数据治理技术之数据清洗
数据清洗背景
数据质量一般由准确性、完整性、一致性、时效性、可信性以及可解释性等特征来描述,根据 Rahm 等人在 2000 年对数据质量基于单数据源还是多数据源以及问题出在模式层还是实例层的标准进行分类,将数据质量问题分为单数据源模式层问题、单数据源实例层问题、多数据源模式层问题和多数据源实例层问题这4大类。
现实生活中的数据极易受到噪声、缺失值和不一致数据的侵扰,数据集成可能也会产生数据不一致的情况。数据清洗就是识别并且(可能)修复这些“脏数据”的过程,如果一个数据库数据规范工作做得好会给数据清洗工作减少许多麻烦。
对于数据清洗工作的研究基本上是基于相似重复记录的识别与剔除方法展开的。
并且以召回率和准确率作为算法的评价指标,现有的清洗技术大都是孤立使用的。
不同的清洗算法作为黑盒子以顺序执行或以交错方式执行,而这种方法没有考虑不同清洗类型规则之间的交互简化了问题的复杂性,但这种简化可能会影响最终修复的质量,因此需要把数据清洗放在上下文中结合端到端质量执行机制进行整体清洗。
随着大数据时代的到来,现在已经有不少有关大数据清洗系统的研究,不仅有对于数据一致性以及实体匹配的研究,也有基于MapReduce的数据清洗系统的优化研究。
数据清洗基本方法
从微观层面来看,数据清洗的对象分为模式层数据清洗和实例层数据清洗,数据清洗识别并修复的“脏数据”主要有错误数据、不完整的数据以及相似重复的数据,根据“脏数据”分类,数据清洗也可以分为 3 类:属性错误清洗、不完整数据清洗以及相似重复记录的清洗。
3.2.1 属性错误清洗
数据库中很多数据违反最初定义的完整性约束,存在大量不一致的、有冲突的数据和噪声数据。我们应该识别出这些错误数据,然后进行错误清洗。
(1)属性错误检测
属性错误检测有基于定量的方法和基于定性的方法。
定量的误差检测一般在离群点检测的基础上采用统计方法来识别异常行为和误差,离群点检测是找出与其他观察结果偏离太多的点,Aggarwal 将关于离群点检测方法又分为 6 种类型:极值分析、聚类模型、基于距离的模型、基于密度的模型、概率模型、信息理论模型,并对这几种模型进行了详尽的介绍;
定性的误差检测一般依赖于描述性方法指定一个合法的数据实例的模式或约束,因此确定违反这些模式或者约束的就是错误数据。
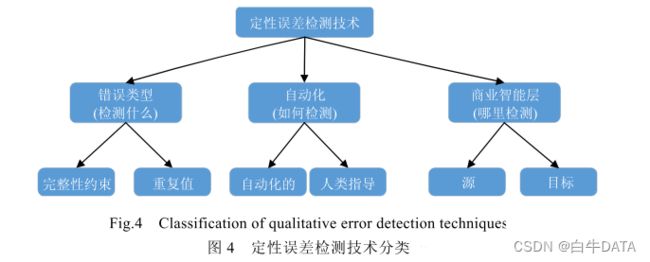
图 4 描述了定性误差检测技术在 3 个不同方面的不同分类下面我们对图中提出的3 个问题进行分析。
首先.错误类型是指要检测什么。定性误差检测技术可以根据捕捉到的错误类型来进行分类,目前大量的工作都是使用完整性约束来捕获数据库应该遵守的数据质量规则,虽然重复值也违反了完整性约束,但是重复值的识别与清洗是数据清洗的一个核心;
其次,自动化检测根据人类的参与与否以及参与步骤来对定性误差检测技术进行分类,大部分的检测过程都是全自动化的,个别技术涉及到人类参与;
最后,,商业智能层是指在哪里检测,错误可以发生在数据治理的任何阶段,大部分的检测都是针对原始数据库,但是有些错误只能在数据治理后获得更多的语义和业务逻辑才能检测出来。
不仅可以使用统计方法来对属性错误进行检测,使用一些商业工具也可以进行异常检测,如数据清洗工具以及数据审计工具等。Potters Wheel是一种公开的数据清洗工具,不仅支持异常检测,还支持后面数据不一致清洗所用到的数据变换功能。
(2)属性错误清洗
属性错误清洗包括噪声数据以及不一致的数据清洗。
噪声数据的清洗也叫光滑噪声技术,主要方法有分箱以及回归等方法,分箱方法是通过周围邻近的值来光滑有序的数据值但是只是局部光滑,回归方法是使用回归函数拟合数据来光滑噪声;
不一致数据的清洗在某些情况下可以参照其他材料使用人工进行修改,可以借助知识工程工具来找到违反限制的数据。
3.2.2不完整数据清洗
在实际应用中,数据缺失是一种不可避免的现象,有很多情况下会造成数据值的缺失,例如填写某些表格时需要填写配偶信息,那没有结婚的人就无法填写此字段,或者在业务处理的稍后步骤提供值,字段也可能缺失。处理缺失值目前有以下几种方法:
忽略元组:一般情况下,当此元组缺少多个属性值时常采用此方法,否则该方法不是很有效,当忽略了此条元组之后,元组内剩下的有值的属性也不能被采用,这些数据可能是有用的;
人工填写缺失值:这种方法最大的缺点就是需要大量的时间和人力,数据清理技术需要做到最少的人工干预,并且在数据集很大、缺失很多属性值时,这种方法行不通;
全局变量填充缺失值:使用同一个常量来填充属性的缺失值,这种方法虽然使用起来较为简单,但是有时不可靠,例如,用统一的常量“NULL”来填写缺失值,在后续的数据挖掘中,可能会认为它们形成了一个有趣的概念;
中心度量填充缺失值:使用属性的中心度量来填充缺失值,中心度量是指数据分布的“中间”值;
使用最可能的值填充:相当于数值预测的概念,回归分析是数值预测最常用的统计学方法,此外也可以使用贝叶斯形式化方法的基于推理的工具或决策树归纳确定缺失值。
3.2.3相似重复记录清洗
相似重复记录识别
消除相似重复记录,首先应该识别出相同或不同数据集中的两个实体是否指向同一实体,这个过程也叫实体对齐或实体匹配。文本相似度度量是实体对齐的最基础方法,大致分为 4 种:基于字符的、基于单词的、混合型和基于语义的。
随着知识表示学习在各个领域的发展,一些研究人员提出了基于表示学习的实体匹配算法,但均是以 TransE 系列模型为基础构建的。TransEl4首次提出基于翻译的方法。将关系解释为实体的低维向量之间的翻译操作,随之涌现出一些扩展的典型算法,下面对这些算法进行简单介绍。
1.MTransE 算法:基于转移的方法解决多语言知识图谱中的实体对齐。首先使用 TransE 对单个的知识图谱进行表示学习;接着学习不同空间的线性变换来进行实体对齐,转移方法有基于距离的轴校准、翻译向量、线性变换这 3 种。该知识模型简单复用 TasE,对于提高实体对齐的精度仍存在很大局限;
2.JAPE 算法:是针对跨语言实体对齐的联合属性保护模型,利用属性及文字描述信息来增强实体表示学习,分为结构表示、属性表示。IPTransE 算法使用联合表示的迭代对齐,即使用迭代的方式不断更新实体匹配。该方法分为 3 部分:知识表示、联合表示、迭代对齐,但这两种算法都是基于先验实体匹配,将不同知识图谱中的实体和关系嵌入到统一的向量空间,然后将匹配过程转换成向量表示间距离的过程;
3.SEEA 算法分为两部分:属性三元组学习、关系三元组学习。该模型能够自学习,不需要对齐种子的输入,每次迭代根据前面迭代过程所得到的表示模型,计算实体向量间的余弦相似度,并选取前B对添加到关系三元组中更新本次表示模型,直到收敛。收敛条件:无法选取前β对实体对。
实体对齐方法不仅应用于数据清洗过程中,对后续的数据集成以及数据挖掘也起到重要的作用。除此之外也有很多重复检测的工具可以使用:如Febrl系统、TAILOR工具、WHIRL系统、BigMatch等。
相似重复记录清洗
相似重复记录的清洗一般都采用先排序再合并的思想,代表算法有优先队列算法、近邻排序算法、多趟近邻排序算法。
优先队列算法比较复杂,先将表中所有记录进行排序后,排好的记录被优先队列进行顺序扫描并动态地将它们聚类,减少记录比较的次数,匹配效率得以提高,该算法还可以很好地适应数据规模的变化。
近邻排序算法是相似重复记录清洗的经典算法,采用滑动窗口机制进行相似重复记录的匹配,每次只对进入窗口的 w 条记录进行比较,只需要比较 w*N 次,提高了匹配的效率。但是它有两个很大的缺点:首先是该算法的优劣对排序关键字的依赖性很大,如果排序关键字选择得不好,相似的两条记录一直没有出现在滑动窗口上就无法识别相似重复记录,导致很多条相似重复记录得不到清洗;其次是滑动窗口的值 w也很难把控,w值太大可能会产生没必要的比较次数,w 值太小又可能会遗漏重复记录的匹配。
多趟近邻排序算法是针对近邻排序算法进行改进的算法,它是进行多次近邻排序算法每次选取的滑动窗口值可以不同,且每次匹配的相似记录采用传递闭包,虽然可以减少很多遗漏记录,但也会产生误识别的情况,这两个算法的滑动窗口值和属性值的权重都是固定的,所以也有一些专家提出基于可变的滑动窗口值和不同权重的属性值来进行相似重复记录的清洗。
以上算法都有一些缺陷,如都要进行排序,多次的外部排序会引起输入/输出代价过大;其次由于字符位置敏感性,排序时相似重复的记录不一定排在邻近的位置,对算法的准确性有影响。
本文引用软件学报吴信东,董丙冰,杨威《数据治理技术》,有删减,有改动,如有侵权,请联系删除。