Hadoop之mapreduce数据去重和求平均分(案例)
阅读目录
-
-
- 一、数据去重
-
-
- 使用idea创建Maven项目
- 在pom.xml文件添加Hadoop的依赖库,内容如下:
- 编写Dedup.class
- 运行程序
-
- 二、求平均分
- 关于部分详细说明
-
一、数据去重
使相同的数据在最终的输出结果中只保留一份,
使用idea创建Maven项目
在pom.xml文件添加Hadoop的依赖库,内容如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version> //集群对应Hadoop的版本
</dependency>
</dependencies>
编写Dedup.class
package com.hadoop.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//数据去重类
public class Dedup {
//map()方法将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object, Text,Text,Text>{
private static Text line = new Text(); //每行数据
//重写map()方法
public void map( Object key,Text value,Context context) throws IOException,InterruptedException{
line = value;
context.write(line,new Text(""));
}
}
//reduce()方法将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text,Text,Text,Text>{
//重写reduce方法
public void reduce (Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
context.write(key,new Text(" "));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//构建任务对象
Job job = Job.getInstance(conf,"Data Deduplication");
job.setJarByClass(Dedup.class);
//设置Map、Combine和Reduce处理类
job.setMapperClass((Map.class));
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入金额输出路径
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0:1);
}
}
运行程序
导出jar包重新命名Dedup.jar,然后上传到Hadoop集群
在HDFS的根目录下创建score-input目录
hadoop fs -mkdir /score-input
编写两个需要去重的文件file1.txt和file2.txt


上传两个文件到/score-input目录
hadoop fs -put file1.txt /dedup-input
hadoop fs -put file2.txt /dedup-input
执行jar包(com.hadoop.mr为程序的包名,Dedup为程序类名,/dedup-input/为输入数据的路径,/dedup-output为输出结果存放的位置)
hadoop jar dedup.jar com.hadoop.mr.Dedup /dedup-input/ /dedup-output
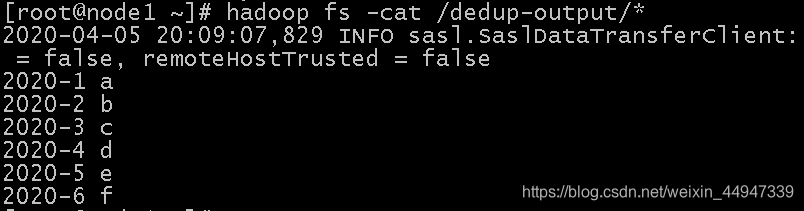
执行jar包后看到以下内容则成功

查看输出结果:
二、求平均分
过程和数据去重的一样(不一样的如下)
编写Score.class
package com.hadoop.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
//求平均分的例子
public class Score {
public static class Map extends Mapper<LongWritable,Text,Text, IntWritable>{
//重写map()方法
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
//将输入的一行数据转化成String
//Hadoop默认是UTF-8编码,如果中文的字符会出现乱码,需要以下面的方法进行转码
String line = new String(value.getBytes(),0,value.getLength(),"Utf-8");
//也可以加入一个参数指定分隔符
StringTokenizer itr = new StringTokenizer(line);
//获取分割后的字符串
String strName = itr.nextToken(); //学生姓名部分
String strScore = itr.nextToken(); //成绩部分
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
//输出姓名和成绩
context.write(name,new IntWritable(scoreInt));
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text, IntWritable>{
//重写reduce()方法
public void reduce(Text key,Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{
int sum = 0;
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
sum += iterator.next().get();
count++; //统计总的科目数
}
int average = (int) sum /count; //计算平均成绩
//输出姓名和平均成绩
context.write(key,new IntWritable(average));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//设置HDFS的访问路径
conf.set("fs.defaultFS","hdfs://192.168.100.101:9000");
Job job = Job.getInstance(conf,"Score Average");
job.setJarByClass(Score.class);
//设置Map、Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//将输入的数据集分割成小数据块splites,提供一个RecordReader的实现
job.setInputFormatClass(TextInputFormat.class);
//提供一个Record Writer的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
//设置输入和输出的路径
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}
编写需要求平均分的文件:

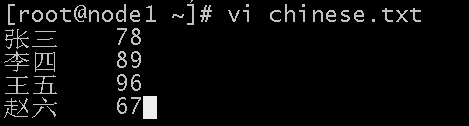
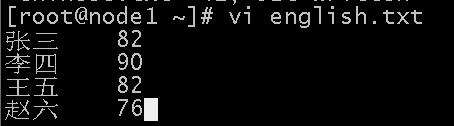
查看输出结果:(取整数)

关于部分详细说明
使用idea创建maven项目,和打包jar包,上传jar包请看这篇博客:Hadoop 之Mapreduce wordcount词频统计案例(详解)