哈希/散列表的课程设计(数据结构)
目录
1 人员组成及分工……………………………………………1
2 分析和设计…………………………………………………1
3 实现…………………………………………………………2
4 关键代码……………………………………………………3
5 测试…………………………………………………………17
6 总结…………………………………………………………19
7 附件…………………………………………………………20
8 说明…………………………………………………………20
1 人员组成及分工
xxx:控制台的搭建以及冲突解决之拉链法
xxx:冲突解决之线性探测和二次探测
2 分析和设计
1)设计一组关键码,个数为N,N>30。
2)设计一个散列函数H(Key),自行定义其散列公式。
3)根据关键码情况和N设计一个长度为M的数组,作为散列表的存储空间。
4)设计闭散列表,采用地址线性探测法和二次探测法检测冲突。
线性探测法:
依次计算各个关键字的散列地址,如果没有冲突,将关键字直接存放在相应的散列地址所对应的单元中;否则,用线性探测法处理冲突,直到找到相应的存储单元中。
如对前三个关键字进行计算, H(l9)= 19, H(l4) = 14, H(23) = 23, 所得散列地址均没有冲突,直接填入所在单元。
而对第14个关键字, H(45) =: 14, 发生冲突,根据线性探测法,求得下 一 个地址 (14 + 1)% 31 = 15 ,没有冲突,所以45填入序号为15的单元。
二次探测法:
依次计算各个关键字的散列地址,如果没有冲突,将关键字直接存放在相应的散列地址所对应的单元中;否则,用二次探测法处理冲突,直到找到相应的存储单元中。
如图2所示对前三个关键字进行计算, H(l9)= 19, H(l4) = 14, H(23) = 23, 所得散列地址均没有冲突,直接填入所在单元。
而对第24个关键字, H(53) =22, 发生冲突,根据线性探测法,求得下 一 个地址 31 ,没有冲突,所以53填入序号为31的单元。
5)设计开散列表,使用拉链法。
依次计算各个关键字的散列地址,如果没有冲突,将关键字直接存放在相应的散列地址所对应的单元中;否则,用线性探测法处理冲突,直到找到相应的存储单元中。
如对前三个关键字进行计算, H(l9)= 19, H(l4) = 14, H(23) = 23, 所得散列地址均没有冲突,直接填入所在单元。
而对第14个关键字, H(45) =: 14, 发生冲突,根据拉链法 ,直接将45填入序号为14的单元的单链表中。
6)数据结构:哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码 映射的位置去寻找存放值的地方,也就是通过H(key)寻找key
7)思考:对于闭散列表,当填充达到一个阀值后,自动增长其空间,以便减少冲突,如何处理?
建立一张新表,将新存入的数据放到新表里面!
3 实现
1)、设关键字序列为
Key { 19 14 23 1 68 20 84 31 55 42 41 90 79 45 65 22 33 100 32 17 88 36 44 53 12 118 10 85 66 61 64 }共N=31个
2)、散列公式为:
H(key)=key MOD 31
哈希函数也并不是固定的,可以自己根据情况来定,一般常用常见的有直接定址法,除留余数法,平方取中法,折叠法,随机数法,数字分析法。当向该结构插入元素时,存入根据关键码以此函数计算出的位置,当搜索时,也是先要将给定的关键码用函数转换成存储位置进行查找,将得到位置处的元素进行比较,若关键码相同,则搜索成功。
但是通过一个哈希函数得到的位置,一定是会有冲突的,例如用除留余数法,哈希函数为key/100。在此情况下数字1与数字101得到的存储位置就是相同的,这样就是哈希冲突, 哈希冲突一般有两种解决方式,一种是闭散列,另一种是开散列。
3)、哈希表长为M=35 ,作为散列表的存储空间,并且散列表中所有单元填充为-1
4)、闭散列表的设计,采用地址线性探测法和二次探测法检测冲突,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中还有空位,那就可以把key值存放到了列表的下一个空位。
5)、开散列表的设计,使用拉链法解决冲突。首先对关键码集合用哈希函数计算哈希表中的偏移位置,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
4 关键代码
#include "stdio.h"
#include "stdlib.h"
#define HASHSIZE 31 //定义散列表长为数组的长度
#define NULLKEY -1
typedef struct{
int *elem;//数据元素存储地址,动态分配数组
int count; //当前数据元素个数
}HashTable;
//对哈希表进行初始化
void Init(HashTable *hashTable){
int i;
hashTable->elem= (int *)malloc(HASHSIZE*sizeof(int));
hashTable->count=HASHSIZE;
for (i=0;i<HASHSIZE;i++){
hashTable->elem[i]=NULLKEY; //给哈希表中所有表格赋默认值为-1
}
}
//哈希函数(除留余数法)
int Hash(int data){
return data%HASHSIZE;
}
//哈希表的插入函数,可用于构造哈希表
void InsertLine(HashTable *hashTable,int data){
int hashAddress=Hash(data); //求哈希地址
//发生冲突
while(hashTable->elem[hashAddress]!=NULLKEY){
//利用开放定址法解决冲突(线性探测法)
hashAddress=(++hashAddress)%HASHSIZE;
}
hashTable->elem[hashAddress]=data;
}
void InsertTwo(HashTable *hashTable,int data){
int hashAddress=Hash(data); //求哈希地址
//发生冲突
int CNum=0;
while(hashTable->elem[hashAddress]!=NULLKEY&&hashTable->elem[hashAddress]!=data){
//利用开放定址法解决冲突(二次探测法)
if(++CNum%2){
hashAddress = hashAddress + (CNum+1)/2*(CNum+1)/2;
while(hashAddress>=hashTable->count)
hashAddress -= hashTable->count;
}else{
hashAddress = hashAddress - CNum/2*CNum/2;
while(hashAddress<0)
hashAddress += hashTable->count;
}
}
hashTable->elem[hashAddress]=data;
}
int InsertZipper(HashTable hashTable,int data){
int hashAddress = Hash(data);//求哈希地址
//发生冲突,利用(拉链探测法) 解决冲突
int *p;
p=&hashTable.elem[hashAddress];
/* while(*p!=NULLKEY && *p!=data){
p++;
}
*/
while(*p == NULLKEY){
*p = data;
p++;
}
}
//哈希表的查找算法(线性探测查找)
int SearchLine(HashTable *hashTable,int data){
int hashAddress=Hash(data); //求哈希地址
while(hashTable->elem[hashAddress]!=data){//发生冲突
//利用开放定址法解决冲突
hashAddress=(++hashAddress)%HASHSIZE;
//如果查找到的地址中数据为NULL,或者经过一圈的遍历回到原位置,则查找失败
if (hashTable->elem[hashAddress]==NULLKEY||hashAddress==Hash(data)){
return -1;
}
}
return hashAddress;
}
//哈希表的查找算法(二次查找 )
int SearchTwo(HashTable *hashTable,int data){
int hashAddress=Hash(data); //求哈希地址
while(hashTable->elem[hashAddress]!=data){//发生冲突
//利用开放定址法解决冲突(二次探测)
int CNum=0;
while(hashTable->elem[hashAddress]!=NULLKEY&&hashTable->elem[hashAddress]!=data){
if(++CNum%2){
hashAddress = hashAddress + (CNum+1)/2*(CNum+1)/2;
while(hashAddress>=hashTable->count)
hashAddress -= hashTable->count;
}else{
hashAddress = hashAddress - CNum/2*CNum/2;
while(hashAddress<0)
hashAddress += hashTable->count;
}
}
//如果查找到的地址中数据为NULL,或者经过一圈的遍历回到原位置,则查找失败
if (hashTable->elem[hashAddress]==NULLKEY||hashAddress==Hash(data)){
return -1;
}
}
return hashAddress;
}
//哈希表的查找算法(拉链法查找)
int SearchZipper(HashTable *hashTable,int data){
int hashAddress=Hash(data); //求哈希地址
int *p;
p=&hashTable->elem[hashAddress];
while(*p!=data){//发生冲突
//利用拉链法解决冲突
p++;
if (*p==NULLKEY){
return -1;
}
else
return hashAddress;
}
return hashAddress;
}
//哈希表的删除
int Delete(HashTable *hashTable,int data){
int hashAddress=Hash(data);
while(hashTable->elem[hashAddress]==data){
hashTable->elem[hashAddress] = NULLKEY;
}
if (hashTable->elem[hashAddress]==NULLKEY||hashTable->elem[hashAddress]!=data){
return -1;
}
return hashAddress;
}
int main(){
int i,result;
HashTable hashTable;
int arr[HASHSIZE] = {};
//初始化哈希表
Init(&hashTable);
int n,k,m,key,a,num,x;
printf("请输入要存入哈希表的数字总数(哈希表长为35):") ;
scanf("%d",&x);
printf("请输入要存入哈希表的数字(输入空格隔开):") ;
for(num=0;num<x;num++)
{
scanf("%d",&arr[num]);
}
for(a=0;a<=x;a++){
printf("请选择您要使用的散列表结构:\n");
printf("------------------------------------------------\n");
printf("1 为闭散列表\n");
printf("2 为开散列表\n");
printf("3 为删除列表\n");
printf("------------------------------------------------\n");
printf("请输入:");
scanf("%d",&n);
switch(n)
{
case 1:
printf("请选择检测冲突的方法:\n");
printf("-----------------------------\n");
printf("1 为线性探测法\n");
printf("2 为二次探测法\n");
printf("-----------------------------\n");
printf("请输入:");
scanf("%d",&k);
if(k!=1&&k!=2){
printf("非法输入!!!\n");
break;
}
printf("请输入您要查找的数字:");
scanf("%d",&key);
switch(k)
{
case 1:
//利用插入函数构造哈希表
for (i=0;i<HASHSIZE;i++){
InsertLine(&hashTable,arr[i]);
}
//调用查找算法
result= SearchLine(&hashTable,key);
if (result==-1) printf("查找失败");
else printf("%d在哈希表中的位置是:%d\n",key,result+1);
break;
case 2:
//利用插入函数构造哈希表
for (i=0;i<HASHSIZE;i++){
InsertTwo(&hashTable,arr[i]);
}
//调用查找算法
result= SearchTwo(&hashTable,key);
if (result==-1) printf("查找失败");
else printf("%d在哈希表中的位置是:%d\n",key,result+1);
break;
}
break;
case 2:
printf("开散列表检测冲突的方法为拉链法\n");
printf("请问您是否要继续:\n");
printf("-----------------------------\n");
printf("1 为继续\n");
printf("2 为取消\n");
printf("-----------------------------\n");
printf("请输入:");
scanf("%d",&m);
if(m!=1&&m!=2){
printf("非法输入!!!");
break;
}
printf("请输入您要查找的数字:");
scanf("%d",&key);
switch(m){
case 1:
//利用插入函数构造哈希表
for (i=0;i<HASHSIZE;i++){
InsertZipper(hashTable,arr[i]);
}
//调用查找算法
result= SearchZipper(&hashTable,key);
if (result==-1) printf("查找失败");
else printf("%d在哈希表中的位置是:%d\n",key,result+1);
break;
}
break;
case 3:
printf("您现在执行的是删除操作!警告!警告!\n");
printf("请问您是否要继续:\n");
printf("-----------------------------\n");
printf("1 为继续\n");
printf("2 为取消\n");
printf("-----------------------------\n");
printf("请输入:");
scanf("%d",&k);
switch(k){
case 1:
printf("请输入您要删除的元素:");
scanf("%d",num);
result = Delete(&hashTable,num);
if (result==-1) printf("查找失败");
else printf("恭喜你!操作成功!");
break;
case 2:
printf("取消成功!警告解除!!!\n");
}
}
}
}
5 测试
线性探测法测试

二次查找法测试

拉链法测试
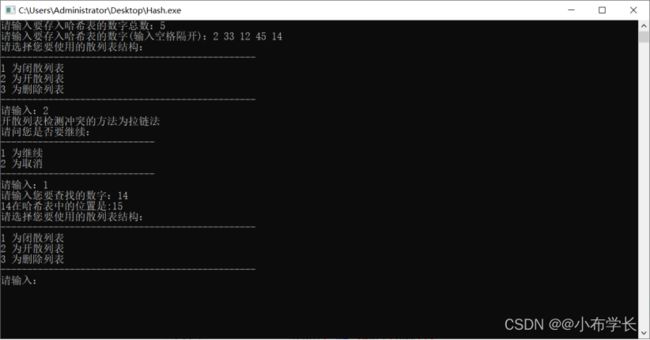
6 总结
课程设计结束了,我和组员一起度过了这段忙碌而充实的时光。这次的课程设计深刻的反映出实践是检验真理的唯一标准这句话的真谛。课程设计是我们专业课程知识综合应用的实践训练,是我们迈向社会,从事职业工作前一个必不少的过程。“千里之行始于足下”,通过这次课程设计,我深深体会到这句千古名言的真正含义。我今天认真的进行课程设计,学会脚踏实地迈开这一步,就是为明天能稳健地在社会大潮中奔跑打下坚实的基础。
这次的课程设计的主题是散列函数技术编程,首先老师先介绍了这次课程设计的主要内容和实施步骤,然后同学们进行分组并选出组长和集成组组员,各组进行分工安排、制定计划,组员明确各自的任务后,互相合作完成工作。在明确各自任务后,我们就开始了真正的哈希技术编程。在需求分析阶段,我们通过各种渠道查阅了许多资料,以及已有的样例等,然后根据资料做了需求分析,最后在不懈的努力下完成了课程设计,收获很多,但仍有很多不足需要改进。
7 附件
