NLP学习
参考:NLP发展之路I - 从词袋模型到Transformer - 知乎 (zhihu.com)
NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。
NLP技术,全称为Natural language Processing,即自然语言处理技术,也就是用计算机来处理人类语言的学科。
这一时期最有代表性的方法是词袋模型(Bag of Words, or BOW),即统计文章中每个词出现的频率,然后对这个频率的向量进行各种各样的统计分析。比如可以根据正向词汇和负向词汇在文中出现的频率对比,来判断文章的情感倾向。或者用词频向量去训练一个分类器,做文本分类任务。

词袋模型是一个简单有效的办法。即使在普遍使用深度学习的今天,这个方法仍有时候被作为快速验证或比较基准来使用。
词频向量实际上是将人类语言翻译成了一种机器能看懂的方式,有两项信息损失最为突出:第一个是词袋模型中,每个词都是独立的,没有相对的语义关系,无法使用词与词之间的关联来更好地帮助分析。第二个是词袋模型完全忽视了语序信息。例如,“我,很不好”和“不,我很好”两句的词频向量完全相同,但语义却相反。
不过在深度学习出现之后,这两个问题都得到了解决。
WordEmbedding: 深度学习解决语义问题
2012年,深度学习在ImageNet比赛中碾压了其它传统的机器学习方法,拉开了划时代的大幕。
深度学习无需手写任何规则,而是依赖大量的数据进行训练。简单来说,深度学习,也就是神经网络,是通过给模型看大量的数据,并对每次模型输出的结果与正确答案比对,让模型自己慢慢调整到正确的方向。由于神经网络的参数远多于一般机器学习模型,在较大数据量的训练下,可以对数据中复杂的隐含的关系进行更精确的建模,因此能够实现其他方法达不到的准确度。
2013年,谷歌的研究员Mikolov使用神经网络训练了词向量(word embedding,有些文献又称“词嵌入”,但还是“词向量”更直观一些)。研究者使用一个简单的一层全连接的神经网络,通过“给出一句话的上文,让模型去预测下一个词”的方式去训练。在看过了大量文章之后,这个神经网络便可将语言中隐含的语义信息”记“在自己的参数中。比如“我想喝一杯”,后文是“水”或是”茶“的概率差不多,那么模型对这两个词的参数也会差不多,即输出的的词向量也是相似的。这样,模型便学会了同义词。
词向量的一个重要性质就是,这个向量在高维空间中的位置关系即可代表语义的关系。比如相似的词可能会聚拢在一起,甚至“法国“与”巴黎”的距离和”英国”与”伦敦”之间的距离都是相似的。
Word2Vec词向量可以抓住不同词之间的相对语义关系 (source: NCAA word2vec lecture notes)

这种给模型喂上文,让模型去预测下文的训练方式,被称为Language Modeling,也就是语言模型或语言建模。这种训练方式不需要人工标注,模型结果可以直接和原文对比,从而能够利用到海量的数据。这种语言建模的方法后面还会一次又一次地被用到,目前实现技术突破的大语言模型也是应用此方法。
RNN: 循环神经网络解决语序问题
语义的问题解决之后,RNN的出现又解决了语序问题。
全连接神经网络是最简单的神经网络模型,在此之上又发展出两类主要的变体,一个是卷积神经网络(Convolutional Neural Network, or CNN) 和循环神经网络(Recurrent Neural Network, or RNN) 。CNN的输入采用滑动一个固定窗口的方式,每次只考虑附近的信息,适合处理图像问题,能做到又快又好。而RNN的输入是按顺序一个一个接收的,在处理完上一个信息之后才会处理下一个信息,天然是阅读文章的一把好手。
LSTM(RNN的一种模型)示意图 (source: Modeling Genome Data Using Bidirectional LSTM)

使用词向量(语义)+RNN(语序)的方法成为这一时期的王者,在各项NLP通用任务上表现颇为亮眼。
研究者们在这一时期的主要工作是在词向量+RNN的基本思想上,对网络架构进行各种各样的改动,用叠加各种buff方式来提升模型的表现。
词向量+RNN这样的NLP已经相对比较接近人脑处理语言的方式了。然而还是有一个显著的缺陷,那就是无法像人一样根据上下文处理多义词的含义。由于词向量的训练方式,每个词只能有一个固定的词向量。如果一个词有两个同样常用的,但毫不相关的含义,那么这个词向量在高维空间内只能处于这两个位置的中间点,实际效果就是两边都没法准确建模。
语言模型解决上下文问题
ELMo的作者大开脑洞,谁说没法处理上下文含义啊,语言模型不就是一个天然的、考虑了上下文的模型吗?当RNN一个一个吸收完前文,再吐出来的最后一个词,这个输出显然已经是包含了上文信息的。于是ELMo的作者训练了一个双向的LSTM模型(LSTM是RNN的一种)。这个模型通过把文章从前往后读一遍,再从后往前读一遍,来接收上文和下文的信息。然后作者将这个过程中的三层输出进行组合,就变成了ELMo词向量(Embeddings from Language Models)从此,我们把文本放进ELMo模型里,拿到的输出就可以作为词向量使用。而每次的输入句子不同时,即使同一个词的词向量也会有所不同,因为ELMo的输出是考虑到了整个句子的信息的。
LSTM(Long Short-Term Memory,长短期记忆)是一种特殊的循环神经网络(RNN),它被广泛用于解决一些与序列和时序相关的深度学习问题。传统的RNN在处理长序列时,会出现梯度消失或梯度爆炸的问题,这使得它们无法有效地记住序列中的长期依赖关系。为了解决这个问题,LSTM被设计出来。
LSTM的核心思想是通过引入一种称为“门”的机制来控制信息的流动。它有三个主要的门:输入门、遗忘门和输出门。这些门可以学习在何时让信息进入、何时让信息保留、何时让信息输出,从而有效地解决了长期依赖的问题。
具体来说,LSTM的工作流程如下:
- 遗忘门:这个门决定上一时刻的单元状态有多少保留到当前时刻。它会读取上一时刻的输出和当前时刻的输入,然后通过一个sigmoid函数输出0到1之间的数值,表示保留的比例。
- 输入门:这个门决定当前时刻网络的输入有多少保存到单元状态。首先,一个sigmoid函数决定哪些值需要更新,然后一个tanh函数生成新的候选值,这些新的候选值可以被添加到状态中。
- 单元状态:这个状态负责在网络中传递信息。首先,我们将上一时刻的状态和遗忘门的输出相乘,丢弃不需要的信息。然后,将输入门的输出和候选值相乘,添加到状态中。这样,我们就得到了新的单元状态。
- 输出门:这个门决定单元状态有多少输出到LSTM的当前输出值。首先,一个sigmoid函数决定哪些部分的状态需要输出,然后将单元状态通过tanh函数进行处理(得到一个在-1到1之间的值),并将它和sigmoid函数的输出相乘,最终得到LSTM的输出。
通过这种方式,LSTM可以选择性地记住或遗忘序列中的信息,从而可以有效地处理具有长期依赖关系的序列数据。这使得LSTM在许多任务中都取得了很好的效果,例如语音识别、自然语言处理(NLP)、时间序列预测等。
Elmo的三层组合词向量 (source: Analytics Vidhya)
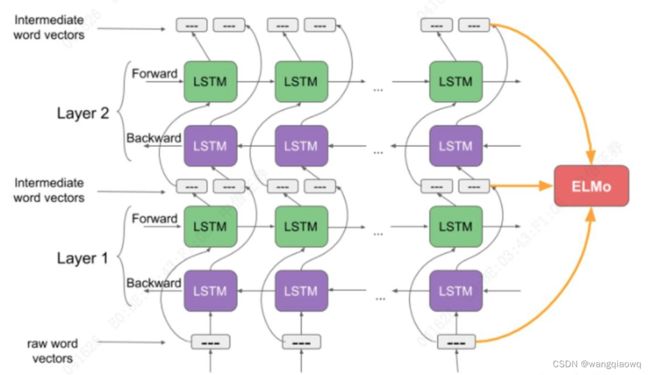
语义解决了,语序解决了,甚至上下文含义也解决了。从思想上看,这时NLP模型越来越接近人类处理语言的方式。RNN需要一个词一个词地处理,在处理大数据时,这个时间差异就十分巨大。RNN的长期记忆还不太好。因为RNN把信息存储在一个固定纬度的向量里,就好比一个打包盒,每多加一个词,就往这个打包盒里压缩一次。到输出层,需要把这个打包盒打开、找到相关的信息的时候,恐怕最开始输入的信息都已经被压缩得面目全非了,很难解码。
Transformer大幅提升效果
2018年,本世纪NLP界最大的外挂诞生了。这就是Transformer。
先说一下注意力机制(attention)
人们发现如果能让输入和输出直接建立一个连接,让模型去学习特定的目标词应该更关注哪些输入词,而不是只从RNN压缩的打包盒里解码,会非常好地提升翻译的表现。attention被作为一种增强手段,用在循环或卷积神经网络上。其中一个重要的点是,attention能非常有效地解决RNN长期记忆不好的缺点,输入序列的任何两个词之间都有联系关系,真正实现了“天涯若比邻”。
**Attention(注意力机制)**是深度学习中的一个重要概念,它的核心思想是在处理复杂数据时,允许模型集中关注于最相关的部分,而忽视其他不太相关的信息。
在深度学习的上下文中,特别是在处理序列数据(如文本、时间序列等)时,注意力机制允许模型在处理一个序列的元素时,将更多的“注意力”放在与该元素更相关的其他元素上。这使得模型可以更有效地处理长序列,并捕获序列中的长期依赖关系。
注意力机制的实现方式有很多种,但大多数都涉及到计算一个权重分布,这个分布决定了在处理一个序列的元素时,应该如何关注其他元素。这个权重分布通常是通过计算元素之间的相似性或相关性得到的。
自注意力机制(Self-Attention)是注意力机制的一种特殊形式,它允许模型在处理一个序列时,关注该序列中的其他位置。自注意力机制的一个关键优点是它能够捕获序列中的长期依赖关系,而且它的计算复杂度不随序列长度的增加而线性增长,这使得它能够更有效地处理长序列。
Transformer模型就是完全基于自注意力机制的深度学习架构,它在NLP领域取得了很好的效果。在Transformer中,注意力和前馈神经网络是其主要的构成部分,而传统的RNN和CNN结构被完全摒弃。
总的来说,注意力机制是一种强大的工具,它允许深度学习模型更有效地处理复杂数据,特别是序列数据。
Transformer的创新之处在于,将attention的输入与输出之间的连接,变为输入与输入自己的连接,这相当于在做任务时,把每个词都在上下文的语境中理解一次。作者称为自注意力机制(self-attention)。使用时将语义信息(词向量)和语序信息(序号)作为输入。由于自注意力模型之下词与词之间的联系变得很直接,这种模型能更好地编码输入的上下文信息,训练的反馈也能得到很好的传导。
Transformer的另一个厉害之处在于它可以毫无压力地进行并行计算。虽然它的计算量相比RNN大大增加了,但由于可以并行计算,在拥有足够算力的情况下,需要的时间反而变少了。

Transformer出现之后,由于效果太好,大家几乎完全抛弃了其他的架构。如果说RNN时代是百花齐放的春秋战国,Transformer就是秦王扫六合,一举统一了整个NLP模型江湖。Transformer的性能使整个NLP界从蒸汽时代迈入了内燃机时代,也使得后续效果超群的大模型的出现成为可能。
参考:NLP发展之路II - 从BERT到ChatGPT - 知乎 (zhihu.com)
预训练-微调时代
2018年,BERT和初代GPT几乎在同一时间出现。BERT由谷歌开发,GPT由OpenAI开发
首先,它们都采用了Transformer,甚至层数也相同。
其次,它们都使用了当时几乎所有开源的、较高质量的NLP数据,如wikipedia, 书籍等。
最后,它们的训练方法都是语言建模Language Modeling,即给模型输入上文,令其预测下文的方法。从而可以使用大量文本而无需人工标注。
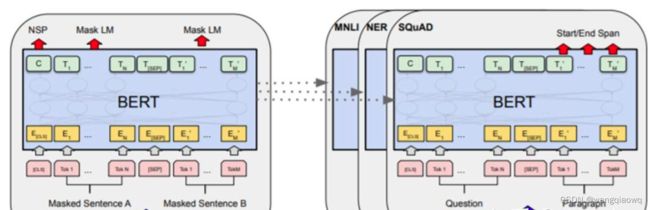
BERT和GPT的参数量大约在亿级,在当时已经是从未出现过的“大模型”了。加上使用了当时可获得的几乎所有高质量文本数据训练,研究者发现,这两个模型在大量数据中学到了对语言的基本理解和一些通用的世界知识,并且将这些知识被储存在模型的参数中。有了这样的“义务教育”打底,在此基础上,只需针对各个专业下游任务(如情感分析、对话生成)进行一个小范围的基于监督学习的微调,比如只调整模型最后一层的参数,居然可以打败很多专门针对这些任务开发的模型。这就是‘’预训练-微调‘’模式。
BERT的预训练模型可以用来做不同的下游任务 (source: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
GPT是一个单向模型。OpenAI采用标准的Language Modeling方式进行训练,模型根据上文来推测下文。
BERT是一个双向模型。Google在训练BERT的时候,挖掉输入文本中15%的词,让模型去完成类似完形填空的任务
BERT和GPT架构的区别 (source: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
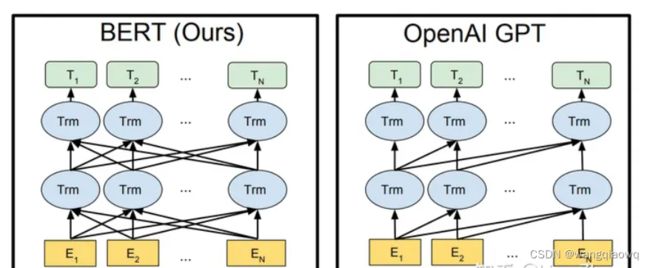
ERT模型由于同时可以看到目标词上下文的信息,一般在理解类任务上表现较好。而GPT模型只能看到上文,在此类任务上表现略逊一筹。但是这类单向模型天然更适合生成类任务,表现也稍好。
这一时期的流行做法是,无论什么任务,先来一个BERT打底,再换掉最后一层,用自己的数据进行微调,让模型产出成为自己需要的格式。尤其是在自己的数据不多的情况下,这样做普遍比自己从头训练Transformer效果要好。
大语言模型时代:Prompt代替微调
OpenAI提出了非常巧妙的办法来忽悠模型完成任务——小样本提示词(Few Shot Prompt),也就是先给模型一些问答的例子,最后留出一个问题。因为作为预测下文的语言模型,GPT-2的目标是续写我们提供的输入,而在这个过程中,就正好回答了我们最后留出的问题。使用这样的方法,GPT-2就可以在未经微调的情况下来完成各种它并没有被专门训练过的任务。
利用提示Prompt和大语言模型互动 (Source: GPT-3: Language Models are Few-Shot Learners)
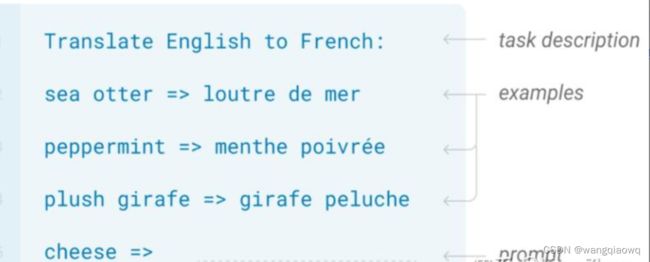
Prompt模式本质是文本生成,刚好是GPT这样单向模型更为擅长的。因此在目前大语言模型的训练中,研究者们变成了更多采用GPT而不是BERT。
大模型的涌现能力:大力出奇迹
OpenAI继续沿着大力出奇迹的道路前行,发布了GPT-3。
GPT-3与GPT-2在模型架构上没有区别,只是采用了更大的模型和更多的数据,将参数提升到千亿级别,是BERT的五百倍。在标准NLP任务的测试中,又展现出了不小的提升,而且人们发现了这个模型出现了一些之前模型没有的,处理复杂任务能力。
模型解决某些相对简单直接的任务能力是随着模型的增大逐渐线性增长的,而解决另外一些较复杂任务的能力,则是在模型达到某个量级之后突然出现的,我们称之为涌现能力(Emergent Ability)。
大模型的涌现能力(source: Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models)
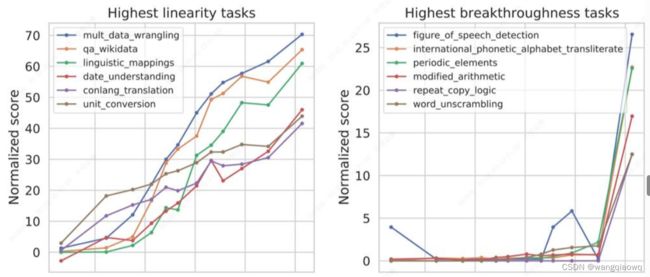
这类涌现能力有一些共同的特点:比如任务是需要多步骤解决,逻辑推理能力比较重要等等。
一个突出的涌现能力叫做思维链能力(Chain-of-Thought,简写为CoT)。这个现象是:如果在prompt当中加入一个一步步推理的例子,然后再问问题,能够提高模型的准确率,把以前做不对的题做对。一个可能的猜想是思维链prompt中给出了与目标答案更加相关的文本(也就是人工写的相似的例子),这些文本会激发模型中的相似记忆,帮助它找到更相关的答案。
引爆全球:逻辑思维和对话能力的增强
Codex 增加GitHub上所有的代码作为训练数据的模型
InstructGPT,这里OpenAI使用了一种基于强化学习的方法RLHF(Reinforcement Learning from Human Feedback with dialogue)RLHF的具体方法是首先让人类标注员来写一些prompt和对应的答案,然后用这个数据集去微调GPT-3,然后再让人工为这个新GPT-3的输出排序,用这个排序信息训练一个reward模型来辨别什么样的回答是人类喜欢的,最后再用这个reward模型和强化学习的方法去继续训练GPT-3。
ChatGPT在GPT-3的架构和训练数据基础上,增加代码数据,再加上RLHF指令微调训练而成,内部代号GPT-3.5。
其能力分解开来大致就是GPT-3提供语言理解能力和世界知识,Codex增强逻辑推理能力,InstructGPT提供对话能力。OpenAI又对后端基础模型进行了升级,从最开始的GPT-3.5升级到了GPT-4,性能上又有大幅提升,而且可以接受图像作为输入。
至此,我们已经回顾完了NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。
ChatGPT(Chat Generative Pre-training Transformer)是自然语言处理(Natural Language Processing,NLP)领域的一种AI模型。
OpenAI 还发布了支持语音转文本的 Whisper API。