使用Pytorch从零开始构建GRU
门控循环单元 (GRU) 是 LSTM 的更新版本。让我们揭开这个网络的面纱并探索这两个兄弟姐妹之间的差异。
您听说过 GRU 吗?门控循环单元(GRU)是更流行的长短期记忆(LSTM)网络的弟弟,也是循环神经网络(RNN)的一种。就像它的兄弟一样,GRU 能够有效地保留顺序数据中的长期依赖性。此外,它们还可以解决困扰普通 RNN 的“短期记忆”问题。
考虑到序列建模和预测中循环架构的遗留问题,GRU 有望因其卓越的速度而超越其前辈,同时实现相似的准确性和有效性。
在本文中,我们将介绍 GRU 背后的概念,并将 GRU 与 LSTM 的机制进行比较。我们还将探讨这两种 RNN 变体的性能差异。如果您不熟悉 RNN 或 LSTM,您可以查看我之前介绍这些主题的文章:
- 使用Pytorch从零开始构建RNN
- 使用Pytorch从零开始构建LSTM
什么是 GRU?
门控循环单元(GRU),顾名思义,是RNN 架构的一种变体,它使用门控机制来控制和管理神经网络中单元之间的信息流。Cho 等人于 2014 年才引入 GRU 。可以被认为是一种相对较新的架构,特别是与Sepp Hochreiter 和 Jürgen Schmidhuber于 1997 年提出的广泛采用的 LSTM 相比。
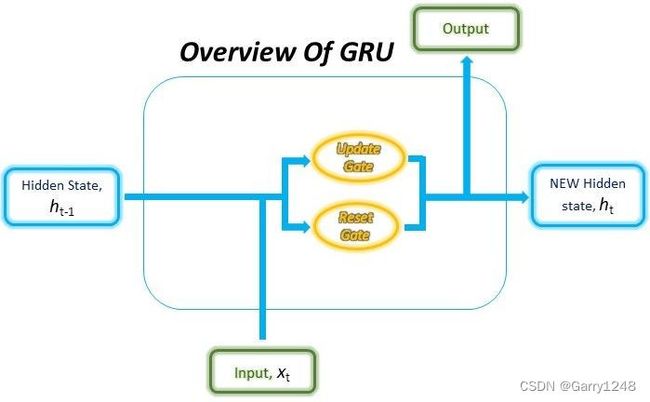
GRU 的结构使其能够自适应地捕获大型数据序列的依赖性,而不会丢弃序列早期部分的信息。这是通过其门控单元实现的,类似于 LSTM 中的门控单元,它解决了传统 RNN 的梯度消失/爆炸问题。这些门负责调节每个时间步要保留或丢弃的信息。我们将在本文后面深入探讨这些门的工作原理以及它们如何克服上述问题的细节。

除了其内部门控机制之外,GRU 的功能就像 RNN 一样,其中顺序输入数据由 GRU 单元在每个时间步与内存一起消耗,或者称为隐藏状态。然后,隐藏状态与序列中的下一个输入数据一起重新输入到 RNN 单元中。这个过程像继电器系统一样持续进行,产生所需的输出。
GRU 的内部运作
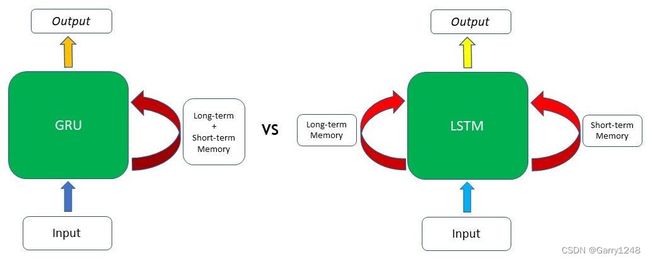
GRU 保持长期依赖性或记忆的能力源于 GRU 单元内产生隐藏状态的计算。虽然LSTM在单元之间传递两种不同的状态——单元状态和隐藏状态,分别承载长期和短期记忆,但 GRU 在时间步之间仅传递一种隐藏状态。由于隐藏状态和输入数据所经历的门控机制和计算,该隐藏状态能够同时保持长期和短期依赖性。
GRU 单元仅包含两个门:更新门和重置门。就像 LSTM 中的门一样,GRU 中的这些门经过训练可以有选择地过滤掉任何不相关的信息,同时保留有用的信息。这些门本质上是包含0到1之间的值的向量,这些值将与输入数据和/或隐藏状态相乘。门向量中的0值表示输入或隐藏状态中的相应数据不重要,因此将返回零。另一方面,门向量中的值1意味着相应的数据很重要并将被使用。
在本文的其余部分中,我将交替使用术语“门”和“向量” ,因为它们指的是同一事物。
GRU单元的结构如下所示。

虽然由于存在大量连接,该结构可能看起来相当复杂,但其背后的机制可以分为三个主要步骤。
重置门
第一步,我们将创建重置门。该门是使用前一时间步的隐藏状态和当前时间步的输入数据导出和计算的。
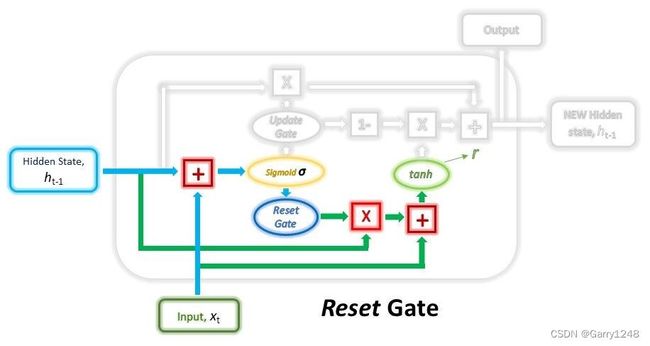
从数学上讲,这是通过将先前的隐藏状态和当前输入与其各自的权重相乘并在将总和传递给sigmoid函数之前将它们相加来实现的。sigmoid函数会将值转换为介于0和1之间,从而允许门在后续步骤中在不太重要和更重要的信息之间进行过滤。
g a t e r e s e t = σ ( W i n p u t r e s e t ⋅ x t + W h i d d e n r e s e t ⋅ h t − 1 ) gate_{reset} = \sigma(W_{input_{reset}} \cdot x_t + W_{hidden_{reset}} \cdot h_{t-1}) gatereset=σ(Winputreset⋅xt+Whiddenreset⋅ht−1)
当整个网络通过反向传播进行训练时,方程中的权重将被更新,使得向量将学会仅保留有用的特征。
先前的隐藏状态将首先乘以可训练权重,然后与重置向量进行逐元素乘法(哈达玛乘积) 。 此操作将决定将先前时间步骤中的哪些信息与新输入一起保留。同时,当前输入还将乘以可训练权重,然后与上面的重置向量和先前隐藏状态的乘积相加。最后,将非线性激活tanh函数应用于最终结果,以获得下面等式中的r 。
r = t a n h ( g a t e r e s e t ⊙ ( W h 1 ⋅ h t − 1 ) + W x 1 ⋅ x t ) r = tanh(gate_{reset} \odot (W_{h_1} \cdot h_{t-1}) + W_{x_1} \cdot x_t) r=tanh(gatereset⊙(Wh1⋅ht−1)+Wx1⋅xt)
更新门
接下来,我们必须创建更新门。就像重置门一样,门是使用先前的隐藏状态和当前输入数据来计算的。

更新和重置门向量都是使用相同的公式创建的,但是,与输入和隐藏状态相乘的权重对于每个门来说是唯一的,这意味着每个门的最终向量是不同的。这使得大门能够满足其特定目的。
g a t e u p d a t e = σ ( W i n p u t u p d a t e ⋅ x t + W h i d d e n u p d a t e ⋅ h t − 1 ) gate_{update} = \sigma(W_{input_{update}} \cdot x_t + W_{hidden_{update}} \cdot h_{t-1}) gateupdate=σ(Winputupdate⋅xt+Whiddenupdate⋅ht−1)
然后,更新向量将与之前的隐藏状态进行逐元素相乘,以获得下面等式中的u ,该值将用于稍后计算我们的最终输出。
u = g a t e u p d a t e ⊙ h t − 1 u = gate_{update} \odot h_{t-1} u=gateupdate⊙ht−1
稍后在获得最终输出时,更新向量还将用于另一个操作。这里更新门的目的是帮助模型确定存储在先前隐藏状态中的过去信息有多少需要保留以供将来使用。
组合输出
在最后一步中,我们将重用更新门并获取更新的隐藏状态。
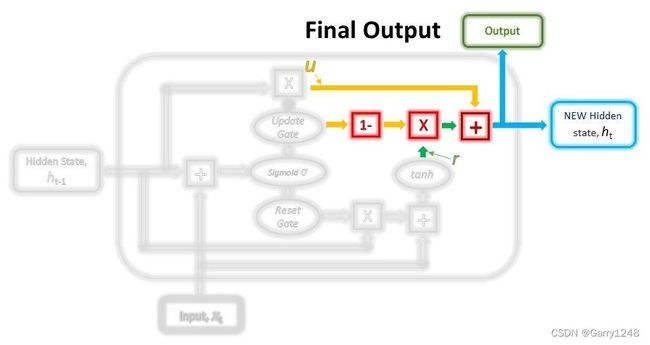
这次,我们将采用同一更新向量(1 -更新 门)的逐元素逆版本,并与重置门的输出r进行逐元素乘法。此操作的目的是让更新门确定新信息的哪一部分应存储在隐藏状态中。
最后,上述操作的结果将与上一步更新门的输出u相加。这将为我们提供新的和更新的隐藏状态。
h t = r ⊙ ( 1 − g a t e u p d a t e ) + u h_t = r \odot (1-gate_{update}) + u ht=r⊙(1−gateupdate)+u
我们也可以通过将这个新的隐藏状态传递给线性激活层来将其用作该时间步的输出。
解决梯度消失/爆炸问题
我们已经看到了大门的运作。我们知道它们如何转换我们的数据。现在让我们回顾一下它们在管理网络内存方面的整体作用,并讨论它们如何解决梯度消失/爆炸问题。
正如我们在上面的机制中所看到的,重置门负责决定将先前隐藏状态的哪些部分与当前输入组合以提出新的隐藏状态。
更新门负责确定要保留多少先前的隐藏状态,以及将新提出的隐藏状态(源自重置门)的哪一部分添加到最终隐藏状态。当更新门首先与先前的隐藏状态相乘时,网络会选择将先前隐藏状态的哪些部分保留在内存中,同时丢弃其余部分。随后,当它使用更新门的逆来从重置门过滤提议的新隐藏状态时,它会修补信息的缺失部分。
这使得网络能够保留长期的依赖关系。如果更新向量值接近 1,则更新门可以选择保留隐藏状态中的大部分先前记忆,而无需重新计算或更改整个隐藏状态。
在训练 RNN 时,反向传播过程中会出现梯度消失/爆炸问题,特别是当 RNN 处理长序列或具有多层时。训练期间计算的误差梯度用于以正确的方向和正确的幅度更新网络的权重。然而,这个梯度是用链式法则从网络末端开始计算的。因此,在反向传播过程中,梯度将连续进行矩阵乘法,并且对于长序列,梯度会呈指数收缩(消失)或爆炸(爆炸) 。梯度太小意味着模型无法有效更新其权重,而梯度太大会导致模型不稳定。
由于更新门的附加组件,LSTM 和 GRU 中的门有助于解决这个问题。传统 RNN 总是在每个时间步替换隐藏状态的全部内容,而 LSTM 和 GRU 保留大部分现有隐藏状态,同时在其上添加新内容。这允许误差梯度反向传播,而不会由于加法运算而消失或爆炸太快。
虽然 LSTM 和 GRU 是解决上述问题最广泛使用的方法,但梯度爆炸问题的另一种解决方案是梯度裁剪。Clipping 在梯度上设置了一个定义的阈值,这意味着即使在训练过程中梯度增加超过预定义值,其值仍然会被限制在设定的阈值内。这样,梯度的方向不受影响,仅梯度的大小发生变化。

GRU 与 LSTM
我们已经掌握了 GRU 的机制。但它与它的老兄弟(也更流行)的 LSTM 相比如何呢?
两者都是为了解决标准 RNN 面临的梯度消失/爆炸问题而创建的,并且这两种 RNN 变体都利用门控机制来控制网络内长期和短期依赖关系的流动。
但它们有什么不同呢?
-
结构性差异
虽然 GRU 和 LSTM 都包含门,但这两种结构之间的主要区别在于门的数量及其具体作用。GRU 中的更新门的作用与LSTM 中的输入门和遗忘门非常相似。然而,这两者对添加到网络的新内存内容的控制有所不同。
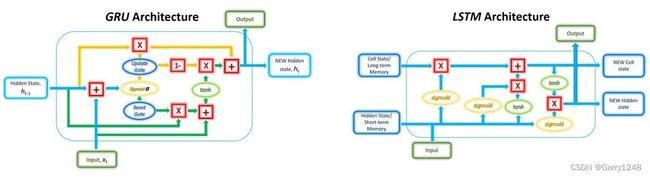
在 LSTM 中,遗忘门决定保留先前单元状态的哪一部分,而输入门则决定要添加的新内存量。这两个门是相互独立的,这意味着通过输入门 添加的新信息量完全独立于通过遗忘门保留的信息量。
对于GRU来说,更新门负责决定保留之前内存中的哪些信息,并 负责控制新内存的添加。这意味着 GRU 中先前内存的保留和向内存中添加新信息不是独立的。
如前所述,这些结构之间的另一个主要区别是 GRU 中缺少单元状态。LSTM 将其长期依赖关系存储在单元状态中,并将短期记忆存储在隐藏状态中,而 GRU 将两者存储在单个隐藏状态中。然而,就保留长期信息的有效性而言,两种架构都已被证明可以有效地实现这一目标。 -
速度差异
与 LSTM 相比,GRU 的训练速度更快,因为训练期间需要更新的权重和参数数量较少。这可以归因于与 LSTM 的三个门相比,GRU 单元中的门数量较少(两个门)。
在本文后面的代码演练中,我们将直接比较在完全相同的任务上训练 LSTM 和 GRU 的速度。 -
性能评估
模型的准确性,无论是通过误差幅度还是正确分类的比例来衡量,通常是决定使用哪种类型的模型来完成任务时的主要因素。GRU 和 LSTM 都是 RNNs 的变体,可以互换插入以获得类似的结果。
项目:使用 GRU 和 LSTM 进行时间序列预测
我们已经了解了 GRU 背后的理论概念。现在是时候将所学知识付诸实践了。
我们将在代码中实现 GRU 模型。为了进一步进行 GRU-LSTM 比较,我们还将使用 LSTM 模型来完成相同的任务。我们将根据一些指标评估这两个模型的性能。我们将使用的数据集是每小时能源消耗数据集,可以在Kaggle上找到。该数据集包含按小时记录的美国不同地区的电力消耗数据,你可以访问 GitHub 代码库。
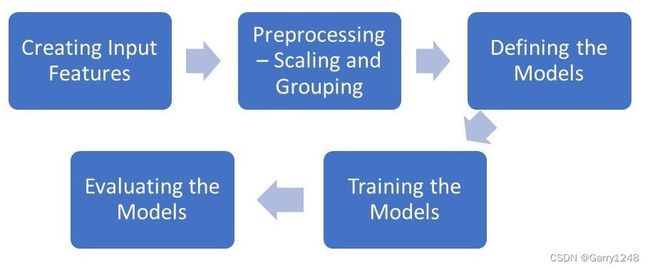
该项目的目标是创建一个模型,可以根据历史使用数据准确预测下一小时的能源使用情况。我们将使用 GRU 和 LSTM 模型来训练一组历史数据,并在未见过的测试集上评估这两个模型。为此,我们将从特征选择和数据预处理开始,然后定义、训练并最终评估模型。
这将是我们项目的流程。
我们将使用 PyTorch 库以及数据分析中使用的其他常见 Python 库来实现这两种类型的模型。
import os
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from tqdm import tqdm_notebook
from sklearn.preprocessing import MinMaxScaler
# Define data root directory
data_dir = "./data/"
# Visualise how our data looks
pd.read_csv(data_dir + 'AEP_hourly.csv').head()
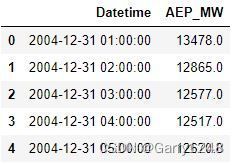
我们总共有12 个 .csv文件,其中包含上述格式的每小时能源趋势数据(未使用“est_hourly.paruqet”和“pjm_hourly_est.csv” )。在下一步中,我们将按以下顺序读取这些文件并预处理这些数据:
- 获取每个单独时间步的时间数据并对它们进行概括
- 一天中的某个小时,即 0 - 23
- 一周中的某一天,即。1 - 7
- 月份,即 1 - 12
- 一年中的某一天,即 1 - 365
- 将数据缩放到 0 到 1 之间的值
- 当特征具有相对相似的规模和/或接近正态分布时,算法往往会表现更好或收敛得更快
- 缩放保留了原始分布的形状并且不会降低异常值的重要性
- 将数据分组为序列,用作模型的输入并存储其相应的标签
- 序列长度或回顾周期是模型用于进行预测的历史数据点的数量
- 标签将是输入序列中最后一个数据点之后的下一个数据点
- 将输入和标签拆分为训练集和测试集
# The scaler objects will be stored in this dictionary so that our output test data from the model can be re-scaled during evaluation
label_scalers = {}
train_x = []
test_x = {}
test_y = {}
for file in tqdm_notebook(os.listdir(data_dir)):
# Skipping the files we're not using
if file[-4:] != ".csv" or file == "pjm_hourly_est.csv":
continue
# Store csv file in a Pandas DataFrame
df = pd.read_csv('{}/{}'.format(data_dir, file), parse_dates=[0])
# Processing the time data into suitable input formats
df['hour'] = df.apply(lambda x: x['Datetime'].hour,axis=1)
df['dayofweek'] = df.apply(lambda x: x['Datetime'].dayofweek,axis=1)
df['month'] = df.apply(lambda x: x['Datetime'].month,axis=1)
df['dayofyear'] = df.apply(lambda x: x['Datetime'].dayofyear,axis=1)
df = df.sort_values("Datetime").drop("Datetime",axis=1)
# Scaling the input data
sc = MinMaxScaler()
label_sc = MinMaxScaler()
data = sc.fit_transform(df.values)
# Obtaining the Scale for the labels(usage data) so that output can be re-scaled to actual value during evaluation
label_sc.fit(df.iloc[:,0].values.reshape(-1,1))
label_scalers[file] = label_sc
# Define lookback period and split inputs/labels
lookback = 90
inputs = np.zeros((len(data)-lookback,lookback,df.shape[1]))
labels = np.zeros(len(data)-lookback)
for i in range(lookback, len(data)):
inputs[i-lookback] = data[i-lookback:i]
labels[i-lookback] = data[i,0]
inputs = inputs.reshape(-1,lookback,df.shape[1])
labels = labels.reshape(-1,1)
# Split data into train/test portions and combining all data from different files into a single array
test_portion = int(0.1*len(inputs))
if len(train_x) == 0:
train_x = inputs[:-test_portion]
train_y = labels[:-test_portion]
else:
train_x = np.concatenate((train_x,inputs[:-test_portion]))
train_y = np.concatenate((train_y,labels[:-test_portion]))
test_x[file] = (inputs[-test_portion:])
test_y[file] = (labels[-test_portion:])
我们总共有 980,185 个训练数据序列。
为了提高训练速度,我们可以批量处理数据,这样模型就不需要频繁更新权重。Torch Dataset和DataLoader类对于将数据拆分为批次并对其进行混洗非常有用。
batch_size = 1024
train_data = TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_y))
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size, drop_last=True)
我们还可以检查是否有 GPU 来加快训练时间。如果您使用带有 GPU 的 FloydHub 来运行此代码,训练时间将显着减少。
# torch.cuda.is_available() checks and returns a Boolean True if a GPU is available, else it'll return False
is_cuda = torch.cuda.is_available()
# If we have a GPU available, we'll set our device to GPU. We'll use this device variable later in our code.
if is_cuda:
device = torch.device("cuda")
else:
device = torch.device("cpu")
接下来,我们将定义 GRU 和 LSTM 模型的结构。两种模型具有相同的结构,唯一的区别是循环层(GRU/LSTM)和隐藏状态的初始化。LSTM 的隐藏状态是包含单元状态和隐藏状态 的元组,而 GRU 仅具有单个隐藏状态。
class GRUNet(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, n_layers, drop_prob=0.2):
super(GRUNet, self).__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.gru = nn.GRU(input_dim, hidden_dim, n_layers, batch_first=True, dropout=drop_prob)
self.fc = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x, h):
out, h = self.gru(x, h)
out = self.fc(self.relu(out[:,-1]))
return out, h
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device)
return hidden
class LSTMNet(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, n_layers, drop_prob=0.2):
super(LSTMNet, self).__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, n_layers, batch_first=True, dropout=drop_prob)
self.fc = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x, h):
out, h = self.lstm(x, h)
out = self.fc(self.relu(out[:,-1]))
return out, h
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device))
return hidden
训练过程在下面的函数中定义,以便我们可以为两个模型重现它。两个模型在隐藏状态和层中将具有相同数量的维度,在相同数量的epoch和学习率上进行训练,并在完全相同的数据集上进行训练和测试。
为了比较两个模型的性能,我们将跟踪模型训练所需的时间,并最终比较两个模型在测试集上的最终准确性。对于我们的准确性测量,我们将使用对称平均绝对百分比误差(sMAPE)来评估模型。sMAPE是预测值和实际值之间的绝对差值除以预测值和实际值的平均值的总和,从而给出衡量误差量的百分比。这是sMAPE的公式:
$$
$$
def train(train_loader, learn_rate, hidden_dim=256, EPOCHS=5, model_type="GRU"):
# Setting common hyperparameters
input_dim = next(iter(train_loader))[0].shape[2]
output_dim = 1
n_layers = 2
# Instantiating the models
if model_type == "GRU":
model = GRUNet(input_dim, hidden_dim, output_dim, n_layers)
else:
model = LSTMNet(input_dim, hidden_dim, output_dim, n_layers)
model.to(device)
# Defining loss function and optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
model.train()
print("Starting Training of {} model".format(model_type))
epoch_times = []
# Start training loop
for epoch in range(1,EPOCHS+1):
start_time = time.clock()
h = model.init_hidden(batch_size)
avg_loss = 0.
counter = 0
for x, label in train_loader:
counter += 1
if model_type == "GRU":
h = h.data
else:
h = tuple([e.data for e in h])
model.zero_grad()
out, h = model(x.to(device).float(), h)
loss = criterion(out, label.to(device).float())
loss.backward()
optimizer.step()
avg_loss += loss.item()
if counter%200 == 0:
print("Epoch {}......Step: {}/{}....... Average Loss for Epoch: {}".format(epoch, counter, len(train_loader), avg_loss/counter))
current_time = time.clock()
print("Epoch {}/{} Done, Total Loss: {}".format(epoch, EPOCHS, avg_loss/len(train_loader)))
print("Total Time Elapsed: {} seconds".format(str(current_time-start_time)))
epoch_times.append(current_time-start_time)
print("Total Training Time: {} seconds".format(str(sum(epoch_times))))
return model
def evaluate(model, test_x, test_y, label_scalers):
model.eval()
outputs = []
targets = []
start_time = time.clock()
for i in test_x.keys():
inp = torch.from_numpy(np.array(test_x[i]))
labs = torch.from_numpy(np.array(test_y[i]))
h = model.init_hidden(inp.shape[0])
out, h = model(inp.to(device).float(), h)
outputs.append(label_scalers[i].inverse_transform(out.cpu().detach().numpy()).reshape(-1))
targets.append(label_scalers[i].inverse_transform(labs.numpy()).reshape(-1))
print("Evaluation Time: {}".format(str(time.clock()-start_time)))
sMAPE = 0
for i in range(len(outputs)):
sMAPE += np.mean(abs(outputs[i]-targets[i])/(targets[i]+outputs[i])/2)/len(outputs)
print("sMAPE: {}%".format(sMAPE*100))
return outputs, targets, sMAPE
lr = 0.001
gru_model = train(train_loader, lr, model_type="GRU")
Lstm_model = train(train_loader, lr, model_type="LSTM")
[Out]: Starting Training of GRU model
Epoch 1......Step: 200/957....... Average Loss for Epoch: 0.0070570480596506965
Epoch 1......Step: 400/957....... Average Loss for Epoch: 0.0039001358837413135
Epoch 1......Step: 600/957....... Average Loss for Epoch: 0.0027501484048358784
Epoch 1......Step: 800/957....... Average Loss for Epoch: 0.0021489552696584723
Epoch 1/5 Done, Total Loss: 0.0018450273993545988
Time Elapsed for Epoch: 78.02232400000003 seconds
.
.
.
Total Training Time: 390.52727700000037 seconds
Starting Training of LSTM model
Epoch 1......Step: 200/957....... Average Loss for Epoch: 0.013630141295143403
.
.
.
Total Training Time: 462.73371699999984 seconds
从两个模型的训练时间可以看出,我们的弟弟妹妹在速度方面绝对击败了哥哥。GRU 模型在这个维度上是明显的赢家;它比 LSTM 模型快 72 秒完成了 5 个训练周期。
继续测量两个模型的准确性,我们现在将使用评估()函数和测试数据集。
gru_outputs, targets, gru_sMAPE = evaluate(gru_model, test_x, test_y, label_scalers)
[Out]: Evaluation Time: 1.982479000000012
sMAPE: 0.28081167222194775%
lstm_outputs, targets, lstm_sMAPE = evaluate(lstm_model, test_x, test_y, label_scalers)
[Out]: Evaluation Time: 2.602886000000126
sMAPE: 0.27014616762377464%
有趣,对吧?虽然 LSTM 模型的误差可能较小,并且在性能准确度方面略微领先于 GRU 模型,但差异并不显着,因此尚无定论。
比较这两个模型的其他测试同样没有得出明显的胜利者,无法确定哪个是更好的整体架构。
最后,让我们对预测输出与实际消耗数据的随机集进行一些可视化。
plt.figure(figsize=(14,10))
plt.subplot(2,2,1)
plt.plot(gru_outputs[0][-100:], "-o", color="g", label="Predicted")
plt.plot(targets[0][-100:], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.subplot(2,2,2)
plt.plot(gru_outputs[8][-50:], "-o", color="g", label="Predicted")
plt.plot(targets[8][-50:], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.subplot(2,2,3)
plt.plot(gru_outputs[4][:50], "-o", color="g", label="Predicted")
plt.plot(targets[4][:50], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.subplot(2,2,4)
plt.plot(lstm_outputs[6][:100], "-o", color="g", label="Predicted")
plt.plot(targets[6][:100], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.show()

看起来这些模型在预测能源消耗趋势方面基本上是成功的。虽然他们可能仍然会犯一些错误,例如延迟预测消耗下降,但预测非常接近测试集上的实际线。这是由于能源消耗数据的性质以及模型可以解释的模式和周期性变化这一事实造成的。更困难的时间序列预测问题,例如股票价格预测或销量预测,可能具有很大程度上随机的数据或没有可预测的模式,在这种情况下,准确性肯定会较低。
超越 GRU
正如我在LSTM 文章中提到的,多年来,RNN 及其变体在各种 NLP 任务中已被取代,不再是NLP 标准架构。预训练的Transformer 模型(例如 Google 的 BERT、OpenAI 的 GPT和最近推出的 XLNet)已经产生了最先进的基准和结果,并将下游任务的迁移学习引入到 NLP。
至此,GRU 的所有事情就暂时结束了。这篇文章完成了我涵盖 RNN 基础知识的系列文章;未来,我们将探索更先进的概念,例如注意力机制、Transformers 和 NLP 中最先进的技术。
本博客译自 Gabriel Loye的博文。