支持向量机c++实现
本人参考李航《统计学习方法》,以及 JC Platt《Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines》实现了一个简易的支持向量机求解方法,采用数据集如链接所示,若发现有问题或不足之处,还忘各位不吝赐教。
数据集: http://download.csdn.net/download/wz2671/10172405
main.cpp
#include
#include "SVM.h"
#include "matrix.h"
#include "mat.h"
#include
#pragma comment(lib, "libmat.lib")
#pragma comment(lib, "libmx.lib")
using namespace std;
const int fn = 13;
const int sn1 = 59;
const int sn2 = 71;
const int sn3 = 48;
const int sn = 178;
int readData(double* &data, double* &label)
{
MATFile *pmatFile = NULL;
mxArray *pdata = NULL;
mxArray *plabel = NULL;
int ndir;//矩阵数目
//读取数据文件
pmatFile = matOpen("wine_data.mat", "r");
if (pmatFile == NULL) return -1;
/*获取.mat文件中矩阵的名称
char **c = matGetDir(pmatFile, &ndir);
if (c == NULL) return -2;
*/
pdata = matGetVariable(pmatFile, "wine_data");
data = (double *)mxGetData(pdata);
matClose(pmatFile);
//读取类标
pmatFile = matOpen("wine_label.mat", "r");
if (pmatFile == NULL) return -1;
plabel = matGetVariable(pmatFile, "wine_label");
label = (double *)mxGetData(plabel);
matClose(pmatFile);
}
int main()
{
doubl e *data ;
double *label;
readData(data, label);
//需要注意从.mat文件中读取出的数据按列存储
double *d;
double *l;
SVM svm;
//第一组数据集与第二组数据集 预处理
l = new double[sn1 + sn2];
for(int i=0; i SVM.h
/*
用支持向量机求解二分类问题
分离超平面为:w'·x+b=0
分类决策函数:f(x)=sign(w'·x+b)
*/
#include
using namespace std;
class SVM
{
private:
int sampleNum; //样本数
int featureNum; //特征数
double **data; //存放样本 行:样本, 列:特征
double *label; //存放类标
double *alpha;
//double *w; 对于非线性问题,涉及kernel,不方便算
double b;
double *gx;
double s_max(double, double);
double s_min(double, double);
int secondAlpha(int);
void computeGx();
double kernel(int, int);
void update(int , int ,double, double);
bool isConvergence();
bool takeStep(int, int);
public:
~SVM();
//初始化数据
void initialize(double *, double *, int, int);
//序列最小最优算法
void SMO();
double objFun(int);
void show();
}; SVM.cpp
#include "SVM.h"
#include
using namespace std;
#define eps 1e-2 //误差精度
const int C = 100; //惩罚参数
SVM::~SVM()
{
if (data) delete[]data;
if (label) delete label;
if (alpha) delete alpha;
if (gx) delete gx;
}
//d中为样本,每个样本按行存储; l标签(1或-1); sn样本个数; fn特征个数
void SVM::initialize(double *d, double *l, int sn, int fn)
{
this->sampleNum = sn;
this->featureNum = fn;
this->label = new double[sampleNum];
this->data = new double*[sampleNum];
for (int i = 0; i < sampleNum; i++)
{
this->label[i] = l[i];
}
for (int i = 0; i < sampleNum; i++)
{
this->data[i] = new double[featureNum];
for (int j = 0; j < featureNum; j++)
{
data[i][j] = d[i*featureNum + j];
}
}
alpha = new double[sampleNum] {0};
gx = new double[sampleNum] {0};
}
double SVM::s_max(double a, double b)
{
return a > b ? a : b;
}
double SVM::s_min(double a, double b)
{
return a < b ? a : b;
}
double SVM::objFun(int x)
{
int j = 0;
//选择一个0 < alpha[j] < C
for (int i = 0; i < sampleNum; i++)
{
if (alpha[i]>0 && alpha[i] < C)
{
j = i;
break;
}
}
//计算b
double b = label[j];
for (int i = 0; i < sampleNum; i++)
{
b -= alpha[i] * label[i] * kernel(i, j);
}
//构造决策函数
double objf = b;
for (int i = 0; i < sampleNum; i++)
{
objf += alpha[i] * label[i] * kernel(x, i);
}
return objf;
}
//判断有无收敛
bool SVM::isConvergence()
{
//alpah[i] * y[i]求和等于0
//0 <= alpha[i] <= C
//y[i] * gx[i]满足一定条件
double sum = 0;
for (int i = 0; i < sampleNum; i++)
{
if (alpha[i] < -eps || alpha[i] > C + eps) return false;
else
{
// alpha[i] = 0
if (fabs(alpha[i]) < eps && label[i] * gx[i] < 1 - eps) return false;
// 0 < alpha[i] < C
if (alpha[i] > -eps && alpha[i] < C + eps && fabs(label[i] * gx[i] - 1)>eps) return false;
// alpha[i] = C
if (fabs(alpha[i] - C) < eps && label[i] * gx[i] > 1 + eps) return false;
}
sum += alpha[i] * label[i];
}
if (fabs(sum) > eps) return false;
return true;
}
//假装是个核函数
//两个向量做内积
double SVM::kernel(int i, int j)
{
double res = 0;
for (int k = 0; k < featureNum; k++)
{
res += data[i][k] * data[j][k];
}
return res;
}
//计算g(xi),也就是对样本i的预测值
void SVM::computeGx()
{
for (int i = 0; i < sampleNum; i++)
{
gx[i] = 0;
for(int j=0; j < sampleNum; j++)
{
gx[i] += alpha[j] * label[j] * kernel(i, j);
}
gx[i] += b;
}
}
//更新很多东西
void SVM::update(int a1, int a2, double x1, double x2)
{
//更新阈值b
double b1_new = -(gx[a1] - label[a1]) - label[a1] * kernel(a1, a1)*(alpha[a1] - x1)
- label[a2] * kernel(a2, a1)*(alpha[a2] - x2) + b;
double b2_new = -(gx[a2] - label[a2]) - label[a1] * kernel(a1, a2)*(alpha[a1] - x1)
- label[a2] * kernel(a2, a2)*(alpha[a2] - x2) + b;
if (fabs(alpha[a1]) < eps || fabs(alpha[a1] - C) < eps || fabs(alpha[a2]) < eps || fabs(alpha[a2] - C) < eps)
b = (b1_new + b2_new) / 2;
else
b = b1_new;
/*
int j = 0;
//选择一个0 < alpha[j] < C
for (int i = 0; i < sampleNum; i++)
{
if (alpha[i]>0 && alpha[i] < C)
{
j = i;
break;
}
}
//计算b
double b = label[j];
for (int i = 0; i < sampleNum; i++)
{
b -= alpha[i] * label[i] * kernel(i, j);
}
*/
//更新gx
computeGx();
}
//选取第二个变量
/*
先选择是对应E1-E2最大的
若没有,用启发式规则,选目标函数有足够下降的alpha2
还没有,选择新的alpha1
*/
int SVM::secondAlpha(int a1)
{
//先计算出所有的E,也就是样本xi的预测值与真实输出之差Ei=g(xi)-yi
//若E1为正,选最小的Ei作为E2,反正选最大
bool pos = (gx[a1] - label[a1] > 0);
double tmp = pos ? 100000000 : -100000000;
double ei = 0; int a2 = -1;
for (int i = 0; i < sampleNum; i++)
{
ei = gx[i] - label[i];
if (pos && ei < tmp || !pos && ei > tmp)
{
tmp = ei;
a2 = i;
}
}
//对于特殊情况,直接遍历间隔边界上的支持向量点,选择具有最大下降的值
return a2;
}
//选定a1和a2,进行更新
bool SVM::takeStep(int a1, int a2)
{
if (a1 < -eps) return false;
double x1, x2; //old alpha
x2 = alpha[a2];
x1 = alpha[a1];
//计算剪辑的边界
double L, H;
double s = label[a1] * label[a2];//a1 与 a2同号或异号
L = s < 0 ? s_max(0, alpha[a2] - alpha[a1]) : s_max(0, alpha[a2] + alpha[a1] - C);
H = s < 0 ? s_min(C, C + alpha[a2] - alpha[a1]) : s_min(C, alpha[a2] + alpha[a1]);
if (L >= H) return false;
double eta = kernel(a1, a1) + kernel(a2, a2) - 2 * kernel(a1, a2);
//更新alpah[a2]
if (eta > 0)
{
alpha[a2] = x2 + label[a2] * (gx[a1] - label[a1] - gx[a2] + label[a2]) / eta;
if (alpha[a2] < L) alpha[a2] = L;
else if (alpha[a2] > H) alpha[a2] = H;
}
else//我也不知道为什么这么算,我抄的论文里的,意思是选到超平面距离近的边界
{
alpha[a2] = L;
double Lobj = objFun(a2);
alpha[a2] = H;
double Hobj = objFun(a2);
if (Lobj < Hobj - eps)
alpha[a2] = L;
else if (Lobj > Hobj + eps)
alpha[a2] = H;
else
alpha[a2] = x2;
}
//下降太少,忽略不计
if (fabs(alpha[a2] - x2) < eps*(alpha[a2] + x2 + eps))
{
alpha[a2] = x2;
return false;
}
//更新alpha[a1]
alpha[a1] = x1 + s*(x2 - alpha[a2]);
update(a1, a2, x1, x2);
/*
for (int ii = 0; ii < sampleNum; ii++)
{
cout << gx[ii] << endl;
}
*/
return true;
}
//由SVM分类决策的对偶最优化问题求解alpha
/*
用序列最小最优化算法(SMO)求解alpha
step1:选取一对需要更新的变量alpha[i]和alpha[j]
step2:固定alpha[i]和alpha[j]以外的参数,求解对偶问题的最优化解获得更新后的alpha[i]和alpha[j]
参考:李航《统计学习方法》
JC Platt《Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines》
*/
void SVM::SMO()
{
//bool convergence = false; //判断有没有收敛
int a1, a2;
bool Changed = true; //有没有更新
int numChanged = 0; //更新了多少次
int *eligSample = new int[sampleNum]; // 记录访问过的样本
int cnt = 0; //样本个数
computeGx();
do
{
numChanged = 0; cnt = 0;
//选择第一个变量(最不满足KKT条件的样本点)
//优先选 0 < alpha < C 的样本 , alpha会随着后面的迭代发生变化
for (int i = 0; i < sampleNum; i++)
{
//记录下不满足KKT条件的样本,做个缓存
if (Changed)
{
cnt = 0;
for (int j = 0; j < sampleNum; j++)
{
if (alpha[j] > eps && alpha[j] < C - eps)
{
eligSample[cnt++] = j;
}
}
Changed = false;
}
if (alpha[i] > eps && alpha[i] < C-eps)
{
a1 = i;
//不满足KKT条件
if (fabs(label[i] * gx[i] - 1) > eps)
{
//选择第二个变量,优先选下降最多的
a2 = secondAlpha(i);
Changed = takeStep(a1, a2);
numChanged += Changed;
if(Changed) continue;
else //目标函数没有下降
{
//先依次遍历间隔边界上的
for(int j=0; j 1)
{
//选择第二个变量,步骤同上
a2 = secondAlpha(i);
Changed = takeStep(a1, a2);
numChanged += Changed;
if (Changed) continue;
else //目标函数没有下降
{
//先依次遍历间隔边界上的
//间隔边界上的点已经记录在eligSample中了
for(int j=0; jeps)
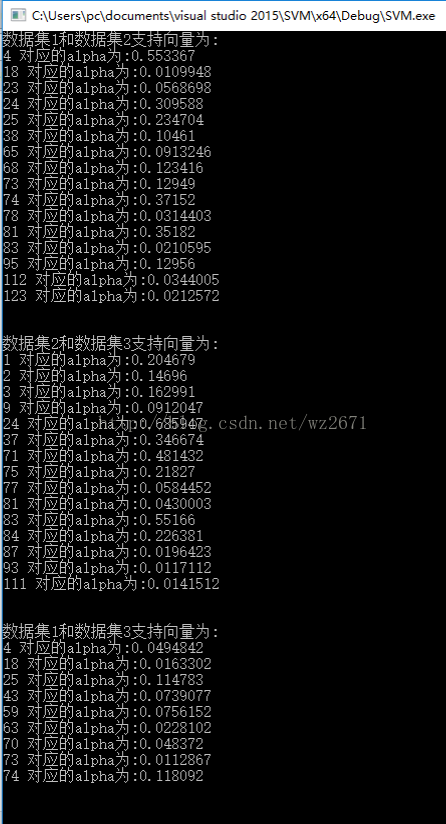
cout < 结果如下图所示: