Elasticsearch 之 REST API
Elasticsearch提供了一个非常全面和强大的REST API,可以使用Linux curl命令发起一个HTTP请求与集群进行交互,也可以使用任何允许进行HTTP/REST调用的工具来发起请求(比如Postman;如果是GET请求也可以直接在浏览器中访问)
一个基于HTTP协议的curl请求的基本格式如下:
curl -X <VERB> '://:/?' -d ''
| 名称 | 说明 |
|---|---|
| VERB | HTTP请求方法,取值为GET、POST、PUT、HEAD或DELETE |
| PROTOCOL | 请求协议,取值为http或https |
| HOST | Elasticsearch集群任意一个节点的主机名 |
| PORT | Elasticsearch HTTP服务端口号,默认为9200 |
| PATH | 请求路径,也成为API端点 |
| QUERY_STRING | 查询字符串 |
| BODY | JSON格式的请求体 |
文章目录
-
- 集群状态API
-
- 了解当前Elasticsearch集群的健康情况
- 查看Elasticsearch集群节点信息
- 索引API
-
- 创建索引
- 查询索引
- 打开和关闭索引
- 删除索引
- 文档API
-
- 添加文档
- 查询文档
- 更新文档
- 删除文档
- 批处理
- 搜索API
-
- URL方式
- body体方式
- Query DSL
-
- 查询(Query)
- 过滤(Filter)
集群状态API
了解当前Elasticsearch集群的健康情况
curl -X GET 'centos01:9200/_cat/health?v'
![]()

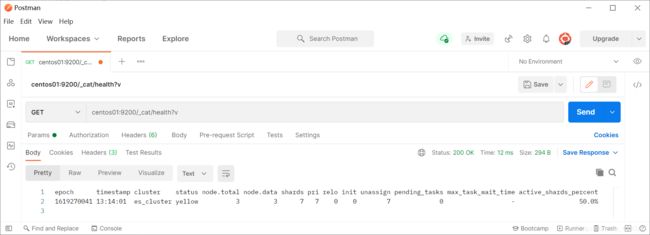
| 返回字段 | 原文 | 含义 |
|---|---|---|
| epoch | seconds since 1970-01-01 00:00:00 | 自标准时间(1970-01-01 00:00:00)以来的秒数 |
| timestamp | time in HH:MM:SS | 时分秒,utc时区 |
| cluster | cluster name | 集群名称 |
| status | health status | 集群状态 green:所有主分片和副本分片都正常运行 yellow:所有主分片都正常运行,但不是所有副本分片都正常运行 red:存在至少一个主分片没能正常运行 |
| node.total | total number of nodes | 节点总数 |
| node.data | number of nodes that can store data | 数据节点总数 |
| shards | total number of shards | 分片总数 |
| pri | number of primary shards | 主分片总数 |
| relo | number of relocating nodes | 复制节点总数 |
| init | number of initializing nodes | 初始化节点总数 |
| unassign | number of unassigned shards | 未分配分片总数 |
| pending_tasks | number of pending tasks | 待定任务总数 |
| max_task_wait_time | wait time of longest task pending | 等待最长任务的等待时间 |
| active_shards_percent | active number of shards in percent | 活动分片百分比 |
我这里status为yellow,unassign等于shards,说明我的集群所有的分片都没有分配…这是因为我的磁盘内存不够了: Elasticsearch的分片默认情况下受控于Elasticsearch集群节点的数据盘磁盘空间,有4个参数进行控制。默认情况下,当数据盘使用超过85%,Elasticsearch不会将分片分配给使用磁盘超过85%的节点。
这四个控制参数分别是:
cluster.routing.allocation.disk.threshold_enabled
默认为true。设置为false禁用磁盘分配决策程序。
cluster.routing.allocation.disk.watermark.low
控制磁盘使用的低水位线。它默认为85%,这意味着Elasticsearch不会将分片分配给使用磁盘超过85%的节点。它也可以设置为绝对字节值(如500mb),以防止Elasticsearch在小于指定的可用空间量时分配分片。此设置不会影响新创建的索引的主分片,或者特别是之前从未分配过的任何分片。
cluster.routing.allocation.disk.watermark.high
控制高水印。它默认为90%,意味着Elasticsearch将尝试从磁盘使用率超过90%的节点重新定位分片。它也可以设置为绝对字节值(类似于低水印),以便在节点小于指定的可用空间量时将其从节点重新定位。此设置会影响所有分片的分配,无论先前是否分配。
cluster.routing.allocation.disk.watermark.flood_stage
控制洪水阶段水印。它默认为95%,这意味着Elasticsearch index.blocks.read_only_allow_delete对每个索引强制执行只读索引块(),该索引在至少有一个磁盘超过泛洪阶段的节点上分配了一个或多个分片。这是防止节点耗尽磁盘空间的最后手段。一旦有足够的可用磁盘空间允许索引操作继续,就必须手动释放索引块。
而我这里已经达到了90%,所以Elasticsearch不会给我分配分片:

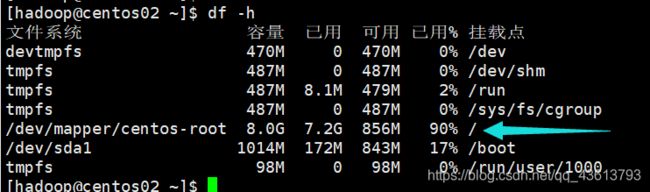
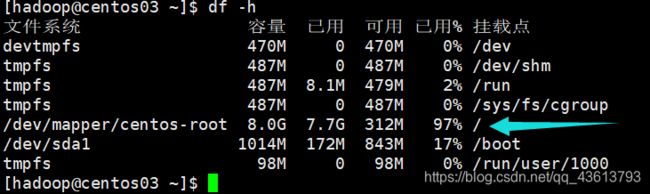
这也是我把Kibana装在centos03上而不是centos01上的原因…
查看Elasticsearch集群节点信息
curl -X GET 'centos01:9200/_cat/nodes?v'

| 返回字段 | 原文 | 含义 |
|---|---|---|
| id | unique node id | ip |
| heap.percent | used heap | 堆内存占用百分比 |
| ram.percent | used machine memory ratio | 内存占用百分比 |
| cpu | recent cpu | CPU占用百分比 |
| load_1m | 1m load avg | 1分钟的系统负载 |
| load_5m | 5m load avg | 5分钟的系统负载 |
| load_15m | 15m load avg | 15分钟的系统负载 |
| node.role | m:master eligible node, d:data node, i:ingest node, -:coordinating node only | node节点的角色 |
| master | *:current master | 是否是master节点 |
| name | node name | 节点名称 |
索引API
创建索引
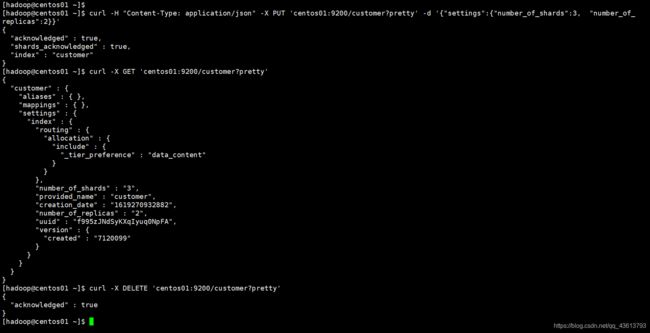
创建一个名为customer的索引:
curl -X PUT 'centos01:9200/customer?pretty'

在创建索引时添加设置,例如设置分片数量、副本数量:(默认都是1)
curl -H "Content-Type: application/json" -X PUT 'centos01:9200/customer?pretty' -d '{"settings":{"number_of_shards":3, "number_of_replicas":2}}'
查询索引
curl -X GET 'centos01:9200/customer?pretty'

查询全部索引:
curl -X GET 'centos01:9200/_all?pretty'
curl -X GET 'centos01:9200/*?pretty'
打开和关闭索引
关闭索引:
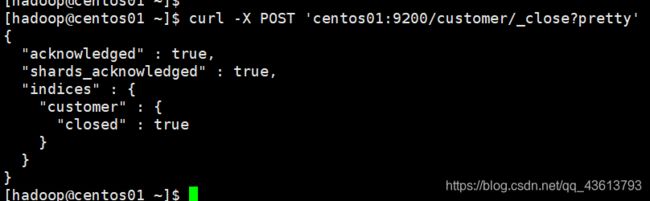
curl -X POST 'centos01:9200/customer/_close?pretty'
打开索引:
curl -X POST 'centos01:9200/customer/_open?pretty'

打开/关闭索引:
curl -X POST 'centos01:9200/_all/_open?pretty'
curl -X POST 'centos01:9200/*/_open?pretty'
curl -X POST 'centos01:9200/_all/_close?pretty'
curl -X POST 'centos01:9200/*/_close?pretty'
删除索引
curl -X DELETE 'centos01:9200/customer?pretty'

文档API
添加文档
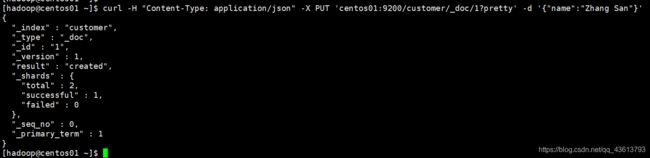
在索引customer中添加一个name为Zhang San的文档,该文档的id为1:
curl -H "Content-Type: application/json" -X PUT 'centos01:9200/customer/_doc/1?pretty' -d '{"name":"Zhang San"}'
查询文档
查询索引customer中id为1的文档:
curl -X GET 'centos01:9200/customer/_doc/1?pretty'

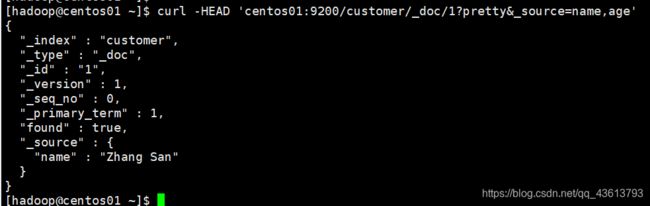
只查询索引customer中id为1的文档的name和age字段:
curl -HEAD 'centos01:9200/customer/_doc/1?pretty&_source=name,age'
只要_source的数据:
curl -X GET 'centos01:9200/customer/_doc/1/_source?pretty'

更新文档
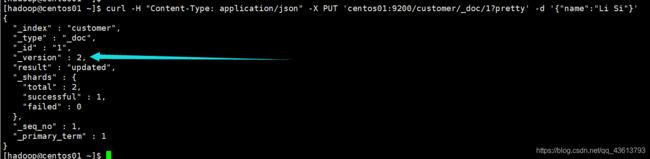
更新customer中id为1的文档的name字段为Li Si:
curl -H "Content-Type: application/json" -X PUT 'centos01:9200/customer/_doc/1?pretty' -d '{"name":"Li Si"}'
一次性更新整个文档例如将customer中id为1的文档更新为{“name”:“Li Si”,“age”:20}:
curl -H "Content-Type: application/json" -X POST 'centos01:9200/customer/_doc/1/_update?pretty' -d '{"doc":{"name":"Li Si","age":20}}'

给age字段 +5 :
curl -H "Content-Type: application/json" -X POST 'centos01:9200/customer/_doc/1/_update?pretty' -d '{"script":"ctx._source.age+=5"}'

删除文档
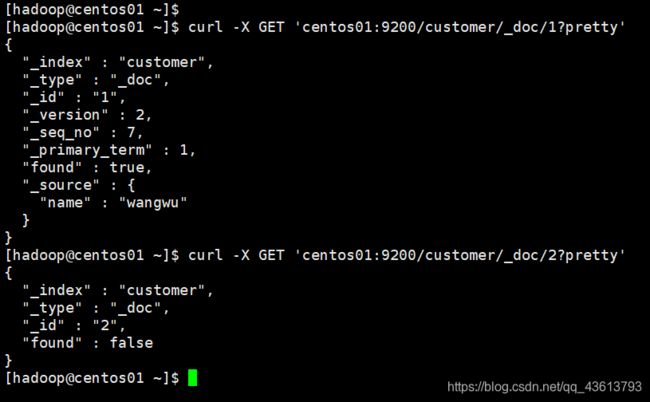
删除索引customer中id为1的文档:
curl -H "Content-Type: application/json" -X DELETE 'centos01:9200/customer/_doc/1?pretty'

批处理
将id为1、name为zhangsan和id为2、name为lisi的两个文档添加到索引customer中:
curl -H "Content-Type: application/json" -X POST 'centos01:9200/customer/_doc/_bulk?pretty' -d '
{"index":{"_id":"1"}}
{"name":"zhangsan"}
{"index":{"_id":"2"}}
{"name":"lisi"}
'

更新id为1的文档,删除id为2的文档:
curl -H "Content-Type: application/json" -X POST 'centos01:9200/customer/_doc/_bulk?pretty' -d '
{"update":{"_id":"1"}}
{"doc":{"name":"wangwu"}}
{"delete":{"_id":"2"}}
'

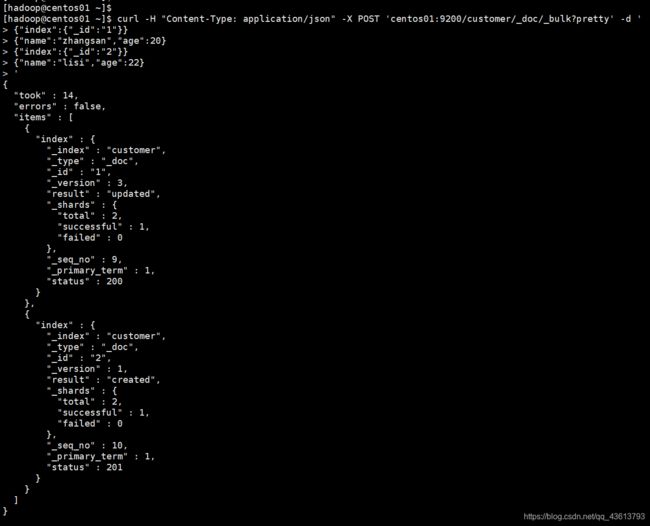
搜索API
首先向索引customer中添加两条数据:
curl -H "Content-Type: application/json" -X POST 'centos01:9200/customer/_doc/_bulk?pretty' -d '
{"index":{"_id":"1"}}
{"name":"zhangsan","age":20}
{"index":{"_id":"2"}}
{"name":"lisi","age":22}
'
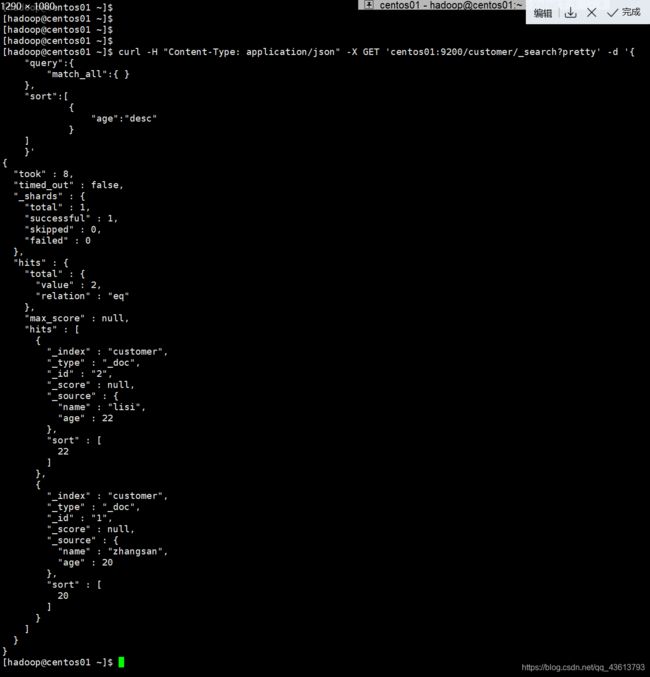
搜索customer索引中的所有文档并将结果按照age字段降序排列:
URL方式
curl -X GET 'centos01:9200/customer/_search?q=*&sort=age:desc&pretty'

body体方式
curl -H "Content-Type: application/json" -X GET 'centos01:9200/customer/_search?pretty' -d '{
"query":{
"match_all":{ }
},
"sort":[
{
"age":"desc"
}
]
}'
Query DSL
上面的将搜索参数放入body体的请求方式在Elasticsearch中被称为领域特定语言(DSL)
查询(Query)
https://www.elastic.co/guide/en/elasticsearch/reference/1.7/query-dsl-queries.html
过滤(Filter)
https://www.elastic.co/guide/en/elasticsearch/reference/1.7/query-dsl-filters.html