性能测试_Day_06(参数化应用、后置处理器、正则表达式)
性能测试_Day_06(参数化应用、后置处理器、正则表达式)
- JMETER 参数化应用
- JMETER 数据量预估值
- JMETER 后置处理器-正则表达式提取器
-
- 应用范围(Apply to)
- 检查当前的响应字段(Field to Check)
- 正则表达式填写参数规范
-
- 引用名称(Reference Name)
- 正则表达式(Regular Expression)
- 模板(Template)
- 匹配数字(Match No)
- 缺省值(默认值)
JMETER 参数化应用
使用函数助手,获取第几个线程的显示
就是显示,现在执行的是,第几个线程!

使用函数助手,获取一个计算器,显示执行到第几次迭代
就是显示,现在执行的是,第几次迭代!

从函数助手里面,复制粘贴到,请求任务,名称里面
${__threadNum}-${__counter(,)}-${name}
函数之间的-横杆,是为了显示好看一点

设置好用户数,和迭代数 看看这两个函数,的显示 {__threadNum}、{__counter(,)}

执行以后,查看结果树,清晰看见,第几个线程(用户数)和第几次迭代数

JMETER 数据量预估值
- 参数化策略UEC
- (Unique-Each iteration-continue)循环使用CSV参数数据
- UEC(测试登录)
- 参数化策略UEA
- (Unique-Each iteration-about)当CSV数据不够的时候就停止
- UEA(已支付的订单,删除过数据,12306同一个票号)用过一次就不能重复用
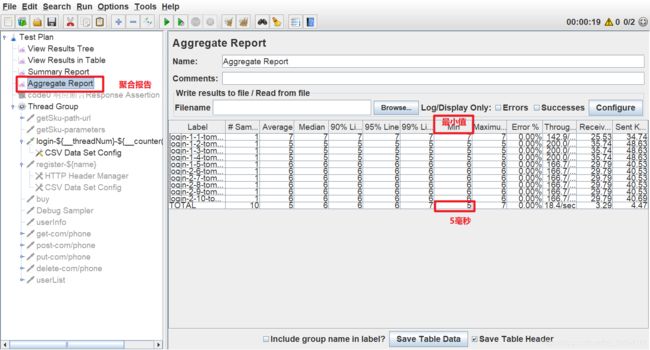
假设:1uv,1iter,5ms(1个用户,迭代1次,需要5毫秒)
如果:持续5分钟,需要多少条数据?
已知:一条数据平均最快是:5毫秒,持续时间300秒
秒转毫秒单位换算:300s(秒)=3000ms(毫秒),
需要多少条:3000/5=600条
结果:如果需要持续5分钟的话,1个用户至少要准备600条数据
估算
假设10uv ,持续5分钟,10*300s(秒)=3000条,如果计算机性能好,参考按照2倍的算
JMETER 后置处理器-正则表达式提取器
| 英文 | 中文 | 路径 |
|---|---|---|
| Regular Expression Extractor | 正则表达式提取器 | 右键一个请求-Add-Post Processors-Regular Expression Extractor |
应用范围(Apply to)
Main sample and sub-samples: 当前父、子节点取样器
Main sample only:仅作用于父节点取样器
Sub samples only: 仅作用于子节点取样器
JMeter Variable:变量值进行匹配,作用于jmeter变量(输入框内可输入jmeter的变量名称),从指定变量值中提取需要的值。

检查当前的响应字段(Field to Check)
1、主体:响应报文的主体,最常用
2、Body(unescaped):主体,是替换了所有的html转义符的响应主体内容,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
3、Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
4、Response Headers:响应信息头
5、Request Headers: 请求信息头
6、URL:请求url
7、Response Code: HTTP的响应状态码,比如200、404等
8、Response Message: 响应的信息
正则表达式填写参数规范
引用名称(Reference Name)
Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名,后文中引用方法是$
正则表达式(Regular Expression)
使用正则表达式解析响应结果,()括号表示提取字符串中的部分值,前后是提取的边界内容。
() 括起来的部分就是需要提取的,对于你要提的内容需要用小括号括起来
. 点号表示匹配任何字符串
+ 一次或多次
? 在找到第一个匹配项后停止
模板(Template)
正则表达式的提取模式。
如果正则表达式有多个提取结果,则结果是数组形式
'$1$' to refer to group 1, 第一种模板
'$2$' to refer to group 2, etc. 第二种模板
'$0$' refers to whatever the entire expression matches. 整个表达式的任何内容
匹配数字(Match No)
0代表随机取值,从1开始取值
-1代码取全部
缺省值(默认值)
匹配失败时候的默认值;通常用于后续的逻辑判断,一般通常为特定含义的英文大写组合,比如:ERROR等
勾选:Default Value is empty 使用空值为默认值