【Python】两种方法计算平均值、中值、众数、方差、标准差、百分位数
目录
- 数据特征
-
- 数据集
- 均值(Mean) - 平均值
- 中值(Median) - 中点值,又称中位数
- 众数(Mode) - 最常见的值
- 方差
- 标准差(欧式距离)
- 百分位数
数据特征
特征探索主要是对数据进行预处理,发现和出炉缺失、异常数据,绘制直方图、观察发现数据的分布特征,求最大最小值、极差等描述性统计量。
数据集
一个数据库的例子:
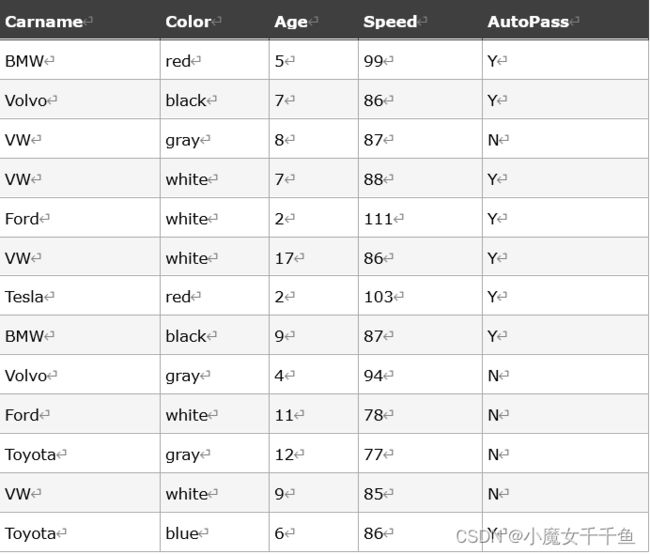 Carname=[]
Carname=[]
Color=[]
Age=[5,7,8,7,2,17,2,9,4,11,12,9,6]
Speed=[99,86,87,88,111,86,103,87,94,78,77,85,86]
Autopass=[]
均值(Mean) - 平均值
方法一:使用Python中的numpy模块
import numpy
speed = [99,86,87,88,111,86,103,87,94,78,77,85,86]
x = numpy.mean(speed)
print(x)

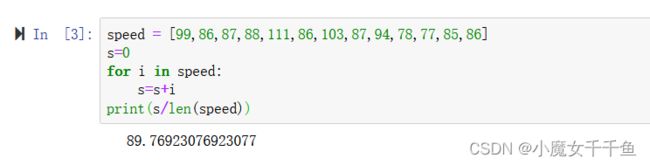
方法二:
speed = [99,86,87,88,111,86,103,87,94,78,77,85,86]
s=0
for i in speed:
s=s+i
print(s/len(speed))
中值(Median) - 中点值,又称中位数
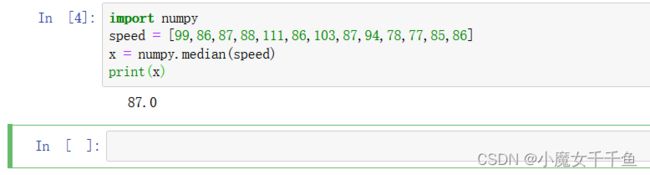
方法一:使用Python中的numpy模块
import numpy
speed = [99,86,87,88,111,86,103,87,94,78,77,85,86]
x = numpy.median(speed)
print(x)
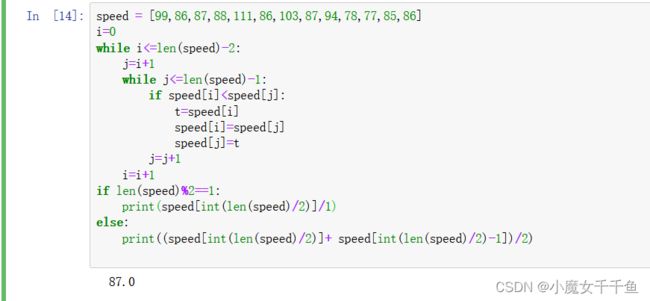
 方法二:
方法二:
speed = [99,86,87,88,111,86,103,87,94,78,77,85,86]
i=0
while i<=len(speed)-2:
j=i+1
while j<=len(speed)-1:
if speed[i]<speed[j]:
t=speed[i]
speed[i]=speed[j]
speed[j]=t
j=j+1
i=i+1
if len(speed)%2==1:
print(speed[int(len(speed)/2)]/1)
else:
print((speed[int(len(speed)/2)]+ speed[int(len(speed)/2)-1])/2)
众数(Mode) - 最常见的值
方法一:使用Python中的numpy模块
from scipy import stats
speed = [99,86,87,88,111,86,103,87,94,78,77,85,86]
x = stats.mode(speed)
print(x)
 方法二:
方法二:
#{99:1,67:2}
speed = [99,86,87,88,111,86,103,86,94,78,77,85,86]
zd={}
for i in speed:
zd[i]=0
for j in speed:
if j in zd.keys():
zd[j]+=1
maxkey=0
maxvalue=0
for key in zd.keys():
if zd[key]>maxvalue:
maxkey=key
maxvalue=zd[key]
print(maxkey,maxvalue)

方差
方差是另一种数字,指示值的分散程度。实际上,如果采用方差的平方根,则会得到标准差!或反之,如果将标准偏差乘以自身,则会得到方差!计算步骤为:
- 求均值:
(32+111+138+28+59+77+97) / 7 = 77.4 - 对于每个值:找到与平均值的差:
32 - 77.4 = -45.4
111 - 77.4 = 33.6
138 - 77.4 = 60.6
28 - 77.4 = -49.4
59 - 77.4 = -18.4
77 - 77.4 = - 0.4
97 - 77.4 = 19.6 - 对于每个差异:找到平方值:
(-45.4)2 = 2061.16
(33.6)2 = 1128.96
(60.6)2 = 3672.36
(-49.4)2 = 2440.36
(-18.4)2 = 338.56
(- 0.4)2 = 0.16
(19.6)2 = 384.16 - 方差是这些平方差的平均值:
(2061.16+1128.96+3672.36+2440.36+338.56+0.16+384.16) / 7 = 1432.2
方法一:使用Python中的numpy模块
import numpy
speed = [32,111,138,28,59,77,97]
x = numpy.var(speed)
print(x)

方法二:
def avg(sz):
av=0
for i in sz:
av=av+i
return av/len(sz)
sp = [32,111,138,28,59,77,97]
av=avg(sp)
sp1=[]
for i in sp:
sp1.append((i-av)**2)
ss=avg(sp1)
print(ss)

注意:标准差是方差的平方根
标准差(欧式距离)
标准差(Standard Deviation,又常称均方差)是一个数字,描述值的离散程度。低标准偏差表示大多数数字接近均值(平均值)。高标准偏差表示这些值分布在更宽的范围内。
方法一:使用Python中的numpy模块
import numpy
speed = [86,87,88,86,87,85,86]
x = numpy.std(speed)
print(x)

百分位数
百分位数(Percentiles)为您提供一个数字,该数字描述了给定百分比值小于的值。
例如:假设我们有一个数组,包含住在一条街上的人的年龄。
ages = [5,31,43,48,50,41,7,11,15,39,80,82,32,2,8,6,25,36,27,61,31]
什么是 75 百分位数?答案是 43,这意味着 75% 的人是 43 岁或以下。
方法一:使用Python中的numpy模块
import numpy
ages = [5,31,43,48,50,41,7,11,15,39,80,82,32,2,8,6,25,36,27,61,31]
x = numpy.percentile(ages, 75)
print(x)
 方法二:
方法二:
def per(sz,pe):
sz.sort()
slen=len(sz)
return sz[int(pe*slen/100)]
ages = [5,31,43,48,50,41,7,11,15,39,80,82,32,2,8,6,25,36,27,61,31]
print(per(ages,75))
 90% 的人口年龄是多少岁?(61)
90% 的人口年龄是多少岁?(61)
import numpy
ages = [5,31,43,48,50,41,7,11,15,39,80,82,32,2,8,6,25,36,27,61,31]
x = numpy.percentile(ages, 90)
print(x)
