基于华为云ECS的目标检测与识别的昇腾AI开发体验【华为云至简致远】
【摘要】 基于华为云弹性云服务器ECS,搭配共享镜像,快速搭建环境,进行目标检测与识别的昇腾AI开发体验,开箱即用,打破时间和空间限制,随时随地进行开发,适合个人开发和团队协作,体验流畅丝滑。
前言
强大的社会粘性不断催温数字化发展,目标检测与识别作为计算机视觉领域的一项关键技术,应用场景广泛,前景十分广阔,从城市治理、楼宇园区、互联网等领域,延伸至智能家居、金融、医疗影像等更多创新领域。随着这些技术潜移默化地渗透入人们的生活中,各行各业竞相通过引入目标检测和识别等人工智能新技术打开市场空间,关于目标检测和识别等各类人工智能需求奔涌而来。

但人工智能应用开发门槛高,周期长,各类AI软件栈理解成本高、各类AI算法模型与业务结合难度高、AI领域开发人员技能要求高,这是AI开发者们的切肤之痛,也是AI基础服务提供商们必须医好的症结。
对此,华为给出了自己的解决方案——昇腾AI。
昇腾AI是以昇腾AI基础软硬件平台为基础构建的人工智能计算产业,昇腾AI基础软硬件平台包括Atlas系列硬件及伙伴硬件、异构计算架构CANN(Compute Architecture for Neural Networks)、全场景AI框架昇思MindSpore、昇腾应用使能MindX等。作为昇腾AI的核心,异构计算架构CANN兼容多种底层硬件设备形态提供强大的异构计算能力,并且通过多层次编程接口,支持用户快速构建AI应用和业务,对上承接多种AI框架,对下服务AI芯片与编程,是提升昇腾处理器效率的关键。同时,还开源了各种AI应用源码供个人和企业开发者们免费使用。
通用目标检测与识别样例介绍
在计算机视觉领域,CANN最新开源的通用目标检测与识别样例,通过其强大的可定制、可扩展性,为AI开发者们提供了良好编程选择。大量模块化编程逻辑、可扩展配置,让开发者们像乐高搭积木一样,仅需进行简单的替换和定制,就能实现符合业务场景需求的高性能、企业级AI应用。
该样例使用了YOLOv3图片检测模型与CNN颜色分类模型,基于CANN AI应用编程接口,对数据预处理、模型推理、模型后处理等AI核心计算逻辑进行模块化组装,实现了车辆检测和车身颜色识别基础功能:
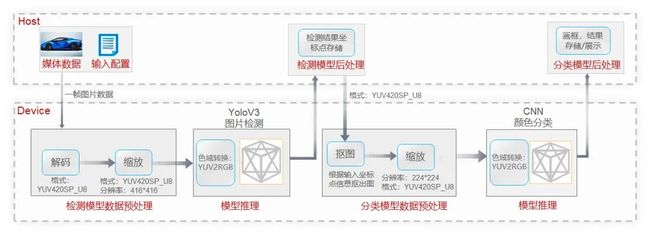
同时,该样例开放出多个编程定制点,并公开了系统的定制文档,详细介绍了样例代码结构、编译运行方法,以及如何基于现有样例代码进行功能定制和扩展,让不同程度的AI开发者们轻松上手。

1. 支持多格式输入和输出
CANN通用目标检测和识别样例支持图片、离线视频、RTSP视频流等多输入格式,开发者可基于此样例实现对图片和视频等不同格式的目标进行识别。另外在结果展示方面,该样例支持图片、离线视频、Web前端等多形式展现,可根据业务场景灵活呈现识别结果。
2. 支持轻松替换和串接模型
样例目前选用的是YOLOv3图片检测模型与CNN颜色分类模型的串接,可实现基本的车辆检测和车辆颜色识别,开发者可轻松修改程序代码,自行替换/增加/删除AI模型,实现更多AI功能。
3. 支持高效数据预处理
图片、视频等各类数据是进行目标检测和识别的原料,在把数据投入AI算法或模型前,我们需要对数据进行预加工,才能达到更加高效和准确的计算。该样例采用独立数据预处理模块,支持开发者按需定制,高效实现解码、抠图、缩放、色域转换等各种常见数据处理功能。
4. 支持图片数、分辨率可变场景定制
在目标检测和识别领域,开发者们除了需要应对输入数据格式等方面差异,还会经常遇到图片数量、分辨率不确定的场景,这也是格外头疼的问题之一。比如,在目标检测和识别过程中,由于检测出的目标个数不固定,导致程序要等到图片攒到固定数量再进行AI计算,浪费了大量宝贵的AI计算资源。该样例开放了便捷的定制入口,支持设置多种数据量Batch档位、多种分辨率档位,在推理时根据实际输入情况灵活匹配,不仅扩宽了业务场景,更有效节省计算资源,大大提升AI计算效率。
5. 支持多路多线程高性能编程
同时,为了进一步提高编程的灵活性,满足开发者实现高性能AI应用,该样例支持通过极为友好和便捷的方式调整线程数和设备路数,极大降低学习成本,提升设备资源利用率。
6. 高效后处理计算
除此之外,本样例还将原本需要在CPU上进行处理的功能推送到昇腾AI处理器上执行,利用昇腾AI处理器强大的算力实现后处理的加速,进一步提升整个AI应用的计算效率。
CANN为AI开发者用户提供了越来越灵活的编程技术支持,让越来越多的开发者们寻求到了更加友好且高效的编程体验。让大学生创新人才更轻松地上手AI开发、开展创意实践,让企业开发者们更高效落地商业应用。
通用目标检测与识别样例实战
基础知识
1. 昇腾形态介绍
以昇腾 AI 处理器的PCIe的工作模式进行区分:
(1)如果PCIe工作在主模式,可以扩展外设,则称为RC模式;
(2)如果PCIe工作在从模式,则称为EP模式。EP模式通常由Host侧作为主端,Device侧作为从端。客户的AI业务程序运行在Host系统中,产品作为Device系统以PCIe从设备接入Host系统,Host系统通过PCIe通道与Device系统交互,将AI任务加载到Device侧的昇腾 AI 处理器中运行。
两种模式的产品及架构如下图所示:

关于Host和Device的概念说明如下:
Host:是指与昇腾AI处理器所在硬件设备相连接的X86服务器、ARM服务器,利用昇腾AI处理器提供的NN(Neural-Network)计算能力完成业务。
Device:是指安装了昇腾AI处理器的硬件设备,利用PCIe接口与服务器连接,为服务器提供NN计算能力。
以下是对于目前的昇腾处理器和产品的工作模式总结:
-
昇腾 AI 处理器的工作模式如下:
− 昇腾310 AI处理器有EP和RC两种模式。
− 昇腾310P AI处理器(昇腾 710 AI处理器)只有EP模式。
− 昇腾910 AI处理器只有EP模式。 -
支持RC模式的产品有:Atlas 200 AI加速模块、Atlas 200 DK 开发者套件。
产品的CPU直接运行用户指定的AI业务软件,接入网络摄像头、I2C传感器、SPI显示器等其他外挂设备作为从设备接入产品。 -
支持EP模式的产品
昇腾310 AI处理器:Atlas 200 AI加速模块、Atlas 300I 推理卡、Atlas 500 智能小站、Atlas 500 Pro 智能边缘服务器、Atlas 800 推理服务器。
昇腾310P AI处理器:Atlas 300I Pro 推理卡、Atlas 300V Pro 视频解析卡。
昇腾910 AI处理器:Atlas 800 训练服务器、Atlas 300T 训练卡。
2. CANN介绍

(1)昇腾计算语言接口:昇腾计算语言(Ascend Computing Language,AscendCL)接口是昇腾计算开放编程框架,是对低层昇腾计算服务接口的封装。它提供Device(设备)管理、Context(上下文)管理、Stream(流)管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理、Graph(图)管理等API库,供用户开发人工智能应用调用。
(2)昇腾计算服务层:本层主要提供昇腾计算库,例如神经网络(Neural Network,NN)库、线性代数计算库(Basic Linear Algebra Subprograms,BLAS)等;昇腾计算调优引擎库,例如算子调优、子图调优、梯度调优、模型压缩以及AI框架适配器。
(3)昇腾计算编译引擎:本层主要提供图编译器(Graph Compiler)和TBE算子开发支持。前者将用户输入中间表达(Intermediate Representation,IR)的计算图编译成NPU运行的模型。后者提供用户开发自定义算子所需的工具。
(4)昇腾计算执行引擎:本层负责模型和算子的执行,提供如运行时(Runtime)库(执行内存分配、模型管理、数据收发等)、图执行器(Graph Executor)、数字视觉预处理(Digital Vision Pre-Processing,DVPP)、人工智能预处理(Artificial Intelligence Pre-Processing,AIPP)、华为集合通信库(Huawei Collective Communication Library,HCCL)等功能单元。
(5)昇腾计算基础层:本层主要为其上各层提供基础服务,如共享虚拟内存(Shared Virtual Memory,SVM)、设备虚拟化(Virtual Machine,VM)、主机-设备通信(Host Device Communication,HDC)等。
环境要求
按照官方的文档说明,如下条件的硬件环境中进行测试,若环境不符合如下要求,样例可能运行失败:
| 产品型号 | 支持的操作系统 |
|---|---|
| Atlas 200 DK 开发者套件(型号 3000) | Ubuntu 18.04 |
| Atlas 300I Pro 推理卡 | Ubuntu 18.04 / CentOS 7.6 |
但遗憾的是,目前我暂无上述两种设备,不过幸好我手头有一些代金券,又恰好有上次CANN训练营的镜像,那我就在华为云ECS购买一台云服务器来试试吧。
如图是我选择的镜像:

根据此镜像,我创建了一台云服务器,规格为: AI加速型 | ai1s.large.4 | 2vCPUs | 8GiB,系统版本为Ubuntu 18.04 server 64bit,是x86 + Ascend 310的硬件组合。不得不说华为云这个弹性云服务器ECS还真是不错,很方便,当然也感谢上次的CANN训练营,是的我可以根据镜像快速创建服务器,不用一个个安装各种驱动和固件了,赞!
这里记录一下我这台云服务器的一些信息:


注意,CANN版本为:5.0.4.alpha001及以上版本,同时解析以下概念:
开发环境指编译开发代码的环境。
运行环境指运行推理程序的环境,运行环境必须带昇腾AI处理器。
开发环境与运行环境合设场景指带昇腾AI处理器的机器既作为开发环境又作为运行环境,此种场景下,代码开发与代码运行在同一台机器上。
开发环境与运行环境分设场景指开发者使用其他独立机器进行代码开发与编译,而不使用带有昇腾AI处理器的机器。
而通过上图,可以看到我这里的CANN版本为:5.0.5.alpha001,对了,咱这是开发环境与运行环境合设场景,安装用户是HwHiAiUser。
应用流程介绍
本样例基于CANN,实现了在昇腾AI处理器上对输入图片或者视频进行目标识别,通用业务流程如下所示:

- AscendCL初始化 调用aclInit接口实现初始化AscendCL。
- 运行管理资源申请 依次申请运行管理资源Device、Context与Stream,确保可以使用这些资源执行运算、管理任务。在申请管理资源时,样例进行了当前昇腾AI处理器运行模式的判断,做到不同形态的昇腾AI处理器的代码实现归一。
- 加载模型文件 加载模型文件,并构建模型的输入与输出。
- 数据预处理。 针对不同类型的输入,分别进行不同的处理,使其满足模型对输入数据的要求。
- 模型推理 执行模型推理,并获取输出结果。
- 推理结果后处理 根据用户选择的后处理方式,对输出结果进行不同的处理,例如对推理结果进行标注,输出为离线视频文件,或通过网页在线展示等。
目录结构
├── model //模型文件夹,存放样例运行需要的模型文件
│ └── xxxx.pb
├── data //数据文件夹
│ └── xxxx //测试数据,输入图片/视频
├── inc //头文件文件夹
│ └── CarParams.h //声明样例使用的数据结构的头文件
├── out //编译输出文件夹,存放编译生成的可执行文件
│ ├── xxxx //可执行文件
│ └── output //结果输出文件夹(如果不存在需要自行创建)
│ └── xxxx //样例运行的输出结果
├── display //网页展示功能实现代码文件夹
│ ├── presenterserver //presenterserver文件夹
│ └── run_presenter_server.sh//presenterserver启动脚本
├── scripts //配置文件+脚本文件夹
│ ├── params.conf //样例运行配置文件
│ ├── present_start.conf //presentserver启动配置文件
│ ├── sample_build.sh //快速编译脚本
│ └── sample_run.sh //快速运行脚本
├── src
│ ├── acl.json //系统初始化的配置文件
│ ├── CMakeLists.txt //Cmake编译文件
│ ├── classifyPostprocess //分类模型后处理线程文件夹,存放该业务线程的头文件及源码
│ ├── classifyPreprocess //分类模型预处理线程文件夹,存放该业务线程的头文件及源码
│ ├── detectPostprocess //检测模型后处理线程文件夹,存放该业务线程的头文件及源码
│ ├── detectPreprocess //检测模型预处理线程文件夹,存放该业务线程的头文件及源码
│ ├── inference //预处理线程文件夹,存放该业务线程的头文件及源码
│ ├── presentagentDisplay //网页展示线程文件夹,存放该业务线程的头文件及源码
│ └── main.cpp //主函数,图片分类功能的实现文件
└── CMakeLists.txt //编译脚本入口,调用src目录下的CMakeLists文件
环境配置
因为咱这次用的是开发环境与运行环境合设场景,下面操作皆针对此场景设置,如果是分设环境,请参考README。
1. 配置环境变量
- 以安装用户在任意目录下执行以下命令,打开.bashrc文件。
注意,咱这里安装用户就是HwHiAiUser,但ECS默认登录是root用户,因此需要切换用户,执行如下命令:
su - HwHiAiUser
运行截图:

接下来就执行:
vi ~/.bashrc
- 在文件最后一行后面添加如下内容。
提示:按“i”可以进入编辑状态。
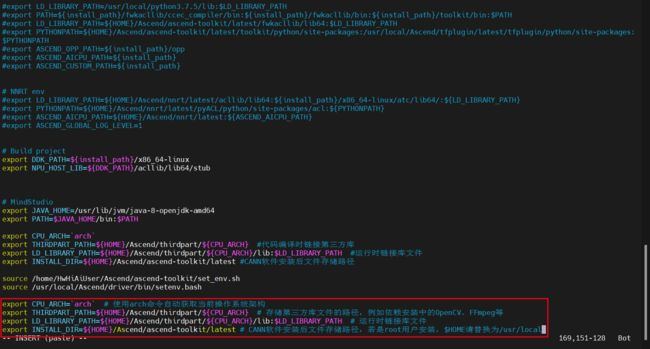
export CPU_ARCH=`arch` # 使用arch命令自动获取当前操作系统架构
export THIRDPART_PATH=${HOME}/Ascend/thirdpart/${CPU_ARCH} # 存储第三方库文件的路径,例如依赖安装中的OpenCV、FFmpeg等
export LD_LIBRARY_PATH=${HOME}/Ascend/thirdpart/${CPU_ARCH}/lib:$LD_LIBRARY_PATH # 运行时链接库文件
export INSTALL_DIR=${HOME}/Ascend/ascend-toolkit/latest # CANN软件安装后文件存储路径,若是root用户安装,$HOME请替换为/usr/local
运行截图:
- 执行命令保存文件并退出。
提示:按“Ecs”是退出编辑状态。
:wq!
- 执行命令使其立即生效。
source ~/.bashrc
2. 创建第三方依赖文件夹。
注意,因为已经使用镜像创建的环境已经创建过了,所以这里就跳过,如果之前未创建过,这里要执行:
mkdir -p ${THIRDPART_PATH}
3. 下载samples仓源码。
先来介绍一些命令,注意先别执行哈:
cd ${HOME} # 此处以将samples源码仓下载到用户家目录为例,开发者可自定义下载路径
sudo apt-get install git # 可选,如果没安装git,则需要执行本命令,本环境可省略,因为已经安装了。
git clone https://gitee.com/ascend/samples.git
那这里,我执行的是如下命令:
mkdir downloads
cd downloads
git clone https://gitee.com/ascend/samples.git
运行截图:

4. 将samples源码仓中的公共库拷贝到前面创建的第三方依赖文件夹中。
cp -r samples/common ${THIRDPART_PATH}
运行截图:
依赖安装
注意,因为咱使用的镜像很棒,所以以下依赖基本都安装过了或者根据业务需求,并不需要安装,所以这里的依赖可省略,但如果确有需求,可参考以下方式安装。
1. OpenCV
样例使用OpenCV接口的作用是进行输入视频文件的读取,以及所有类型输出数据的后处理,数据后处理包括目标标注、不同类型数据的输出,为此必选依赖。但咱这里预装过了,所以可以省略。
咱们这是开发环境与运行环境合设场景,所以在环境上执行如下命令安装OpenCV:
sudo apt-get install libopencv-dev
运行截图:
提示:这里可能要让你输入HwHiAiUser密码,如果你之前没有设置过的话,可以按照如下步骤进行设置:
su - root
passwd HwHiAiUser
这个过程,按照提示操作即可,运行截图:

2. FFmpeg
样例中,FFmpeg的作用是在输入数据类型为RTSP视频流或者离线视频的情况下,进行数据切帧的操作,如果业务不包含输入时RTSP视频流或者离线视频的场景,该第三方库实际上并不会被调用,可以不安装此依赖。
但还是介绍下,在咱这开发环境与运行环境合设场景的安装方法,在环境上参考如下命令使用源码编译的方式安装FFmpeg:
# 下载并解压缩FFmpeg安装包,此处以将FFmpeg安装包存储在用户家目录下为例,开发者也可以自定义FFmpeg安装包存储路径。
cd ${HOME}
wget http://www.ffmpeg.org/releases/ffmpeg-4.1.3.tar.gz --no-check-certificate
tar -zxvf ffmpeg-4.1.3.tar.gz
cd ffmpeg-4.1.3
# 安装ffmpeg
./configure --enable-shared --enable-pic --enable-static --disable-x86asm --prefix=${THIRDPART_PATH}
运行截图:
下面开始make了:
make -j2 # 因为我买的ECS是双核,所以这里写2,具体数值可根据自己的处理器设置
make install
运行截图:

3. PresentAgent
PresentAgent是为了将带有推理结果的图片数据发送到网页进行显示,如果业务场景不存在需要在网页观察推理结果的情况,可以不安装PresentAgent。由于PresentAgent依赖Protobuf,所以若需要使用PresentAgent,也要要同步安装Protobuf。
在咱们的开发环境与运行环境合设场景,参考如下命令使用源码方式安装Protobuf以及PresentAgent:
# 安装Protobuf相关依赖,可省略,咱们的镜像环境已经装过了
sudo apt-get install autoconf automake libtool
运行截图:

# 下载Protobuf源码,此处以将Protobuf存储在用户家目录下为例,开发者也可以自定义Protobuf源码的存储路径。
cd ${HOME}
git clone -b 3.13.x https://gitee.com/mirrors/protobufsource.git protobuf
# 编译安装Protobuf
cd protobuf
./autogen.sh
./configure --prefix=${THIRDPART_PATH}
make clean
make -j2 # 因为我买的ECS是双核,所以这里写2,具体数值可根据自己的处理器设置
sudo make install
# 进入PresentAgent源码目录并编译,PresentAgent源码存储在samples仓的“cplusplus/common/presenteragent”目录下,此处以samples源码存储在用户家目录的downloads文件夹下为例
cd ${HOME}/downloads/samples/cplusplus/common/presenteragent/proto
${THIRDPART_PATH}/bin/protoc presenter_message.proto --cpp_out=./
# 编译安装Presentagnet
cd ..
make -j2
make install
运行截图:
4. AclLite
AclLite库是对AscendCL DVPP图像和视频处理相关接口,AscendCL设备管理、资源管理、模型推理等接口进行了封装,旨在为用户提供一组更简易的公共接口。本样例是基于AclLite接口进行的开发,所以需要下载并编译安装AclLite库。但咱这里预装过了,所以可以省略。
如需安装,请参考文档。
模型及数据准备
样例运行前,请参见本章节准备样例依赖的模型文件及测试数据文件。
1. 准备模型
| 模型名称 | 模型说明 | 模型下载路径 |
|---|---|---|
| yolov3 | 图片检测推理模型。是基于onnx的Yolov5模型。 | 请参考https://gitee.com/ascend/ModelZoo-PyTorch/tree/master/ACL_PyTorch/built-in/cv/Yolov5_for_Pytorch中的“原始模型”章节下载原始模型网络文件、权重文件以及配置文件。 |
| color | 车辆颜色分类推理模型。是基于tensorflow的CNN模型。 | 请参考Ascend/ModelZoo-TensorFlow - Gitee.com中的“原始模型”章节下载原始模型网络文件。 |
2. 模型转换
需要将下载的原始模型转换为适配昇腾AI处理器的离线om模型,并放置到样例代码中的“model”目录下。
为方便操作,此处直接给出了原始模型的下载命令以及模型转换命令,可直接拷贝执行。当然,您也可以参见模型列表中的下载地址中对应的README进行手工操作,并了解更多细节。
# 进入目标识别样例工程根目录,根据实际情况,比如我这里就是根据实际路径
cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify
# 创建并进入model目录
mkdir model
cd model
# 下载yolov3的原始模型文件及AIPP配置文件
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/yolov3_t.onnx
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/aipp_onnx.cfg
运行截图如下,可以看到网络速度是真的快啊,OBS和ECS的搭配真是不错。
下面开始转换模型了:
# 执行模型转换命令,生成yolov3的适配昇腾AI处理器的离线模型文件
atc --model=./yolov3_t.onnx --framework=5 --output=yolov3 --input_shape="images:1,3,416,416;img_info:1,4" --soc_version=Ascend310 --input_fp16_nodes="img_info" --insert_op_conf=aipp_onnx.cfg
运行截图:

接着按照上面的方法,再来一次转换模型:
# 下载color模型的原始模型文件及AIPP配置文件
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/color.pb
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/aipp.cfg
# 执行模型转换命令,生成color的适配昇腾AI处理器的离线模型文件
atc --input_shape="input_1:10,224,224,3" --output=./color_dvpp_10batch --soc_version=Ascend310 --framework=3 --model=./color.pb --insert_op_conf=./aipp.cfg
运行截图:
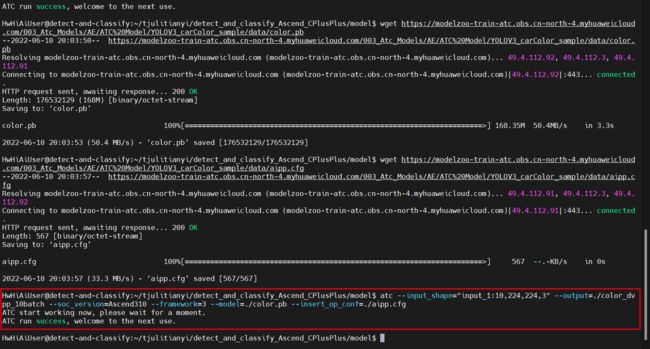
感觉转个模型转换,对CPU要求较高,咱这双核有点慢。
3. 准备数据
样例编译时会自动下载测试数据,无需手工下载。
若您想自行下载测试数据,可参见如下命令:
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car1.mp4 --no-check-certificate
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car2.mp4 --no-check-certificate
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car1.jpg --no-check-certificate
样例数据下载完后请存储在样例工程的data目录下。
样例编译运行
请确认之前的环境及模型、数据准备完成。
1. 在通用目标识别样例工程的根目录下执行以下命令,进行样例编译。
cd scripts
bash sample_build.sh
很遗憾,报错了,报错信息如下图所示:
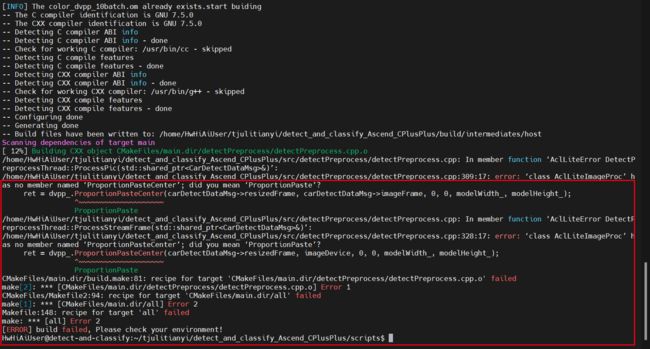
看这报错,应该是没有找到相应的函数或属性,应该是我们的AclLite没安装编译,因为当时镜像已经预装了,便直接用了,看来不行啊,那么下面安装一下吧。
以下操作均在安装用户HwHiAiUser下进行,在咱们的开发环境与运行环境合设场景下,先进入acllite目录,这里要根据实际目录操作哦:
cd ${HOME}/downloads/samples/cplusplus/common/acllite
make
make install
运行完成截图:

好了,这次返回通用目标识别样例工程的根目录下,再来试试:
bash sample_build.sh
果然,编译成功了!如下图所示:
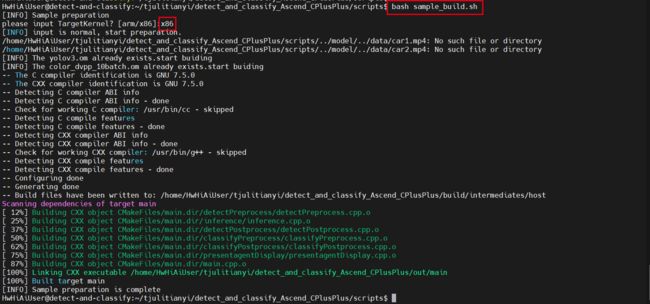
编译完成后,会在out文件夹下生成可执行文件main。
2. 修改scripts目录下的params.conf文件,配置样例的输入数据类型及结果展示类型。
[base_options]
device_num=1 // Device数量
[device_0_options] //Device0的配置参数
inputType_0=pic // Device0的输入数据类型
outputType_0=pic // Device0的输出数据类型
inputDataPath_0=../data/pic // Device0的输入数据路径
#outputFrameWidth_0=1280 //outputType_0为video时,需要配置此参数,代表输出视频的宽
#outputFrameHeight_0=720 //outputType_0为video时,需要配置此参数,代表输出视频的高
#[device_1_options] //Device1的配置参数
#inputType_1=video
#outputType_1=presentagent
#inputDataPath_1=../data/car2.mp4
#outputFrameWidth_1=2368
#outputFrameHeight_1=1080
.......
参数说明:
-
device_num,表示运行此样例的Device数量,device_X_options表示每一个Device上的配置,其中X为Device ID。需要注意,device_num的优先级高于device_X_options的个数,例如,若device_num配置为1,但配置了两个Device的详细信息,即device_0_options与device_1_options,那么实际生效的只有device_0_options,若device_num配置为2,则device_0_options与device_1_options都会生效。
-
inputType_X,表示DeviceX的输入数据类型,其中X为Device ID,此参数当前支持的配置项有:
- pic:表示输入数据为图片,当前此样例支持的图片格式为JPEG压缩图片
- video:表示输入数据为MP4视频文件
- rtsp:表示输入数据为rtsp流
-
outputType_X,表示DeviceX的输出数据类型,其中X为Device ID,此参数当前支持的配置项有:
- pic:表示输出结果为图片
- video:表示输出结果为MP4视频文件
- presentagent:表示用PresentAgent展示推理结果
-
inputDataPath_X:表示DeviceX的输入数据路径,其中X为Device ID,此参数的配置规则如下:
- 若输入数据类型是图片,则填写图片所在文件夹的相对路径,只支持填入一个路径
- 若输入数据类型是mp4视频文件,则填写视频文件的相对路径,只支持填入一个路径
- 若输入数据类型是rtsp流,则填写rtsp流地址,只支持填入一个地址
咱们这里就暂时不做任何修改了。
3. 注意事项
若输出类型配置的为“presentagent”,运行可执行文件前您需要参考此步骤启动PresentServer,若配置的其他输出类型,则此步骤可跳过。
-
配置PresentServer配置文件“present_start.conf”,配置文件参数如下:
在通用目标识别样例根目录下执行如下命令打开配置文件:
cd scripts vim present_start.conf配置文件如下所示:
[present_serer_options] # A socket server address to communicate with presenter agent presenter_server_ip=192.168.1.2 # The port of presenter agent and server communicate with presenter_server_port=7006 #the ip in presenter server view web url presenter_view_ip=192.168.1.2 #view entry label in presenter server view web channel_name=multi_videos #the data type that send to presenter server from agent, 0:image, 1:video content_type=1 [display] display_channel=0- 其中presenter_server_ip为数据发送IP,presenter_view_ip为网页展示IP,两者的IP需要保持一致,配置参考如下:
- 对于Atlas 200 DK开发者板,请填写Atlas 200 DK的与windows主机通信的IP地址即可,例如“192.168.1.2”
- 对于Atlas 300加速卡(例如,ai1s云端推理环境),请填写ai1s的内网IP地址。
- presenter_server_port:PresenterServer的访问端口,请配置为PresentAgent的默认端口号7006即可。
- 其中presenter_server_ip为数据发送IP,presenter_view_ip为网页展示IP,两者的IP需要保持一致,配置参考如下:
-
启动PresentServer服务。
在通用目标识别样例根目录下执行如下命令启动PresentServer:
cd display bash run_presenter_server.sh ../scripts/present_start.conf其中run_presenter_server.sh为PresentServer的启动脚本,present_start.conf为上一步骤中修改的PresentServer的配置文件。
其中PresentServer后,界面会提示PresentServer服务所使用的IP地址及端口号。 -
访问PresentServer展示界面。
-
在windows系统中通过浏览器访问PresentServer网页界面。
- 对于Atlas 200 DK开发者板,请使用启动PresenterServer服务时提示的URL访问即可。
- 对于Atlas 300加速卡(例如,ai1s云端推理环境):
以内网的IP地址为“192.168.0.194”,公网的IP地址为“124.70.8.192”进行举例说明。
启动PresentServer服务时提示“Please visit http://192.168.0.194:7009 for display server”,用户需要将提示URL中的内网IP地址“192.168.0.194”替换为公网IP地址“124.70.8.192”进行访问,即需要访问的URL为“http://124.70.8.192:7009”。
-
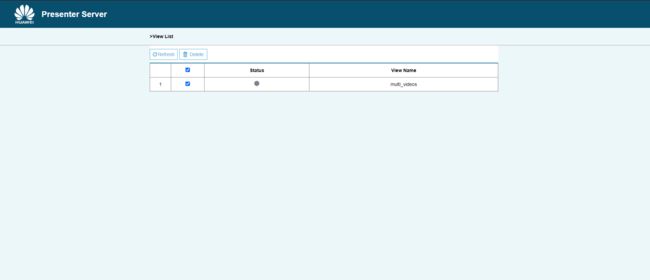
等待PresentAgent传输数据给服务端,单击“Refresh“刷新,当有数据时相应Channel的Status会变成绿色。
-
然后单击右侧对应的View Name链接,查看结果。
说明 :PresentServer当前仅支持显示前四路,如果业务有修改展示路数的需要,除代码开发适配外,还需要对网页UI代码进行修改:
-
修改文件:
display/presenterserver/display/ui/templates/view.html
-
核心代码:
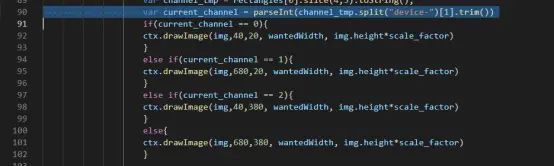
-
-
4. 运行样例。
cd ../out
./main
运行报错了,如图所示:

看看这个报错:
[ERROR] The ../data/car1.mp4 is inaccessible
应该是输入的视频../data/car1.mp4没找到,我去看了一下,还真没有,甚至都没有data文件夹,看来代码并没有自己下载啊,那咱们还是先回到前面,修改下scripts/params.conf吧,先来看看该文件的内容:
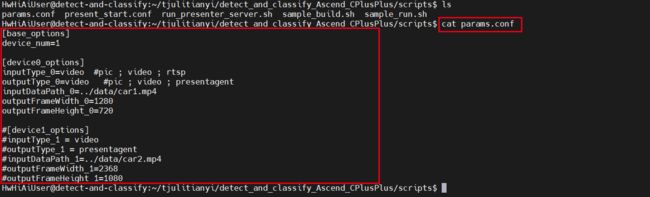
哦,应该就是没有自动下载,那就先建个data文件夹,下载几张图片,在通用目标识别样例工程的根目录下执行:
mkdir data
cd data
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car1.mp4 --no-check-certificate
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car2.mp4 --no-check-certificate
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car1.jpg --no-check-certificate
运行完成截图:
咱们顺便看看下载的这三个文件吧!不过很抱歉的是,视频展示有点Bug,请大家海涵。
car1.mp4
car2.mp4
car1.jpg如下图所示:

下面我们来试试PresentServer展示,这时候要配置一下,请参考之前的 3 注意事项部分:
咱们这利用的是ECS,需要在配置里填写ai1s的内网IP地址。可在ECS的服务台找到,如图所示:

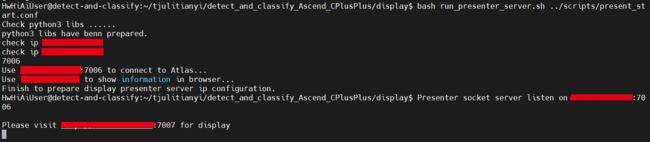
之后要启动PresentServer服务:
cd display
bash run_presenter_server.sh ../scripts/present_start.conf
启动后,界面会提示PresentServer服务所使用的IP地址及端口号。
接下来就访问看看,不过咱们用的是ECS,假设内网的IP地址为“192.168.0.194”,公网的IP地址为“124.70.8.192”。若启动PresentServer服务时提示“Please visit http://192.168.0.194:7009 for display server”。
则需要将提示URL中的内网IP地址“192.168.0.194”替换为公网IP地址进行访问,即需要访问的URL为“http://124.70.8.192:7009”。
如果你遇到无法访问的情况,请修改下安全组入方向的安全规则,我全部放行了(不建议这样做,这样对服务器来说不安全),就能显示了,当然,也可能是网络的延迟,等一会可能就行。
下面还是照例修改scripts目录下的params.conf文件,这里先测试下图片哈:
[base_options]
device_num=1
[device0_options]
inputType_0=pic #pic ; video ; rtsp
outputType_0=presentagent #pic ; video ; presentagent
inputDataPath_0=../data/car1.jpg
outputFrameWidth_0=1280
outputFrameHeight_0=720
#[device1_options]
#inputType_1 = video
#outputType_1 = presentagent
#inputDataPath_1=../data/car2.mp4
#outputFrameWidth_1=2368
#outputFrameHeight_1=1080
之后运行:
cd ../out
./main
可以看到运行成功,但是还是没有显示,可能是一张图片不行?下面试试视频。
换成视频,照例修改scripts目录下的params.conf文件,这里先测试下图片哈:
[base_options]
device_num=1
[device0_options]
inputType_0=video #pic ; video ; rtsp
outputType_0=presentagent #pic ; video ; presentagent
inputDataPath_0=../data/car1.mp4
outputFrameWidth_0=1280
outputFrameHeight_0=720
#[device1_options]
#inputType_1 = video
#outputType_1 = presentagent
#inputDataPath_1=../data/car2.mp4
#outputFrameWidth_1=2368
#outputFrameHeight_1=1080
之后再运行:
cd ../out
./main
好消息,这次没问题了,而且速度很快,FPS在30左右,这时候我们输入的是car1.mp4(1920 * 1080, 30FPS),设置的输出应该是(1280 * 720),这个性能很强啊:

对了,如果最开始没有,别担心,刷新一下,当下图中绿圈“√”出现时候,点击右侧的multi_videos就会跳转了,就能看了:

下面试试car1.mp4(2368 * 1080, 30FPS),输出大小不变,此时scripts目录下的params.conf文件配置如下:
[base_options]
device_num=1
[device0_options]
inputType_0=video #pic ; video ; rtsp
outputType_0=presentagent #pic ; video ; presentagent
inputDataPath_0=../data/car2.mp4
outputFrameWidth_0=1280
outputFrameHeight_0=720
#[device1_options]
#inputType_1 = video
#outputType_1 = presentagent
#inputDataPath_1=../data/car2.mp4
#outputFrameWidth_1=2368
#outputFrameHeight_1=1080
运行结果:
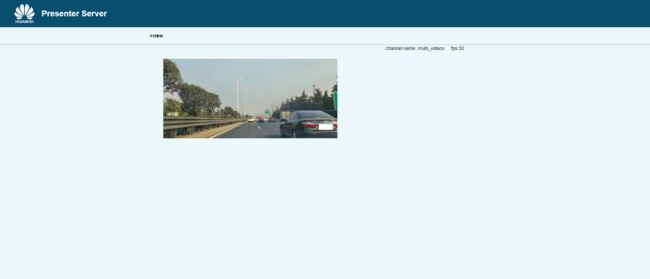
不得不说,真是太强了,速度几乎没变化,FPS仍在30左右,说明输入阶段的视频解码和处理很强,应该是DVPP + AIPP(应该是用于色与转换)的功劳,牛啊!
最后奉上 Ascend 310的硬件情况,AI Core的利用率很高,稳定在68%左右,此时功耗大概12.8W,不过这个功耗很稳定,这个运行期间没什么变化,大约占了1GB的Memory吧,硬件资源占用不大,且利用率高,昇腾果然很强。

结语
整体体验还是很流畅的,华为云弹性云服务器ECS还真挺好用的,大大减轻了我本地的硬件资源要求,让我可以轻松方便体验到昇腾的强大算力,随时随地都能开发,只要有网络即可,搭配镜像使用就更完美了,这次基于共享镜像创建环境非常快,不用重复配置,直接进入开发,可以想象,如果是团队协作开发,效率一定很高,不过最后无法展示有点遗憾,期待更新代码,完善功能。
如果需要开发新的应用,可以很轻松的在此基础上进行改进和优化,官方给了非常详尽的保姆级的教程,手把手教你进行模型替换和开发自己的应用,特别详细,可以想象官方工程师做了很多努力和工作,详细的文档让人赏心悦目,真是把简单留给开发者,把困难留给自己了。
道阻且长,未来可期,期待昇腾AI以向上之力,持续推动人工智能产业生态的建设和发展,构建万物AI的美好世界。