2021斯坦福CS224N课程笔记~4
4. 依存解析 Dependency Parsing
参考文档:
https://zhuanlan.zhihu.com/p/420736640
https://www.showmeai.tech/article-detail/237
https://zhuanlan.zhihu.com/p/147321515
https://zhuanlan.zhihu.com/p/49992664https://blog.csdn.net/qq_29216461/article/details/126096245
https://zhuanlan.zhihu.com/p/61321995
https://www.showmeai.tech/article-detail/237
句法结构和依存解析
\1. 句法结构:成分和依存(25 分钟)
\2. 依存语法和树库(15 分钟)
\3. 基于转换的依存解析(15 分钟)
\4. 神经依存解析(20 分钟)
提醒/评论:
在周二的作业 3 中,您使用 PyTorch 构建了一个神经依存解析器;
开始安装和学习 PyTorch(作业 3 有“脚手架”,即教学支持和反馈);
参加 PyTorch 教程,周五上午 10 点(在 Zoom 选项下,不是网络研讨会);
最终项目讨论 - 来与我们会面;第 4 周的星期四是本课程的重点。
4.1.句法结构的种类★
句法结构一般包含两种类型:成分和依存。
成分(Constituency):聚焦于短语及句子结构,见图 4.0(a)。
依存(Dependency):聚焦于单词之间的关系,见图 4.0(b)
前者,主要关心的是句子是怎么构成的,词怎么组成短语。所以研究Constituency,主要 是研究忽略语义的“ 语法” 结构(content-free grammars) 。
后者,依赖关系,则主要关心的是句子中的每一个词, 都依赖于哪个其他的词。

注意,在图中我们增加了一个根节点“Root”,这是为了让“瞧”这个字也有依赖的对象。
4.1.1. 成分
句法的成分是指单词可以作为单个成分。
概括地说:成分 = 短语结构语法 = 上下文无关语法(CFG)。短语结构将单词组织成嵌套的成分。
英语中的单词是怎样组合在一起的?
简单地说,起始单词被赋予一个词类(POS),单词可以组合成不同类别的短语,短语可以用递归的方法组合成更长的短语,见图 4.1。【嵌套过程】

详细地说,上下文无关语法由**规则和词表(单词和符号)**组成,见图 4.2。每个规则可以将语言的符号进行组合和排序。
-
符号分为两类。
- 与语言中单词对应的符号(“The”、“dog”)称为**终端(terminal)**符号,见图 4.2(a);
- 在这些终端上表达抽象的符号称为**非终端(non-term inal)符号,**见图 4.2(b)。
即 终端符号是一些具体的单词,而非终端符号就是它的一个抽象**【对象–>类】**
-
词表是一组引入这些终端符号的规则。
- 在每个规则中,箭头(→)右边的项是一个由一个或多个终端和非终端组成的有序列表;
- 箭头左边是一个表示某些集群或泛化的非终结符号。
- 与词表中每个单词相关联的非终端符号是它的词类(POS)。
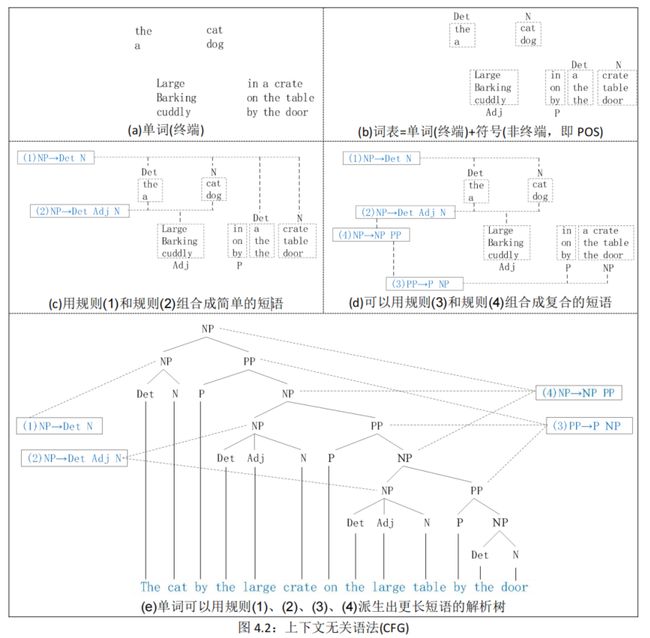
更进一步说,可以把 CFG 理解为生成器:
- 将规则中的“→”箭头理解为“用右边的符号串重写左边的符号”,即用规则生成短语。
- 而且,字符串可以从非终端 NP 派生。
- 因此,CFG 可用于生成一组字符串。
- 而且,字符串可以从非终端 NP 派生。
- 规则扩展的这种序列称为单词字符串的派生(derivation)。
- 通常用解析树(parse tree)来表示派生树(通常以根倒置显示)。
下面是几种生成案例:
- 单词用规则(1)和规则(2)生成简单的短语,例如:(1)the door,(2)a cuddly cat,见图 4.2©;
- 短语用规则(3)和规则(4)生成复合的短语,例如:(3)by the door,(4)the large table by the door,见图 4.2(d);
- 单词用规则(1)、(2)、(3)、(4)派生出更长短语,例如:the cat by the large crate on the large table by the door, 其解析树见图 4.2(e):
- 但是,在计算语言学中占主导地位的是另一种观点:依存。
4.1.2. 依存★★
依存结构是二元关系,它包括一个中心词(head )和一个依存(dependent)。在基于依存的方法中,通过将中心词直接连接到依存于它们的单词,绕过对成分结构的需求,从而使中心词-依存关系很明确。
句子的依存结构展示了单词依赖于另外一个单词 (修饰或者是参数)。词与词之间的二元非对称关系称为依存关系,描述为从head (被修饰的主题) 用箭头指向dependent (修饰语)。一般这些依存关系形成树结构,他们通常用语法关系的名称 (主体,介词宾语,同位语等)。
除了指定中心词-依存偶对之外,按照依存相对于中心词扮演的角色,依存语法还允许我们进一步分类语法关系或语法功能的种类。诸如主语,直接宾语和间接宾语之类的熟悉概念都是我们想到的那种关系。
语言学家已经发展出了依存关系的分类,远远超出了我们熟悉的主语和宾语的概念。**通用依存(Universal Dependency)**关系清单见图 4.3:
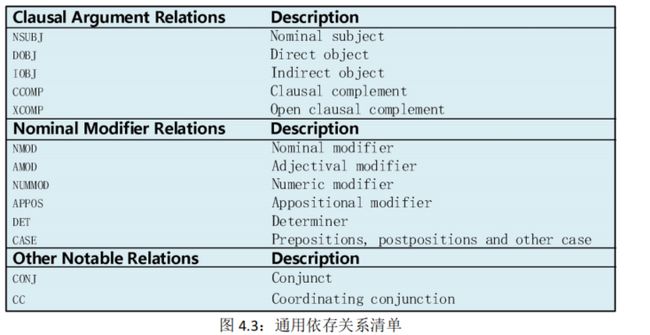
依存结构显示哪些词依赖(修饰、附加或作为其论元)哪些词。
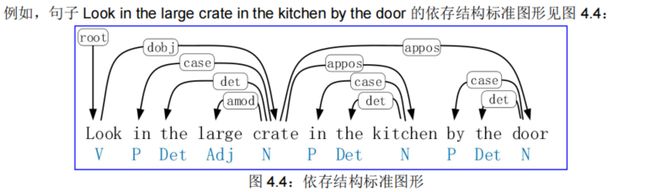
从图 4.4 可见,句子下方是每个单词的词类,句子上方是单词之间的依存关系。
Look 是整个句子的根(root),look 依存于 crate(或者说 crate 是 look 的依存);
in, the, large 都是 crate 的依存;
in the kitchen 是 crate 的修饰;
in, the 都是 kitchen 的依存;
by the door 是 crate 的依存。
为什么我们需要句子结构?原因有以下几点:
(1) 人类通过将单词组合成更大的单元来传达复杂的含义来传达复杂的想法。
(2) 听众需要弄清楚什么修饰了[附着到]什么。
(3) 模型需要理解句子结构才能正确解释语言。
4.2.句法分析的难点
无论我们使用何种方法,进行句法分析都很困难。那么,存在什么客观问题呢?
4.2.1. 介词短语的附着歧义
介词短语如 with, from, of, in 等开头的短语,可以用来修饰其他成分,如果像汉语一样就近原则,倒并不会有什么大问题,而难就难在,有很多句子会有不同的理解。
例 4.1:BBC 的两则报道标题的句子:
- 句子 1:San Jose cops kill man with knife 有歧义,产生两种解释(见图 4.5):
- 第一种解释是:圣何塞警察用刀杀死了那个人,其中 with knife 修饰 kill。
- 第二种解释是:圣何塞警察杀死那个拿刀的人,其中 with knife 修饰 man。
- 句子 2:Scientists count whales from space 也有歧义,产生两种解释(见图 4.6):
- 第一种解释是:科学家从太空中统计鲸鱼,其中 from space 修饰 count。
- 第二种解释是:科学家统计来自太空的鲸鱼,其中 from space 修饰 whale。


例 4.2:介词短语附着歧义倍增的两个句子。
- 句子 1:Put the block in the box on the table in the kitchen. 在这个句子里,有 3 个介词短语(见下划线部分),可以产生如下 5 种解释:
- (1) Put the block ((in the box on the table) in the kitchen).
- (2) Put the block (in the box (on the table in the kitchen))
- (3) Put ((the block in the box) on the table) in the kitchen.
- (4) Put (the block (in the box on the table)) in the kitchen.
- (5) Put (the block in the box) (on the table in the kitchen)

4.2.2. 并列范围的歧义
英语中并列连词有很多,最经典的有:and,or,so,for,but,yet 等…;固定搭配的有:not only…but(also),not only…but…(all well),both…and,either…or,neither…nor,too…to 等…
连词 and 是链接两个或者两个以上的单词、词组或子句用的。
- 如果是在三个以上的词(短语)并列的场合,通常只在最后一个词(短语)前加 and
- 这种情形,and 加不加“逗号”都是可以的
- 还有种情况就是表示顺序关系的比如 and then 就可以不加逗号,直接连接。
- 英语中的逗号不能表示一个完整的句子,一般都是主从关系或者是并列关系的才会用逗号隔开。
==连词 and 和逗号,最容易引起并列结构的歧义,==见以下两个例子。


4.2.3. 形容词修饰语歧义

4.2.4. 动词短语附着歧义
例 4.6:由动词短语附着引起的歧义,见图 4.11:
句子 Mutilated body washes up on Rio beach to be used for Olympics beach volleyball 有歧义,产生两种理解:

4.2.5. 依赖路径识别语义关系
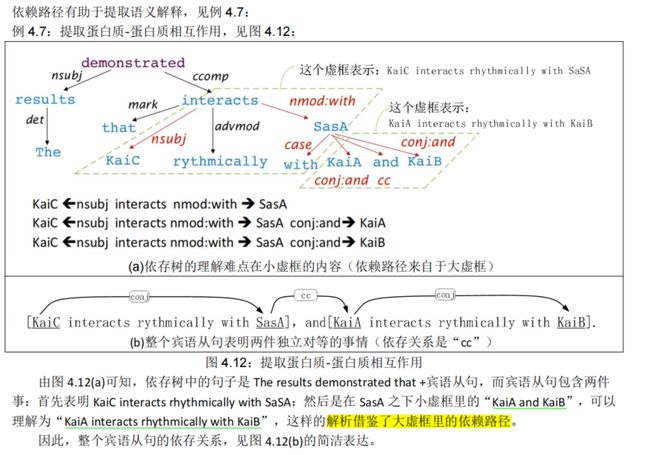
4.3.依存语法和树库
4.3.1. 依存语法和依存结构★★★
依存语法是给定一个输入句子S,分析句子的句法依存结构的任务。依存句法的输出是一棵依存语法树,其中输入句子的单词是通过依存关系的方式连接。
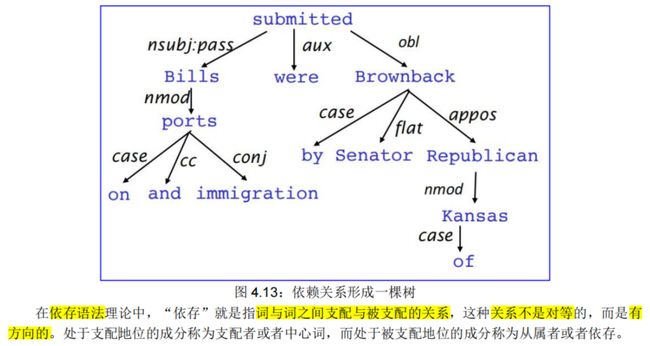
依赖句法假定句法结构由词汇项之间的关系[让箭头从中心词指向依存词(箭头中包含用到的依存关系)]组成。一般地,依赖关系常用“箭头”来表示,并且在箭头上会打印出语法关系的名称(主语、介词宾语、同位语等)。箭头将中心词(head)(统治者、上级、摄政者)与依存(dependent)(修饰语、下级、下属)连接起来。
因此,标准的依存关系是一个三元组:关系名称、统治者、依存者。
通常,依赖关系形成一棵树(连接的、无环的、单根的),见图 4.13:
4.3.2. 依存语法/解析的历史
在依存结构中,有些人以一种方式画箭头,有些人用其他方式画箭头。
我们遵循 Tesnière 提出的惯例:让箭头从中心词指向依存词…
我们通常会添加一个假的 ROOT(伪根),因此每个单词都依赖于 1 个其他单词(节点),见图 4.15:

4.3.3. 通用依存树库★★★
由上下文无关语法规则组成的足够健壮的语法可以用于将解析树分配给任何句子【4.1.1. 成分】。这意味着可以构建一个语料库,其中每个句子都与相应的解析树配对。这样的句法注释语料库称为树库(Treebank)。树库在句法分析以及语言学对句法现象的研究中扮演着重要的角色。
已经创建了各种各样的树库,通常是通过使用解析器(在接下来的几章中描述的那种)自动解析每个句子,然后使用人类(语言学家)手动更正解析。宾州树库(Penn Treebank)项目(包含 POS 标记集)已经从Brown、Switchboard、ATIS 和华尔街日报的英语语汇中生成了树库,以及阿拉伯语和汉语的树库。
许多树库使用依存表示,比如通用依存树库(http://universaldependencies.org)。
通用依赖树库得益于带注释的数据的兴起,图 4.16 是通用依赖树库的应用:

通用依存树库是一个统一的并行系统,可用于人类的任何语言。
优点:用一条规则捕捉很多信息,效率高;
缺点:规则越来越复杂,没有共享和重用人类所做工作。
改进:建立句子结构的树库,使效率更高。
虽然构建树库似乎比编写语法(手工)慢得多,用处也小的多,但是树库给了我们很多东西,比如:
• 劳动力的可重用性
• 许多解析器、词类标注器等都可以建立在它之上
• 语言学的宝贵资源
• 覆盖面广,不仅仅是一些直觉
• 频率和分布信息
• 一种评估 NLP 系统的方法
4.3.4. 依存的条件偏好
依存解析的信息来源是什么?
\1. 双词关联:依存[讨论→问题]是合理的;
\2. 依存距离:大多数依存关系都在附近的单词之间;
\3. 中介材料:依存关系很少跨越中间动词或标点符号;
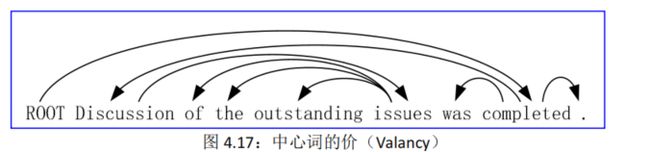
\4. 中心词的价(Valency):一个中心词通常在哪一边有多少依存关系?
Tesnière 在《结构句法基础》(1959)中将化学中“价”的概念引入依存语法中。“价”亦称“配价”或“向”(法文 valence,德文 valenz,英文 valence/ valency)。一个动词所能支配的行动元(名词词组)的个数即为该动词的价数。也就是说,它能支配几个行动元,它就是几价动词。
例如,在汉语中,
零价动词:“地震、刮风”;
一价动词:“病、醉、休息、咳嗽、游泳”等;
二价动词:“爱、采、参观、讨论”等;
三价动词:“给、送、告诉、赔偿”等;
再如:我给你东西(“给”支配三个行动元:我、你、东西)。
例如,在图 4.17 的英语中,Discussion 是二价名词,issues 是四价名词,completed 是二价动词。
4.3.5. 依赖解析
依存解析,就是通过为每个词选择它所依存的其他词(包括 ROOT)来解析句子。
依存解析通常有一些限制:
• 只有一个词是 ROOT 的依赖;
• 不要循环 A → B、B → A。
因此,依赖关系就成为一棵树。
那么,问题来了:箭头是否可以交叉(见图 4.18)?

这就引出投射性和非投射性问题。
4.3.6. 投射性
投射性的定义:当单词按线性顺序排列时,没有交叉依存弧,所有弧都在单词上方。
对应于 CFG 树的依存关系必须是投射性的,即通过将每个类别的 1 个孩子作为中心词来形成依存关系。大多数句法结构都是像这样投射的,但依存理论通常确实允许非投射结构(见图 4.19)来解释移位的成分,这是因为,如果没有这些非投射依存关系,那么你就不能轻易地正确理解某些结构的语义【4.4.7. 处理非投射性】。

非投射结构有其必要性,因为它可以考虑两个问题:远距离的依赖关系和灵活的词序,见图 4.20:

4.4.基于转移的依存解析(Transition-Based Parsing)★
这个转移系统是一个状态机,它由这些状态之间的状态和转换组成。该模型引发了从一些初始状态到多个终点状态之一的一个转换序列。
基于转换的解析是在良好的机器学习分类器指导下的贪婪附着选择。但是对于依赖与中心词距离过远情况来说,该方法效果不如基于神经网络的依存解析。
Transition-based 依存语法依赖于定义可能转换的状态机,以创建从输入句到依存句法树的映射。
- 「学习」问题是创建一个可以根据转移历史来预测状态机中的下一个转换的模型。
- 「解析」问题是使用在学习问题中得到的模型对输入句子构建一个最优的转移序列。
4.4.1. 依存解析方法的概述
依存解析在 20 世纪 90 年代后期随着大型基于依存树库的出现而重新流行起来,主要算法有以下几种:
4.4.1.1. 动态规划
Eisner (1996)基于源于宾州树库的双元语法,开发了一种高效的依存解析动态规划方法,给出了一个复杂度为 O(n3)的巧妙算法,通过生成中心词在末端而不是在中间的解析项来实现。
4.4.1.2. 图算法
图算法为一个句子创建一棵最大生成树。这等价于在包含所有可能的弧的完全图中找到一棵生成树,见图 4.21:
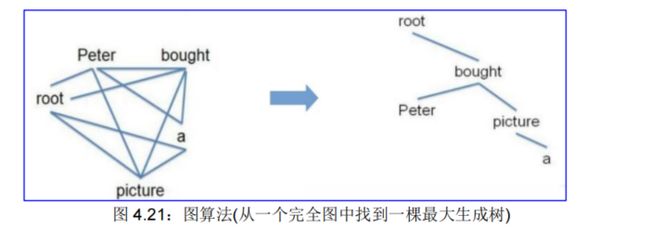
基于图的最大生成树方法是由 McDonald 等人(2005)引入的,他提出的 MSTParser 使用 ML 分类器独立地对依赖项进行评分(他使用 MIRA,用于在线学习,但也可以是其他东西)。
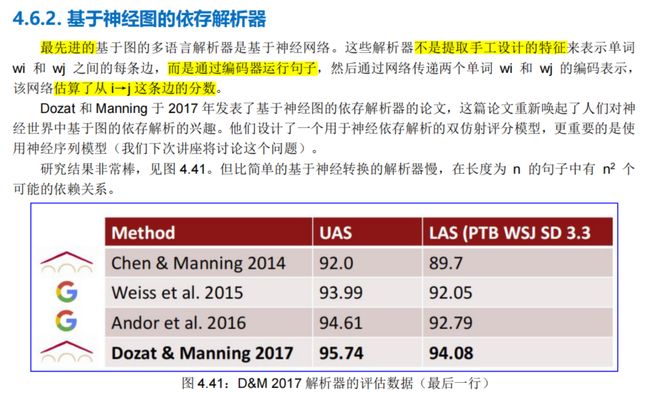
Dozat 和 Manning (2017)提出的基于神经图的解析器(见第 4.6.2 节),非常成功!
4.4.1.3. 约束满足
约束满足讨论的是如何更有效地求解更多种类的问题。使用成分表示来描述状态:即一组变量,每个变量有自己的值。当每个变量都有自己的赋值同时满足所有关于变量的约束时,问题就得到了解决。这类问题称为约束满足问题,简称 CSP(Constraint Satisfaction Problem)。
CSP 搜索算法利用了状态结构的优势,使用的是通用策略而不是问题专用启发式来求解复杂问题。
主要思想是通过识别违反约束的变量/值的组合迅速消除大规模的搜索空间。
Karlsson 等人(1990)提出了依存解析的约束满足的算法:把不满足硬约束的边从图中被消除。换句话说,就是在图上根据约束条件逐步删除不满足要求的边,直到生成一棵树。
4.4.1.4. 基于转换的解析或确定性依存解析
Covington(2001)在当前基于转移的方法基础上,引入了确定性方法。Yamada 和 Matsumoto(2003)、Kudo 和 Matsumoto(2002)引入了入栈-归约范式,以及以支持向量机的形式使用监督机器学习来进行依存分析。
Nivre(2003)定义了现代的、确定的、基于转移的依存解析方法。Nivre 和他的同事随后的工作形式化和分析了许多转移系统、训练方法和处理非投射语言的方法的性能(Nivre 和 Scholz 2004, Nivre 2006, Nivre 和 Nilsson 2005, Nivre 等人 2007, Nivre 2007)。
基于转换的解析是在良好的机器学习分类器指导下的贪婪附着选择。
例如,Nivre 等人(2008)提出的 MaltParser,已证明非常有效(见第 4.4.4 节)。
4.4.2. 基于贪婪转换的解析器★★
Nivre(2003)提出了基于贪婪转换的解析器,它是贪婪区分式依存解析器的一种简单形式。解析器执行一系列自下而上的操作,大体上类似于 shift-reduce 解析器中的“shift”(入栈)或“reduce”(归约),但“reduce”动作专门用于创建中心词在左侧或右侧的依赖关系。

注意,解析器的核心是预言机(即一个分类器)。在每一步中,解析器都要咨询预言机(oracle)。预言机提供了给定当前配置的正确转移操作符,然后将该操作符应用到当前配置,生成一个新配置。当句子中的所有单词都被处理完,并且根节点(ROOT)是堆栈上唯一剩下的元素时,进程结束。
4.4.3. 基本的基于转换的解析器★★

首先,我们来看一个简单的例子。
例 4.8:句子 I ate fish 的解析,见图 4.24:

由图可见,开始状态:堆栈(灰色框)中只有 root,缓存(黄色框)中则是整个句子,A 为空集。
首先进行 Shift 操作将“I”加入堆栈中,其次再进行 Shift 操作将“ate”加入堆栈中。这时候由于“I”是“ate”的主语,所以我们可以进行 reduce 操作,向 A 中加入由“ate”指向“I”的 Left Arc,而堆栈中只保存中心词也就是“ate”。然后再进行 Shift 操作将“fish”移入堆栈,此时缓存为空。这时我们发现**“fish”是“ate”的宾语,因此可以向 A 中加入由“ate”指向“fish”的 Right Arc**。这时堆栈中就只剩下“root”和“ate”,只需再加入一个 Right Arc 就完成了对这句话的分析。
然后,我们来看一个简练的例子。
例 4.9:句子 Book me the morning flight 的解析,见图 4.25 和图 4.26:

最后,我们来看一个详细的例子。
例 4.10:句子 We vigorously wash our cats who stink 的解析,见图 4.27 和图 4.28.
4.4.4. MaltParser 解析器
我们现在来解释如何选择下一步操作。答案是:机器学习。
Nivre 和 Hall(2005)提出了 MaltParser,它是一个用于依赖解析的数据驱动的解析器生成器。给定依赖格式的树库,MaltParser 可用于为树库的语言引入解析器。MaltParser 支持多种解析算法和学习算法,并允许用户定义的特征模型,由词汇特征、词性特征和依赖特征的任意组合组成。
MaltParser 具有以下特点:
- 每个动作都由区分式分类器(例如,softmax 分类器)对每个合法移动(move)进行预测;
- 最多 3 个无类型(untyped)选择:最多|R|×2+1 个有类型(typed)选择;
- 特征:栈顶字,POS;缓冲区首字,POS;等等。
- 没有搜索(以最简单的形式)
- 但是,如果您愿意,则可便利地进行波束搜索(虽更慢但更好):在每个时间步保持 k 个好的解析前缀
- 它提供非常快速的线性时间解析,准确度高——非常适合解析 web 网页
- 该模型的准确度略低于依存解析的最新技术水平

4.4.5. 传统特征表示★★★
基于转换的依存解析旨在预测从初始配置(configration)到某个终端配置的转换序列,从而导出目标依存解析树,如图 4.29 所示。在本文中,我们只检查贪婪解析,它使用分类器根据从配置中提取的特征来预测正确的转换。
我们要做的事情,就是不断地把Buffer中的词往Stack中推,跟Stack中的词判断是否有依赖关系,有的话则输出到Set中,直到Buffer中的词全部推出,Stack中也仅剩一个 Root,就分析完毕了。



我怎么让机器去决定当前的Action呢?即机器怎么知道,Stack中是否构成了依赖关系?
在Nivre的年代,这里使用是机器学习的方法, 需要做繁重的特征工程.这里的特征,往往有个二值特征,即无数个指示条件作为特征,来训练模型,可以想象这么高纬度的 特征是十分稀疏的。因此,这种模型的95%左右的解析时间,都花费在计算特征上。这也 是传统方法的最要问题。
神经依存分析方法[4.5],是斯坦福团队2014年的研究成果,主要就是利用了神经网络的方法代替了传统机器学习方法、用低维分布式表示来代替传统方法的复杂的高维稀疏特征表示。而 整个解析的过程,依然是根据之前的Transition-based方法。
这些特征存在以下问题:
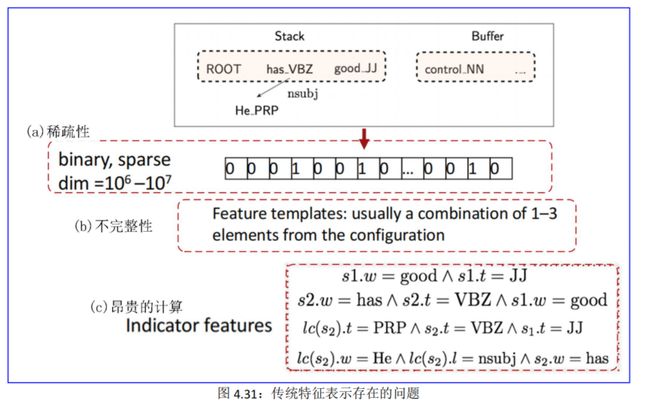
• 稀疏性。特征(尤其是词汇化特征)高度稀疏,这是许多 NLP 任务中的常见问题。这种情况在依存分析中很严重,因为它严重依赖于词到词的交互以及高阶特征。见图 4.31(a)。
• 不完整性。不完整是所有现有特征模板中不可避免的问题。因为即使涉及专业知识和人工处理,它们仍然不包括每个有用单词组合的连词。例如,在几乎所有常用的特征模板中都省略了 s1和 b2的连接,但是如果从 s1到 b2存在弧,则它可能表明我们无法执行 RIGHTARC 操作。见图 4.31(b)。
• 昂贵的计算。指示符特征的特征生成通常很昂贵——我们必须连接一些单词、词类标签或弧线标签来生成特征字符串(由句子 He has good control 根据图 4.30 中的双字特征模板而生成的指示符特征),并在包含数百万个特征的巨大表中查找它们。实验表明,超过 95%的时间是在解析过程中被特征计算消耗的。见图 4.31©。
到目前为止,我们已经讨论了基于转换的依赖解析的预备基础和稀疏指示符特征的存在问题。在接下来的部分中,我们将详细说明用于学习密集特征的神经网络模型以及证明其效率的实验评估。

4.4.6. 依存解析的评估★
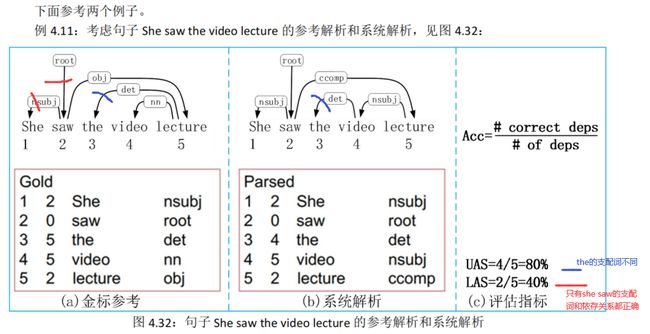
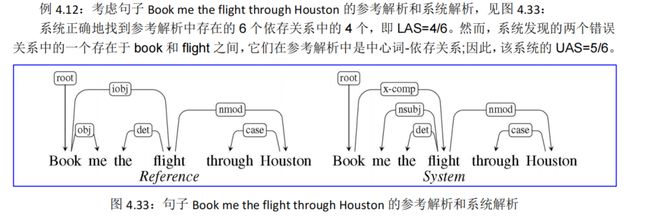
依存解析器的评估是通过测量它们在测试集上的工作情况来进行的。一个明显的度量标准是精确匹配(exact m atch,EM)——有多少句子被正确解析。这个度量相当悲观,大多数句子都被标错了。这样的度量不够细粒度,不足以指导开发过程。我们的度量标准必须足够敏感,以判断是否进行了实际的改进。
因此,评估依存解析器最常见的方法是有标签的(LAS )和未标签(UAS )的附着正确度。
- 有标签的附着是指将一个词恰当地赋值给它的中心词,并建立正确的依存关系。
- 未标签的附着只是查看分配的中心词的正确性,忽略了依存关系。
- 给定一个系统输出和相应的参考解析,正确度就是输入中单词的百分比,这些单词被赋予了正确的中心词和正确的关系。
- 这些度量标准通常称为有标签的附着得分(LAS )和未标签的附着得分(UAS )。
- Unlabeled Attachment Score(UAS):所有词中找到其正确支配词的词所占的百分比,没有找到支配词的词(即根结点)也算在内。
- Labeled Attachment Score(LAS):所有词中找到其正确支配词并且依存关系类型也标注正确的词所占的百分比,根结点也算在内。
4.4.7. 处理非投射性
对于非投射性问题【4.3.6. 投射性】,可能有如下处理方法:
(1) 在非投射弧上宣告失败
(2) 使用只有投射表示的依存形式
上下文无关语法(CFG)只允许投影结构;你提升了投射性违规的中心词
(3) 使用后处理器到投射依存解析算法来识别和解析非投射链接
(4) 添加至少可以模拟大多数非投射结构的额外转换
例如,添加额外的 SWAP 转换,参见冒泡排序
(5) 转移到不使用或不需要任何投射约束的解析机制
例如,基于图的 MSTParser 或 Dozat 和 Manning (2017)
4.5.基于神经的依存解析(Neural Dependency Parsing)★★★★
为什么需要神经网络句法分析器
传统特征表示稀疏、不完全、计算代价大(SVM之类的线性分类器本身是很快的,而传统parser的95%时间都花在拼装查询特征上了)。
虽然有很多深度学习模型应用在依存语法上,这部分特别侧重于基于贪心和基于转移的神经网络依存语法分析器。与传统的基于特征的判别的依存语法分析器相比,神经网络依存语法分析器性能和效果更好。与以前模型的主要区别在于这类模型依赖稠密而不是稀疏的特征表示。
我们将要描述的模型采用上一部分中讲述的标准依存弧转换系统【即为基于转移的依存解析】。最终,模型的目标是预测从一些初始状态C到一个终点状态的转换序列,对模型中的依存语法树进行编码的。
首先明确,我们的预测任务,是根据当前的状态,即Stack、Buffer、Set的当前状态,来构建特征,然后预测出下一步的动作。
在神经依存分析中,我们的特征是怎么构建的呢?我们可以利用的信息包括词(word)、词性(postag)和依赖关系的标签(label)。我们对这三者,都进行低维分布式表示,即通过Embedding的方法,把离散的word、label、tag都转化成低维向量表示。
对于一个状态,我们可以选取stack、Buffer、set中的某些词和关系,构成一个集合,然 后把他们所有的embedding向量都拼接起来,这样就构成了该状态的特征表示。
至于**选择哪些词、关系,这个就是一个「经验性」**的东西了,在斯坦福的论文中可以详细了 解。整个模型的网络结构也十分简洁:
前馈神经网络模型



4.5.1. C&M 2014 解析器
几乎所有当前的依赖解析器都基于数百万个稀疏指示符特征进行分类。这些特征不仅泛化性很差,而且特征计算的成本限制了解析速度。Chen and Manning(2014)提出了一种学习神经网络分类器的新方法,用于贪婪的、基于转换的依赖解析器。因为这个分类器**只学习和使用少量的密集特征**,所以它可以非常快地工作,同时在英文和中文数据集上的未标记和标记附件分数上实现了大约 2%的改进。具体来说,C&M 2014 解析器能够以 92.2%的未标记附件分数在英语 Penn Treebank 上每秒解析 1000 多个句子。
具体的实验数据见图 4.34:
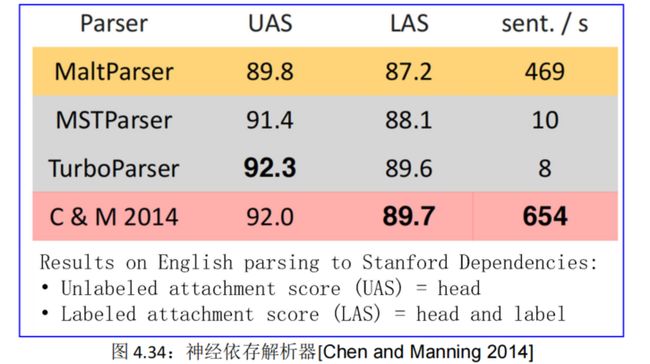
由图可知,C&M 2014 解析器在准确性和速度方面都更胜一筹。与 arc-eager 和 arc-standard 解析器的基线相比,C&M2014 解析器在所有数据集上的 UAS 和 LAS 上实现了约 2% 的改进,同时运行速度提高了约 20 倍。
4.5.2. 第一场胜利:分布式表示★
分布式表示 取代 离散型表示
【传统方法拼接单词、词性、依存标签,新方法拼接它们的向量表示:】


4.5.3. 第二场胜利:非线性分类器
根据第 2.8 节的论述,softmax 分类器可以学习具有非线性决策边界的更复杂的函数,能够正确地作出分类,所以神经网络能获胜。一个简单的前馈神经网络多类分类器如图 4.36 所示:

4.5.4. 神经依存解析器模型架构及其分析
4.5.4.1. 模型架构

![]()


4.5.4.2. 模型分析
我们将分析输入数据和检查学到的参数,并希望研究这些密集特征捕获的内容。我们使用权重,这些权重是从英语宾州树库(使用斯坦福依赖关系进行)中学习得到的。
我们分析三个问题:

这个模型,既可以用来决定 dependency labels,也可以用来决定 POS tags,只不过输入不同,输出也不同。输入和输出,在设置中人工定义,并且可以修改。


4.5.5. 句子结构的依存解析
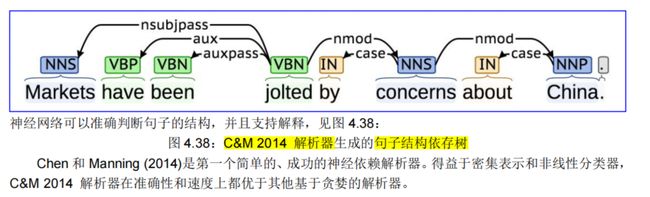
4.5.6. 基于转换的神经依存解析的进展
这项工作由其他人进一步开发和改进,特别是在 Google。
4.5.6.1. SyntaxNet 框架

POS 标记 P = {NN, NNP, NNS, DT, JJ, . . .}(for English)
和弧标签 L = {amod, tmod, nsubj, csubj, dobj, . . .}( for Stanford Dependencies on English)
4.5.6.2. Paesey McParseface 解析器


4.6.基于图的依存解析
基于图的方法是第二个重要的依赖解析算法系列。基于图的解析器比基于转换的解析器更准确,尤其是在长句子上; 当**中心词离依存词很远时**,
- 基于转换的方法会遇到麻烦(McDonald and Nivre,2011)
- 基于图的方法通过对整个树进行评分来避免这种困难,而不是依赖于贪婪的局部决策
此外,与基于转换的方法不同,基于图的解析器可以生成非投射树。虽然投射性对英语来说不是一个重要问题,但对于世界上的许多语言来说,这绝对是一个问题。
4.6.1. 基于特征图的依存解析器

4.6.2. 基于神经图的依存解析器