GFS分布式文件系统
目录
一、GFS概述:
1、概念:
2、GFS的特点:
3、GFS的组件和术语:
4、工作流程:
5、GFS的卷有哪些类型:
6、gluster常用命令:
二、实验:
1、环境:
2、安装软件:
3、添加节点到存储信任池中
4、创建分布式卷:
5、部署 Gluster 客户端
6、测试 Gluster 文件系统
7、创建复制卷:
8、创建分布式复制卷:
9、访问控制:
10、总结:
一、GFS概述:
1、概念:
GFS分布式文件系统:glusterFS开源的分布式的文件系统
存储服务器、客户端、以及网络(NFS/samba)网关
传统式老的分布式系统元服务器,元服务器保存储存节点的目录树信息
一旦元服务器故障,所有的存储节点全部失效
现在的GFS取消了元服务器机制,数据横向扩展能力更强。可靠性更强。存储效率也更高
2、GFS的特点:
- 扩展性更强、性能也很出色
- 高可用,可以自动对文件进行复制。多次复制,确保数据总是可以访问。哪怕硬件故障也能正常访问
- 全局统一的命名空间。所有节点都在一个分支的管理之下。客户端访问分支节点即可
- 弹性卷,类似于LVM。不同硬盘上的不同分区组成一个逻辑上的硬盘。而GFS是不同服务器上的不同的硬盘分区组成一个卷,类似于逻辑卷。可以动态扩容
- 基于标准协议,GFS存储服务支持NFS、FTP、HTTP以及自身的GFS协议。应用程序可以直接使用数据,不需要任何修改
3、GFS的组件和术语:
1、BRICK(存储块),存储服务器提供的用于物理存储的专用分区,GFS当中的基本存储单元。也是对外提供的存储目录,是服务器和目录的绝对路径组成
server:dir
20.0.0.21:/opt/gfs
node1:/opt/gfs
2、volume逻辑卷,一个逻辑卷就是一组brick的集合。类似与lvm,我们管理GFS,就是管理这些卷
3、FUSE:GFS的内核模块,允许用户创建自己的文件系统
4、VFS:内核空间对用户提供的访问磁盘的接口。虚拟端口。
服务端在每个存储节点上都要运行。glusterd(后台管理进程)
4、工作流程:

5、GFS的卷有哪些类型:
分布式卷,也是GFS的默认卷类型
条带卷(没了)
复制卷(镜像化)
分布式复制卷(工作中主要用)
dis-volume 分布式卷
rep-volume 复制卷
dis-rep 分布式复制卷
分布式卷:文件数据通过HASH算法分布到设置的所有BRICK SERVER上。GFS的默认卷。属于RAID0,没有容错机制

在分布式卷的模式下,没有对文件进行分块,只是直接存储在某个SERVER的节点上。存取的效率也没有提高。直接使用本地文件系统进行存储
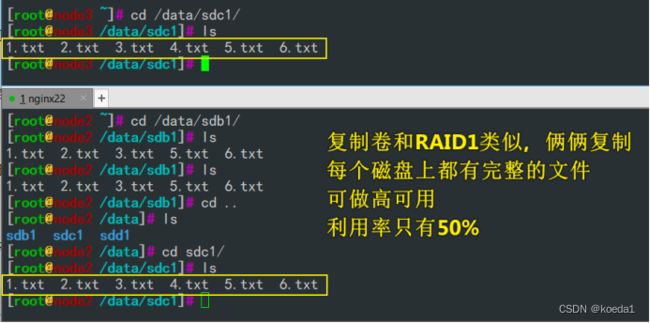
复制卷:类似于RAID1,文件会同步在多个BRICK SERVER上。读性能上升,写性能下降。
复制卷具有冗余,坏一个节点不影响数据,但是要保存副本,磁盘利用率只有50%

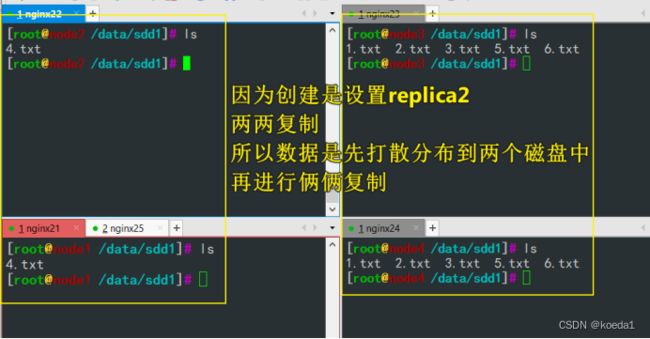
分布式复制卷:俩俩复制,文件会在组内同步。不同的组之间数据未必同步。

6、gluster常用命令:
1.查看GlusterFS卷
gluster volume list
2.查看所有卷的信息
gluster volume info
3.查看所有卷的状态
gluster volume status
4.停止一个卷
gluster volume stop dis-stripe
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe
6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.deny 20.0.0.21
#仅允许
gluster volume set dis-rep auth.allow 20.0.0.*
#设置20.0.0.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)
二、实验:
1、环境:
四台服务器:
node1:20.0.0.21
磁盘:
/dev/sdb1 /data/sbd1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
node2:20.0.0.22
磁盘:
/dev/sdb1 /data/sbd1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
node3:20.0.0.23
磁盘:
/dev/sdb1 /data/sbd1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
node4:20.0.0.24
磁盘:
/dev/sdb1 /data/sbd1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
客户端:20.0.0.25
先关闭防火墙和安全机制:
写一个自动磁盘分区的脚本:
四台机器全部部署
cd /opt/
vim fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
scan刷新端口
alias scan='echo "- - -" > /sys/class/scsi_host/host0/scan;echo "- - -" > /sys/class/scsi_host/host1/scan;echo "- - -" > /sys/class/scsi_host/host2/scan'
四台虚拟机都添加三块硬盘
sh fdisk.sh
mount -a刷新
df -h查看是否挂载

修改主机名,简化操作:
node1 2 3 4
四台都hosts做映射:

2、安装软件:
yum -y install centos-release-gluster
yum clean all && yum makecache
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
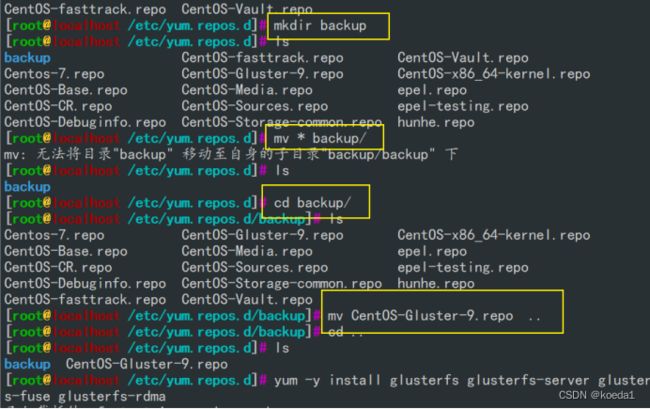
systemctl start glusterd.service
systemctl status glusterd.service

查看版本
glusterd -V

3、添加节点到存储信任池中
(在 node1 节点上操作)
vim /etc/hosts
20.0.0.21 node1
20.0.0.22 node2
20.0.0.23 node3
20.0.0.24 node4
#节点要做映射关系

只要在一台Node节点上添加其它节点即可
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
node1添加:

删除节点
gluster peer detach node1
#在每个Node节点上查看群集状态
gluster peer status

4、创建分布式卷:
四个节点中任选一个做
这里选择node1做
创建分布式卷:
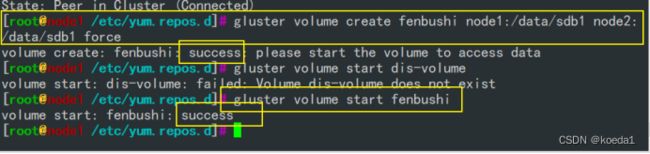
gluster volume create fenbushi node1:/data/sdb1 node2:/data/sdb1 force
gluster volume create:创建新卷,没有指定任何模式默认就是分布式卷
fbs:卷名,唯一不可重复
node1:/data/sdb1 node2:/data/sdb1 force
是两个服务器上不同的挂载点
force:强制创建
创建完之后还要开启:
gluster volume start fenbushi
查看卷的信息:
gluster volume info fenbushi
查看卷列表
gluster volume list


5、部署 Gluster 客户端
1.安装客户端软件
#将gfsrepo 软件上传到/opt目下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
yum clean all && yum makecache
yum -y install glusterfs glusterfs-fuse

vim /etc/hosts
做映射

2.创建挂载目录
mkdir -p /test/fenbushi
mount.glusterfs node1:fenbushi /test/fenbushi/

永久挂载:
![]()
6、测试 Gluster 文件系统
cd /test/fenbushi/
touch {1..6}.txt

node1和node2的data里面查看sdb1

7、创建复制卷:
复制卷用 node2:/data/sdc1 node3:/data/sdc1
cd /opt
gluster volume create fuzhi replica 2 node2:/data/sdc1 node3:/data/sdc1 force
replica 2:设置复制策略
2是两两复制。要小于等于存储节点,不能比存储节点多,否则创建失败
gluster volume info fuzhi

启动复制卷:
gluster volume start fz
回到客户端:
mkdir /test/fuzhi
挂载
mount.glusterfs node1:fuzhi /test/fuzhi/
四个节点通用,挂载哪个都行

客户机创建文件:

服务端验证:
8、创建分布式复制卷:
采用:node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1
gluster volume create fbfz replica 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
开启
gluster volume start fbfz

客户端测试:
创建目录且挂载:
mount.glusterfs node3:fbfz /test/fbfz/

客户端创建文件:
touch {1..6}.txt

node节点测试:
设置replica 4
gluster volume create fbfz replica 4 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force

分布式复制卷是最常用的分布式文件存储方式,根据replica策略,在存储文件时还是分布式的存储方式,分开存储,但是会进行复制。所以也拥有冗余的功能,但是磁盘利用率只有50%。
如何查看存储池上所有卷的状态:
gluster volume status
删除卷:
若在运行状态要先停再删
gluster volume stop fbs
gluster volume delete fbs
如何对卷进行访问控制
停止节点:node1
![]()
gluster peer detach node1
查看节点:
gluster peer status
9、访问控制:
拒绝26访问:
gluster volume set fbfz auth.reject 20.0.0.26
客户端访问GFS卷是通过挂载的方式实现的。

如何允许网段来访问
gluster volume set fbfz auth.allow 20.0.0.*
10、总结:
GFS分布式存储系统:
- 分布式卷
- 复制卷
- 分布式复制卷(重点)
工作性质:要和RAID作区分。RAID是磁盘冗余阵列,本机的磁盘冗余
GFS:是把不同服务器上的不同硬盘组合起来,形成一个卷(基于网络的虚拟磁盘),实现的是文件系统的冗余