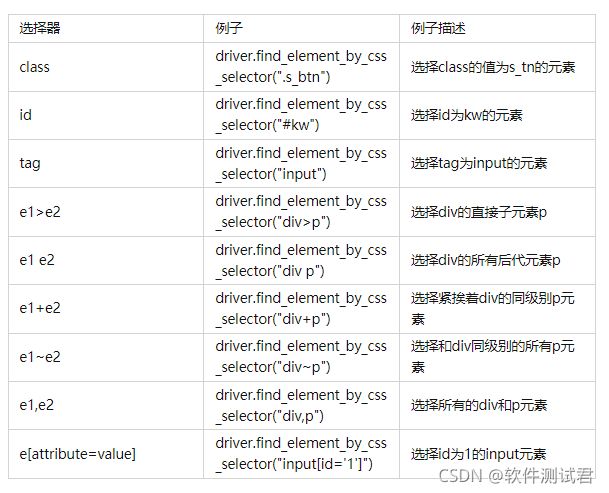
7、通过css定位元素
css定位原理同上述,都是根据标签的属性来锁定元素,只是语法不同,但是可以完成更复杂的高级定位。
总结如下:
页面分析:
通过前面分析,我们知道百度的首页中,输入框的id为kw,那么对应的自动化脚本应该如下:
代码部分:
#导入驱动文件
from selenium import webdriver
import time
# 加载驱动文件的路径
driver=webdriver.Chrome(r'C:\webdriver\chromedriver.exe')
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过xpath定位搜索框,并输入'建党100周年'
driver.find_element_by_css_selector('#kw').send_keys('建党100周年')
# 等待5秒
time.sleep(5)
8、通过xpath定位元素
Xpath也是定位元素的一种方法,有自己的语法。

页面分析:
通过前面分析,我们知道百度的首页中,输入框的id为kw,那么对应的自动化脚本应该如下:
代码部分:
#导入驱动文件
from selenium import webdriver
import time
# 加载驱动文件的路径
driver=webdriver.Chrome(r'C:\webdriver\chromedriver.exe')
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过xpath定位搜索框,并输入'建党100周年'
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('建党100周年')
# 等待5秒
time.sleep(5)
运行结果
Selenium自动化框架设计
框架结构:selenium+python+unittest+HTMLTestRunner,该框架可以直接套用于项目中。
1、项目目录结构

- 一级目录一般是项目名称。
- 二级目录有具备的模块,如有a_regist模块,b_login模块等;同时把report报告目录和主程序runner.py也放在二级目录。
- 三级目录是python模块文件,建议取名为test_二级模块名.py。比如test_regist.py、test_login.py。
【注意:二级目录名称前面的a、b字符是为了改变程序运行的顺序,在实际项目中,结构清晰的框架,更方便维护和调用。】
2、框架运行原理
对于搭建python+selenium这样的框架来说:
首先有一个主入口模块,叫runner.py,运行此模块可以执行所有用例,类似于点击一下启动按钮。所有其他的用例和最后用例执行完生成的报告,都是依赖于runner.py。
在runner.py中,首先要导入需要用到的库,比如unittest框架等,其次找到用例存放的路径,定义报告生成的格式,最后调用run方法运行测试用例,把结果写入报告。
整个框架在运行的时候,只需要运行runner.py这个主入口程序,其中关于这个程序主要实现:
- 通过unittest.defaultTestLoader.discover()方法收集所有的测试用例
- 构造测试报告,通过HTMLTestRunner指定报告生成的路径和名称
【备注:测试用例即在每个py文件的test开头的函数】
3、通过HTMLTestRunner的run方法,运行所有的测试用例
3、具体代码详解

test_register.py是项目的一个注册页面,且以test开头命名符合runner.py中搜索用例的规则。所以该文件中包含需要的测试用例。
import time
import unittest
import random
from selenium import webdriver
username = ‘wang’+str(random.randint(1,10000))
class Test_Register(unittest.TestCase):
‘’‘注册模块’’’
@classmethod
def setUpClass(cls):
driver = webdriver.Chrome(r"e:\webdriver\chromedriver.exe")
driver.implicitly_wait(10)
driver.get(r"http://localhost:8081/phpwind732/register.php")
cls.driver=driver #声明类属性
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def setUp(self):
time.sleep(3) # 为了看到演示效果
def tearDown(self):
time.sleep(3) # 为了看到演示效果
def test_00_regist(self): #测试用例
‘’‘测试注册用户名过短’’’
driver=self.driver
time.sleep(3)
driver.find_element_by_css_selector(‘input[onclick*=“unpermit()”]’).click()
time.sleep(3)
driver.find_element_by_id(“regname”).send_keys(‘t’)
time.sleep(3)
driver.find_element_by_id(“regpwd”).send_keys(“123456”)
driver.find_element_by_id(‘regpwdrepeat’).send_keys(‘123456’)
driver.find_element_by_id(‘regemail’).send_keys(username+’@qq.com’)
driver.find_element_by_css_selector(‘input[type=“submit”]’).click()
time.sleep(3)
msg=driver.find_element_by_id(‘regname_info’).text
time.sleep(3)
self.assertIn(“用户名长度错误”,msg)
def test_01_regist(self):
‘’‘测试注册成功’’’
driver = self.driver
time.sleep(3)
driver.find_element_by_css_selector(‘input[onclick*=“unpermit()”]’).click()
time.sleep(3)
driver.find_element_by_id(“regname”).send_keys(username)
time.sleep(2)
driver.find_element_by_id(“regpwd”).send_keys(“123456”)
driver.find_element_by_id(‘regpwdrepeat’).send_keys(‘123456’)
driver.find_element_by_id(‘regemail’).send_keys(‘Ms’+username+’@qq.com’)
time.sleep(3)
driver.find_element_by_css_selector(‘input[type=“submit”]’).click()
time.sleep(3)
msg = driver.find_element_by_css_selector(‘form tr:nth-of-type(1) td:nth-of-type(1)’).text
time.sleep(3)
self.assertIn(“注册成功”, msg)
if name == ‘main’:
unittest.main(verbosity=2) #运行类里面的方法

test_login.py是项目的登录页面,且文件命令以test开头,符合用例文件的命令规则,即该文件里面包含需要执行的测试用例。

4、项目框架维护
如何维护自动化测试用例?【增删改用例】
在已有框架的基础上,每个测试场景都是一个独立的.py文件。假如,需要增加一个查询的用例,则根据模块命令规则新建test_query.py,在该模块中,用selenium元素获取方法加元素定位方法完成业务操作,比如通过id找到输入框,通过send_keys方法输入内容,通过class的值等定位查询按钮,点击查询按钮,完成页面的查询操作等操作,在该方法里面同样可以增加断言来判断是否查询成功,并把结果记录到报告。
该自动化的框架结构比较简单,引用了很多封装好的库,如果想研究直接继承过来的类或方法,可以在python的lib库里找到unittest这个文件夹,里面包含了unittest的所有类和方法的实现,方便大家对底层封装的理解。
最后: 可以关注公众号:伤心的辣条 ! 进去有许多资料共享!资料都是面试时面试官必问的知识点,也包括了很多测试行业常见知识,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
好文推荐
转行面试,跳槽面试,软件测试人员都必须知道的这几种面试技巧!
面试经:一线城市搬砖!又面软件测试岗,5000就知足了…
面试官:工作三年,还来面初级测试?恐怕你的软件测试工程师的头衔要加双引号…
什么样的人适合从事软件测试工作?
那个准点下班的人,比我先升职了…
测试岗反复跳槽,跳着跳着就跳没了…