leetcode刷题之哈希表的应用(1)
"study hard"
作者:Mylvzi
文章主要内容:leetcode刷题之哈希表的应用(1)



1.只出现一次的数字
136. Single Number - 力扣(LeetCode) https://leetcode.cn/problems/single-number/
https://leetcode.cn/problems/single-number/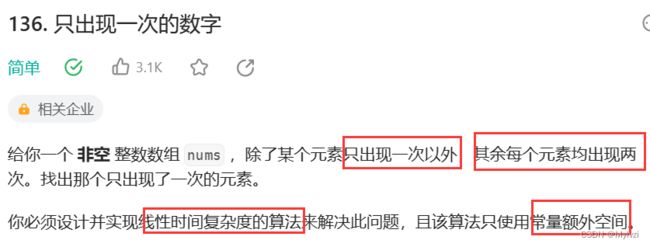
分析:
核心就是在数组中找出现一次的数字,其实有很多思路,比如设计计数数组,比如使用Set不存储相同数据的特性来存储数据, 下面是用Set解题
public int singleNumber(int[] nums) {
Set set = new HashSet<>();
for (int x: nums) {
if(set.contains(x)) {
set.remove(x);
continue;
}
set.add(x);
}
Object[] objects = set.toArray();
return (int)objects[0];
} 其实如果你对异或运算熟悉,很容易想到这是利用异或来解决单身狗问题
public int singleNumber(int[] nums) {
int single = 0;
for (int x: nums) {
single ^= x;
}
return single;
} 
补充哈希表的思路:
public int singleNumber(int[] nums) {
Map map = new HashMap<>();
for (int x:nums) {
map.put(x, map.getOrDefault(x,0)+1);
}
for (int x:nums) {
if(map.get(x) == 1) {
return x;
}
}
return -1;
} set的天然去重是指当你插入多个相同的值的时候,只会保留一个

在leetcode上一共有关于他的两个题目,都可以采用hashMap的方式解决
137. 只出现一次的数字 II - 力扣(LeetCode)
class Solution {
public int singleNumber(int[] nums) {
Map map = new HashMap<>();
for (int x:nums) {
map.put(x, map.getOrDefault(x,0)+1);
}
for (int x:nums) {
if(map.get(x) == 1) {
return x;
}
}
return -1;
}
} 260. 只出现一次的数字 III - 力扣(LeetCode)
class Solution {
public int[] singleNumber(int[] nums) {
Map map = new HashMap<>();
for (int x:nums) {
map.put(x, map.getOrDefault(x,0)+1);
}
List list = new ArrayList<>();
for (int x:nums) {
if(map.get(x) == 1) {
list.add(x);
}
}
int[] ret = new int[2];
for (int i = 0; i < ret.length; i++) {
ret[i] = list.get(i);
}
return ret;
}
} 2.随机链表的复制
138. 随机链表的复制 - 力扣(LeetCode)

此题的难点在于不能直接拷贝原链表,直接拷贝会发生错乱的,只能拷贝val(直接拷贝会让你新的结点指向旧的结点),因为随机指针的存在,当我们拷贝节点时,「当前节点的随机指针指向的节点」可能还没创建,但是如果我们能建立旧结点和新节点的映射,就能很好的解决问题,所以本题使用hashMap

代码实现:
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
// return head;
HashMap hashMap = new HashMap();
Node cur = head;
while (cur != null) {
Node newNode = new Node(cur.val);
hashMap.put(cur,newNode);
cur = cur.next;
}
cur = head;
while (cur != null) {
hashMap.get(cur).next = hashMap.get(cur.next);
hashMap.get(cur).random = hashMap.get(cur.random);
cur = cur.next;
}
return hashMap.get(head);
}
} 3.宝石与石头
771. 宝石与石头 - 力扣(LeetCode)

此题最容易想到的就是暴力搜索,遍历字符串stone,遇到的每个字符都再去和jewels一一比较,但这样时间复杂度过高,有没有其他方法呢?
使用set,先将jewels中的所有字符存储,再去遍历stones字符串,去判断set中是否包含对应的字符
代码实现
class Solution {
public int numJewelsInStones(String jewels, String stones) {
// 思路1:暴力搜索
int cnt = 0;
for (int i = 0; i < stones.length(); i++) {
char ch = stones.charAt(i);
for (int j = 0; j < jewels.length(); j++) {
if (jewels.charAt(j) == ch) {
cnt++;
}
}
}
return cnt;
// 思路2:使用set
Set set = new HashSet<>();
for (int i = 0; i < jewels.length(); i++) {
set.add(jewels.charAt(i));
}
int cnt = 0;
for (int i = 0; i < stones.length(); i++) {
if(set.contains(stones.charAt(i))) {
cnt++;
}
}
return cnt;
}
} 实际上这两种方式的时间复杂度相同(( ̄▽ ̄)")
当然还有大佬提供了一种"位运算的思路"
class Solution {
public:
int numJewelsInStones(string jewels, string stones) {
long long mask = 0;
for (char c: jewels)
mask |= 1LL << (c & 63);
int ans = 0;
for (char c: stones)
ans += mask >> (c & 63) & 1;
return ans;
}
};参考大佬链接:
分享|从集合论到位运算,常见位运算技巧分类总结! - 力扣(LeetCode)
4.前k个高频词
https://leetcode.cn/problems/top-k-frequent-words/submissions/

代码实现:
class Solution {
public List topKFrequent(String[] words, int k) {
// 1.使用Map存储的单词--次数的映射关系 不涉及下标的使用foreach循环更快
Map map = new TreeMap<>();
for (String word:words) {
if (map.get(word) == null) {// 未被插入
map.put(word,1);
}else {
int val = map.get(word);
map.put(word,val+1);
}
}
// 2.建立小根堆 top-k问题(频率从高到低) 这里使用了匿名内部类 是通过Comparator这个接口实现的 需要重写compare方法
PriorityQueue> minheap = new PriorityQueue<>(new Comparator>() {
@Override
public int compare(Map.Entry o1, Map.Entry o2) {
// 频率相同 要根据字母顺序建立大根堆 输出的时候是要字母顺序小的在前 插入的时候虽然也是字母顺序小的进入 但是再一反转 字母顺序大的就跑前面了
if(o2.getValue().compareTo(o1.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue() - o2.getValue();
}
});
// 3.遍历map 在queue中存储数据
for (Map.Entry entry: map.entrySet()) {
// 堆排 现存前k个
if(minheap.size() < k) {
// 这里也有可能出现频率相同的数据 插入的时候要去判断字母顺序
minheap.add(entry);
}else {
Map.Entry top = minheap.peek();
// 频率i相同 还要进一步判断字母顺序 字母顺序小的进来
if(top.getValue().compareTo(entry.getValue()) == 0) {
if (top.getKey().compareTo(entry.getKey()) > 0) {
minheap.poll();
minheap.offer(entry);
}
}else {// 频率不同 频率大的进来
if(top.getValue().compareTo(entry.getValue()) < 0) {
minheap.poll();
minheap.offer(entry);
}
}
}
}
List ret = new ArrayList<>();
for (int i = 0; i < k; i++) {
ret.add(minheap.poll().getKey());
}
Collections.reverse(ret);
return ret;
}
} 另一种更简单的写法:将所有的比较逻辑使用匿名内部类和三目运算符解决
public List topKFrequent(String[] words, int k) {
Map cnt = new HashMap();
for (String word : words) {
cnt.put(word, cnt.getOrDefault(word, 0) + 1);
}
List rec = new ArrayList();
for (Map.Entry entry : cnt.entrySet()) {
rec.add(entry.getKey());
}
// 排序的逻辑也很简单 谨记频率的大小是优先 频率相同再去考虑字母顺序
// 先看频率是否相同 不同 直接返回频率的差值 i相同比较字典序
Collections.sort(rec, new Comparator() {
public int compare(String word1, String word2) {
return cnt.get(word1) == cnt.get(word2) ? word1.compareTo(word2) : cnt.get(word2) - cnt.get(word1);
}
});
return rec.subList(0, k);
}