IDA Pro 使用技巧、动态调式 so、monitor.bat
From:IDA Pro7.0 使用 技巧 总结:https://www.52pojie.cn/thread-886103-1-1.html
IDA Pro 7.7 全插件绿色版:https://www.chinapyg.com/thread-142494-1-1.html
hex-ray 官网 ida pro 版本 :https://hex-rays.com/products/ida/news/
hex-ray 官网文档:https://hex-rays.com/documentation/
安全相关文章 ( 车联网 ):https://zhuanlan.zhihu.com/p/559716931
向分析人员常用 API 列表:https://zhuanlan.zhihu.com/p/465387959
IDA Pro反汇编工具初识及逆向工程解密实战:https://zhuanlan.zhihu.com/p/461862715
俗话说,工欲善其事,必先利其器,在二进制安全的学习中,使用工具尤为重要,而 IDA 又是玩二进制的神器。参考《IDA pro权威指南》(第二版),记录一些使用过程。
IDA Pro 安装成功会后会显示两个运行程序 “IDA Pro(32bit)” 和 “IDA Pro(64bit)”,分别对应32位和64位程序的分析。idaq.exe负责反编译32位可执行文件,idap64.exe负责反编译64位可执行文件。IDA 支持常见的PE格式,DOS、UNIX、Mac、Java、.NET 等平台的文件格式。
:https://bbs.kanxue.com/thread-271124.htm
硬件断点、软件断点
- 硬件断点:由硬件特性实现(数量有限),是通过监测地址来触发断点的。所以,硬件断点可以设置在任何地方,不管是 FLASH,ROM 还是 RAM,只要给定地址就可以了。
- 软件断点:是通过监测特定的指令来触发断点的。在某个地址设置软件断点的时候,仿真器会将这个地址的 "数据 / 指令" 替换成一个特殊格式的指令。断点单元通过监测这个特殊格式的指令来触发断点。因为需要执行替换操作,所以软件断点只能设置在RAM里面。软件断 适用于运行于内存中的程序(软件实现)。以x86为例,向某个地址打入断点,实际上就是往该地址写入断点指令INT 3,即0xCC。目标程序运行到这条指令之后就会触发SIGTRAP信号,gdb捕获到这个信号,根据目标程序当前停止位置查询gdb维护的断点链表,若发现在该地址确实存在断点,则可判定为断点命中。
硬件断点是对地址的直接监测,依赖于CPU寄存器,所以数量有限,软件断点因为是监测替换后指令通常是无限的。硬件断点比软件断点的功能更强。硬件断点的本质就是在指定内存下断点,内存可以位于代码段(函数断点)也可以是数据段(数据断点)。可以设置事件有执行、写入、读写时中断。
1、一些 二进制 工具
在《IDA pro权威指南》的开篇一两章中,先是介绍了几款常用于二进制研究的工具,我这里简单的记了几个,介绍一波:
- C++filt:可以用于显示出c++中复杂的重载后的函数名称
- PE tools:是一组用于分析Windows系统中正在运行的进程和可执行文件的工具
- string:可以用于直接搜索出 elf 文件中的所有字符串。参数 -a 表示搜索整个文件,参数 -t 可以显示出每一个字符串的偏移,参数-e 可以用于搜索更多的字符编码的字符串,如Unicode编码
- strip:可用于 elf 去符号,去符号后仍然保持正常功能但增加了逆向的难度,出题恶人必备
开发 IDA 的天才是 Ilfak,他的个人博客有很多 IDA 的教程:https://www.hexblog.com/
linux 下可执行文件分析
:https://zhuanlan.zhihu.com/p/319710983
- 1. file 可执行文件 可查看可执行文件是ARM架构还是X86架构
- 2. nm 可执行文件 可查看文件中的符号,包括全局变量,全局函数等
- 3. ldd 可执行文件 可查看文件执行所需要的动态库
- 4. strings 可执行文件 可查看文件中所有的符号,包括编译器版本信息
- 5. readelf 可执行文件 可查看文件的所有详细信息,包括文件的头信息,动态库信息,段信息等
file 基本信息查看
linux 下有个最常用的通用命令,来分析任何文件的基本格式,那就是file 可以看到基本信息,比如是什么类型文件,只是概述,还有些其他选项,可以用-h 查看。
- -b:列出辨识结果时,不显示文件名称;
- -c:详细显示指令执行过程,便于排错或分析程序执行的情形;常与 -m 一起使用,用来在安装幻数文件之前调试它
- -f <文件名>:指定一个或多个文件名,让file依序辨识这些文件,格式为每列一个文件名称;
- -L:直接显示符号连接所指向的文件类别;
- -m <魔法数字文件>:指定魔法数字文件;
- -v:显示版本信息;
- -z:尝试去解读压缩文件的内容。
- -i:显示MIME类别
ldd 打印程序依赖的共享库
-v 详细信息模式,打印所有相关信息
-u 打印未使用的直接依赖
-d 执行重定位和报告任何丢失的对象
-r 执行数据对象和函数的重定位,并且报告任何丢失的对象和函数
--help 显示帮助信息
示例:ldd /bin/vim
xxd
xxd命令可以为给定的标准输入或者文件做一次十六进制的输出,它也可以将十六进制输出转换为原来的二进制格式,即将任意文件转换为十六进制或二进制形式
dd
dd命令用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。
nm 符号查看
nm命令是Linux下自带的强大的文本分析工具,是命令来源于name的简写。该命令用来列出指定文件中的符号(如常用的函数名、变量等,以及这些符号存储的区域)。它显示指定文件中的符号信息,文件可以是对象文件、可执行文件或对象文件库。如果文件中没有包含符号信息,nm报告该情况,单不把他解释为出错。nm缺省情况下报告十进制符号表示法下的数字值。
对于一些动态库,直接nm可能查不到信息,可以通过nm -D命令查看。
参数说明:
-A / -o / --print-file-name: 在输出时加上文件名;
-a / --debug-syms: 输出所有符号,包含debugger-only symbols;
-B / --format=bsd: BSD码显示,兼容MIPS nm;
-C / --demangle: 将低级符号名解析为用户级名字,可以使得C++函数名更具可读性;
-D / --dynamic: 显示动态符号。该选项只对动态目标(如特定类型的共享库)有意义;
-f format / --format=format 使用format格式输出。format可以选取bsd、sysv或posix,该选项在GNU的nm中有用。默认为bsd
-g / --extern-only: 只显示外部符号;
-l / --line-numbers: 对于每个符号,使用debug信息找到文件名和行号;
-n / -v / --numeric-sort: 按符号对应地址的顺序排序,而非按符号名字字符顺序排序;
-P /--portability: 按照POSIX2.0标准格式输出,等同于使用 -f posix;
-p / --no-sort: 按照目标文件中遇到的符号顺序显示,不排序;
-r / --reverse-sort: 反转排序;
-s / --print-armap: 当列出库成员符号时,包含索引。索引的内容:模块和其包含名字的映射;
-u / --undefined-only: 只显示未定义符号;
--defined-only: 只显示定义了的符号。

常用选项:
-A 每个符号前显示文件名
-D 显示动态符号
-g 仅显示外部符号
-r 反序显示符号表
strings 查看二进制文件中的字符串
strings信息可以打印二进制文件中的字符串信息,结合grep进行搜索,用grep命令其实可以直接在二进制文件中搜索内容,但是不够直观,用strings看起来的更直观些
strings 会把任何可打印字符串都显示出来,比nm的内容更多
-a --all:扫描整个文件而不是只扫描目标文件初始化和装载段
-f --print-file-name:在显示字符串前先显示文件名
-n --bytes=[number]:找到并且输出所有NUL终止符序列
- :设置显示的最少的字符数,默认是4个字符
-t --radix={o,d,x} :输出字符的位置,基于八进制,十进制或者十六进制
-o :类似--radix=o
-T --target= :指定二进制文件格式
-e --encoding={s,S,b,l,B,L} :选择字符大小和排列顺序:s = 7-bit, S = 8-bit, {b,l} = 16-bit, {B,L} = 32-bit
@ :读取中选项
查找ls中包含libc的字符串,不区分大小写:strings /bin/ls | grep -i libc
objdump 将二进制代码转汇编指令
objdump是个值得深入学习的指令,不光可以还原汇编指令,还可以读取二进制中特定段的信息,更可怕的是,如果我们的程序是以-g -o0等调试不优化的情况下,用objdump -S指令可能尽可能地还原源代码信息(没看错,是还原出源代码信息),其实也可以理解这些信息是完整的在可执行文件中的,要不然gdb调试的时候没办法单步追踪了,
-a, --archive-headers
显示档案头信息,展示档案每一个成员的文件格式。效果等同于命令 ar -tv
-b, --target=BFDNAME
指定目标码格式。这不是必须的,objdump 能自动识别许多格式,比如 objdump -b oasys -m vax -h fu.o 显示 fu.o 的头部摘要信息,明确指出该文件是 Vax 系统下用 Oasys 编译器生成的目标文件。objdump -i 将给出这里可以指定的目标码格式列表
-C, --demangle[=STYLE]
目标文件中的符号解码成用户级名称。比如移除符号修饰时在变量与函数名前添加的下划线等。
-d, --disassemble 反汇编目标文件,将机器指令反汇编成汇编代码
-D, --disassemble-all
与 -d 类似,但反汇编所有段(section)
-z, --disassemble-zeroes
一般反汇编输出将省略零块,该选项使得这些零块也被反汇编
-EB, -EL,--endian={big | little}
指定目标文件的字节序,在目标文件没描述字节序时很有用,例如 S-records。这个选项只影响反汇编
-f, --file-headers
显示每一个目标文件的头信息
-F, --file-offsets
反汇编时,打印每一个符号的偏移地址
--file-start-context
显示源码/汇编代码(假设为 -S)时,将上下文扩展到文件的开头
-g, --debugging
显示调试信息。企图解析保存在文件中的调试信息并以 C 语言的语法显示出来。仅仅支持某些类型的调试信息。有些其他的格式被readelf -w支持
-e, --debugging-tags
类似 -g 选项,但是生成的信息是和ctags工具相兼容的格式
-h, --section-headers, --headers
显示目标文件各个 section 的头部摘要信息
-i, --info
显示对于 -b 或者 -m 选项可用的架构和目标格式列表
-j, --section=NAME
仅显示指定名称的 section 的信息
-l, --line-numbers
用文件名和行号标注相应的目标代码,仅仅和 -d、-D 或者 -r 一起使用
-S,--source
反汇编时尽可能使用源代码表示。隐含了-d参数
-m, --architecture=MACHINE
指定反汇编目标文件时使用的架构,当待反汇编文件本身没描述架构信息的时候(比如S-records),这个选项很有用。可以用-i选项列出这里能够指定的架构
-M, --disassembler-options=OPTIONS
给反汇编程序传递参数,可以指定多个,使用逗号分隔
-p, --private-headers
打印目标文件格式的特定信息。打印的信息取决于目标文件格式,对于某些目标文件格式,不打印任何附加信息。
-P, --private=OPTIONS
打印目标文件格式的特定信息。OPTIONS 是一个逗号分隔的列表。例如对于XCOFF,可用的选项有 header, aout, sections, syms, relocs, lineno, loader, except, typchk, traceback and toc
-r, --reloc
显示文件的重定位入口。如果和-d或者-D一起使用,重定位部分以反汇编后的格式显示出来
-R, --dynamic-reloc
显示文件的动态重定位入口,仅仅对于动态目标文件意义,比如某些共享库
-s, --full-contents
显示section的完整内容。默认所有的非空section都会被显示
-W[lLiaprmfFsoRt],--dwarf=[rawline,=decodedline,=info,=abbrev,=pubnames,=aranges,=macro,=frames,=frames-interp,=str,=loc,=Ranges,=pubtypes,=trace_info,=trace_abbrev,=trace_aranges,=gdb_index]
显示文件中调试段的内容,如果存在的话
-G, --stabs
显示请求的任何 section 的全部内容。显示段 .stab、.stab.index 和 .stab.excl 的内容
-t, --syms
显示文件的符号表入口。类似于nm -s提供的信息
-T, --dynamic-syms
显示文件的动态符号表入口,仅仅对动态目标文件意义,比如某些共享库。它显示的信息类似于 nm -D,--dynamic 显示的信息
-x, --all-headers
显示所可用的头信息,包括符号表、重定位入口。-x 等价于 -a -f -h -p -r -t 同时指定
-w, --wide
为具有超过80列的输出设备格式化某些行。也不要在显示符号名称时截断符号名称
--start-address=ADDRESS
从指定地址开始显示数据,该选项影响 -d、-r 和 -s 选项的输出
--stop-address=ADDRESS
显示数据直到指定地址为止,该项影响-d、-r和-s选项的输出
--prefix-addresses
反汇编的时候,显示每一行的完整地址。这是一种比较老的反汇编格式
--no-show-raw-insn
反汇编时,不显示汇编指令的机器码。当使用--prefix-addresses时,这是缺省选项
--adjust-vma=OFFSET
当解析信息时,首先给所有的段添加偏移值offset。当段地址与符号表不符时,这个选项很有用。比如将段放置到特殊地址,因为某个格式无法表示段地址,比如 a.out
--special-syms
显示特殊符号与用户不关心的符号
--prefix=PREFIX
当使用 -S 时,指定前缀添加到绝对路径中
--prefix-strip=LEVEL
指定剥离绝对路径中多少个前缀目录名。此选项只有在使用了选项 --prefix=PREFIX 才有效
--insn-width=WIDTH
指定反汇编后的指令输出的行宽,单位字节
-V, --version
版本信息
-H, --help
帮助信息
readelf 读取ELF文件格式
如果二进制文件是ELF格式的,通过file文件可以查看文件格式.使用readelf指令可以方便分析ELF文件的结构,比如节信息,elf头文件信息,比如我们在分析文件是否为病毒文件的时候,需要读取elf文件头信息,做一些特征的判断,或作为特征参与机器学习的判断。
示例:readelf -h xxx
动态查看文件结构
ltrace
跟踪进程调用库函数过程 ltrace ./a.out
这在查看系统调用耗时很有用。
# -T 是查看调用时间开销
ltrace -T
#-t -tt -ttt 是查看调用绝对时间,t越多越精确
ltrace -t
ltrace 查看系统调用信息 ltrace -S
strace
strace和ltrace的命令差不多,strace更偏向于系统调用的追踪或信号产生的情况。安装命令 yum -y install strace
强大地方在于可以指定系统调用的类型:
-e trace=set
只跟踪指定的系统 调用.例如:-e trace=open,close,rean,write表示只跟踪这四个系统调用.默认的为set=all.
-e trace=file
只跟踪有关文件操作的系统调用.
-e trace=process
只跟踪有关进程控制的系统调用.
-e trace=network
跟踪与网络有关的所有系统调用.
-e strace=signal
跟踪所有与系统信号有关的 系统调用
-e trace=ipc
跟踪所有与进程通讯有关的系统调用
-e abbrev=set
设定 strace输出的系统调用的结果集.-v 等与 abbrev=none.默认为abbrev=all.
-e raw=set
将指 定的系统调用的参数以十六进制显示.
-e signal=set
指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表示不跟踪SIGIO信号.
-e read=set
输出从指定文件中读出 的数据.例如:
-e read=3,5
-e write=set
GDB 命令
gdb命令其实是我们最常用的,调试程序的利器,用来查看二进制文件的结构,非常合适,可以把程序运行起来通过gdb -p pid方便地调试。 也可如下运行:
PEiD、 Exeinfo 检测 PE文件
PEiD只支持检测32位的可执行文件,如果显示不是有效的PE文件,说明你的可执行文件为64位,不能用 PEiD 检测。可以使用 Exeinfo PE 查看,Exeinfo 相当于 PEiD 的升级版,可查看64位的可执行文件
全功能的二进制文件分析工具 Radare2 指南
根据其 https://github.com/radareorg/radare2,Radare2(也称为 r2)是一个“类 Unix 系统上的逆向工程框架和命令行工具集”。它名字中的 “2” 是因为这个版本从头开始重写的,使其更加模块化。
:https://linux.cn/article-13074-1.html
IDA Pro 插件
IDA Pro 插件:https://www.52pojie.cn/thread-1016307-1-1.html
:https://github.com/search?q=ida+plugin

2、IDA 目录结构
在 IDA 的安装根目录下有许多文件夹,各个文件夹存储不同的内容
- cfg:包含各种配置文件,基本IDA配置文件ida.cfg,GUI配置文件idagui.cfg,文本模式用户界面配置文件idatui.cfg,
- idc:包含IDA内置脚本语言IDC所需要的核心文件
- ids:包含一些符号文件
- loaders:包含用于识别和解析PE或者ELF
- plugins:附加的插件模块
- procs:包含处理器模块


3、打开 ida、关闭 ida
打开 ida
打开 IDA 后,IDA 会提供 3 种不同的打开方式:New(新建),Go(运行),Previous(上一个)。

New 选项表明反编译新可执行文件,Go 选项表明直接进入主界面,Previous 选项表明加载已反编译的文件选项。其中 previous 会给出给出之前逆向过的文件
初次打开的时候选择 GO 就可以了。进入之后,选择左上角的 file 中的 open 打开文件。
ida 能自动识别加载的可执行文件类型。IDA 加载文件后,会生成一个可能的文件类型列表,在顶部显示,它将显示最适合处理文件的加载器。
Binary File(二进制文件) 是列表最后一个选项,会一直显示,是IDA加载无法识别文件的默认选项,提供最低级的加载方法。需要使用二进制加载器的情形包括:分析从网络数据包或日志文件中提取出来的rom镜像和破解程序负载。
在processor type【处理器类型】下拉菜单中,可以指定在反汇编过程中使用的处理器模块【在ida的procs目录中】。多数情况下,ida将根据可执行文件头中读取信息,选择合适的处理器。

一旦选择“Binary file”方式加载文件,则需要用户手动填入加载段地址和相对偏移,对应上图“Loading segment”和”Loading offset”选项。该种方式主要应用场景为:分析动态保存的二进制代码、ShellCode二进制代码分析等。选择“Binary file”方式加载文件,IDA不会自动分析代码,用户需根据具体需求自行反汇编二进制代码。
Processor Type:可以指定在反汇编过程中使用的处理器模块。多数情况,IDA将从可执行文件的头中读取到信息,选择合适的处理器。
kernel options:配置特定反汇编分析选项,IDA可利用这些选项该进递归下降过程。通常ida默认的都是最优的。
processor options:选择适用于处理器模块的配置选项。
打开文件以后。IDA主界面:
- IDA View 三种反汇编视图:文本视图、图表视图、路径视图
- IDA View-A:是反汇编窗口。( 空格键 切换 文本视图 与 图表视图 )
- HexView-A:十六进制格式显示的窗口,
- Imports: 导入表(程序中调用到的外面的函数)。导入函数窗口
- Exports: 导出函数窗口
- Functions:程序中所有函数
- Structures:结构体窗口。
- Enums:枚举窗口
- Strings:字符串窗口(字符串窗口:View --> open subviews --> Strings,或者快捷键
shift+F12)
按下 F5 键可以查看伪代码。IDA 图形视图会有执行流,
- Yes 箭头默认为绿色,
- No 箭头默认为红色,
- 蓝色 表示默认下一个执行块。
可以在左侧查看代码的运行过程,按下 空格键 也可以直观地看到程序的图形视图。
关闭 ida

dont pack database【不打包数据库】:仅刷新4个数据库,不创建idb文件
pack database【打包数据库】:将4个数据库组件文件存到idb文件中
pack database 【打包数据库,压缩】:等同于上一个,压缩到idb归档
collect garbage【收集垃圾】:在关闭数据库之前,删除没有的内存页面
dont save the database【不保存数据库】:删除四个数据库组件文件,保留现有未经修改idb文件
ida 创建的 数据库
IDA 会创建一个数据库,名为 IDB文件,它由四个文件组成。
- id0:二叉树形式的数据库
- id1:程序字节标识
- nam:Named窗口的索引信息
- til:给定数据库的本地类型定义的相关信息

当关闭时,可以选择 Don't save database,就不会生成和保存这些文件。
4、IDA 主界面

在 IDA 界面底部有一个交互栏可以执行 Python 命令,能够帮助我们快速进行进制转换。
在 Python 交互中输入 0x45,由于开头的 0x 将会被解释为十六进制数。直接按回车可将 0x45 转换为十进制数,输出结果为 69
将十进制转换为十六进制数,可以使用 hex()函数。Bin()函数将其他进制的数字转换为二进制数。输出结果是 1000101,开头的 0b 代表这是一个二进制数。

菜单栏
File:用于打开、新建、装载、保存、关闭一个文件或是数据库
Edit:用于编辑反汇编代码
Jump:用于跳转到某个位置、地址或是一个窗口
Search:用于搜索代码段、数据、错误等等
View:用于显示文件内容的显示方式
Debugger:调试器,集成在IDA中
Lumina:对元数据进行各种操作
Options:可以进行一些个性化的设置
Windows
Help
导航条:
- 蓝色: 表示常规的指令函数
- 黑色: 节与节之间的间隙
- 银白色: 数据内容
- 粉色: 表示外部导入符号
- 暗黄色: 表示 ida 未识别的内容
如图所示,蓝色方框 标注了 颜色和对应说明:
以上基于 IDA 默认设置介绍各种颜色在导航条的含义,IDA 同时提供了颜色设置,方便用户根据需求选择合适的颜色,对应 “Options” 菜单的“Colors”选项中

可在“IDA Colors”对话框的选择“Navigation band”Table项,在对应选项中设置各项数据的颜色,方便实际场景的分析。
跳转 相关

常用功能、快捷键:
空格键: 切换 文本视图 与 图表视图
ESC: 返回上一个操作地址。(只有在反汇编窗口才是这个作用,如果是在其他窗口按下esc,会关闭该窗口)
G: 直接跳转到某个地址
N: 对符号重命名
Y: 更改变量的类型H: 转换16进制
T: 解析结构体偏移
M: 转换为枚举类型常量冒号键: 常规注释
分号键: 可重复注释。在反汇编后的界面中写下注释
/ : 在反编译后伪代码的界面中写下注释
\: 在反编译后伪代码的界面中隐藏/显示变量和函数的类型描述,有时候变量特别多的时候隐藏掉类型描述看起来会轻松很多
Alt+M: 添加 标签
Ctrl+M: 查看 标签
ctrl+w: 保存 ida 数据库
ctrl+shift+w:拍摄 IDA 快照
Ctrl+S: 查看 段信息。选择某个数据段,直接进行跳转
ctrl+鼠标滚轮:能够调节流程视图的大小
shift+f12:可以打开 string 窗口,一键找出所有的字符串。
X ( ctrl+X ): 对着某个函数、变量按该快捷键,可以查看它的交叉引用。
F5: 查看 伪代码,即 一键反汇编
Shift +F5:打开签名窗口
ALT+L:标记(Lable)
ALT+G:转换局部变量为结构体
ALT+Enter:跳转到新的窗口Alt+T: 搜索 字符串 (文本搜索)
Alt+B: 搜索 十六进制。通常在分析过程中可以用来搜索opcode
伪 C 代码窗口:右键 ---> comment ---> 注释伪 C 代码。
copy to assembly : 把 伪C代码 复制到反汇编窗口的汇编代码。
IDA 可以修改 so 的 hex 来修改 so,edit,然后 edit-patchrogram,
其实也可以 使用 winhex 来实现相同的功能
函数 操作
删除函数:函数窗口中选中函数后,按 Delete 键
P : 创建函数。即定义函数。在反汇编窗口选中对应行后,按P键。即 识别成一个函数
修改函数参数:在函数窗口中选中并按 Ctrl+E 组合键,或在反汇编窗口的函数内部按 Alt+P 组合键
数据类型 操作
在自动分析阶段,字节有时可能被错误地归类。数据字节可能被错误地归类为代码字节,并被反汇编成指令。而代码字节可能被错误地归类为数据字节,并被格式化成数据值。有许多原因会导致这类情况,如一些编译器将数据嵌入在程序的代码部分,或者一些代码字节从未被作为代码直接引用,因而IDA选择不对它们反汇编。模糊程序特别容易模糊代码部分与数据部分之间的区别。
在重新格式化之前首先必须删除其当前的格式(代码或数据。右击你希望取消定义的项目,在结果上下文菜单中选择Undefine(也可使用Edit Undefie命令或热键U),即可取消函数、代码或数据的定义。取消某个项目的定义后,其基础字节将作为原始字节值重新格式化。在执行取消定义操作之前,使用“单击并拖动”操作选择一个地址范围,可以取消大范围内的定义。下面以一个简单的函数为例:
C:光标所在地址处的内容解析成代码
D:光标所在地址处的内容解析成数据
A:光标所在地址处的内容解析成ascll码字符串
U:光标所在地址处的内容解析成未定义内容。
U 键:解析成未定义的内容。u:undefine,取消定义函数、代码、数据的定义
D 键:让某一个位置变成数据。即 解析成 数据
C 键:让某一个位置变成指令。即 解析成 代码
A 键:将选择的信息转换成 ASCII 字符串。
* 键:此处定义为一个数组
O 键:将此处定义为一个地址偏移
导航 操作
Esc 后退到上一位置
Ctrl+Enter 前进到下一位置
G 跳转到某一个特定位置,然后可以输入地址/已经定义的名称
Ctrl+S 跳转到某一区段,然后选择区段即可
类型 操作
IDA 开发了一套类型分析系统,用来处理 C/C++语言的各种数据类型【函数声明、变量声明、结构体声明等】,并且允许用户自由指定。选中变量、函数后按 Y 键,弹出 “Please enter the type declaration”对话框,从中输入正确的 C 语言类型,IDA 就可以解析并自动应用这个类型。
查看 所有 子窗口
:点击“View”中“Open subviews”->“Disaassembly”调出来的。

IDA View 窗口
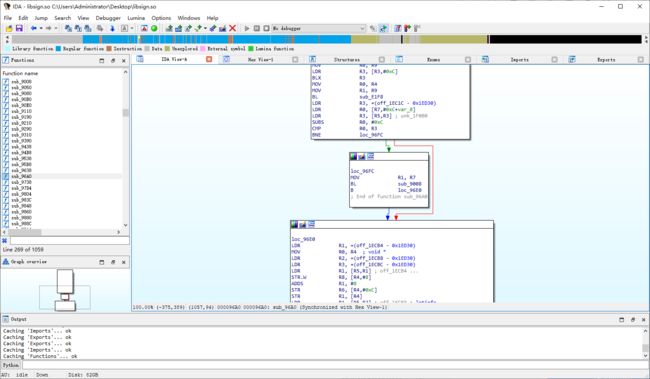
IDA View 包括两种浏览模式,右键能够相互跳转。也可以通过快捷键 "空格键" 相互切换
- 一种是Text View,
- 一种是 Graph View,
虚线:条件跳转
实线:无条件跳转
IDA View 主要包括三个区域:
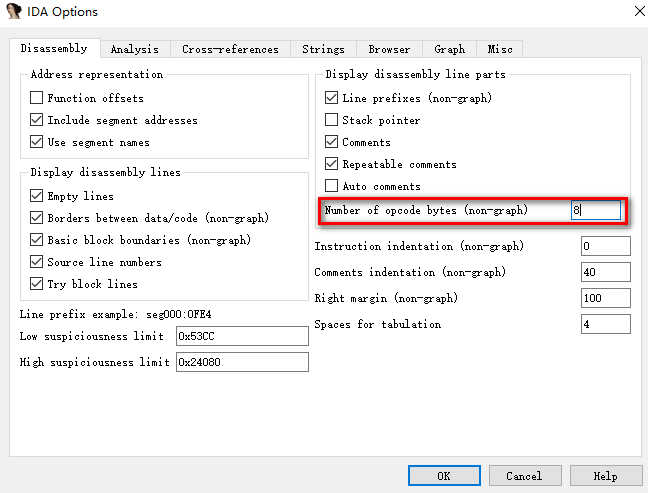
- 地址区: PE文件加载到内存后的虚地址为准,镜像地址+偏移地址,如 0x00401000
- OpCode操作区: 该部分默认。因此,需要 Options->General->设置 Number of opcode bytes为8显示出来,它是16进制数。
- 反编译代码区: IDA主功能区域,能高亮显示,双击函数或变量名能跳转对应的地址。

Hex View 窗口
显示16进制,默认为只读状态,可以用快捷键F2对数据区域(绿色字符区域)在只读和编辑两种状态切换。

Strings 窗口
IDA 的 View 有几个按钮对定位代码很重要,如下图所示:

- Open exports window 打开导出窗口
- Open import window 打开导入窗口
- Open names window 函数和参数的命名列表
- Open functions window 程序调用的所有函数窗口
- Open strings window 打开字符串显示窗口
点击 Strings 显示程序中所有字符串,该窗口有助于你通过程序的运行输出逆向找出对应的代码片断,如下图的字符串及对应的Address。

双击 String 跳转 IAD View 页面,如下图所示的地址,单击会高亮。

strings(快捷键f12):字符串表 包括程序中存储的字符串常量(在逆向分析中对于定位关键函数有很大帮助)。
在逆向分析中,往往我们可以利用 Ida 中的 "交叉引用" 功能找到引用了指定字符串的函数,从而实现了关键函数的定位。比如( 在程序的符号表被 stripped 掉的时候,无法直接搜索 main 函数) 查看字符串 "input:flag" 的引用直接定位到 main 函数
函数 窗口 ( 重要 )
函数窗口:函数名称,区域,起始位置,长度,描述函数的标记。用于分析每一个单独的函数。
在逆向分析中往往都是直接利用 Function windows 查找关键函数对整个程序进行分析。该窗口提供 ctrl+F 的搜索功能,例如可以直接 ctrl+f 定位到 main 函数,选中函数后双击,即可在右侧窗口开始分析,对于一般的函数 IDA 提供强大的反汇编功能,(快捷键f5,f5大法好啊)直接能阅读到c代码,免除了阅读汇编语言的痛苦。
import (导入表)、export (导出表)
导出窗口列出文件的入口点,导入窗口列出由被分析的二进制文件导入的所有函数,表中内容为程序需要的外表函数和可以被外部程序调用的函数(涉及到动态链接的相关知识)
- (1) Exports窗口是导出表(so中能让外部调用的函数)
- (2) Imports窗口是导入表(so调用到外面的函数)
段 窗口
段表 :包程序的各个段的信息比如.text(代码段).data(数据段)(涉及到PE结构的相关知识)
段窗口 segmentation:段的简单列表
结构体 窗口
分析数据结构,双击数据结构名称展开,查看详细布局。
如果程序正使用某个结构体,而 IDA 并不了解其布局,这时 IDA 可以添加该结构体的布局,并将新定义的结构体包含到反汇编代码清单中。IDA 使用 Structures 窗口来创建新的结构体除非结构体已经在 Structures 窗口中列出,否就无法将结构体包含到反汇编代码清单中。IDA将自动在 Structures 窗口中列出任何它能够识别、并确定已被个程序使用的结构体。
IDA 之所以在分析阶段无法识别结构体,可能源于两个原因。首先,虽然 IDA 了解某个结构体的布局,但它并没有足够的信息,能够判断程序确实使用了结构体。其次,程序中的结构体可能是一种 IDA 对其一无所知的准结构体。在这两种情况下,问题都可以得到解决,且首先从Structures窗口下手。
枚举 窗口
enums 可列举,定义枚举类型
5、IDA 常用设置
快照
由于 IDA 不提供撤销的功能,如果你不小心按到某个键,导致ida数据库发生了改变,就得重新来过,所以要记得在经常操作的时候,加上快照:file --> take database snapshot
加完快照后,会生成一个新的 ida 数据库文件,本质上是有点像另存的操作
快捷键:ctrl+shift+w
恢复原始布局
- view --> open subviews: 可以恢复你无意中关闭的数据显示窗口
- windows --> reset desktop:可以恢复初始 ida 布局。简单恢复GUI设置,即回到默认视图,但不会更改任何完成的任务或者反汇编工作。
- Windows-Save desktop :保存这个新的视图,从而形成个人的视图风格
- option --> font: 可以改变字体的相关属性
在流程视图中添加地址偏移
IDA 中的流程视图可以说是非常的好用,简单明了地能看出程序的执行流程,尤其是在看 if 分支代码和循环代码的时候,能够非常直观

但是,我们还可以改得更加好用,在这个视图中添加地址偏移的话,我们取地址就非常方便,不再需要按空格切换视图去找,在菜单栏中设置:option --> general

将该选项打钩后就可以看到效果了:

自动添加反汇编注释
这个功能对于萌新来说非常友好,在刚刚初学汇编的时候, 难免遇到几个不常用的蛇皮汇编指令,就得自己一个个去查,很麻烦,开启了自动注释的功能后,IDA就可以直接告诉你汇编指令的意思
同样是在菜单栏中设置:option --> general

效果如下:

导入 jni.h 分析 jni 库函数
找到 jni.h 文件,单独复制一份并修改复制的文件如下:

导入修改后 jni.h 文件( 快捷方式:Ctrl + F9 ---> 选择 jni.h 头文件 ):

6、IDA 常用操作
创建 数组
在操作IDA的时候,经常会遇到需要创建数组的情况,尤其是为了能方便我们看字符串的时候,创建数组显得非常必要,以下我随便找了个数据来创建数组
首先点击选中你想要转换成数组的一块区域:
接着在菜单栏中选择:edit --> array,就会弹出如下的选项框

下面来解释一下各个参数的意思:
Array element size这个值表示各数组元素的大小(这里是1个字节),是根据你选中的数据值的大小所决定的Maximum possible size这个值是由自动计算得出的,他表示数组中的元素的可能的最大值Array size表示数组元素的数量,一般都根据你选定的自动产生默认值Items on a line这个表示指定每个反汇编行显示的元素数量,它可以减少显示数组所需的空间Element print width这个值用于格式化,当一行显示多个项目时,他控制列宽Use “dup” construct:使用重复结构,这个选项可以使得相同的数据值合并起来,用一个重复说明符组合成一项Signed elements表示将数据显示为有符号数还是无符号数Display indexes显示索引,使得数组索引以常规的形式显示,如果选了这个选项,还会启动右边的Indexes选项栏,用于选择索引的显示格式Create as array创建为数组,这个一般默认选上的
创建好了以后,就变成了这样:

可以看到这些数据已经被当成一个数组折叠到了一起,其中2 dup(0FFh)这样的,表示有两个重复的数据0xff
流程图
折叠流程图中的分支
在流程视图中,分支过多的时候,可以在窗口标题处右击选择group nodes,就能把当前块折叠起来

效果如下:

分支块是可以自己命名的,方便自己逆向理解
函数调用图
菜单栏中:view --> graphs --> Function calls(快捷键Ctrl+F12)

这个图能很清楚地看到函数之间是如何相互调用的
函数流程图
菜单栏中:view --> graphs --> flowt chart(快捷键F12)

这个其实跟IDA自带的反汇编流程视图差不多,他可以导出来作为单独的一张图
创建结构体:
手工创建结构体
创建结构体是在 IDA 的 structures 窗口中进行的,这个操作在堆漏洞的pwn题中经常使用

可以看到,这里已经存在了四个结构体,程序本身存在的,可以右击选择hide/unhide,来看具体的结构体的内容

创建结构体的快捷键是:insert

在弹出的窗口中,可以编辑结构体的名字
这底下有三个复选框,第一个表示显示在当前结构体之前(就会排列在第一位,否则排列在你鼠标选定的位置),第二个表示是否在窗口中显示新的结构体,第三个表示是否创建联合体。
需要注意的是,结构体的大小是它所包含的字段大小的总和,而联合体的大小则等于其中最大字段的大小
在单击ok以后,就定好了一个空的结构体:

将鼠标放在 ends这一行,单击快捷键D即可添加结构体成员,成员的命名默认是以field_x表示的,x代表了该成员在结构体中的偏移

同时,可以把鼠标放在结构体成员所在的行,按D,就可以切换不同的字节大小
默认情况下可供选择的就只有db,dw,dd(1,2,4字节大小)
如果想添加型的类型,可以在option-->setup data types(快捷键Alt+D),进行设置

如图,勾选了第五个和第九个的话,就会出现 dq 和 xmmword 了(代表了8字节和16字节)

如果要添加数组成员则可以对着成员所在的那一行,右击选择array
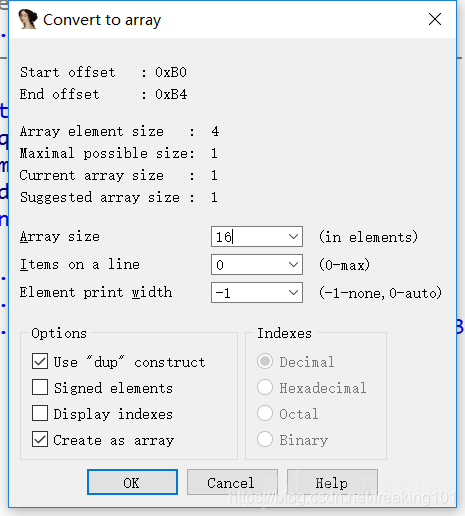
如图,要创建的是16个元素的4字节数组
如果要删除结构体,那么对着结构体按下delete键即可删除
如果要删除成员,则对着成员按下u(undefine)但是需要注意的是,这里只是删除了成员的名字,而没有删除它所分配的空间
如图,我们删除了中间的field_10的数组成员:

会变成这样:

数组所分配的20个字节的空间并没有被删除,这时如果要删除掉这些空间,就需要在原来数组成员所在的第一行中按下Ctrl+S,删除空间(Edit-->shrink struct types)
就可以真正的删除掉成员
给结构体的成员重命名可以用快捷键N
我们在IDA中创建好了结构体以后,就是去应用它了
如图,这是一个典型的堆的题目

可以看到v1是一个新建的chunk的地址指针,而后的操作都是往chunk不同的偏移位置写入内容,为了方便我们逆向观察,可以将其变成一个结构体,通过v1 v1+4 v1+0x48 这样的偏移,创建好结构体后,将char *v1的类型改成mail *v1,(快捷键Y可以更改函数、变量的类型和参数)这个mail是我们创建的结构体的名称,效果如下:

导入C语言声明的结构体
实际上,IDA有提供一个更方便的创建结构体的方法,就是直接写代码导入
在View-->Open Subviews-->Local Types中可以看到本地已有的结构体,在该窗口中右击insert
可以添加新的结构体:

这样就导入了新的结构体:

但同时我们发现structure视图里面,并没有这个结构体,我们需要对着my_structure右击,选择 synchronize to idb
这样structure视图就有了,如图
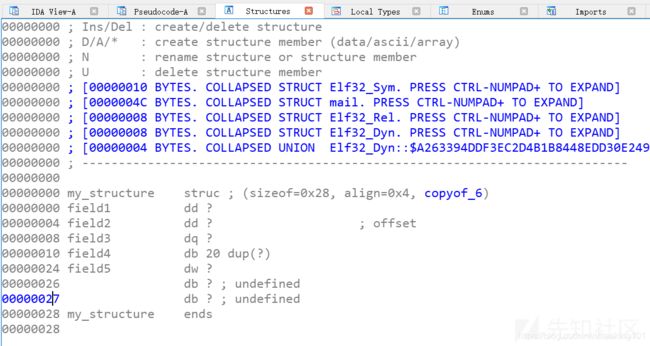
这里你会发现,多出来两个db的undefined的成员,这是因为ida默认是会把结构体统一4字节对齐的,满足结构体的大小为0x28
IDA 动态调试 elf:
这里以一个在Ubuntu虚拟机中的 elf 为例子,进行调试。首先把 ida 目录中的 dbgsrv 文件夹 中的linux_server64 拷贝到 Ubuntu 的 elf 的文件夹下,这个 elf 是 64 位的所有用的是 linux_server64,如果调试的是 32 位的程序,就需要拷贝 linux_server
记得给他们权限,然后在终端运行,这个程序的作用就像是连接ida和虚拟机中elf的桥梁

然后再到ida中进行配置:
在菜单栏中选择:debugger --> process options

注意,application 和 input file 都是填写在虚拟机中的 elf 的路径,记得要加文件名
而 directory 填写 elf 所在目录,不用加文件名
hostname 是虚拟机的 ip 地址,port 是默认的连接端口
parameter 和 password 一般都不用填
设置好了以后点击 ok
接着可以直接在反汇编视图中下断点,只要点击左边的小蓝点即可

这时按下快捷键 F9,可以直接开始调试
按下快捷键 F4,则直接运行到断点处停下

这个就是基本的各个功能区的介绍,上面是我比较喜欢的常用布局,和 ida 默认的不太一样,想要自定义添加一些视图的话,可以在 debugger --> quick debug view 中添加
另外可以在 Windows --> save desktop 来保持当前的视图布局,以后就可以直接加载使用
下面介绍一些常用的快捷键
F7 单步步入,遇到函数,将进入函数代码内部F8 单步步过,执行下一条指令,不进入函数代码内部F4 运行到光标处(断点处)F9 继续运行CTRL+F2 终止一个正在运行的调试进程CTRL+F7 运行至返回,直到遇到RETN(或断点)时才停止.
知道了这些快捷键后,调试起来就比较容易了,ida 调试有个比较方便的地方在于能直接看到函数的真实地址,下断点也非常直观易操作
IDA-python
IDAPython官方函数文档: https://hex-rays.com/documentation/
IDC函数官方文档查询: IDC函数
在 IDA 的最下面有个不起眼的 Output Window 的界面,其实是一个终端界面,这里有 python 终端和 IDC 终端

在 IDA 的运用中,我们经常需要计算地址,计算偏移,就可以直接在这个终端界面进行操作,非常方便
IDA Python 常见模块介绍与脚本使用。在IDA中,有三个重要的库,分别是: IDC、idautils、idaapi
- IDC 他是封装 IDA 与 IDC 函数的兼容性模块.
- Idautils 这个是 IDA 提供给我们的一个高级实用的模块.
- idaapi 他可以允许我们访问更加底层的数据.
在 IDA 中我们要使用脚本有三种方式
- 第一种 :可以直接按 shift + F2 快捷键调出界面,也可以直接在菜单中选择命令脚本.
- 第二种 :可以是写一个脚本文件直接进行引用。
-
第三种:直接在 IDA 底部写命令。
当然上面说的只是很简单的 python 用法,真正的IDA-python的用法是这样的:
这里以简单的一道逆向题来做个例子

这个程序很简单,一开始来个for循环,把judge函数的内容全部异或0xc,这样就导致了程序一运行就会直接破坏掉judge函数

从而使得没法进行后面的flag判断
这里我们就需要写一个脚本来先把被破坏的内容还原,这里 IDA 提供了两种写脚本操作的方法,一种就是 IDC 脚本,一种就是 python 脚本
这里只简单的介绍 IDA-python
而 IDA-python 通过三个 python 模块将 python 代码注入 IDA 中:
- idaapi 模块负责访问核心IDA API
- idc 模块负责提供IDA中的所有函数功能
- idautils 模块负责提供大量实用函数,其中许多函数可以生成各种数据库相关对象的python列表
所有的 IDApython 脚本会自动导入 idc 和 idautils 模块,而 idaapi 模块得自己去导入
这里贴上 IDApython 的官方函数文档 https://www.hex-rays.com/products/ida/support/idapython_docs/,这里包含了所有函数,值得一看。
针对以上的题目,我们只需要做一个脚本,指定 judg 函数的 0-181 范围的字节异或 0xc,即可恢复
judge=0x600B00
for i in range(182):
addr=0x600B00+i
byte=get_bytes(addr,1)#获取指定地址的指定字节数
byte=ord(byte)^0xC
patch_byte(addr,byte)#打patch修改字节在菜单栏中 file --> script file,加载 python 脚本
接着在 judge 函数中 undefined 掉原来的函数,在重新生成函数(快捷键 p),就可以重新 f5 了
脚本中出现的函数都是已经封装在 idc 模块中的,具体可查官方文档

这只是一个简单的 IDApython 的使用例子,实际上这个功能非常强大,能弄出非常骚的操作
pycharm 搭建 ida python 环境
在 PyCharm 中写 IDAPython 脚本:https://blog.csdn.net/qq_45323960/article/details/125493588
先添加 解释器,在添加 自定义路径。路径选择 IDA Pro 7.7\python\3 (3 和 2 表示 Python3 和 Python2 )
之后就可以使用 PyCharm 的智能补全编写 IDAPython 程序了。
这个方法只是在pycharm中编写程序,同时使用pycharm的代码补全,运行是使用ida选择文件运行
用 pycharm 调试 idapython 脚本:
python.exe -m pip install pydevd
pycharm中这样设置
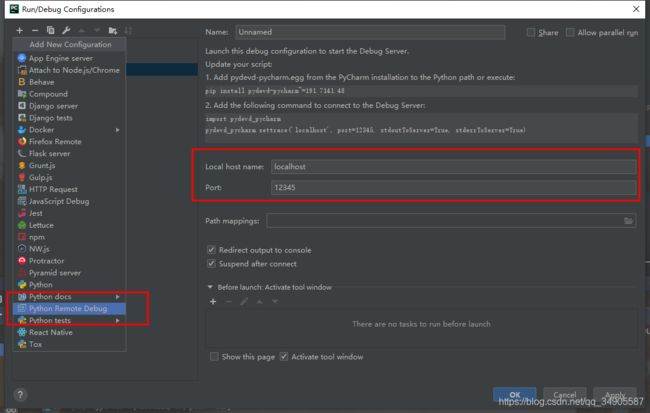
然后设置要调试的程序

这句话相当于插入一个断点
最后先运行pycharm 端的先等到起,然后打开 ida 即可。
IDA 脚本
- python
- IDA 的脚本语言 --- IDC
其中,python语言就不用过多的介绍了,下面简单介绍一下IDC语言。
在IDA软件的帮助选项中,包含着对IDC语言的语法和函数的介绍(相当于官方说明/API手册),如下图所示。
一些常见的 IDC 函数介绍如下(包括但不限于,用到可查询API手册)——
(1)读取和修改数据的函数

(2)用户交互函数

(3)字符串操纵函数

(4)代码交叉引用函数

在 IDA 中运行 python、IDC 脚本/命令 有三种方式,如下图所示。

脚本示例。枚举一个函数的调用方。

IDA 插件
A.基础:插件开发:c++开发的dll文件。具体的知识(如插件的开发、安装、执行等)可以参考《IDA Pro权威指南》中第17章的内容。
B.常见插件:IDA 中自带的插件如下图所示。

官方 获奖 插件:https://plugins.hex-rays.com/
(1)静态分析
- IDA FLIRT Signature Database——用于识别静态编译的可执行文件中的库函数
- IDA signsrch——寻找二进制文件所使用的加密、压缩算法
- IDA scope——自动识别windows函数和压缩、加密算法
- Ponce—— 污点分析和符号化执行工具
- snowman decompiler——C/C++反汇编插件(F3 进行反汇编)
- keystone—— 二进制文件修改工具,可以直接修改汇编
- CodeXplorer——自动类型重建以及对象浏览(C++)(jump to disasm)
- IDA Ref——汇编指令注释(支持arm,x86,mips)
- Hexlight——大括号高亮匹配及跳转(B跳转到匹配括号)
- auto re——函数自动重命名
- nao——dead code 清除
- HexRaysPyTools——类/结构体创建和虚函数表检测
- findcrypt-yara——寻找常用加密算法中的常数
(2)动态调试
IDA sploiter——漏洞利用开发工具,寻找gadget
DIE——动态调试增强工具,保存函数调用上下文信息
sk3wldbg——IDA动态调试器,支持多平台
idaemu——模拟代码执行(支持X86、ARM平台)
(3)其他
Keypatch --- ida补丁神器
IFL
FRIEND—— 用于改进反汇编,将将寄存器/指令文档直接带入IDA视图的IDA插件。
x86emu——嵌入式x86模拟器
Lighthouse—— IDA Pro 的代码覆盖资源管理器
AndroidAttacher
python Editor—— 在 ida 中运行脚本文件和应用程序。
ret-sync—— ret-sync stands for Reverse-Engineering Tools synchronization. It’s a set of plugins that help to synchronize a debugging session (WinDbg/GDB/LLDB/OllyDbg/OllyDbg2/x64dbg) with IDA disassembler. The underlying idea is simple: take the best from both worlds (static and dynamic analysis).让调试器(WinDbg / GDB / LLDB / OllyDbg / OllyDbg2 / x64dbg)与IDA同步的一个插件。
IDAPython 脚本编写指南
- :https://www.cnblogs.com/TJTO/p/13216673.html
- :https://www.cnblogs.com/TJTO/p/13284864.html
Map 文件从 IDA 到 OD
什么是 MAP 文件?
简单地讲, MAP 文件是程序的全局符号、源文件和代码行号信息的唯一的文本表示方法,它可以在任何地方、任何时候使用,不需要有额外的程序进行支持。而且,这是唯一能找出程序崩溃的地方的救星。
在逆向分析的时候IDA可疑获得比较详细的map文件信息,同时结合OD动态调试将IDA中分析出的map文件导入到OD中可以起到事半功倍的效果。
IDA与OD导出使用map文件:菜单栏 ---> File ---> Produce file ---> Creat MAP file
使用IDA导出map文件时,在不需要Label信息的情况下,不要选中"dummy names"选项,否则在Ollydbg中使用LoadMapEx(by forever)加载时,会将OD的注释替换掉
对于 dummy names,IDA帮助中的解释是这样:
Dummy names are automatically generated by IDA. They are used to denote subroutines, program locations and data.
假名字被艾达自动生成。他们是用来表示子程序、程序的位置和数据。
Dummy names have various prefixes depending on the item type and value:
假的名字有不同的前缀根据项目类型和值:
sub_ instruction, subroutine start
locret_ 'return' instruction
loc_ instruction
off_ data, contains offset value
seg_ data, contains segment address value
asc_ data, ascii string
byte_ data, byte (or array of bytes)
word_ data, 16-bit (or array of words)
dword_ data, 32-bit (or array of dwords)
qword_ data, 64-bit (or array of qwords)
flt_ floating point data, 32-bit (or array of floats)
dbl_ floating point data, 64-bit (or array of doubles)
tbyte_ floating point data, 80-bit (or array of tbytes)
stru_ structure (or array of structures)
algn_ alignment directive
unk_ unexplored byte
使用OD载入导出的 map 文件

打 PATCH
打 patch,其实就是给程序打补丁,本质上是修改程序的数据,指令等,这在 CTF 中的 AWD 赛制中经常用到,发现程序漏洞后马上就要用这个功能给程序打好 patch,防止其他队伍攻击我们的gamebox
这里,我是用一个叫 keypatch 的插件进行操作的,IDA 自带的 patch 功能不太好用
安装 keypatch
这个很简单,教程在 https://github.com/keystone-engine/keypatch
下载 Keypatch.py 复制到插件目录
IDA 7.0\plugins\Keypatch.py
下载安装 keystone python 模块,64位系统只需要安装这一个就行
https://github.com/keystone-engine/keystone/releases/download/0.9.1/keystone-0.9.1-python-win64.msi
安装好后,你就会发现这里有个 keypatch 的选项

修改程序指令
如果我们要修改程序本身的指令,怎么做呢

如图,我们要修改 63h 这个值
将鼠标指向该行,按快捷键 Ctrl+Alt+K
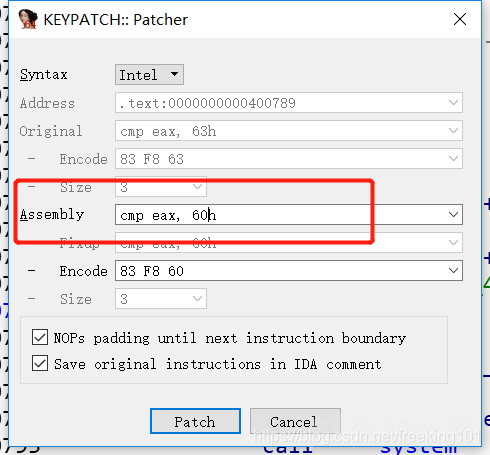
直接输入汇编语句即可修改,打好 patch 后效果如图:

这里会生成注释告诉你,这里打过 patch,非常人性化
接着还要在菜单栏进行设置才能真正使得 patch 生效
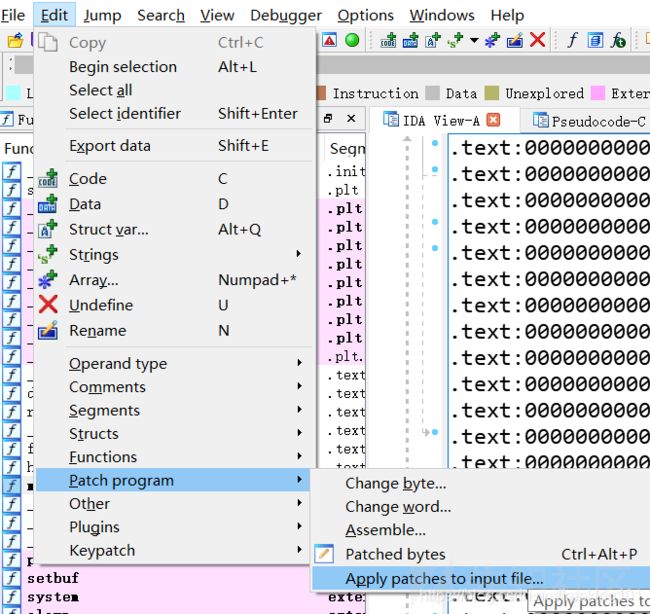
这样一来,原来的程序就已经被修改了
撤销 patch
如果不小心打错了 patch,就可以在这里进行撤销上一次 patch 的操作了

但是如果打了很多次patch,不好分清该撤销哪一次的patch,那么可以在菜单栏中打开patched bytes界面
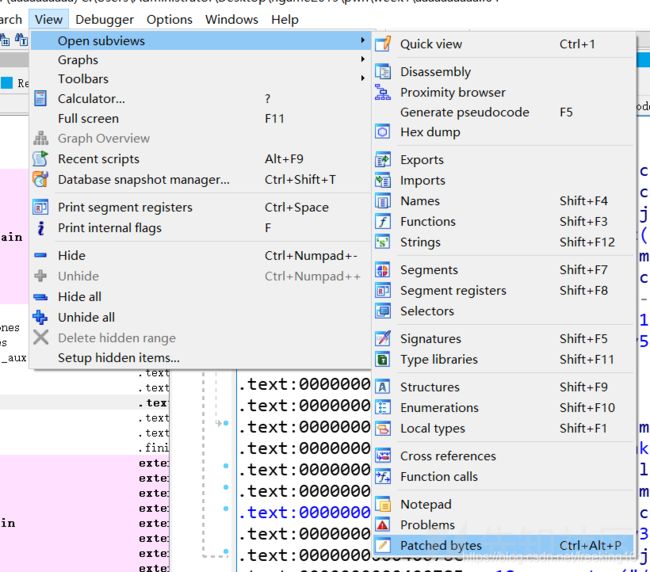
看到所有的patch,要撤销哪一个就右击选择 revert

IDA 导出数据文件
在菜单栏中,这里有个选项可以生成各种不同的输出文件
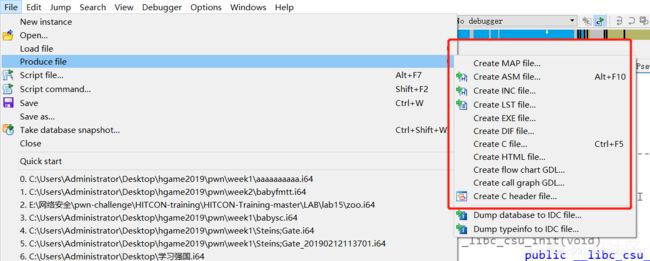
这里简单的介绍前两个文件,后面的大家可以自己去生成测试一下用途,我这里就不详细介绍了
- .map 文件 描述二进制文件的总体结构,包括与构成改二进制文件的节有关的信息,以及每个节中符号的位置。
- .asm文件,也就是汇编了,直接能导出ida中反汇编的结果,这个非常实用,有的时候在逆向中经常遇到大量数据加解密的情况,如果在从IDA中一个个慢慢复制可就太没效率了,直接导出生成asm,在里面复制数据快很多
IDA常见命名意义
IDA 经常会自动生成假名字。他们用于表示子 "函数,程序地址和数据"。
根据不同的类型和值假名字有不同前缀
sub 指令和子函数起点
locret 返回指令
loc 指令off 数据,包含偏移量
seg 数据,包含段地址值asc 数据,ASCII字符串
byte 数据,字节(或字节数组)word 数据,16位数据(或字数组)
dword 数据,32位数据(或双字数组)qword 数据,64位数据(或4字数组)
flt 浮点数据,32位(或浮点数组)dbl 浮点数,64位(或双精度数组)
tbyte 浮点数,80位(或扩展精度浮点数)stru 结构体(或结构体数组)
algn 对齐指示unk 未处理字节
IDA 中有常见的说明符号,如 db、dw、dd 分别代表了1个字节、2个字节、4个字节
IDA 反编译报错
目前来说, 我遇到的反编译报错的情况,一般是两种
-
一是由于程序存在动态加密,导致程序的某些代码段被修改,从而反编译出错,这种情况,就需要去使用 IDA-python 解密一波,再进行 F5 反汇编
-
二是由于某些玄学问题,直接提示了某个地方出错,一般来说,就按照 IDA 的提示,去进行修改。
比如,出现如下报错

那我们就去找 413238 这个地址的地方,提示是说 sp 指针的值没有被找到,说明是这里出错了,那么就去修改sp的值,修改方法如下:

也可以使用快捷键 Alt+K
有的时候,遇到的这种报错

就尝试着把报错的地址的汇编语句改一哈,改成 nop,就可以解决问题
目前来说,我遇到报错的情况不多,一般都可以通过以上方法解决
配置 IDA
在 ida 的根目录的 cfg 文件夹是专门用来存储配置文件的
ida 的主配置文件为 ida.cfg,另外的还有 idagui.cfg,idatui.cfg 这两个配置文件对应 IDA 的 GUI 配置和文本模式的版本
一、ida.cfg
该文件包含了option-->general中的所有选项的配置,可以通过选项中的描述在配置文件总找到相应的选项
这里举几个例子:
SHOW_AUTOCOMMENTS 表示是否自动生成汇编指令的注释
GRAPH_SHOW_LINEPREFIXES 表示是否在流程控制视图中显示地址
VPAGESIZE 表示内存调整参数,当处理非常大的输入文件时,IDA可能报告内存不足而无法创建新数据库,在这种情况下增大该参数,重新打开输入文件即可解决问题
OPCODE_BYTES 表示要显示的操作码字节数的默认值
INDENTATION 表示指令缩进的距离
NameChars 表示IDA支持的变量命令使用的字符集,默认是数字+字母还有几个特殊符号,如果需要添加就改变该参数
二、idagui.cfg
这个文件主要配置默认的GUI行为,键盘的快捷键等,这个很少需要修改,不做过多介绍。感兴趣的可以自己打开该文件观察,并不难懂,改改快捷键还是很容易的
三、idatui.cfg
这个似乎更加不常用。。。不多说了
需要注意的是,以上三个文件是默认配置,也就是说,每次打开创建新的ida数据库的时候,都会以这三个配置文件的设置进行创建,之前临时在菜单栏的设置就会消失,要永久设置ida的配置,就改这三个文件
但,凡是都有例外,在option-->font和option-->colors这两个选项是全局选项,修改一次就永久生效的,不用在以上三个配置文件中改
x86 汇编指令
在反汇编窗口中大多是 eax, ebx, ecx, edx, esi, edi, ebp, esp 等。这些都是 X86 汇编语言中 CPU 上的通用寄存器的名称,是32位的寄存器。这些寄存器相当于C语言中的变量。
- EAX 是”累加器”(accumulator), 它是很多加法乘法指令的缺省寄存器。
- EBX 是”基地址”(base)寄存器, 在内存寻址时存放基地址。
- ECX 是计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
- EDX 则总是被用来放整数除法产生的余数。
- ESI/EDI 分别叫做”源/目标索引寄存器”(source/destination index),因为在很多字符串操作指令中, DS:ESI指向源串,而ES:EDI 指向目标串。
- EBP 是”基址指针”(BASE POINTER), 它最经常被用作高级语言函数调用的”框架指针”(frame pointer)。
- ESP 专门用作堆栈指针,被形象地称为栈顶指针,堆栈的顶部是地址小的区域,压入堆栈的数据越多,ESP也就越来越小。在32位平台上,ESP每次减少4字节。
- 还有一些指令,如:mov,jmp等。
数据转移指令
- MOV 移动
- MOVC 程式记忆体移动
- MOVX 外部RAM和扩展I/O口与累加器A的数据传送指令
- PUSH 放入堆叠
- POP 由堆叠取回
- XCH 8位元交换
- XCHD 低4位元交换
- SWAP 高低4位元交换
算术指令
- ADD 两数相加
- ADDC 两数相加再加C
- SUBB 两数相减再减C
- INC 加一指令
- DEC 减一指令
- MUL (MUL AB乘法指令仅此一条)相乘指令,所得的16位二进制数低8位存累加器A高8位存B
- DIV (DIV AB 除法指令仅此一条)相除指令,所得商存A,余数存B
- DA (DA A 只此一条指令)调整为十进数
逻辑指令
- ANL做AND(逻辑与)运算
- ORL做OR(逻辑或)运算
- XRL 做(逻辑异或)运算
- CLR 清除为0
- CPL 取反指令
- RL 不带进位左环移
- RLC 带进位左环移
- RR 不带进位右环移
- RRC 带进位右环移
控制转移类指令
- JC C=1时跳
- JNC C=0时跳
- JB 位元=1时跳
- JNB 位元=0时跳
- JBC 位元=1时跳且清除此位元
- LCALL 长调用子程序
- ACALL 绝对调用子程序
- RET 由副程式返回
- RETI 由中断副程式返回
- AJMP 绝对转移
- SJMP 相对转移
- JMP @A+DPTR 散转,相对DPTR的间接转移
- JZ A=0时跳
- JNZA 0时跳
- CJNE 二数比较,不相等时跳
- DJNZ 减一,不等於0时跳
- NOP 空操作
位变量指令
- SETB 设定为1
- ORG 程序开始,规定程序的起始地址
- END 程序结束
- EQU 等值指令(先赋值后使用)例:SUM EQU 30H
- DB 定义字节指令
- DW 定义字内容
- DS 定义保留一定的存贮单元数目
- BIT 位地址符号指令 例:SAM BIT P1.0
- RET 子程序返回指令
- RETI 中断子程序返回指令
- $ 本条指令地址
了解这一些,相信大家可以更快的上手 IDA 这个利器了!
示例:IDA pro 调试 exe
:https://zhuanlan.zhihu.com/p/80751993
通过一个简单的题来了解一下 IDA 的基本操作,题目是 bugku 的一个简单的逆向,Easy_re。
将题目下载下来,发现是一个exe可执行文件,先运行一下看看
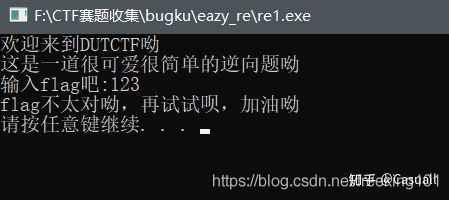
有一些字符串提示,让你输入一个字符串,提示输入flag,随便输入几个字符,看一下有什么提示。
然后开始进入分析阶段,首先通过 Detect It Easy 这个软件查看一下程序的基本信息。

这一步我们主要想看一下程序时32位还是64位的,通过上图可以看到程序属于32位程序。然后我们通过 IDA 对程序进行分析,IDA 是一个静态反编译软件,用来静态的分析软件,我们在32位的IDA中打开re1.exe(如果程序时64位的需要用64位的IDA打开),他会弹出弹窗,这里不用管,一路点“是(或者ok)”就行了,然后界面如下。

一进来,最大的那片区域为反汇编窗口,左边为函数窗口,在反汇编窗口按空格键,会在图形视图和列表视图之间切换。然后分析程序一般先从字符串入手,打开字符串窗口,View --> open subviews --> Strings,或者快捷键shift+F12。

程序中往往包含很多字符串资源,这些资源存在于 PE 文件的 rdata 段,可以看到运行程序时出现过的 "DUTCTF" 字符串,双击它找到他的位置

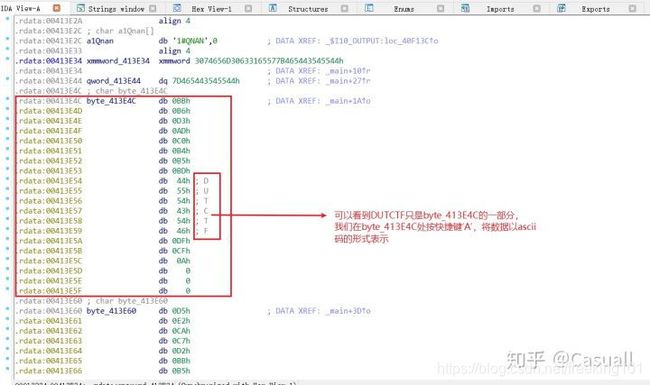

可以看到 aDutctf 字符串周围还有很多字符串,我们把它们都变成可显示字符,结果如下,由于本题比较简单,所以直接出现了flag。

当然,本文是为了介绍 IDA 的使用,所以我们继续往下分析,找到关键的字符串后,在字符串的位置,按快捷键x,查看程序在哪里引用了它,比如这道题没有给出 flag,我们需要在提示信息处(也就是 aDutctf 的位置)按快捷键x,可以看到只有一处引用了它。
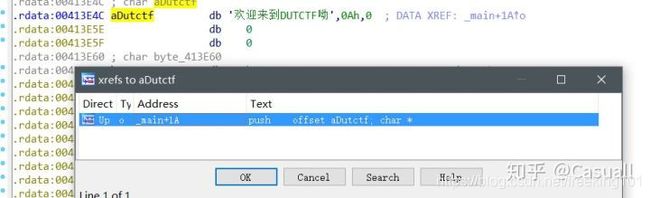
我们跟进去看一下,找到了引用它的位置,这一步是 为了找到程序的主要逻辑 在哪,因为有时候IDA 可能分析不出函数名来,你就没办法通过左边的函数窗口定位程序的主要逻辑位置,也有可能程序的主要逻辑不在 main 函数里,在一个其他的函数里。
所以说,先运行程序,找到程序运行时出现的提示字符,然后定位提示字符出现的位置,用这样的方法来找程序的主要逻辑比较靠谱一些。

找到了关键位置后,发现是一堆汇编代码,看不懂怎么办?IDA 的强大之处还在于他可以将分析的程序以伪代码的形式给出,快捷键为F5(不是所有程序都能以伪代码的形式显示,也不是所有函数都能以伪代码的形式显示,如果没办法显示伪代码,那只能刚汇编了),下一步就是分析程序的逻辑了,至于怎么分析,这里就不多赘述了。

在关闭 IDA 的时候他会提示你是否保存 database,你可以选择保存,下次用 IDA 打开这个程序的时候可以加载这个数据库,里面保存了你上次的操作。
下面给出了一些常用的快捷键

参考:IDA Pro 权威指南 (第2版)
示例:IDA Pro 动态调试 so
********************* 前提条件 和 运行环境 一定要写清楚,不然会有很多坑,坑死人。 *********************
雷电、蓝叠的 cpu 是 x86 的,ida不能正常调试,需要用 Android 编译器自带的创建模拟器。
ida 模拟器动态调试,当执行到断点时会出现错误。但是可以用 Android studio 创建模拟器会出现下面的选项,选择 Other Images 选项,这时显示出 armeabi-v7a,选择这个创建模拟器,就是 arm 的模拟器不是 x86,能正常调试。

IDA 动态调试 Android
IDA 静态分析 与 动态分析:https://zhuanlan.zhihu.com/p/38983223
IDA 动态调试:https://zhuanlan.zhihu.com/p/145383282
Android逆向之旅---动态方式破解apk进阶篇(IDA调试so源码):https://zhuanlan.zhihu.com/p/23321571
IDA动态调试android的so文件(二):https://blog.csdn.net/binbin594738977/article/details/106070388
在调试 so 库的时候 先执行.init_array 其次 JNI_OnLoad,在调试 so 库的很多时候要双开 IDA 动静太结合的双调,因为 IDA 在编译的过程不能全部展示所要调用的函数,指针还有内存地址
动态调试 总览
:https://blog.csdn.net/AHuqihua/article/details/127269887
1. 将IDA pro下的android_server移动到android手机中, 并运行,成功后不要关闭该cmd
2, 新建立cmd, 端口转发:
# 前面是电脑的端口,后面是手机的端口
adb forward tcp:23946 tcp:23946
# 调试模式打开APP, 不然IDA发现不了该APP
adb shell am start -D -n com.yaotong.crackme/com.yaotong.crackme.MainActivity
3. 进入IDA,选择对应的程序,进入调试窗口。并记好该app对应的PID.
4. adb forward tcp:8700 jdwp:(APP进程号)
5. jdb -connect com.sun.jdi.SocketAttach:hostname=127.0.0.1,port=8700
6. 在IDA中进行调试。
手机端 执行 android_server ,等待 IDA Pro 的连接
Android未root环境下使用IDA调试:https://blog.csdn.net/lsg305/article/details/103638118
- 1. 复制 android_server 文件到手机的 /data/local/tmp 目录下。
命令:adb push IDA_Pro\dbgsrv\android_server /data/local/tmp- 2. 添加权限,并执行 android_server
adb shell su
cd /data/local/tmp
chmod 777 android_server
./android_server // 启动 android_server- 3. 端口转发。命令:adb forward tcp:23946 tcp:23946
- 4. 启动被调试的 APP:命令:adb shell am start -D -n com.cmxxzwy.mz/com.e4a.runtime.android.mainActivity。加了
-D参数,此时 Android 设备上会给出提示:“Waiting For Debugger”,表示正在等待调试器的链接。【注意:也可以让 APP 正常启动,然后 IDA 依然可以 attach 到已经运行的进程上,但是这样无法调试到 APP 启动阶段的逻辑。】

用 am 启动被调试应用 ( am是activity manager的缩写 )
am启动程序命令:am start -D -n com.example.testarm/.MainActivity
am start -D -n 调试模式打开应用
com.example.testarm 要调试启动的包名
.MainActivity 要启动的 MainActivity
启动后等待调试器的链接。
IDA Pro 设置 调试,连接到手机上的 android_server 并进行调试
- 1. IDA菜单栏 ---> debugger ---> attach ---> Remote ARM Linux/android debugger
- 2. debug options 一定要选
- 3. 设置 host,点击 ok 后,在弹出的进程选择框 选择要调试的 com.cmxxzwy.mz 进程。【启动 IDA Pro。在主菜单选择:Debugger -> Attach -> Remote ArmLinux/Android debugger。在 setup 对话框中,hostname 输入
127.0.0.1,Port 输入23946,点击 OK 按钮。此时会出现一个列表,罗列了 Android 设备上当前运行的所有进程,找到需要调试的进程点击 OK 按钮。接下来进入了调试器界面:】
- 设置断点 ( 一定要先下断点再运行,如果有反调试时一运行就崩溃,一切的重新来过 ),然后点击 IDA 的 开始运行 按钮。【 注意:这里 ida 的运行只是说明 ida 已经开始监测断点,但是此时 app 还没有恢复运行,需要使用 jdb 将 app 恢复执行】



打开 DDMS,下一步要用

查看要调试的进程,其中8700代表选中的进程的调试端口,可以是8700也可以是 / 左边的。比如图中的 8677
ddms 已经废弃 ,使用 monitor 替代。
tools/monitor.bat ( java8 才能运行,高版本不行 ),修改 monitor.ini 指定 jdk 版本

用 jdb 将 app 恢复执行。
命令:jdb -connect com.sun.jdi.SocketAttach:hostname=127.0.0.1,port=8700
这里的 8700 也可以不写 8700,可以选择要调试的进程端口也是可以的,否则你选择了哪个进程哪个就是8700那么调试的就是哪个

这一步的作用是使程序恢复运行。(注意这时候如果ida里还没有点击运行,程序是不会真的继续运行的)。这时候就可以正常地在 IDA 里下断调试了。F7进入函数,F8单步调试,F9跳到下一个断点,F2下断点,G调到函数地址
动态、静态 结合调试
动态调试的时候面对的都是 Arm 汇编,理解能力要跟的上调试速度,这有点难。怎么办?
那就是动静态结合调试。我们来看动态调试窗口

1 为这句代码的动态内存地址。
2 为该so文件的动态内存基地址。
3 为内存段的大小。
静态调试窗口显示的都是代码的相对偏移地址,所以我们用 1动态内存地址 - 2内存基地址 = 静态相对偏移地址
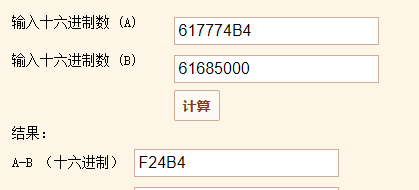
所以 F24B4 就是静态代码的偏移地址。所以我们打开静态调试窗口就可以看到

这样,动态和静态的代码就对上了,用静态的代码来记录动态调试的位置信息,就不怕调试过程中断带来的麻烦。而且使用 F5 来辅助理解代码也是棒棒哒
动态调试过程往往反反复复,命令有时候懒得重新输入。快捷键 ctrl +c 结束当前命令程序,按上下键输入之前输过的命令。
跳转到指定地址全是 DCB 数据

这个时候可以按 C 键识别为代码,或者按 P 键识别为函数
动态调试 查看 内存
动态调试经常就是为了查看内存。步骤如下
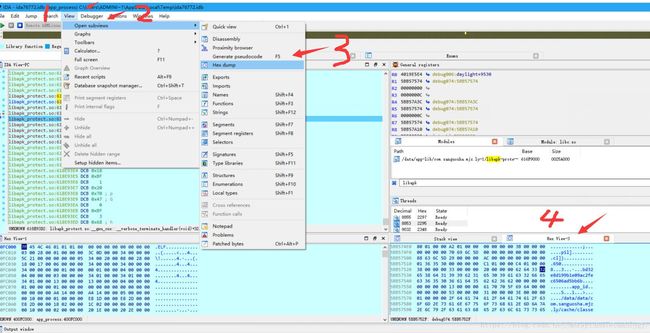
一些 反调试、反反调试
反动态分析
首先需要说明的是,一个可执行二进制文件,比如一个 Android native so 库,它本身能做的事情是有限的,它只能访问 system call,调用系统库函数,访问寄存器、虚拟内存、IO 设备等等,仅此而已。因此,我们如果在它的第一条执行指令处下断点,它是无法阻止我们的。但是它还是能够使用很多技巧来干扰调试器的运行,增加我们的工作量。
注意:Android native so 中最早被执行的代码位于 ELF 的 .init_array section 中,比 JNI_OnLoad 函数中的代码执行更早。
对于下面描述的各种反动态分析的技巧,我们首先需要通过静态分析,来确认被分析二进制文件的检测点,之后,我们也许可以修改运行环境;也许可以编写特定的 IDA 扩展,在运行时欺骗被调试二进制的逻辑;也许可以直接修改二进制文件,删除或修改它的检测点或检测条件。
检测虚拟化
分析恶意软件时,我们往往在沙盒或虚拟化环境中调试它。虚拟化环境往往会留下一些痕迹,比如使用了某个特定的虚拟硬件标识符;启用了某些虚拟机特定的机制,比如共享剪贴板;运行了某些辅助工具,比如 VMware Tools。
检测特定工具
比如检测当前环境是否安装了 Wireshark 网络抓包工具,恶意软件作者可能会认为正常用户不应该安装 Wireshark。
检测运行环境
比如发现 Android 环境下存在一个名叫 android_server 的进程在运行,或者 23946 TCP 端口处于监听状态,则终止进程。
检测调试器
Linux / Android 进程在同一时刻只能被 一个 进程调试,因此 so 库可以 fork 一个子进程,然后尝试 ptrace() attach 它的父进程,如果失败,则 so 库可能正在被调试器调试,此时立刻终止进程。
so 启动后也可以直接调用 ptrace(PTRACE_TRACEME, ...),这样后续调试器再调用 ptrace 来 attach 的时候都会失败。
Linux / Android 系统中,如果一个进程正在被调试,则 /proc/self/status 信息中的 TracerPid 项会显示调试器进程的 PID,如果没有被调试,则 TracerPid 为 0。so 库可以编写逻辑来定期检测这个值。
检测代码执行的时间间隔
进入调试器后,由于人为的断点和单步操作,代码段执行的间隔一般都会显著的拉长,so 库可以加入时间检测逻辑,如果发现大于某个阈值,则终止进程。
最后
通过这一次系统地去学 IDA,发现这个软件真的是非常厉害,IDA还有很多高级的开发技巧,甚至你还能自定义模块和加载器等,也能自己制作 ida 的插件,在这个过程中,发现看书真的很重要,自己看书和看网上别人总结的,完全不一样,搞二进制还是得踏踏实实打好基础。
《 二进制分析实战》
