Python数据分析上机
一,Numpy数值计算上机
1.创建数组并进行运算。
(1)创建一个数值范围为0~1,间隔为0.01的数组,并查看该数组的维度。
(2)创建100个服从正态分布的随机数,并查看数组的类型。
(3)对创建的两个数组进行四则运算。
(4)对创建的随机数组进行简单的统计分析。
import numpy as np #导入库 arr = np.arange(0,1,0.01) #创建一个数值范围为0~1,间隔为0.01的数组 print('生成的数组为:',arr) #输出数组 arr.ndim #查看该数组的维度 arr2 = np.random.randn(100) #创建100个服从正态分布的随机数 print('生成的随机数组为:',arr2) #输出数组 arr2.dtype #查看数组的类型 print('相加') #创建的两个数组进行四则运算 print(arr+arr2) print('相减') print(arr-arr2) print('相乘') print(arr*arr2) print('相除') print(arr/arr2) print('数组和为',np.sum(arr)) #对创建的随机数组进行简单的统计分析 print('数组均值',np.mean(arr)) print('数组方差为',np.var(arr))2,生成两个2X2矩阵,并计算矩阵的和、差、乘积。
import numpy as np #导入库 arr = np.mat("1 2;3 4 ") #形成矩阵 print(arr) arr1 = arr*3 print(arr1) print('矩阵相加为:',arr+arr1) #运算 print('矩阵相减为:',arr-arr1) print('矩阵相乘为:',arr*arr1)3. 已知矩阵
[[2 3 4]
[4 5 6]
[6 7 8]]
(1)将矩阵存储在mat当中。
(2)将矩阵[1 2 3]存在arr当中,计算mat+arr,并输出结果。
import numpy as np #导入库 mat = np.array([[2,3,4],[4,5,6],[6,7,8]]) #以二维矩阵形式存储数组 print('数组1为:',mat) arr = np.array([[1,2,3]]) #将矩阵[1 2 3]存在arr中 print('数组2为:',arr) print('相加的结果为:',mat+arr)4.读取iris数据集中的花萼长度数据(已保存为CSV格式),并对其进行统计分析。
(1)读取文件。
(2)输出花萼长度表。
(3)输出去重后的花萼长度表
(4)输出花萼长度表总和
(5)输出花萼长度表的累计和
(6)输出花萼长度表的均值
(7)输出花萼长度表的标准差、方差
(8)输出花萼长度表的最小值、最大值
import numpy as np #导入库 iris_sepal_length = np.loadtxt("iris_sepal_length.csv",delimiter=",") #读入时要写相对路径或者绝对路径,delimiter=,用,分隔 print('花萼长度表为:',iris_sepal_length) 2 iris_sepal_length.sort() print('排序后的花萼长度表为:',iris_sepal_length) 3 print('去重后的花萼长度表为:',np.unique(iris_sepal_length)) print('花萼长度表的总和为:',np.sum(iris_sepal_length)) print('花萼长度表的均值为:',np.mean(iris_sepal_length)) print('花萼长度表的标准差为:',np.std(iris_sepal_length)) print('花萼长度表的方差为:',np.var(iris_sepal_length)) print('花萼长度表的最小值为:',np.min(iris_sepal_length)) print('花萼长度表的最大值为:',np.max(iris_sepal_length))
二,Matplotlib数据可视化上机
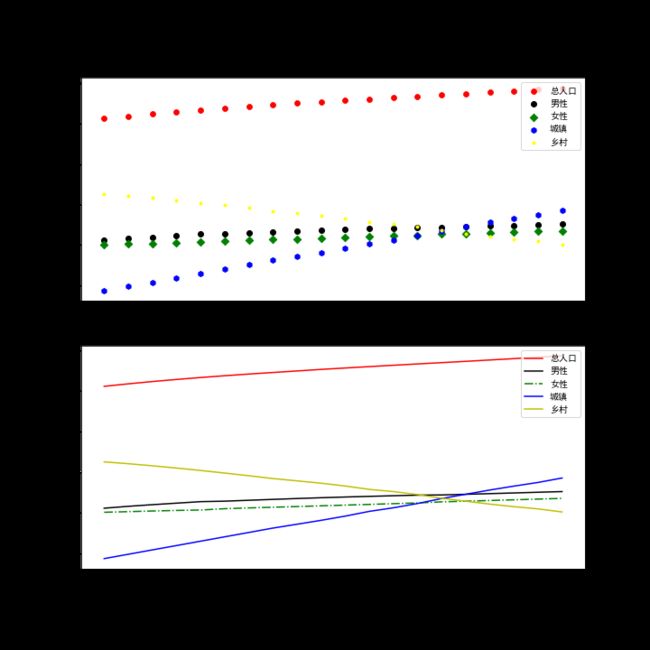
1.分析1996~2015年人口数据特征间的关系。
人口数据总共拥有6个特征,分别为年末人口、男性人口、女性人口、城镇人口、乡村人口和年份。查看各个特征随着时间推移发生的变化情况可以分析出未来男女人口比例、城乡人口变化方向。
(1)使用NumPy库读取populations.nzp人口数据。
(2)创建画布,并添加子图。
(3)在两个子图上分别绘制散点图和折线图。
(4)保存,显示图片
(5)分析未来人口变化趋势。
#导入库 import numpy as np import matplotlib.pyplot as plt #(1)使用NumPy库读取populations.nzp人口数据。并输出 data=np.load("populations.npz",allow_pickle=True) #读入数据,后面的参数解决无法加载参数问题 print(data['feature_names']) #读取每一列的名 print(data['data']) #读取每一列的数据 #(2)创建画布,并添加子图。 plt.rcParams['font.sans-serif']='SimHei' name=data['feature_names'] #设置中文字体 values=data['data'] #确定值数据 p=plt.figure(figsize=(10,10)) #确定画布大小 #(3)在两个子图上分别绘制散点图和折线图。 p1=p.add_subplot(2,1,1) #添加子图1 plt.scatter(values[-3::-1,0],values[-3::-1,1],marker='8',color='red') #绘制散点图 plt.scatter(values[-3::-1,0],values[-3::-1,2],marker='o',color='black') #绘制散点图 plt.scatter(values[-3::-1,0],values[-3::-1,3],marker='D',color='green') #绘制散点图 plt.scatter(values[-3::-1,0],values[-3::-1,4],marker='h',color='blue') #绘制散点图 plt.scatter(values[-3::-1,0],values[-3::-1,5],marker='.',color='yellow') #绘制散点图 plt.xticks(values[-3::-1,0]) plt.xlabel('时间') plt.ylabel('总人口') plt.title('1996~2015年末人口分布特征散点图') plt.legend(['总人口','男性','女性','城镇','乡村']) p2=p.add_subplot(2,1,2) #添加子图2 plt.plot(values[-3::-1,0],values[-3::-1,1],'r-') #绘制折线图 plt.plot(values[-3::-1,0],values[-3::-1,2],'k-') #绘制折线图 plt.plot(values[-3::-1,0],values[-3::-1,3],'g-.') #绘制折线图 plt.plot(values[-3::-1,0],values[-3::-1,4],'b-') #绘制折线图 plt.plot(values[-3::-1,0],values[-3::-1,5],'y-') #绘制折线图 plt.xticks(values[0:20,0]) plt.xlabel('时间') plt.ylabel('总人口') plt.title('1996~2015年末人口分布特征折线图') plt.legend(['总人口','男性','女性','城镇','乡村']) #(4)保存,显示图片 plt.savefig('1996~2015年末人口分布特征散点图和折线图.png') #保存图片前面可加保存路径 plt.show() #展示图片 #(5)分析未来人口变化趋势。 print("未来城镇人口会增加,乡村人口数下降,男女比例不均衡,总人口的增长减慢。") #自主分析
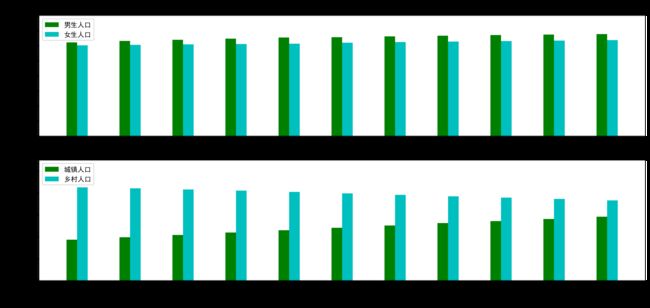
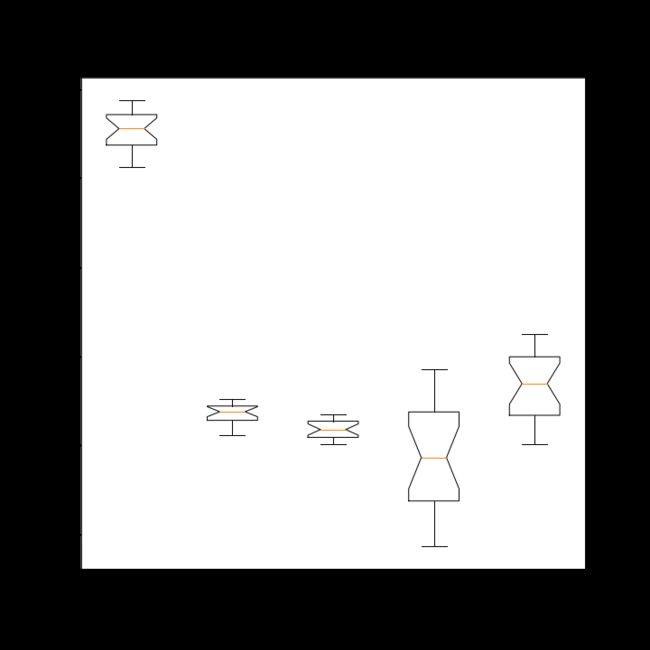
2. 分析1996~2015年人口数据各个特征的分布与分散状况。
通过绘制各年份男女人口数目及城乡人口数目的直方图,男女人口比例及城乡人口比例的饼图可以发现人口结构的变化。而绘制每个特征的箱线图则可以发现不同特征增长或者减少的速率是否变得缓慢。
(1)创建3幅画布并添加对应数目的子图。
(2)在每一幅子图上绘制对应的图形。
(3)保存和显示图形。
(4)根据图形,分析我国人口结构变化情况以及变化速率的增减状况。
直方图
import numpy as np #导入numpy import matplotlib.pyplot as plt #导入matplotlib data=np.load('C:populations.npz',allow_pickle=True) #读入数据 plt.rcParams['font.sans-serif']='SimHei' #设置中文 name=data['feature_names'] #将数据的feature_names设置为name p_data=data['data'] #将数据data的具体数值赋值给p_data p_feature=data['feature_names'] #将列名赋值给p_feature p_data = p_data[:-2] #去空值 p = plt.figure(figsize=(16,15), dpi=300) # 子图1 男女人口数目直方图 ax1 = p.add_subplot(4,1,1) # 绘制男性 plt.bar(np.arange(11), p_data[::-1 ,2][0:11], width=0.2, color='g') # 绘制女性 plt.bar(np.arange(11) + 0.2, p_data[::-1 ,3][0:11], width=0.2, color='c') plt.title('2005年-2015年共11年男女人口数据对比直方图') plt.xticks(range(0,11,1),rotation=45) #设置下列x plt.xlabel('年份') plt.ylabel('人口数目') plt.legend(['男生人口', '女生人口'], loc='upper left') plt.ylim([0, 80000]) # 子图2, 城乡人口数目直方图 ax2 = p.add_subplot(4,1,2) # 绘制男性 plt.bar(np.arange(11), p_data[::-1 ,4][0:11], width=0.2, color='g') # 绘制女性 plt.bar(np.arange(11) + 0.2, p_data[::-1 ,5][0:11], width=0.2, color='c') plt.title('2005年-2015年共11年城乡人口数据对比直方图') plt.xticks(range(0,11,1),rotation=45) #设置下列x plt.xlabel('年份') plt.ylabel('人口数目') plt.legend(['城镇人口', '乡村人口'], loc='upper left') plt.ylim([0, 110000]) plt.savefig('1996`2015年各特征人口直方图.png') plt.show()
饼图,箱线图
import numpy as np import matplotlib.pyplot as plt data=np.load('C:populations.npz',allow_pickle=True) plt.rcParams['font.sans-serif']='SimHei' name=data['feature_names'] values=data['data'] label1=['男性','女性']#标签 label2=['城镇','乡村'] ex=[0.01,0.01]#饼图:设定各项距离圆心n个半径 #2.饼图 p2=plt.figure(figsize=(8,8)) #子图1 a2=p2.add_subplot(2,2,1) plt.pie(values[19,2:4],explode=ex,labels=label1,colors=['pink','crimson'],autopct='%1.1f%%') plt.title('1996年男、女人口数饼图') #子图2 b2=p2.add_subplot(2,2,2) plt.pie(values[0,2:4],explode=ex,labels=label1,colors=['PeachPuff','skyblue'],autopct='%1.1f%%') plt.title('2015年男、女人口数饼图') #子图3 c2=p2.add_subplot(2,2,3) plt.pie(values[19,4:6],explode=ex,labels=label2,colors=['pink','crimson'],autopct='%1.1f%%') plt.title('1996年城、乡人口数饼图') #子图4 d2=p2.add_subplot(2,2,4) plt.pie(values[0,4:6],explode=ex,labels=label2,colors=['PeachPuff','skyblue'],autopct='%1.1f%%') plt.title('2015年城、乡人口数饼图') plt.savefig('1996、2015年各类人口饼图.png') #3.箱线图 p3=plt.figure(figsize=(10,10)) plt.boxplot(values[0:20,1:6],notch=True,labels=['年末','男性','女性','城镇','乡村'],meanline=True) plt.xlabel('类别') plt.ylabel('人口(万人)') plt.title('1996~2015年各特征人口箱线图') plt.savefig('1996`2015年各特征人口箱线图.png') #显示 plt.show()
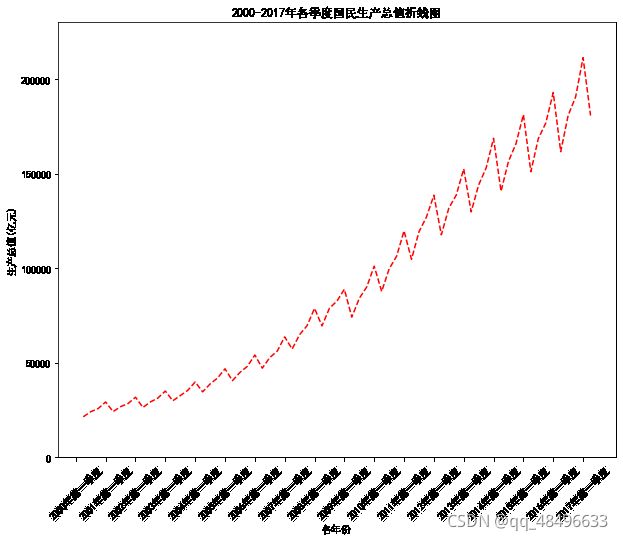
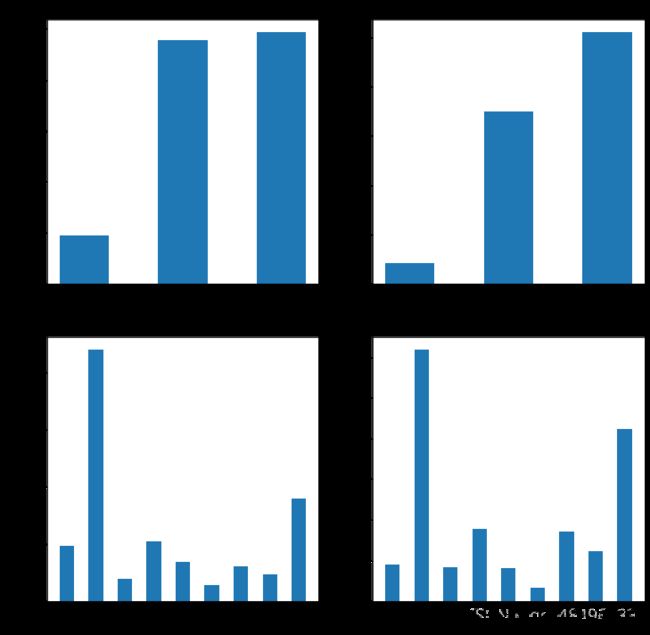
3. 绘制2000年-2017年国民经济核算季度数据相关可视化分析。
(1)“国民经济核算季度数据.npz”文件描述了2000~2017年各季度国民生产值信息。读取“fi”文件信息。
(2)绘制2000-2017年各季度国民生产总值散点图。
(3)绘制2000-2017年各季度国民生产总值折线图。
(4)绘制由4个子图构成的直方图。4个子图分别是:2000年第一季度的国民生产总值产业构成分布直方图、2017年第一季度的国民生产总值产业构成分布直方图、2000年第一季度国民生产总值行业构成分布直方图、2017年第一季度国民生产总值行业构成分布直方图。
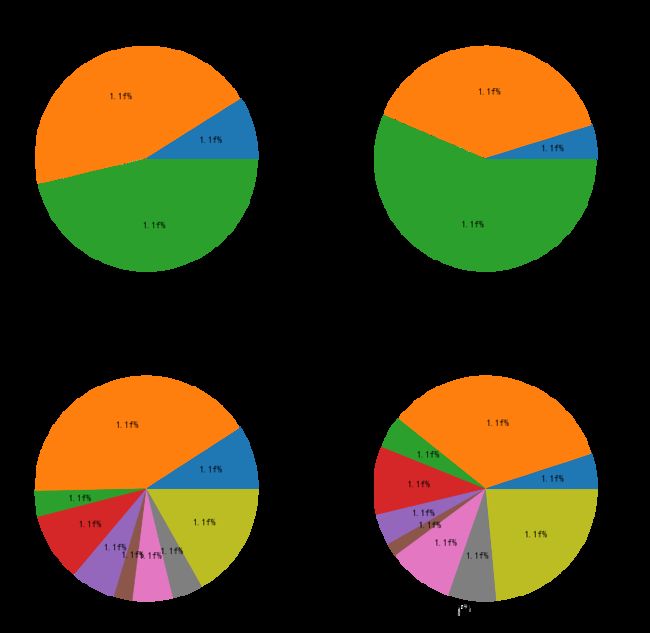
(5)绘制由4个子图构成的饼图。4个子图分别是:2000年第一季度的国民生产总值产业构成分布饼图、2017年第一季度的国民生产总值产业构成分布饼图、2000年第一季度的国民生产总值行业构成分布饼图、2017年第一季度的国民生产总值行业构成分布饼图。
#第一题读取数据 import numpy as np import matplotlib.pyplot as plt plt.rcParams["font.sans-serif"]="SimHei" plt.rcParams["axes.unicode_minus"]=False data=np.load("国民经济核算季度数据.npz",allow_pickle=True) print(data.files) #第二题散点图 name=data["columns"] values=data["values"] plt.figure(figsize=(10,8)) plt.scatter(values[:,0],values[:,2],marker="o") plt.xlabel("各年份") plt.ylabel("生产总值(亿元)") plt.ylim((0,230000)) plt.xticks(range(0,70,4),values[range(0,70,4),1],rotation=45) #设置横向位置和倾斜角度 plt.title("2000-2017年各季度国民生产总值散点图") #图标题 plt.show() #第三题折线图 plt.figure(figsize=(10,8)) plt.plot(values[:,0],values[:,2],color="r",linestyle="--") plt.xlabel("各年份") plt.ylabel("生产总值(亿元)") plt.ylim((0,230000)) plt.xticks(range(0,70,4),values[range(0,70,4),1],rotation=45) #设置横向位置和倾斜角度 plt.title("2000-2017年各季度国民生产总值折线图") #折线图标题 plt.savefig("2000-2017年各季度国民生产总值折线图.png") plt.show() #第四题 label1=["第一产业","第二产业","第三产业"] #设置刻度标签 label2=["农业","工业","建筑","批发","交通","餐饮","金融","房地产","其他"] p=plt.figure(figsize=(12,12)) #子图1 ax1=p.add_subplot(2,2,1) plt.bar(range(3),values[0,3:6],width=0.5) plt.xlabel("产业") plt.ylabel("生产总值(亿元)") plt.xticks(range(3),label1) plt.title("2000年第一季度国民生产总值产业构成分布直方图") #子图2 ax1=p.add_subplot(2,2,2) plt.bar(range(3),values[-1,3:6],width=0.5) plt.xlabel("产业") plt.ylabel("生产总值(亿元)") plt.xticks(range(3),label1) plt.title("2017年第一季度国民生产总值产业构成分布直方图") #子图3 ax1=p.add_subplot(2,2,3) plt.bar(range(9),values[0,6:],width=0.5) plt.xlabel("行业") plt.ylabel("生产总值(亿元)") plt.xticks(range(9),label2) plt.title("2000年第一季度国民生产总值行业构成分布直方图") #子图4 ax1=p.add_subplot(2,2,4) plt.bar(range(9),values[-1,6:],width=0.5) plt.xlabel("行业") plt.ylabel("生产总值(亿元)") plt.xticks(range(9),label2) plt.title("2017年第一季度国民生产总值行业构成分布直方图") plt.savefig("国民生产总值行业构成分布直方图.png") #第五题 label1=["第一产业","第二产业","第三产业"] #设置刻度标签 label2=["农业","工业","建筑","批发","交通","餐饮","金融","房地产","其他"] explode1=[0.01,0.01,0.01] explode2=[0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01] p=plt.figure(figsize=(12,12)) #子图1 ax1=p.add_subplot(2,2,1) plt.pie(values[0,3:6],explode=explode1,labels=label1,autopct="1.1f%%")#制作饼图 plt.title("2000年第一季度的国民生产总值产业构成分布饼图") #子图2 ax2=p.add_subplot(2,2,2) plt.pie(values[-1,3:6],explode=explode1,labels=label1,autopct="1.1f%%")#制作饼图 plt.title("2017年第一季度的国民生产总值产业构成分布饼图") #子图3 ax3=p.add_subplot(2,2,3) plt.pie(values[0,6:],explode=explode2,labels=label2,autopct="1.1f%%")#制作饼图 plt.title("2000年第一季度的国民生产总值行业构成分布饼图") #子图4 ax4=p.add_subplot(2,2,4) plt.pie(values[-1,6:],explode=explode2,labels=label2,autopct="1.1f%%")#制作饼图 plt.title("2017年第一季度的国民生产总值行业构成分布饼图") plt.savefig("2017年国民生产总值总饼图.png") plt.show()


三, pandas数据分析与处理上机
1.读取并查看用户信息更新表Training_Userupdate.csv的基本信息。
(1)使用ndim、shape、memory_usage属性分布查看维度、大小、占用内存信息。
(2)使用describe方法进行描述性统计。
import pandas as pd #导入pandas库 test=pd.read_csv("Training_Userupdate.csv",encoding="gbk") #读取数据 #第一题 print("主表的维度",test.ndim) #显示维度 print("主表的形状",test.shape) #形状 print("主表占用的内存",test.memory_usage().head()) #占内存 #第二题 print("主表的描述性统计",test.describe()) #使用describe方法2.提取登录信息表Training_LogInfo.csv的时间信息。
(1)使用to_datetime函数转换登录信息表的时间字符串。
(2)使用year、month、week等方法提取登录信息表中的时间信息。
(3)计算登录信息表中两时间(LogInfo3、Listinginfo1)的差,以日计算。
(4)使用groupby方法对登录信息表进行分组。
(5)使用agg方法求取分组后的最早和最晚登录时间。
(6)使用size方法求取分组后的数据的的信息登录次数。
import pandas as pd import numpy as np w=pd.read_csv("Training_LogInfo.csv") w["Listinginfo1"]=pd.to_datetime(w["Listinginfo1"]) w["LogInfo3"]=pd.to_datetime(w["LogInfo3"]) year=[i.year for i in w["Listinginfo1"].head()] print("(2)\nLIstinginfo1中前5个年份信息",year[:5]) week=[i.week for i in w["Listinginfo1"].head()] print("LIstinginfo1中前5个星期信息",week[:5]) day=[i.day for i in w["Listinginfo1"].head()] print("LIstinginfo1中前5个日期信息",day[:5]) w1= w["Listinginfo1"]- w["LogInfo3"] print("3\n计算时间差以小时为单位",w1.head()) def TransformDayIntoHour(data): for i in range(0,len(data)): data[i]=data[i].total_seconds()/3600 return data def TransformDayIntoMinute(data): for i in range(0,len(data)): data[i]=data[i].total_seconds()/60 return data w2= w["Listinginfo1"]- w["LogInfo3"] print("计算时间差以分钟为单位:",TransformDayIntoMinute(w2).head()) w3=w[["Idx","LogInfo3"]].groupby(by="Idx") print("分组后的登录信息",w3.head()) print("分组后最早的更新信息",w3.agg(np.min).head()) print("分组后最晚的更新信息",w3.agg(np.max).head()) print("分组后的信息登录次数",w3.size().head())3.插补用户用电量数据缺失值。
用户用电量数据呈现一定的周期性关系,missing_data.csv表中存放了用户A、用户B和用户C的用电量数据,其中存在缺失值,需要进行缺失值插补才能进行下一步分析。
(1)读取missing_data.csv表中的数据。
(2)查询缺失值所在位置。
(3)使用SciPy库中interpolate模块中的lagrange对数据进行拉格朗日插值。
(4)查看数据中是否存在缺失值,若不存在则说明插值成功
import pandas as pd import numpy as np arr=np.array([0,1,2]) w=pd.read_csv("missing_data.csv",names=arr) print("lagrange插值前(False为缺失值所在位置)",w.notnull()) from scipy.interpolate import lagrange for i in range(0,3): la=lagrange(w.loc[:,i].dropna().index,w.loc[:,i].dropna().values) list_d=list(set(np.arange(0,21)).difference(set(w.loc[:,i].dropna().index))) w.loc[list_d,i]=la(list_d) print("第%d列缺失值的个数为:%d"%(i,w.loc[:,i].isnull().sum())) print("lagrance插值后(False为缺失值所在位置)","\n",w.notnull())4. 合并线损、用电量趋势与线路告警数据。
线路线损数据、线路用电量趋势下降数据和线路警告数据是识别用户窃漏电与否的3个重要特征,需要对由线路线路编号(ID)和时间(data)两个键值构成的主键进行合并。
(1)读取ele_loss.csv和alarm.csv表。
(2)查看两个表的形状。
(3)以ID和date两个键值作为主键进行内连接。
(4)查看合并后的数据。
import pandas as pd w=pd.read_csv("ele_loss.csv") w1=pd.read_csv("alarm.csv",encoding='gbk') print('w表的形状',w.shape) print('w1表的形状',w1.shape) merge=pd.merge(w,w1,left_on=["ID","date"],right_on=["ID","date"],how="inner") print("合并后的表的形状为",merge.shape) print("合并后的表为",merge)
四,sklearn模型构建上机
1.使用sklearn处理wine和wine_quality数据集
wine数据集和wine_quality数据集是两份和酒有关的数据集。wine数据集包含3种不同起源的葡萄酒的记录,共178条。其中,每个特征对应葡萄酒的每种化学成分,并且都属于连续型数据。通过化学分析可以推断葡萄酒的起源。
wine_quality数据集共有4898个观察值,11个输入特征和1个标签。其中,不同类的观察值数量不等,所有特征为连续型数据。通过酒的各类化学成分,预测该葡萄酒的评分。
(1)使用pandas库分别读取wine数据集和wine_quality数据集。
(2)将wine数据集和wine_quality数据集的数据和标签拆分开。
(3)将wine_quality数据集划分为训练集和测试集。
(4)标准化wine数据集和wine_quality数据集。
(5)对wine数据集和wine_quality数据集进行PCA降维。
#第(1)(2)题 import pandas as pd data = pd.read_csv('wine.csv',encoding= 'gbk') data1 = pd.read_csv('winequality.csv',sep = ';') w_data=data.iloc[:,1:] w_target=data['Class'] wq_data=data1.iloc[:,:-1] wq_target=data1['quality'] print('wine数据为:',w_data) print('wine标签为:',w_target) print('winequality数据为:',wq_data) print('winequality标签为:',wq_target) #第(3)(4)题 from sklearn.model_selection import train_test_split w_data_train, w_data_test, \ w_target_train, w_target_test = \ train_test_split(w_data, w_target, \ test_size=0.1, random_state=6) wq_data_train, wq_data_test, \ wq_target_train, wq_target_test = \ train_test_split(wq_data, wq_target, \ test_size=0.1, random_state=6) print('wine测试集数据的形状为:',w_data_test.shape) print('wine测试集标签的形状为:',w_target_test.shape) print('wine训练集数据的形状为:',w_data_train.shape) print('wine训练集标签的形状为:',w_target_train.shape) print('winequlity测试集数据的形状为:',wq_data_test.shape) print('winequlity测试集标签的形状为:',wq_target_test.shape) print('winequlity训练集数据的形状为:',wq_data_train.shape) print('winequlity训练集标签的形状为:',wq_target_train.shape) from sklearn.preprocessing import StandardScaler stdScale = StandardScaler().fit(w_data_train) w_trainScaler = stdScale.transform(w_data_train) w_testScaler = stdScale.transform(w_data_test) stdScale = StandardScaler().fit(wq_data_train) wq_trainScaler = stdScale.transform(wq_data_train) wq_testScaler = stdScale.transform(wq_data_test) print('标准化wine数据为',w_trainScaler) print('标准化wine标签为',w_testScaler[:5]) print('标准化winequlity数据为',wq_trainScaler) print('标准化winequlity标签为',wq_testScaler[:5]) from sklearn.decomposition import PCA pca = PCA(n_components=5).fit(w_trainScaler) w_trainPca = pca.transform(w_trainScaler) w_testPca = pca.transform(w_testScaler) pca = PCA(n_components=5).fit(wq_trainScaler) wq_trainPca = pca.transform(wq_trainScaler) wq_testPca = pca.transform(wq_testScaler) print("降维后wine数据集测试集的形状为:",w_trainPca.shape) print("降维后wine数据集测试集的形状为:",w_testPca.shape) print("降维后winequlity数据集测试集的形状为:",wq_trainPca.shape) print("降维后winequlity数据集测试集的形状为:",wq_testPca.shape)2.构建基于wine数据集的K-Means聚类模型
wine数据集的葡萄酒总共分为3种,通过将wine数据集的数据进行聚类,聚集为3个簇,能够实现葡萄酒的类别划分。
(1)根据第1题的wine数据集处理的结果,构建聚类数目为3的K-Means模型。
(2)对比真实标签和聚类标签取FMI。
(3)在聚类数目为2-10类时,确定最优聚类数目。
(4)求取模型的轮廓系数,绘制轮廓系数折线图,确定最优聚类数目。
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters = 3,random_state=1).fit(w_trainScaler) print('构建的KMeans模型为:\n',kmeans) from sklearn.metrics import fowlkes_mallows_score score=fowlkes_mallows_score(w_target_train,kmeans.labels_) print("wine数据集的FMI:%f"%(score)) for i in range(2,11): kmeans = KMeans(n_clusters = i,random_state=123).fit(w_trainScaler) score = fowlkes_mallows_score(w_target_train,kmeans.labels_) print('wine数据聚%d类FMI评价分值为:%f' %(i,score)) from sklearn.metrics import silhouette_score import matplotlib.pyplot as plt silhouettteScore = [] for i in range(2,11): kmeans = KMeans(n_clusters = i,random_state=1).fit(data) score = silhouette_score(data,kmeans.labels_) silhouettteScore.append(score) plt.figure(figsize=(10,6)) plt.plot(range(2,11),silhouettteScore,linewidth=1.5, linestyle="-") plt.show()3. 构建基于wine数据集的SVM分类模型
wine数据集种的葡萄酒类别为3种,将wine数据集划分为训练集和测试集,使用训练集训练SVM分类模型,并使用训练完成的模型预测测试集的葡萄酒类别归属。
(1)读取wine数据集,区别标签和数据。
(2)将wine数据集划分为训练集和测试集。
(3)使用离差标准化方法标准化wine数据集。
(4)构建SVM模型,并预测测试集结果。
(5)打印出分类报告,评价分类模型性能。
import pandas as pd import numpy as np wine = pd.read_csv('wine.csv',encoding= 'gbk') wine_data=data.iloc[:,1:] wine_target=data['Class'] print('wine数据为:',wine_data) print('wine标签为:',wine_target) from sklearn.model_selection import train_test_split wine_data_train, wine_data_test, \ wine_target_train, wine_target_test = \ train_test_split(wine_data, wine_target, \ test_size=0.1, random_state=6) print('测试集数据的形状为:',wine_data_test.shape) print('测试集标签的形状为:',wine_target_test.shape) from sklearn.preprocessing import MinMaxScaler stdScale = MinMaxScaler().fit(wine_data_train) wine_trainScaler = stdScale.transform(wine_data_train) wine_testScaler = stdScale.transform(wine_data_test) print('标准化wine数据为',wine_trainScaler) print('标准化wine标签为',wine_testScaler[:5]) from sklearn.svm import SVC svm = SVC().fit(wine_trainScaler,wine_target_train) print('建立的SVM模型为:\n',svm) wine_target_pred = svm.predict(wine_testScaler) print('预测前10个结果为:\n',wine_target_pred[:10]) from sklearn.metrics import classification_report print('使用SVM预测iris数据的分类报告为:','\n', classification_report(wine_target_test, wine_target_pred))