python刷题笔记1(42例题)
1. split()函数
str.split([sep [, maxsplit]])
分割字符串,返回一个数组

2. 判断子串
# 判断子串是否在主串里面,是则输出“Yes”,否则输出“No”
str1 = input("子串:")
str2 = input("主串:")
if str1 in str2:
print("Yes")
else:
print("NO")子串:hello world 主串:this is hello world, it is ok. Yes
3. 反向输出一个三位数
法一:运用字符串切片

字符串可以切片:

法二:取余和除法
def reverse_integer(num):
reversed_num = 0
while num != 0:
digit = num % 10
reversed_num = reversed_num * 10 + digit
num = num // 10
return reversed_num
# 示例
# num = 12345
num = int(input("输入一个数:")) # erro: 输入100,输出1
reversed_num = reverse_integer(num)
print(reversed_num) # 输出:543214. 22、整数序列的元素最大跨度值
描述
给定一个长度为n的非负整数序列,请计算序列的最大跨度值(最大跨度值 = 最大值减去最小值)。
输入
一共2行,第一行为序列的个数n(1 <= n <= 1000),第二行为序列的n个不超过1000的非负整数,整数之间以一个空格分隔。
输出
输出一行,表示序列的最大跨度值。
样例输入
6 3 0 8 7 5 9
样例输出
9
代码:!!
n = int(input())
s = input().split()
maxV = minV = int(s[0])
for i in s:
maxV = max(maxV,int(i))
minV = min(minV,int(i))
print(maxV-minV)
5. 28、数字统计
描述
请统计某个给定范围[L, R]的所有整数中,数字2出现的次数。
比如给定范围[2, 22],数字2在数2中出现了1次,在数12中出现1次,在数20中出现1次,在数21中出现1次,在数22中出现2次,所以数字2在该范围内一共出现了6次。
输入
输入共 1 行,为两个正整数 L 和 R,之间用一个空格隔开。
输出
输出共 1 行,表示数字 2 出现的次数。
样例输入输出
2 100 20
2 22
6
代码展示:
# 28、!!数字统计
m = input().split()
L, R = int(m[0]), int(m[1])
count = 0
for i in range(L,R+1):
if i%10 == 2:
count+=1
if i // 10 == 2:
count+=1
# 参考答案1:
# total=0
# for i in range(L,R+1):
# while i!=0:
# m=i%10
# if m == 2:
# total+=1
# i//=10
# 参考答案2:
# for i in range(L,R+1):
# s=str(i)
# for x in s:
# if x == '2':
# total+=1
print(count)6. 29、数字反转
描述
给定一个整数,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零(参见样例2)。
输入
输入共 1 行,一个整数N。
-1,000,000,000 ≤ N≤ 1,000,000,000。
输出
输出共 1 行,一个整数,表示反转后的新数。
样例输入输出:
123
321
-380
-83
代码展示:
# 29、数字反转
num = input()
if num == 0:
print(0)
else:
if num[0] == "-":
num = num[1:]
while num[-1] == "0":
num = num[:-1]
else:
num = num
num = num[::-1]
print("-"+num)
else:
while num[-1] == "0":
num = num[:-1]
else:
num = num
num = num[::-1]
print(num)
7.30、求最大公约数问题
描述
给定两个正整数,求它们的最大公约数。
输入
输入一行,包含两个正整数(<1,000,000,000)。
输出
输出一个正整数,即这两个正整数的最大公约数。
样例输入输出:
6 9
3
提示:求最大公约数可以使用辗转相除法:
假设a > b > 0,那么a和b的最大公约数等于b和a%b的最大公约数,然后把b和a%b作为新一轮的输入。
由于这个过程会一直递减,直到a%b等于0的时候,b的值就是所要求的最大公约数。
比如:
9和6的最大公约数等于6和9%6=3的最大公约数。
由于6%3==0,所以最大公约数为3。
代码展示
s = input().split()
a, b = int(s[0]), int(s[1])
if a > b:
while a%b!=0:
c = a % b
a = b
b = c
print(b)
else:
while b%a!=0:
c = b % a
b = a
a = c
print(a)8. 多少种取法(递归)
描述
给定三个正整数m,n,s问从1到m这m个数里面取n个不同的数,使它们和是s,有多少种取法
输入
多组数据
输入的第一行是整数t,表示有t组数据
此后有t行,每行是一组数据
每组数据就是三个正整数,m,n, s ( n <= 10,s <= 20)
5 13 4 20 12 5 18 1 1 1 1 2 1 119 3 20
输出
22 3 1 0 24
代码展示:
def count_ways(m,n,s):
if n == 0 and s == 0:
return 1
elif n == 0 or m == 0:
return 0
if m <= 0:
return 0 # 如果可选的数已经用完,返回0
if m > s:
m = s # 如果可选的最大数大于s,将其限制为s,以减小计算复杂性
return count_ways(m-1,n-1,s-m) + count_ways(m-1,n,s)
n = int(input())
for i in range(n):
a, b, c = map(int,input().split())
#map()会根据提供的函数对指定的序列做出映射
print(count_ways(a,b,c))函数的递归逻辑如下:
-
如果
n等于 0 并且s等于 0,则表示已经成功选择了n个整数使它们的和等于s,此时返回 1,表示找到一种方法。 -
如果
m等于 0 或n等于 0,则不可能再选择整数,因此返回 0,表示没有方法
return count_ways(m-1,n-1,s-m) + count_ways(m-1,n,s)讲解:
在一般情况下,函数会递归调用自身两次:
- 一次是选择当前整数
m,然后递归计算在剩余的整数范围内选择n-1个整数使它们的和为s-m。- 另一次是不选择当前整数
m,然后递归计算在剩余的整数范围内选择n个整数使它们的和为s。
函数会返回这两种情况的方法数量之和,因为这代表了所有可能的方法。
这个递归函数通过不断减小整数范围 m 和 n 的值,同时调整目标和 s,来计算所有可能的方法数。在达到基本情况之后,递归函数开始回溯,计算所有可能的方法数,最终返回总的方法数量。
9.石头剪刀布
描述
石头剪刀布是常见的猜拳游戏。石头胜剪刀,剪刀胜布,布胜石头。如果两个人出拳一样,则不分胜负。
一天,小A和小B正好在玩石头剪刀布。已知他们的出拳都是有周期性规律的,比如:“石头-布-石头-剪刀-石头-布-石头-剪刀……”,就是以“石头-布-石头-剪刀”为周期不断循环的。请问,小A和小B比了N轮之后,谁赢的轮数多?
输入
输入包含三行。
第一行包含三个整数:N,NA,NB,分别表示比了N轮,小A出拳的周期长度,小B出拳的周期长度。0 < N,NA,NB < 100。
第二行包含NA个整数,表示小A出拳的规律。
第三行包含NB个整数,表示小B出拳的规律。
其中,0表示“石头”,2表示“剪刀”,5表示“布”。相邻两个整数之间用单个空格隔开。
输出
输出一行,如果小A赢的轮数多,输出A;如果小B赢的轮数多,输出B;如果两人打平,输出draw。
样例输入
10 3 4 0 2 5 0 5 0 2
样例输出
A
提示
对于测试数据,猜拳过程为:
A:0 2 5 0 2 5 0 2 5 0
B:0 5 0 2 0 5 0 2 0 5
A赢了4轮,B赢了2轮,双方打平4轮,所以A赢的轮数多。
代码:
# !!!!!32、石头剪刀布
# 0表示“石头”,2表示“剪刀”,5表示“布”
def result(a,b):
if a == b:
return 0
if a == 5 and b == 0:
return 1
if a == 0 and b == 5:
return -1
if a < b:
return 1
else:
return -1
# n, na, nb--分别表示比了n轮,小A出拳的周期长度,小B出拳的周期长度
n, na, nb = map(int,input().split())
a = input().split() # 小A出拳的规律,包含na个整数
b = input().split() # # 小B出拳的规律,包含nb个整数
a_count = b_count = 0 # 赢的次数
pa = pb = 0 # 用来遍历周期长度
for i in range(n):
r = result(int(a[pa]),int(b[pb]))
if r == 1:
a_count += 1
elif r == -1:
b_count += 1
pa = (pa + 1) % na
pb = (pb + 1) % nb
if a_count > b_count:
print("A wins!")
elif a_count < b_count:
print("B wins!")
else:
print("draw")
10.统计数字字符个数
描述
输入一行字符,统计出其中数字字符的个数。
输入
一行字符串,总长度不超过255。
输出
输出为1行,输出字符串里面数字字符的个数。
样例输入
Peking University is set up at 1898.
样例输出
4
代码:(两种方法)
# 33、统计数字字符个数 方法一
s = input()
count = 0
for i in s:
if '0' <= i <= '9':
count += 1
print(count)# 33、统计数字字符个数 方法二
s = input()
sum = 0
for i in s:
if i.isdigit(): # isdigit()函数判断是否为数字字符
sum += 1
print(sum)isdigit()函数:
1.语法:
str.isdigit()
2.参数:该方法不接受任何参数。
3.返回值:
- 如果字符串中所有字符都是数字字符,则返回True。
- 如果字符串中至少有一个非数字字符(包括空格、标点符号等),则返回False
11.大小写字母互换
描述
把一个字符串中所有出现的大写字母都替换成小写字母,同时把小写字母替换成大写字母。
输入
输入一行:待互换的字符串。
输出
输出一行:完成互换的字符串(字符串长度小于80)。
样例输入
She hasn't started writing it.
样例输出
sHE HASN'T STARTED WRITING IT.
代码展示
# 34、大小写字母互换
s = input()
for c in s:
if 'a' <= c <= 'z':
print(chr(ord(c) - 32 ),end="")
elif 'A' <= c <= 'Z':
print(chr(ord(c) + 32),end="")
else:
print(c,end="")
Python内置函数——chr()函数和ord()函数
chr()函数用于获取给定整数(0~255)对应的 ASCll字符。ord()函数用于获取给定字符的ASCll数值print(chr(65)) # Output: 'A' print(ord('A')) # Output: 65
11.找第一个只出现一次的字符
描述
给定一个只包含小写字母的字符串,请你找到第一个仅出现一次的字符。如果没有,输出no。
输入
一个字符串,长度小于100000。
输出
输出第一个仅出现一次的字符,若没有则输出no。
输入样例
abcabd
输出样例
c
代码
def find_first_unique_character(s):
char_count = {}
# 统计每个字符出现的次数
for char in s:
char_count[char] = char_count.get(char, 0) + 1
# 找到第一个仅出现一次的字符
for char in s:
if char_count[char] == 1:
return char
return 'no' # 如果没有仅出现一次的字符,则返回'no'
# 主程序
if __name__ == '__main__':
input_str = input().strip() # 获取用户输入的字符串
result = find_first_unique_character(input_str)
print(result)
字典 get()方法
语法:dict.get(key[, value])
参数
- key -- 字典中要查找的键。
- value -- 可选,如果指定键的值不存在时,返回该默认值
例:
tinydict = {'Name': 'Kim', 'Age': 27}
print ("Age : %s" % tinydict.get('Age'))
# 没有设置 Sex,也没有设置默认的值,输出 None
print ("Sex : %s" % tinydict.get('Sex'))
# 没有设置 Salary,输出默认的值 0.0
print ('Salary: %s' % tinydict.get('Salary', 0.0))Age : 27
Sex : None
Salary: 0.0
strip()函数
strip()是一个字符串方法,用于去除字符串两端的空白字符(包括空格、制表符和换行符)。它返回一个新的字符串,该字符串是原始字符串去除两端空白字符后的结果。注意,原始字符串text本身不会被修改,而是返回了一个新的字符串。
text = " Hello, World! "
new_text = text.strip()
print(new_text) # 输出: "Hello, World!"
此外,strip()方法还可以接受一个参数,用于指定要删除的字符集合。例如,可以使用strip('!')来删除字符串两端的感叹号:
text = "!!Hello, World!!!"
new_text = text.strip('!')
print(new_text) # 输出: "Hello, World"
12.判断字符串是否为回文
描述
输入一个字符串,输出该字符串是否回文。回文是指顺读和倒读都一样的字符串。
输入
输入为一行字符串(字符串中没有空白字符,字符串长度不超过100)。
输出
如果字符串是回文,输出yes;否则,输出no。
实例输入
abcdedcba
实例输出
yes
代码:
# 37、!!!判断字符串是否为回文
s = input()
def huiwen():
i = 0
j = len(s) - 1
while i < j:
if s[i] != s[j]:
return "no"
i += 1
j -= 1
return "yes"
if __name__ == '__main__':
result = huiwen()
print(result)a = input()
if a == a[::-1]:
print('yes')
else:
print('no')13.38、字符串最大跨距
描述
有三个字符串S,S1,S2,其中,S长度不超过300,S1和S2的长度不超过10。想检测S1和S2是否同时在S中出现,且S1位于S2的左边,并在S中互不交叉(即,S1的右边界点在S2的左边界点的左侧)。计算满足上述条件的最大跨距(即,最大间隔距离:最右边的S2的起始点与最左边的S1的终止点之间的字符数目)。如果没有满足条件的S1,S2存在,则输出-1。
例如,S = "abcd123ab888efghij45ef67kl", S1="ab", S2="ef",其中,S1在S中出现了2次,S2也在S中出现了2次,最大跨距为:18。
输入
三个串:S, S1, S2,其间以逗号间隔(注意,S, S1, S2中均不含逗号和空格);
输出
S1和S2在S最大跨距;若在S中没有满足条件的S1和S2,则输出-1。
样例输入
abcd123ab888efghij45ef67kl,ab,ef
样例输出
18
代码
# 38、字符串最大跨距
n = input().split(',')
s, s1, s2 = n[0], n[1], n[2]
if s1 in s and s2 in s:
x = s.find(s1) # 在字符串a中查找子字符串b的第一个出现位置,并将结果赋值给变量x
y = s.rfind(s2) # 在字符串a中查找子字符串c的最后一个出现位置,并将结果赋值给变量y
if x >= y:
print('-1')
else:
print(y-x-len(s2))
else:
print('-1')find()和rfind()函数是Python中用于查找子字符串在字符串中位置的方法。它们的具体功能如下:
find()函数
find()函数用于在字符串中查找子字符串第一次出现的位置。如果找到子字符串,则返回子字符串的起始索引;如果没有找到,则返回-1。
str.find(sub[, start[, end]])
sub:要搜索的子字符串。start(可选):搜索的起始位置,默认为0。end(可选):搜索的结束位置,默认为字符串的长度。
示例:
s = "Hello, world"
print(s.find("o")) # 输出:4
print(s.find("x")) # 输出:-1
rfind()函数
rfind()函数与find()类似,不同之处在于它从右向左查找子字符串最后一次出现的位置。如果找到子字符串,则返回子字符串的起始索引;如果没有找到,则返回-1。
str.rfind(sub[, start[, end]])
sub:要搜索的子字符串。start(可选):搜索的起始位置,默认为0。end(可选):搜索的结束位置,默认为字符串的长度。
示例:
s = "Hello, world"
print(s.rfind("o")) # 输出:8
print(s.rfind("x")) # 输出:-1
总结:
find()和rfind()函数都是用来查找子字符串在字符串中的位置。find()从左向右查找子字符串第一次出现的位置。rfind()从右向左查找子字符串最后一次出现的位置。- 如果找到子字符串,这两个方法返回子字符串在原始字符串中的索引;如果没有找到,则返回-1。
14 39、找出全部子串位置
描述
输入两个串s1,s2,找出s2在s1中所有出现的位置
两个子串的出现不能重叠。例如'aa'在 aaaa 里出现的位置只有0,2
输入
第一行是整数n
接下来有n行,每行两个不带空格的字符串s1,s2
输出
对每行,从小到大输出s2在s1中所有的出现位置。位置从0开始算
如果s2没出现过,输出 "no"
行末多输出空格没关系
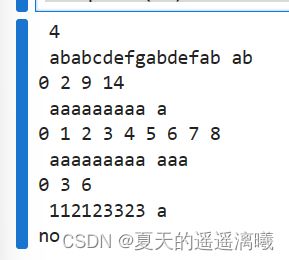
样例输入
4 ababcdefgabdefab ab aaaaaaaaa a aaaaaaaaa aaa 112123323 a
样例输出:
0 2 9 14 0 1 2 3 4 5 6 7 8 0 3 6 no
代码:
# 39、找出全部子串位置
num = int(input())
for i in range(num):
s = input().split()
m = 0
if s[1] not in s[0]:
print('no',end='')
for j in s[0]:
a = s[0].find(s[1],m)
if a == -1:
continue
else:
m = a + len(s[1])
print(a,'',end='')
print("") #每次循环换行运行结果:
15 40、万年历
描述
给定年月日,求星期几。已知2020年11月18日是星期三。另外,本题有公元0年,这个和真实的纪年不一样
输入
第一行是n(n <=30),表示有n组数据
接下来n行,每行是一组数据。
每行三个整数y,m,d,分别代表年,月,日。(-1000000<=y<=1000000)
若今年是2017年,则往前就是2016年,2015年....一直数到2年,1年,再往前就是0年,-1年,-2年.....
输出
对每组数据,输出星期几,星期几分别用
"Sunday","Monday","Tuesday","Wednesday","Thursday", "Friday","Saturday" 表示
如果月份和日期不合法,输出"Illegal"
样例输入
6 2017 2 29 2017 13 2 0 1 1 -2 3 4 2017 10 18 2015 12 31
样例输出
Illegal Illegal Saturday Wednesday Wednesday Thurs
代码:
# 40、万年历
# 判断是否为闰年
def is_leap_year(year):
if (year % 4 == 0) and (year % 100 != 0) or (year % 400 == 0):
return True
else:
return False
def judge_week(year, month, day):
days = date = 0
lst1 = [31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] # 闰年每月天数列表
lst2 = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] # 平年每月天数列表
lst_days = ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"]
is_leap = is_leap_year(year) # 判断是否为闰年
# 判断month是哪月
if month in [1, 3, 5, 7, 8, 10, 12]: # 月份有31天
if day < 1 or day > 31:
print('Illegal')
return
elif month == 2: # 2月份
# 公历年份能够被4整除但不能被100整除的年份是闰年,或者能够被400整除的年份也是闰年
if is_leap:
if day < 1 or day > 29: # 闰年2月份有29天
print('Illegal')
return
else:
if day < 1 or day > 28: # 闰年2月份有28天
print('Illegal')
return
elif month in [4, 6, 9, 11]:
if day < 1 or day > 30:
print('Illegal')
return
else:
print('Illegal')
return
if year >= 1: #1年1月1日为星期一
#累加整年数
for i in range(1,year):
if i % 4 == 0 and i % 100 != 0 or i % 400 == 0:
days+=366
else:
days+=365
#累加整月数
if is_leap:
for i in range(month-1,12):
date += lst1[i] # 闰年每月天数
else:
for i in range(month-1,12):
date += lst2[i] # 平年每月天数
total = date + day + days
x=total % 7
print(lst_days[x])
else:
for i in range(year+1, 1):
if (i % 4 == 0) and (i % 100 != 0) or i % 400 == 0:
days += 366
else:
days += 365 # 累加整年数
if is_leap:
for i in range(month - 1,12):
date += lst1[i]
else:
for i in range(month - 1,12):
date += lst2[i] # 累加整月数
total = date - day + 1 + days
x = total % 7
print(lst_days[(8-x)%7])
n = int(input())
for i in range(n):
y, m, d = map(int,input().split())
judge_week(y, m, d)
计算实际年月份的对应日期 代码:
import datetime
def judge_week(year, month, day):
try:
input_date = datetime.date(year, month, day)
week_day = input_date.strftime("%A")
print(week_day)
except ValueError:
print('Illegal')
n = int(input("请输入要查询的日期数量:"))
for i in range(n):
y, m, d = map(int, input("请输入年月日,空格分隔:").split())
judge_week(y, m, d)通过Python内置的datetime模块,调用其中的date类和strftime方法。date类用于表示日期,接收三个参数:年、月、日。strftime方法用于将日期格式化为字符串,其中"%A"表示输出星期几的全称(比如Monday、Tuesday等)
函数judge_week中,首先通过datetime.date创建一个日期对象input_date,然后使用input_date.strftime方法将星期几格式化成字符串。如果输入的年月日不合法,则捕获ValueError异常并打印"Illegal"。
16 41、病人排队
描述
病人登记看病,编写一个程序,将登记的病人按照以下原则排出看病的先后顺序:
1. 老年人(年龄 >= 60岁)比非老年人优先看病。
2. 老年人按年龄从大到小的顺序看病,年龄相同的按登记的先后顺序排序。
3. 非老年人按登记的先后顺序看病。
输入
第1行,输入一个小于100的正整数,表示病人的个数;
后面按照病人登记的先后顺序,每行输入一个病人的信息,包括:一个长度小于10的字符串表示病人的ID(每个病人的ID各不相同且只含数字和字母),一个整数表示病人的年龄,中间用单个空格隔开。
输出
按排好的看病顺序输出病人的ID,每行一个。
样例输入
5 021075 40 004003 15 010158 67 021033 75 102012 30
样例输出
021033 010158 021075 004003 102012
代码:
# 41、病人排队
num = int(input())
lst = []
for i in range(num):
s = input().split()
lst1 = [str(s[0]),int(s[1]),i] #添加登记顺序
lst.append(lst1)
def f(x):
if x[1] >= 60: # 病人的年龄大于等于60岁,则返回一个元组 (-x[1], x[2]
return(-x[1],x[2]) # x[1] 是年龄的相反数,x[2] 是病人的登记顺序(索引 i)
else:
return(0,x[2])
lst.sort(key=f) # #key为自定义比较函数,按函数f的方式比较
# 根据年龄从大到小的顺序和病人的登记顺序
for i in range(num):
print(lst[i][0]) # 使用循环遍历排好序的列表 a,并打印每个病人的ID(a[i][0])class Patient:
def __init__(self, id, age):
self.id = id
self.age = age
n = int(input("请输入病人的个数:"))
patients = []
for _ in range(n):
patient_info = input("请输入病人的信息(ID 年龄):").split()
id, age = patient_info[0], int(patient_info[1])
patients.append(Patient(id, age))
# 老年人优先,按年龄从大到小,年龄相同按登记顺序
old_patients = [patient for patient in patients if patient.age >= 60]
old_patients.sort(key=lambda x: (-x.age, patients.index(x))) # 从大到小
other_patients = [patient for patient in patients if patient not in old_patients]
sorted_patients = old_patients + other_patients
for patient in sorted_patients:
print(patient.id)
### 定义Patient类
class Patient:
def __init__(self, id, age):
self.id = id
self.age = age
这里定义了一个Patient类表示病人。该类有两个属性:id表示病人的ID,age表示病人的年龄。__init__方法是类的构造函数,用于创建Patient对象时初始化属性。### 输入病人信息
n = int(input("请输入病人的个数:"))
patients = []
for _ in range(n):
patient_info = input("请输入病人的信息(ID
年龄):").split()
id, age = patient_info[0], int(patient_info[1])
patients.append(Patient(id, age))
首先通过input函数获取病人个数n,然后使用for循环逐个输入病人信息,并将每个病人的id和age分别存储在变量id和age中。由于age是从输入中获取的字符串类型,需要使用int函数将其转换为整型。最后通过Patient类创建病人对象,并将其添加到列表patients中。### 按规则排序
old_patients = [patient for patient in patients if patient.age >= 60]
old_patients.sort(key=lambda x: (-x.age, patients.index(x)))
other_patients = [patient for patient in patients if patient not in old_patients]sorted_patients = old_patients + other_patients
先使用列表推导式将老年病人和非老年病人分别提取出来,old_patients存储老年病人,other_patients存储非老年病人。对于老年病人,按照题目描述的规则进行排序,首先按照年龄从大到小排序,年龄相同的按照登记顺序排序。这里使用sort方法,其中key参数是一个函数,用于指定排序规则。这里使用了一个lambda函数表示按照年龄和登记顺序排序。具体实现是将年龄取相反数,这样年龄大的排在前面;如果年龄相同,则按照原始列表中的顺序排列。对于非老年病人,不需要排序,直接按照登记顺序排列。最后将排序好的老年病人和非老年病人合并成一个列表,即为排好序的病人列表sorted_patients。
### 输出排队顺序
for patient in sorted_patients:
print(patient.id)
使用for循环逐个输出病人ID,完成排队顺序的输出。
17 42、校园食宿预订系统
描述
某校园为方便学生订餐,推出食堂预定系统。食宿平台会在前一天提供菜单,学生在开饭时间前可订餐。 食堂每天会推出m个菜,每个菜有固定的菜价和总份数,售卖份数不能超过总份数。 假设共有n个学生点餐,每个学生固定点3个菜,当点的菜售罄时, 学生就买不到这个菜了。 请根据学生预定记录,给出食堂总的预定收入 数据满足1 <= n <= 6000,3 <= m <= 6000,单品菜价不大于1000元,每个菜的配额不超过3000
输入
第一行两个整数n和m,代表有n个学生订餐,共有m个可选的菜
下面m行,每行三个元素,分别是菜名、售价和可提供量,保证菜名不重合,菜价为整数
下面n行,每行三个元素,表示这个学生点的三个菜的菜名
输出
一个整数,表示食堂的收入
样例输入
5 5 yangroupaomo 13 10 jituifan 7 5 luosifen 16 3 xinlamian 12 20 juruo_milktea 999 1 yangroupaomo luosifen juruo_milktea luosifen xinlamian jituifan yangroupaomo jituifan juruo_milktea jituifan xinlamian luosifen yangroupaomo yangroupaomo yangroupaomo
样例输出
1157
提示
如果用python做,要用字典,
如果用其它语言做,也要用类似的数据结构
否则会超时
名字长度范围没有给出,长度不会太离谱。请自己选用合适的办法确保这不是个问题
代码
n, m = map(int,input().split())
t={}
for i in range(m):
s = input().split()
name, price, num =s[0], int(s[1]), int(s[2])
t[name]=[price,num]
total = 0
for i in range(n):
names = input().split()
for name in names:
if t[name][1]>0: # 即num>0
total += t[name][0]
t[name][1] -= 1
print(total)