风控策略分析师日常--代码、数据、策略
开篇:
在魔蝎被警方带走调查后,目前还没有对该案件公开的法律定性定罪。但是爬虫市场已经好像早已经离去,也许他是高利贷的推波助澜,也许他是使用数据的过分泛滥。我们理解,我们遵守,我们敬畏。以下面的案列来告别数据爬虫,也许他将不复存。本文阐述经历在大数据爬虫业务风生水起时。。。。。。一方面了解爬虫数据在风控策略上的应用,一方面了解策略数据挖掘的分析思路。虽然一切过去时,但是方法,思路,技术是永恒的。
继上一篇策略分析师的日常,同学们都觉得是bi同学做的事,但是我好像就没那么幸运了,除了负责公司各部门的报表,还要做策略,还要做模型,最近又负责公司的多产品整体额度授信体系。但是话又说回来了,我不觉得没什么不好的,或者做了以后发现自己懂得更多,能充分了解公司的各个业务,产品,战略等细节。为我的工作提升了整体认知和效率。也在不断克服困难的时候,日积月累,我现在可以负责bi,负责策略,负责模型,参与公司整体规划。是不是自己成了一个复合型的人才。千万不要有这不是我的活,然后各种理由不去干,心态不正,如果我这样,我可能就是一个快要淘汰的电话信审人员,不,已经淘汰了,因为我在16年的时候是一名电话信审人员,觉得策略,数据分析师,模型好高大上哈。正式因为我觉得不会的,我可以尝试的,然后我去克服困难,不断解决,循序渐进,才有今天的不被淘汰。
好了,我们开始讲策略数据代码篇
讲之前先讲下我们风控的整体架构,一个相对完整的风控体系。具体到风控策略:含有准入规则策略、反欺诈规则或者模型策略、信用模型策略、额度策略、利率定价策略,同时针对客户生命周期实施不同的风险管理策略。
分析场景设定
假如我们业务上线了一段时间,积累了大概新户20000左右,当时调取了运营商数据已保存,但是因为谨慎原则,并没有用运营商的规则做决策,现在我们分析下一运营商数据与客户是否坏账的相关性。或者说运营商相关的指标是否具有客户违约预测能力,或者这个预测能力有多大的明显程度,效果怎么样?
(其实这个环节就很重要了,要确定分析的客户必须是新户,要确定的客户坏账定义要明确,逾期多少天,我分析出来的策略要用到哪个环节,怎么用,分析出来用在模型里,还是策略里,这些都很重要,直接影响后续工作要点和质量正确与否的产出)
好了,上面的问题我们确定了,我们先看下运营商的数据什么样的,大概数据结构,类型
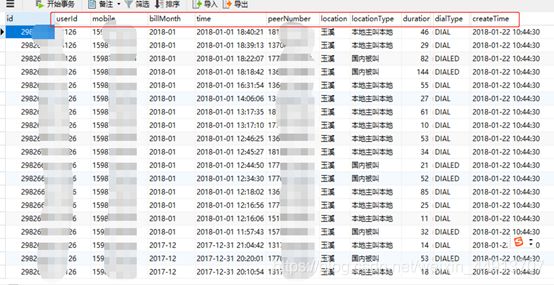
数据是这样的,下一步就是衍生变量,这之前也要注意一些细节,我要确定链接的键值,每一份的里的数据时效性,是否满足分析要求,或者我要有个大概了解,此表userid为键值,createtime 为数据获取时间。数据整体包含了某个手机号与某个手机号在何时何地通话的时长以及通话的类型(主被叫)。
那下一步要直接衍生么,不要,先从数据结构上,再从风控风险策略经验上去设计衍生大纲,衍生思路,(这就是为什么懂风控的数据分析师被大家觉得有优势),如果只是一个单纯的建模人员,或者没有风控经验,多少会有些不愉悦。
好吧,我们按这个思路在sql编辑器上设计变量衍生大纲,我的大纲是这样的。

好吧,衍生变量整体大纲思路设计好,下面我们按这个思路去写衍生变量了,是不是有了思路,体系,写起来就有条理了,清晰了,写出来的顺畅些呢,开始写。


细致的同学看我代码的,我已经衍生了633个变量。中间的变量省去,代码5000多行了,代码语法正确,计算的是一个userid的633个指标,当我们计算多个userid的,就可以用下面的in ( ),然后 group by 。这一步有个关键点,sql计算出来的指标数值要与人工计算的数值进行对比验证,确保准确,核对1-5个userid 的几个随机指标就行。
这个项目,我20000多个样本,写的python(循环样本userid,在提交到sql,然后在合并整体数据) ,夜间配置的自动任务,跑了大概8小时。
你可以看我每个变量都有序号,以及对应的清晰分辨的英文命名,以及清洗的中文解释。这些为后续的维护,迭代,更新,报告,评审,都会带来很方便的工作效率。希望我们大家一开始就从细节做起。
变量跑出来了,因为数据庞大,变量太多,用的python 做的样本主表左链接运营商字段,很方便,上代码。
![]()
数据预览,用文本编辑器打开的,excel几乎打不开了,第一行字段,第二行为衍生指标观测

这么多变量,接下来的工作就好做了,其实数据准备好,后面的工作做起来就方便多了。前期的架构,思路,项目需求,衍生,为后期建立了准确的、丰富的数据准备。
我们开始筛选指标,看看哪个指标预测能力强,我们先来个排序。(一般行业用iv来衡量指标的预测能力,即信息价值,iv中分箱算法对iv影响较大:等频、等宽、卡方、决策树、ks最优)。我采用自己写好的卡方chimerge python代码来计算。
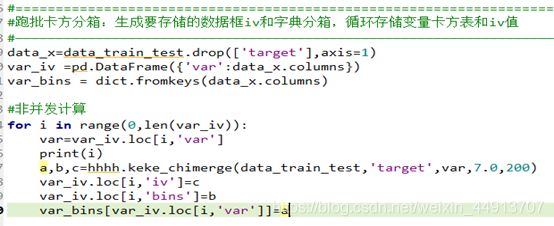
之前的数据集重名为 data_train_test ,前三行代码,去掉目标列,然后取指标,建立一个dataframe存iv值 变量c 和箱数 变量b ,建立一个字典,来存放卡方分箱表 变量a。
用for 循环的形式,遍历每个指标,通过写好的chimerge 分箱iv计算函数,计算每个指标输出的三个值。存放到各个对应的位置。(此函数参数卡方最低合并值为7,默认最低为3.84)
开始跑批我们看下结果,拭目以待了
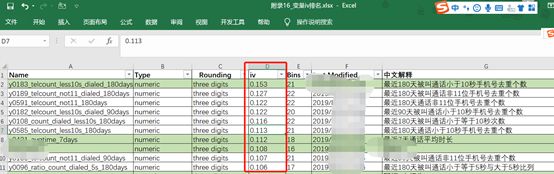
上面这个表是卡方最优分箱计算的iv排名,然后我们看看第一个iv为0.153的变量具体的分箱的详情。
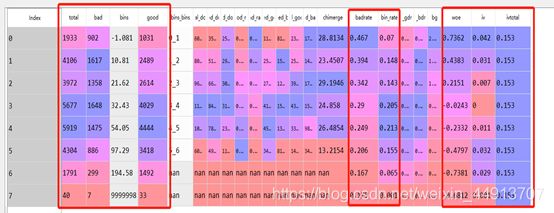
其中缺失值9999998 这一行单独处理,因为运营商的数据大部分是不应该缺失的,我单独放在一箱,可以删除,或者用数学算法填充,用缺失值直接作为一箱处理不好解释。
重点,iv 0.153,具有一定的预测能力了,我们再看下badrate 是单调递减的,趋势完美
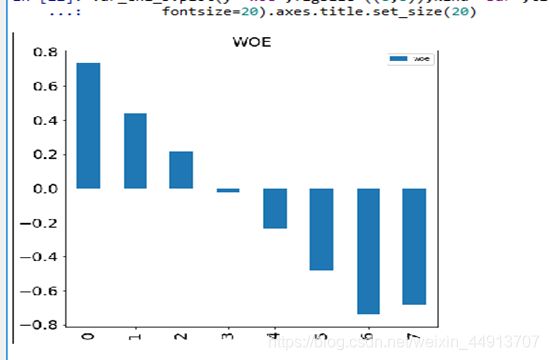
同时woe也是单调递减的。另外我们看每项占比,第一箱坏客户比例46.7%,且占总体比值
Bin_rate 为7%,样本总体坏账为25.9%。从行业经验规则上,本箱坏账达到总体目标坏账的2倍上下,可以单独提取一条策略。这时候这条规则:最近180天被叫通话小于10秒手机号去重个数 < 10.81 ,这条规则数据上可以给出最好的解释,同时从经验解释上也可以很容易理解,我们除了一些主要的电话会大于10秒,而快递,外卖,陌生电话大部分是在10秒内,如果一个欺诈的客户或者坏客户在180天内可能很难养成一个正常人的通话使用习惯。当然如果要建立一个模型也是把可以这个变量放进去的。
好吧,后面就是策略需求上线测试监控的事情了
这就是一个风控策略分析师 进行策略分析、迭代、模型 所涉及的代码数据挖掘分析部分了。
其实大部分的内容相同,每个项目也会涉及到具体的一些细节,用到不同的算法,不同的思路,在这里给大家从项目流程上,从代码分析上,风控策略上给讲述一个简单的案列。
希望我的这个文章可以为同学们带来一点开心,谢谢。
后续
后来我并没有做成单个规则,因为一开始就是个模型项目,其实我整个项目是从建模开始的。文档是这样的,后续如果大家对哪块工作内容感兴趣,我可以针对兴趣点去写,谢谢。
– 行可可–