【论文阅读】An Experimental Survey of Missing Data Imputation Algorithms
论文地址:An Experimental Survey of Missing Data Imputation Algorithms | IEEE Journals & Magazine | IEEE Xplore

处理缺失数据最简单的方法就是是丢弃缺失值的样本,但这会使得数据更加不完整并且导致偏差或影响结果的代表性。因此,研究者提出了一系列填补方法,包括早期的简单统计填补方法、传统的机器学习填补方法和现代深度学习填补算法。
早期的简单统计填补方法是使用训练数据中的统计值(例如平均值、中值、众数)或最相似的统计量来替换缺失值,例如均值填补(Mean imputation)、热卡填补(Hot deck imputation,HDI)、冷卡填补(Cold deck imputation,CDI)和k近邻填补(KNNI) 。第二类填补方法是在机器学习中建立一个预测模型来预测缺失值,例如XGBoost填补(XGBI)、MissForest填补(MissFI)、链式方程的多重填补(MICE)、单模型填补(IIM)、软填补(SI)、矩阵分解填补(MFI)、主成分分析填补(PCAI)、多层感知器填补(MLPI)、循环Sinkhorn填补(RRSI)等。相比之下,现代深度学习填补算法的灵感来自于深度生成模型的强大能力。它们要么丰富显式生成模型的先验或后验,例如深度自动编码器 (AE);要么利用对数似然概率产生隐式生成模型,例如生成对抗网络 (GAN)。总而言之,如图所示,目前填补算法可以分为三组,即统计填补方法、机器学习填补方法和深度学习填补方法。

1 统计填补方法
在早期的研究中,大多数研究人员都专注于基本的统计填补方法,包括基于统计的方法和基于相似度的方法。所有这些方法都属于单一填补,即用单个值来估算缺失值。
一)基于统计的方法
基于统计的填补方法通常利用统计值(例如平均值、中值、众数)来估算缺失值。均值填补(Mean imputation)方法[28]简单地用每个特征的所有观测数据的平均值、中值或众数来替换缺失数据。在包含缺失值的数据特征的情况下,用在该特征中观察到的值的平均值来填充缺失值。而在分类特征的情况下,则使用出现频率最高的值而不是平均值来代替缺失的值。
二)基于相似性的填补方法
基于相似性的填补方法使用一个或多个相似样本的值的平均值来估计缺失值,如图3.2所示。具体来说,基于相似性的填补方法最初计算每个样本对之间的欧几里得距离。在距离计算过程中,缺失值被视为零。然后,对于样本xi,根据xi的每个缺失值(例如,特征fj中缺少xij),它从不完整数据矩阵X中选择xi的K个最近样本,用{x1,…,xK}表示,这样它们都可以观测到在特征fj上的值。接着,它聚合所选样本在特征fj上的观测值以估算缺失值xij。重复该过程,直到成功估算所有缺失值。具体的基于相似性的填补填补方法如下:

图3.2 基于相似度的插补说明
(1)KNNI。K近邻填补(K nearest neighbor imputation,KNNI)是一种典型的基于相似性的方法,缺失值可以通过最近邻的样本的值聚合而成。KNNI可以采用所有最近邻得值的加权平均值,其中与邻居的距离作为其权重,因此距离越近,聚合的权重越大。
(2)HDI。热卡填补(Hot deck imputation,HDI)是KNNI的一种变体,它使用来自最相似样本的相应值来估算缺失值。如果所有样本都包含缺失值,则选择缺失值数量最少的最近样本来估算缺失值。
(3)CDI。与KNNI和HDI不同,冷卡填补(Cold deck imputation,CDI)除了需要原始数据集外,还需要额外的补充数据集来进行填补。具体来说,CDI首先计算原始数据集中的样本与补充数据集中的样本之间的欧氏距离。然后,对于每个不完整的样本,CDI 将缺失值替换为补充数据集中最相似样本对应的值。重复此过程,直到所有缺失值都被估算。
以上所有的统计填补方法总结在表2中。在预测类型中,“一对一”表示为每个不完整特征构建至少一个预测模型,在填补类型中,“单一填补”(single imputation)是指采用一定方式,对每个缺失值只构造一个合理的替代值,并将其插补到原缺失数据的位置上,替代后构造出一个完整的数据集。
表2 统计填补方法的比较
| 类别 |
方法 |
模型 |
预测类型 |
填补类型 |
核心 |
| 统计 |
Mean |
统计 |
一对一 |
单一填补 |
对每个特征使用全局均值 |
| 统计 |
KNNI |
相似性 |
一对一 |
单一填补 |
在每个特征上使用近邻样本的均值 |
| 统计 |
HDI |
相似性 |
一对一 |
单一填补 |
使用最相似样本的对应值 |
| 统计 |
CDI |
相似性 |
一对一 |
单一填补 |
使用补充数据集中最相似样本的值 |
2 机器学习填补方法
与早期的统计填补方法相比,传统的机器学习填补方法解决方案是训练一个用于缺失值填补的预测模型。根据所使用的预测模型,我们可以进一步将现有的机器学习填补方法分为四个子组,即基于树的填补方法、基于回归的填补方法、基于压缩的填补方法和基于浅层神经网络(SNN)的填补方法。基于树的填补方法为每个包含缺失值的不完整特征构建一个决策树模型,例如XGBoost填补(XGBI)和MissForest填补(MissFI);基于回归的填补方法使用具有多重填补的线性回归模型来估计缺失值,例如链式方程的多重填补(MICE)和单模型填补(IIM);基于压缩的填补方法为整个不完整数据集构造一个预测模型(即数据压缩模型),例如软填补(SI)、矩阵分解填补(MFI)和主成分分析填补(PCAI);基于SNN的填补方法利用一个浅层神经网络在一个不完整的特征中估算缺失值,例如多层感知器填补(MLPI)和循环Sinkhorn填补(RRSI)。
一)基于树的填补方法
在基于树的填补方法中,它为涉及缺失值的每个特征构建了一颗决策树模型,例如随机森林和XGBoost。与统计填补方法类似,基于树的方法也是单一值填补,即用一个值对每个缺失值进行填补。它以掩码矩阵M 的不完整数据矩阵 X 作为输入,并返回最终估算矩阵X。最开始,X中的缺失值是通过均值填补估算的,估算矩阵存储在矩阵X0中。然后,它开始以迭代方式估算缺失值。参数 c 表示当前迭代时间,cmax 是迭代次数的最大数量。Xc用于记录矩阵 X 的当前估算矩阵。在每次迭代中,算法遍历每个具有缺失值的特征fj。Xcoj收集用于从X中观察到的特征fj的样本xi (即掩码矩阵M中对应位置的mij为1)形成一个新的训练数据集,使用训练数据集Xcoj在特征fj上训练预测模型∅j。然后使用预测模型∅j 来估算 X 中特征fj上的缺失值。此后,Xc通过将上述估算值合并到其中来继续进行更新,不断的进行重复,直到终止条件。具体的关于树的填补方法如下:
(1)XGBI。XGBoost填补方法(XGBI)遵循上述处理过程并且利用XGBoost作为预测模型。如果新估算Xc和先前估算 Xc−1 之间的平均差异小于给定阈值,则满足 XGBI给定的终止条件。
(2)MissFI。MissForest填补(MissFI)也是基于树的填补方法,也遵循上述的处理过程,并且MissFI利用随机森林作为预测模型。当它的新估算的估算矩阵Xc和先前估算的估算矩阵Xc−1之间的平均差值第一次出现增加时即可终止。
二)基于回归的填补方法
与基于树的填补方法不同,基于回归的填补方法为每个包含缺失值的特征构建多个预测模型,即线性回归模型。具体的回归填补方法如下:
(1)MICE。链式方程法(MICE)的多元填补是一种典型的多重填补方法,它以多次线性回归的结果的平均值来估计缺失值。在基于树的填补方法中的预测模型∅对应于MICE中的线性回归模型,MICE并不是通过多次迭代逐步输入数据来进行填补,而是多次独立地进行填补,最后聚合多个填补结果得到最终的估算矩阵X。
(2)IIM。通过单个模型 (IIM) 进行填补首先需要训练一组回归模型,然后使用xi的最近的样本(在特征fj中能观察到的其他的样本值)的回归模型来估算样本xi的每个缺失分量xij。它也是一种的基于回归的多重填补方法,具体来说,其流程如下:对于每个特征fj,它基于xi的最近邻的训练集(即在 X 中的特征fj上能观察到其他的样本值),根据特征fj上观察到的值为每个样本xi训练一组回归模型。对于样本xi,对应的回归模型的数量最多为其最近邻的最大数量。以图3.3所示的样本xi为例,对于其缺失值xij,IIM 首先找到在特征fj上xi的最近邻样本(即x1、x2 和 x3)的最佳回归模型(即∅1j、∅2j和 ∅3j。然后,用这些不同的最优回归模型预测结果xij1、xij2和xij3。最后,IIM 聚合这些回归结果以获得估算值xij。

图3.3 IIM填补方法示意图
三)基于压缩的填补方法
与其他三种机器学习填补方法不同,基于压缩的填补方法仅为整个不完整数据集构建一个数据压缩模型。基于压缩的填补的基本框架如图3.4所示。它由两个步骤组成,即压缩(步骤1)和重建(步骤2)。具体来说,在压缩步骤中,基于压缩的填补方法利用数据压缩技术(例如奇异值分解)来学习权重矩阵Wd×dt,然后将数据矩阵 X 压缩为潜在表示Tn×dt,即
![]()
其中dt是潜在维度,且dt![]()
其中⊙表示同或运算。通过重构误差损失ℒc,基于压缩的填补方法迭代更新权重矩阵Wd×dt和重构矩阵X。重复该过程,直到迭代时间达到最大迭代次数。最后,估算矩阵X可由下式计算而出:X=M⊙X+(1−M)⊙X![]()
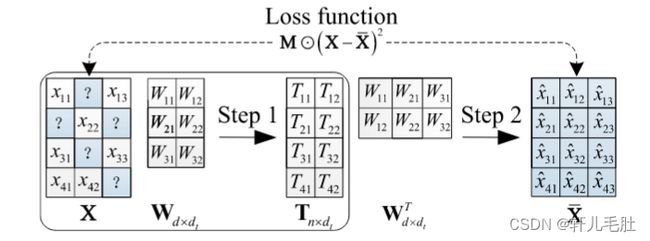
图3.4 基于压缩的填补方法示意图
基于压缩的填补方法具体如下:
(1)SI。软填补方法 (SI) 是一种基本的基于数据压缩的填补方法,它通过利用阈值进行奇异值分解(SVD)对给定阈值的数据矩阵 X 进行迭代更新,这样SI就能得到一组具有不同阈值的估算矩阵X,最终就可以使用最优估算矩阵X来估算X。![]()
(2)MFI。矩阵分解填补 (MFI) 采用潜在因素模型将不完整的数据矩阵 Xn×d压缩为两个小矩阵,即Un×p和Vd×pT,其中p远小于 n 和 d。于是这个算法的主要挑战就是推导出Un×p和Vd×pT。具体来说,MFI最初将X中缺失的分量替换为零,然后通过最小化来自X 中的观测值与来自Un×p和Vd×pT的相应预测值之间的平均差异来迭代优化Un×p∗Vd×pT,直到平均差异小于给定的阈值。同时,迭代时间受cmax的限制。最后,估算矩阵X可由下式计算而出:X=M⊙X+1−M⊙Un×p∗Vd×pT
(3)PCAI。主成分分析填补(PCAI) 使用前几个主成分来迭代填补缺失值并进行单一估算。具体来说,在每次迭代中,PCAI首先通过SVD[42]来计算特征值的特征向量对,然后根据特征值估算方差,利用所需方差的特征向量(即主成分)重建数据矩阵。接下来,PCAI计算新重构矩阵X在观测值上的重构误差,更新缺失值。一旦重建误差低于指定的容差,迭代就会停止。最后,根据 X=M⊙X+1−M⊙X,原始数据矩阵 X 由最后一个重构矩阵 X 估算。
四)基于SNN的填补方法
与基于树的填补方法模型类似,这种填补模型利用浅层神经网络 (SNN)为每个不完整特征构建一个预测模型。具体填补方法如下:
(1)MLPI。多层感知器填补方法(MLPI) 为每个不完整特征构建一个多层感知器 (MLP) 模型来估算缺失值,如图 3.5所示。具体来说,对于每个不完整的特征fj,X 中的完整样本收集在Xcj中。然后,MLPI 用Xcj迭代训练 MLP 模型∅j。最后,MLPI 使用经过训练的模型∅j 来估计 X 中不完整样本xi的特征 fj上的缺失值(如xij)。特别的,根据要估算的数值和分类特征的性质,在训练过程中需要最小化不同的误差函数,如平方误差和交叉熵误差。

图3.5 MLPI填补方法示意图
(2)RSSI。与MLPI类似,循环Sinkhorn填补(RRSI)使用浅层MLP作为每个不完整特征的预测模型。具体来说,对于每个不完整的特征fj,RRSI 首先用观察到的分量的平均值加上少量噪声来初始化其他不完整特征中的缺失值。然后,它从完整的样本中依次提取批次,并使用批次之间的Sinkhorn散度作为损失函数迭代训练MLP模型∅j。最后,RRSI 还利用经过训练的 MLP 模型∅j来估算 fj中相应的缺失分量。![]()
以上所有的机器学习方法总结在表3中,其中在预测类型中,“一对一”表示为每个不完整特征构建至少一个预测模型,“一对多”表示为整个不完整数据集构建一个预测模型。在填补类型中,“单一填补”是指采用一定方式,对每个缺失值只构造一个合理的替代值,并将其插补到原缺失数据的位置上,替代后构造出一个完整的数据集。“多重填补”是指创建数据集的多个副本,并对每个副本使用不同的估计方法来估算缺失值。
表3 机器学习填补算法的比较
| 类别 |
方法 |
模型 |
预测类型 |
填补类型 |
核心 |
| 机器学习 |
XGBI |
决策树 |
一对一 |
单一填补 |
用Boosting进行集合学习 |
| 机器学习 |
MissFI |
决策树 |
一对一 |
单一填补 |
用随机森林模型进行集合学习 |
| 机器学习 |
MICE |
回归 |
一对一 |
多重填补 |
多元线性回归 |
| 机器学习 |
IIM |
回归 |
一对一 |
多重填补 |
将线性回归与 KNNI 结合起来 |
| 机器学习 |
SI |
压缩 |
一对多 |
单一填补 |
使用多个阈值进行奇异值分解 |
| 机器学习 |
MFI |
压缩 |
一对多 |
单一填补 |
典型矩阵因式分解与潜在模型 |
| 机器学习 |
PCAI |
压缩 |
一对多 |
单一填补 |
带有缺失值估算的广义 PCA |
| 机器学习 |
MLPI |
SNN |
一对一 |
单一填补 |
在每个特征上学习带有回归模型的MLP |
| 机器学习 |
RRSI |
SNN |
一对一 |
单一填补 |
学习对每个特征进行最佳传输的 MLP |
3 深度学习填补方法
在本节中,我们将介绍现代深度学习填补算法,其中包括基于自动编码器 (AE) 的算法和基于生成对抗网络 (GAN) 的算法。
一)基于AE的填补方法
基于自动编码器(AE)的填补的基本框架如图3.6所示。它以不完整的数据矩阵X和相应的掩码矩阵M作为输入。AE的结构由两个模块组成,即编码器和解码器。编码器模块将输入数据压缩为潜在表示,而解码器模块将潜在表示重构为与输入数据矩阵 X 相似的输出X。![]()

图3.6 基于 AE 的填补架构
基于 AE 的填补算法中的编码器和解码器都是通过最小化损失函数 ℒAE来进行训练,即 X 中的观测值与 X中的相应生成值之间的重建误差(用ℒrec表示),其中ℒAE=ℒrec=M⊙X−X2,X是解码器的输出。最后,估算矩阵X=M⊙X+(1−M)⊙X。具体的基于AE的填补方法如下:![]()
(1)MIDAE。去噪自编码器多重填补方法(MIDAE)是一种基于深度去噪自编码器(DAE)的多重填补方法。DAE 是基本 AE 的扩展,为了迫使隐藏层发现更好的特征并防止它只简单地进行学习,DAE 训练自动编码器从不完整数据集开始重建输入。MIDAE 多次运行 DAE 模型(次数用 c 表示),每次运行都有一组不同的随机初始权重,以完成多重填补。由于DAE模型在初始化时需要完整的数据,因此MIDAE在训练之前用均值填补来估算缺失值。在训练 DAE 模型时,MIDAE 首先使用随机均匀分布的权重来初始化 DAE。然后,训练阶段从随机损坏过程开始,该过程将部分数据随机设置为零。它的目标函数也是最小化 X 中的原始观测值与 DAE 生成的相应值之间的重构误差。最终估算矩阵X是通过对DAE模型导出的c个估算矩阵求平均值得到的。
(2)VAEI。首先,变分自动编码器 (VAE)与基本 AE 类似,两者都由编码器和解码器组成。编码器将输入数据映射到潜在分布中(用Rl表示),而解码器将潜在分布映射回数据空间。与 AE 不同,VAE 通过在潜在分布上施加先验来规范编码器,用p(Rl)表示,其中Rl~(0,1)。变分自动编码器填补方法 (VAEI)使用 VAE 模型来执行单值填补。它由两个阶段组成,模型训练阶段(使用初始估算数据进行训练 VAE)和迭代填补阶段(使用经过训练的 VAE 迭代地估算缺失的部分)。在训练阶段,VAEI 首先将 X 中的缺失值替换为零。然后,它在给定迭代时间内用估算的 X 迭代训练 VAE 模型。VAE的目标函数是最小化观测向量上的重构误差ℒrec和正则化编码器的特殊先验正则化项ℒprior的总和,即
ℒVAE=ℒrec+ℒprior![]()
其中ℒprior=DKL(q(Rl|X )||0,1),其中DKL是 Kullback-Leibler 散度,q(Rl|X )是编码器的输出。在迭代填补阶段,VAEI 将 X 中的缺失值替换为零。然后,它使用经过训练的 VAE 模型预测的值迭代地估算 X 中的缺失值。在每次迭代中,最后一个估算矩阵X首先被送入训练好的 VAE 模型中,该模型会输出一个新的重构矩阵。然后,VAEI根据观察到的分量计算最后一个估算矩阵和新重构矩阵之间的重构误差,从而更新缺失值。一旦重建误差低于指定阈值,迭代就会停止,或者达到最大迭代次数时间而停止。
(3)HI-VAE。异构不完全 VAE 模型 (Heterogeneous-incomplete VAE model,HI-VAE)是一个基于 VAE 的单值填补的通用模型。它引入了一个输入过滤编码器来处理缺失数据,首先用零替换 X 中的缺失值,然后通过利用不同数据类型之间的不同似然函数来处理异构数据,从而构建解码器模型。此外,为了捕获所有特征之间的统计依赖关系,HI-VAE 利用一个简单的深度神经网络来输入潜在特征从而生成中间特征。在训练模型时,HI-VAE 使用证据下界(ELBO)来优化编码器和解码器的参数,这些参数仅在观察到的值上计算。最后,缺失值由经过训练的 HI-VAE 模型估算。
(4)MIWAE。缺失数据重要性加权自动编码器模型 (MIWAE)是重要性加权自动编码器 (IWAE)的广义版本。IWAE 是一个生成模型,具有与 VAE 相同的架构,它引入了一种重要性加权策略来优化 VAE 的目标函数。在 IWAE 中,编码器模型使用多个样本来近似后验,这对复杂后验进行建模来说会更加灵活。与 IWAE 不同,MIWAE 的目标函数只关注具有单值填补的观察部分。最后,原始矩阵 X 的缺失值由经过训练的 MIWAE 预测。
二)基于GAN的填补方法
生成对抗网络 (GAN)为两方构建了一个对抗训练架构,即用生成器(用 G 表示)和判别器(用 D 表示)来解决极小极大优化问题。生成器尽可能地生成接近真实数据分布的数据,而判别器尽可能正确地区分生成的数据和真实数据之间的差异。基于 GAN 的填补方法的一般架构如图3.7所示。对于生成器 G,其输入包括原始数据矩阵 X、记录数据缺失状态的相应掩码矩阵 M 和噪声 z。生成器 G 为 X 中的缺失值生成一系列值(尽可能接近真实值分布),以欺骗新更新的判别器。相比之下,判别器D 的输入由估算矩阵X(由生成器 G 产生)和原始数据矩阵 X 组成,鉴别器 D 的目的就是将估算值与真实值区分开来。
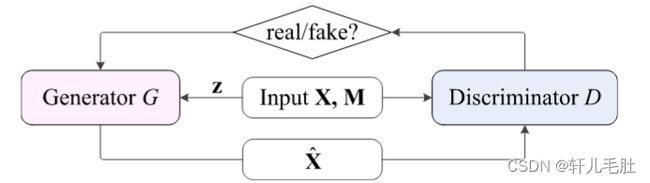
图3.7基于 GAN 的填补架构
换句话说,在基于 GAN 的填补方法中,训练判别器 D 来最大化正确预测 M 的概率,而训练生成器 G 来最小化判别器 D 预测 M 的概率。因此,基于 GAN 的填补方法的损失函数,用ℒGAN表示,通常可以定义为![]()
ℒGANG,D=M⊙logDX+(1−M)⊙log(1−DGX,z)![]()
其中DX表示判别器对 X 中数据的估计概率。因此,与标准GAN相同,基于GAN的填补方法的目标函数可以定义为极大极小问题,即minGmaxDℒGANG,D。具体的基于GAN的填补方法如下:![]()
(1)GINN。图填补神经网络(GINN)是一种在 GAN 结构基础上进行单值填补的生成模型。对于 GINN 生成器来说,最基本的步骤是将每个样本编码为一个节点,从而构建基于流形正则化的相似性图。然后,在相似性图上使用图卷积去噪自编码器。它是通过最小化观测值的重构误差来训练的。由于生成器必须骗过判别器Dg(与标准 GAN 中的判别器相似)并同时最小化重构误差,因此其损失函数ℒGg定义为![]()
ℒGg=M⊙CgX,GgX,zg−(1−M)⊙DgGgX,zg![]()
其中zg是Gg的噪声。对于 X 的特征fj上的每个观察值xij (即掩码矩阵M中对应位置的mij为1),Cg定义为:![]()
Cgxij,xij=β∗xij−xij2 fj是数值型 β−1∗xij∗logxij fj是类别型
其中xij=Ggxij,zg,β是数据集数值特征和分类特征之间的比率的超参数。最终估算矩阵中的缺失值由经过训练的生成器Gg预测。受 GAN 中的判别器的启发,GINN 利用前馈网络作为判别模型Dg进行学习,将估算值与真实观测值区分开来,从而提高图卷积去噪自编码器的填补性能。因此,判别器的损失函数ℒDg表示被定义为: ![]()
ℒDg=(1−M)⊙DgGgX,zg−M⊙DgX
GINN通过对抗过程增强了图卷积去噪自编码器模型,同时训练判别器和图卷积去噪自编码器模型。
(2)GAIN。与标准GAN类似,生成对抗网络(GAIN)也由一对生成器(用GA表示)和判别器(用DA表示)组成,这两个都被建模为全连接神经网络,同时它使用小批量策略以迭代的方式来解决极小极大最优化问题。具体来说,在 GAIN 中,生成器GA最小化更新的判别器DA预测M的概率,并为整个数据 X 输出一个矩阵X(用GA(X ,za))。在训练GA 时,GA生成的矩阵X 也应该接近 X 中的真实值。也就是说,生成器GA的损失函数可以定义为
ℒGA=α∗M⊙CaX,GAX,za−(1−M)⊙logDAGAX,za,H![]()
其中za是GA的噪声,α是超参数。对于 X 的特征fj上的每个观察值xij (即掩码矩阵M中对应位置的mij为1),Ca定义为:![]()
Caxij,xij=xij−xij2 fj是数值型 −xij∗logxij fj是类别型
其中xij=GAxij,za,然后训练GA以最小化ℒGA。另一方面,GAIN 将生成器GA固定优化判别器 DA。判别器用于区分哪些值是观测值哪些值是估计值,也就是说,判别器是最大化正确预测 M 的概率。此外,GAIN 提供了一个提示矩阵,用 H 表示。DA使用提示矩阵 H 将注意力集中在某些缺失值的填补精度上,从而驱动GA准确地学习唯一的真实数据分布。因此,DA的损失函数ℒDA定义为:![]()
ℒDA=−M⊙logDAX,H+(1−M)⊙log(1−DAGAX,za,H)![]()
最后,生成器GA和判别器DA都在具有损失函数的最大最小化过程中中同时训练。![]()
综上所述,这些深度学习填补方法如表4所示。其中在预测类型中, “一对多”表示为整个不完整数据集构建一个预测模型。在填补类型中,“单一填补”是指采用一定方式,对每个缺失值只构造一个合理的替代值,并将其插补到原缺失数据的位置上,替代后构造出一个完整的数据集。“多重填补”是指创建数据集的多个副本,并对每个副本使用不同的估计方法来估算缺失值。
表4 深度学习填补算法的比较
| 类别 |
方法 |
模型 |
预测类型 |
填补类型 |
核心 |
| 深度学习 |
MIDAE |
AE |
一对多 |
多重填补 |
广义DAE |
| 深度学习 |
VAEI |
AE |
一对多 |
单一填补 |
广义VAE |
| 深度学习 |
HI-VAE |
AE |
一对多 |
单一填补 |
用于异构数据填补的广义VAE |
| 深度学习 |
MIWAE |
AE |
一对多 |
单一填补 |
考虑观察数据加权的广义IWAE |
| 深度学习 |
GINN |
GAN |
一对多 |
单一填补 |
在相似性图上使用图卷积算法AE |
| 深度学习 |
GAIN |
GAN |
一对多 |
单一填补 |
带有提示矩阵和噪声的对抗训练 |
实验
数据集:
总共15个基准数据集,使用了三种数据类型
(i) 数值数据集仅包含数值特征(简称 NumFs),包括 EEG、Abone、Wireless、Yeast、Balance、Valley 和 Wine。
(ii) 分类数据集仅包含分类特征(简称 CCatFs),包括 Connect、Ches、Letter、Turkiye、Car 和 Phishing。
(iii) 混合类型数据集包含数值和分类特征,包括 Anuran 和 Heart
指标:
第一个是平均均方根误差(ARMSE),它使用均方根误差(RMSE)进行数值特征,将准确度误差(AR)用于分类特征。ARMSE越小,填补效果越好。
第二个是利用平均绝对误差(MAE)进行数值特征估计,AR用于分类特征,AMAE越小,填补效果越好
实验一:在MCRA机制下,不同数据类型对填补算法的影响:


在数值、分类和混合类型数据集中,相应的实验结果如表7所示,其中Avg-num/cat/mix行分布表示数值、分类、和混合类型数据集的平均结果。从中可以观察到,所有的填补方法在数值数据集中都比在分类数据集中具有更高的填补精度(较小的ARMSE/AMAE值)。
我们可以进一步观察到,对于统计方法,在大多数情况下,KNNI 优于均值插补。在机器学习方法中,RRSI 优于所有其他方法。此属性归因于有效的 MLP 模型和 RRSI 的有用 Sinkhorn 散度损失函数。然而,MICE、IIM、MLPI 和 RRSI 在计算上是不可行的,并且由于执行时间长(超出接受范围),一些大型高维数据集中没有相应的结果。这是因为,所有这些方法都具有很高的复杂性,为每个不完整的特征构建至少一个预测模型。我们还发现,SI 和 MFI 不是很有效,尤其是与其他机器学习方法相比。关于深度学习算法,VGAIN、GAIN 和 MIWAE 属于第一类。虽然 MIWAE 非常昂贵,但即使是在相对较大的高维数据集上也没有工作。总之,基于 SNN 的方法和一些深度学习技术在插补问题上的准确率高于其他方法。