U3-YOLOXs: An improved YOLOXs for Uncommon Unregular Unbalance detection of the rape subhealth regio
Title: U3-YOLOXs: An improved YOLOXs for Uncommon Unregular Unbalance detection of the rape subhealth regions
Abstract: Agricultural production in high latitudes could be limited by cold climate. Plant factory allows continuous production all year round, where the detection of plant growth is one of the most important tasks. To achieve non-destructive detection of rape in our plant factory, a feasible approach is to automatically detect subhealth areas from the rape images. However, this task faces the following challenges: (1) Uncommon problem: the subhealth regions on rape are the domain-specific objects, so the mainstream transfer learning-based detector is unreliable; (2) Unregular problem: the subhealth regions are difficult to detect due to their variable shapes, sizes and colors. (3) Unbalance problem: localization and classification of subhealth regions each have low-/high-quality bounding box unbalance and easy/hard sample unbalance. In this paper, a novel deep object detector based on the YOLOXs, called U3YOLOXs, is proposed for the detection of subhealth regions on rape at the bolting stage. Specifically, a domain-specific self-supervised pre-training strategy in the backbone is developed for the uncommon problem; next, a coordinate attention mechanism in the multi-scale neck network is built for the Unregular problem; finally, the focal EIoU and the focal loss in the decoupled head are designed for the Unbalance problem. The experimental results show that the mAP of our U3YOLOXs is 94.38 % with a latency of 20.4 ms per image, which achieves an optimal accuracy-speed tradeoff. Compared to the YOLOXs it achieves a significant improvement of 9.27 % on mAP at the cost of only 3.55 % increase in latency. Experimental analysis further shows the effectiveness of each improvement, and the reliability of porting U3YOLOXs to edge devices for agricultural production.
Keywords: NONE.
题目:U3-YOLOXs: 一种用于油菜亚健康区域异常不平衡检测的改进YOLOXs
摘要:高纬度地区的农业生产可能会受到寒冷气候的限制。植物工厂可以全年连续生产,其中检测植物生长是最重要的任务之一。为了在我厂实现油菜的无损检测,一种可行的方法是从油菜图像中自动检测亚健康区域。然而,这项任务面临以下挑战:(1)不常见的问题:油菜上的亚健康区域是特定领域的对象,因此主流的基于迁移学习的检测器是不可靠的;(2) 不正常的问题:亚健康区域由于其形状、大小和颜色的变化而难以检测。(3) 不平衡问题:亚健康区域的定位和分类各有低/高质量边界盒不平衡和易/硬样本不平衡。本文提出了一种基于YOLOX的新型深度对象检测器,称为U3-YOLOX,用于检测油菜抽薹期的亚健康区域。具体来说,针对不常见的问题,在主干网中开发了一种特定领域的自监督预训练策略;其次,针对不正常的问题,建立了多尺度颈部网络中的坐标注意机制;最后,针对不平衡问题,设计了解耦合头的聚焦EIoU和聚焦损失。实验结果表明,我们的U3 YOLOX的mAP为94.38%,每张图像的延迟为20.4ms,实现了最佳的精度-速度折衷。与YOLOX相比,它在mAP上实现了9.27%的显著改进,而延迟仅增加3.55%。实验分析进一步表明了每种改进的有效性,以及将U3YOLOX移植到农业生产边缘设备的可靠性。
1.引言
油菜是世界上最重要的经济作物之一。同时,作为中国四大油料作物,油菜的持续生产对食品工业至关重要,为数亿人的日常生活提供食用油。对于传统农业来说,油菜生产受到不可控的气候、自然温度和土壤的影响,例如,在图1中,黑龙江省年平均气温低限制了油菜种植。随着植物工厂的引入(Zhang et al.,2022),可以精确控制油菜所需的光谱、温度、湿度、pH值和营养液元素比例等条件,使寒冷地区全年连续生产油菜成为可能。然而,对水培的依赖也带来了新的问题:营养液中的异常(如紊乱和污染)比土壤中传播得更快。由这些异常引起的油菜亚健康特征,如出现白点和叶片发黄,损害了油菜的质量和经济价值。
如今,计算机技术和人工智能时代促进了精准农业的发展。深度计算机视觉技术已成功应用于农业,如基于二维图像的检测、分类、分割和评估。具体而言,目标检测。Dai(Dai et al,2022a)开发了用于工业级目标检测的具有激活压缩训练的轻量级YOLOv5,它使用模型修剪和知识提取来提供跨物种作物疾病检测。Dai(Dai et al,2022b)进一步提出了一种改进的YOLOv5,它利用CrossConv和快速SPP的多尺度特征融合来检测发芽的土豆,并设计了一种新的遗传迭代来优化锚框大小。Jia(Jia et al,2020)提出了一种改进的掩码R-CNN,它使用密集连接卷积网络(DenseNet)作为主干,用于重叠树枝和树叶下的苹果检测。

李(Li et al,2021a)设计了一种改进的YOLOv4-mining,它添加了颈部卷积块注意力模块(CBAM)和自适应空间特征融合(ASFF),用于在密集背景下快速准确地检测辣椒(AP为95.11%)。
李(Li et al,2021b)提出了一种用于密集水培生菜检测的改进的快速R-CNN,该方法用于细粒度检测的高分辨率网络(HRNet)取代了原来的方法。张(Zhang et al.,2022)设计了一种金字塔分割注意力PSA增强YOLOv5来检测植物工厂中油菜种子的存活率,该方法达到了99.6%的mAP。
分类。Ashraf(Ashraf et al.,2020)提出了一种基于灰度协方差矩阵(GLCM)的支持向量机,用于稻田杂草的自动识别。张(Zhang et al.,2018a)分别基于GoogLeNet和Cifar 10提出了两种改进的玉米叶片病害自动诊断深度模型。Sharif(Sharif et al.,2018)提出了一种两阶段的柑橘病害检测和分类方法,该方法首先使用加权分割提取病害特征,然后使用支持向量机对这些深度融合的特征进行分类。
分割。吴(Wu et al,2021)设计了一种改进的DeepLabV3+,用于水培生菜异常叶片的语义分割,该算法使用统一权重(UW)策略为不同类别的像素分配权重。王(Wang et al.,2020b)提出了一种用于玉米植株分割的空间感知图像恢复方法,该方法使用断点匹配和碎叶贝塞尔曲线拟合策略来优化复杂光照下的分割结果。
评估。张(Zhang et al.,2020)提出了一种基于二维数字图像的作物性状评价方法,该方法使用CNN模型对叶鲜重(LFW)、叶干重(LDW)和叶面积(LA)进行回归预测,均方根误差RMSE=0.23,R2=0.93。
尽管这些工作取得了巨大的进步,但它们仍然存在局限性。他们中的大多数专注于作物级图像处理,例如识别图像中的作物或检测图像中作物的位置,但很少关注缺陷级的图像处理,如检测油菜(或其他作物)的特定亚健康区域。然而,正如我们之前所讨论的,缺陷级图像处理对于工厂的高效生产更为重要。因此,迫切需要一种新的缺陷级深度对象检测器来检测油菜的亚健康区域。然而,实现这一需求并非易事,因为存在以下挑战:(1)不常见:油菜的亚健康区域是特定领域的缺陷水平对象(即,不是根、茎、叶和果实等实体)。由于这些对象很少,传统的基于迁移学习的深度神经网络预训练策略是不可靠的(2) 无规律:亚健康区域由于其形状、大小和颜色的变化而难以检测。例如,油菜叶片上的斑点可能密集或稀疏,也可能大或小,也可能暗或亮;(3) 不平衡:亚健康区域的定位和分类任务各有低/高质量边界框不平衡和易/硬样本不平衡问题。具体而言,在定位阶段,大多数预测的边界框是低质量的(即背景),因为图像中的亚健康区域通常很小;在分类阶段,这些低质量的边界框(即简单样本)进一步削弱了分类器的判别能力。为了解决上述局限性,本文提出了一种基于YOLOX模型的新型检测器,用于检测油菜抽薹阶段的亚健康区域,以解决上述U3问题,称为U3-YOLOX。具体来说:(1)对于不常见的问题,开发了一种在主干中的自监督预训练策略,该策略允许在收集的油菜数据集上预训练特征提取器(主干),用于特定领域的对象检测任务。这与农业中大多数依靠ImageNet迁移学习来预训练主干的检测方法截然不同;(2) 针对不规则问题,在颈部网络中建立了坐标注意机制,允许跨通道捕捉空间和位置信息,融合方向和位置特征,提高检测不规则物体的能力;(3) 对于不平衡问题,解耦头中的焦点EIoU和焦点损失分别用于定位和分类,这允许从高质量的边界框和硬样本中获得更有用的梯度,以提高最终性能。在论文的其余部分,材料和数据在第2节中介绍,方法在第3节中描述,实验细节和结果在第4节中报告,结论和第5节总结了未来的工作。
2. 材料和数据
2.1 栽培环境
本文中使用的油菜是 2021 年 11 月在东北农业大学现代农业技术中心的植物工厂培育的。得益于我们开发的各种监测系统(Jiang et al,2021);(Zhang et al., 2018b),建立了具有参数化气候条件的栽培环境。具体来说,昼夜温度为23/18◦C、 平均相对湿度为65%,营养液节点PH值控制在5.6至6.4之间,营养液的节点EC值控制在1200至1800μS/cm之间,环境节点浓度控制在6000至7000 ppm之间,层间光(全光谱和红光和蓝光)强度为60000–80000 lx,层间叶表面平均温度为18◦C 2021年11月3日至2021年12月20日,水培油菜在上述受控气候条件下生长,如图2所示。具体来说,种子首先在封闭和不透水的条件下浸泡在温水中(2份沸水比1份冷水),然后将种子播种在覆盖着蛭石的营养土中,当幼苗有两片真叶时种植——根尖穿过海绵块的顶部插入种植孔中;最后,营养液开始循环60分钟以上,每天三次。上述操作可以有效避免水培油菜生长过程中的农药、化肥、害虫和重金属污染。

2.2 数据采集
在工厂里,一台分辨率为5472×3648像素的佳能EOS 70D相机被用来拍摄油菜图像。正如我们之前所讨论的,在本文中,拍摄了油菜抽薹阶段的2D图像。连续采集图像20天。为了更好地模拟检测机器人全天候采集图像的视觉系统,我们的采集频率为每天两次,一次在上午9点,另一次在晚上8点。同时,图像是在全光谱和红蓝光源下拍摄的。此外,考虑到不同拍摄角度的影响,在收集过程中,油菜案的垂直俯视图和不同角度的侧视图都被拍摄了下来。最后,我们的收集包括每张图像的单个油菜和每张图像的多个油菜,这是为了增强数据的普遍性。最终,共收集到960张有效图像。
2.3 数据增强处理
数据量小很难训练深度模型,为了合法地扩展我们收集的数据,采用一系列的数据扩充方法来生成更多的等效数据。首先,对原始数据执行经典的数据扩充方法Mosaic和Mixup,生成1620张新图像;然后,对原始数据使用Cutmix方法,随机裁剪图像并将其粘贴到其他图像上,生成960张新图像;最后,在一些原始数据上添加盐噪声以产生420个新图像。上述数据扩充过程如图3所示,之后我们总共有3000张有效图像。
在涉及数据处理时,首先按照7:1:2的比例划分训练集、验证集和测试集。具体而言,训练集中的2100幅图像用于训练模型的参数,验证集中的300幅图像用于调整模型的超参数,测试集中的600幅图像用于评估模型在实验中的最终检测性能。此外,注释软件labelImg用于标记所有图像,包括绘制每个对象的边界框和用特定类别标记每个对象。注释过程如图4所示。PascalVOC2007数据集格式用于生成所有注释。最后,由于原始图像的分辨率高达5472×3648像素,因此图像被均匀压缩到640×640像素以输入模型。


3. 方法:U3YOLOXs
3.1. 模型概述
本文提出的油菜亚健康区域检测任务解决方案的技术路线如图5所示。U3 YOLOX可以由可用的模块灵活地构建。考虑到专家标记数据的昂贵和短缺,从工厂收集的油菜图像允许在没有注释的情况下为U3YOLOX提供自我监督的预训练,即第3.3节中设计的MS-EMD策略。为了统一预先训练的多尺度网络,第3.4节中开发的坐标注意力允许自适应地融合来自不同粒度的特征图。标记的油菜数据集为监督训练提供了U3YOLOX,并且在第3.5节中设计了焦点损失和焦点EIoU,以优化分类和定位的损失。最终,经过训练的模型将被部署到工厂检测应用的检测机器人上。
U3 YOLOX的网络架构如图6所示。与YOLOX类似,整个网络分为骨干网络、颈部网络和头部网络。在自监督预训练阶段,颈部网络输出的多尺度特征图可以通过对比目标MS-EMD进行优化,对应于三个CA块的通道。在训练阶段,头部网络被解耦为分类和定位分支,可以通过监督目标焦点损失和焦点EIoU进行优化。图6中各部件的功能详见第3.2节。

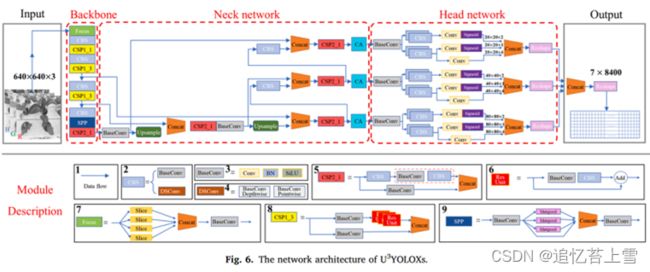
3.2. YOLOXs 框架
农业生产中应用的目标检测技术需要满足Raspberry Pi和Jetson Nano等边缘设备的实时检测,因此模型的大小受到限制。最先进的轻量级物体探测器YOLOX被用作我们的U3 YOLOX的模型基础。我们的模型在不同方面增强了YOLOX的主干网、颈部网络和头部网络,同时模型的参数几乎保持不变,性能得到提高。接下来,以模块化的方式详细阐述了模型的细节。如图6所示,数据流用蓝色箭头表示。CBS模块包括两个候选结构:基本卷积(BaseConv)和深度可分离卷积(DWConv)(Chollet,2017),由代码中的if-else语句选择。具体而言,BaseConv由卷积层、批处理规范化层和SiLU激活函数组成。DWConv由深度卷积层和点卷积层组成,深度卷积层产生多个通道独立的特征图,点卷积层对这些特征图进行跨通道加权融合;跨阶段部分网络(CSP)(Wang et al,2020a)可分为两种类型:CSP1_X是具有ResUnit的深度特征提取器,其中X是堆叠的ResUnit的数量,因此CSP1_X经常插入主干中。CSP2_X是具有全卷积网络的特征积分器,其中X是堆叠的CBS块的数量,因此CSP2_X经常插入到颈部网络中。ResUnit(He et al.,2016)是一种具有跳跃连接的残差网络,用于缓解深度网络的梯度分散问题;聚焦模块用于对输入图像进行切片,这是一种没有信息丢失的下采样方法;空间金字塔池网络(SPP)(He et al,2015)用于将任意大小的多个特征图转换为固定大小的特征张量,从而确保与后续网络的正确连接。
在以上模块的基础上,对模型的体系结构进行了描述。主干采用基于YOLOv5主干的改良CSPDarket53(Bochkovskiy等人,2020)。主干从利用Focus模块对图像进行无损下采样开始,然后通过堆叠CBS模块和CSP1_X模块来提取图像的深层特征,并利用SPP模块重新缩放特征维度,最后利用CSP2_X模块融合这些高维特征。我们在第3.2节中开发的自监督预训练策略致力于训练在亚健康区域检测任务中具有更强非常见特征提取能力的骨干。颈部网络的结构遵循特征金字塔网络(FPN)(Lin et al、 2017a). FPN通过自上而下的路径和横向连接将低分辨率、语义强的特征与高分辨率、语义弱的特征相结合。这个在各个层面上语义丰富的特征金字塔是从单个输入图像尺度快速构建的,这样就不会牺牲表示能力、速度或内存。第3.3节中构建的协调注意力(CA)模块旨在增强非正常亚健康区域上颈部网络的特征表示能力。头部网络的结构遵循FCOS中的解耦头部(Tian et al,2019),其中分类、对象性和定位不再共享参数。如图6中的头部网络所示:_ × _ × 2表示预测的亚健康区域属于spot_ape或yellow_rape类别的概率;_ × _ × 1表示预测为亚健康区域的概率;定位头的_ × _ × 4输出表示预测边界框在x轴、y轴、宽度和高度上的偏移。我们在第3.4节中修改的损失函数致力于缓解解耦头部的样本不平衡问题。请注意,以下将对象性和本地化统称为本地化。
3.3. 针对不常见问题的MS-EMD
最近,自监督方法,如SimCLR(Chen等人,2020)、MoCo(He等人,2020。这些方法通过最大化同一图像的不同变换视图(给定图像V,在对V执行任何数据增强方法(例如,翻转、旋转、缩放、裁剪和添加高斯噪声)后获得的新图像V称为V的变换视图)之间的一致性同时最小化不同图像之间的一致度来预训练检测器。尽管缓解了迁移学习的领域不兼容问题,但由于空间结构和定位信息的破坏,他们学习的图像的全局表示对于目标检测来说并不是最优的。如今,提出了一种专门为目标检测设计的自监督方法,称为自EMD(Liu et al,2020),该方法通过使用卷积特征张量作为图像表示而不是全局向量来保留空间和定位信息。Self-EMD将来自同一图像的两个变换视图的特征张量分别作为提供者和需求者进行处理,然后通过最小化它们之间的地球移动器距离(EMD)来优化特征张量的一致性。
具体而言,自EMD利用两个网络2分别从同一油菜图像的两个视图中提取特征张量。第一个视图Γ被馈送到由编码器fθ和预测器qθ组成的在线网络中;第二个视图v'被馈送到由编码器fξ组成的目标网络中。特别地,fθ和fξ具有相同的结构,并且fξ的参数是fθ的动量移动平均值,通过:ξ-βξ+(1-β)θ,其中动量β∈[0,1]。基于以上,自EMD的损失函数定义为:
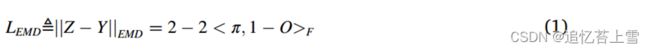
其中Z是由在线网络(预测)预测的视图Γ的特征张量,Y是由目标网络(地面实况)编码的视图Ⅶ’的特征张量。之间的最优运输问题定义为从供应商X到需求方Y的运输损失的最小值,其中π是运输策略矩阵,O是运输损失矩阵,<•,•>F表示两个矩阵之间的Frobenius内积。损失函数LEMD是在求解矩阵π和O的前提下工作的。接下来,我们将阐明如何计算它们。首先,将两个特征张量X,Y∈RH×W×C展平为两个局部向量集:X=[x1,x2,…,xHW],Y=[y1,y2,…,yHW],xi,yj∈RC,其中H,W,C分别表示特征张量的通道的高度、宽度和数量。假设每个供应商xi总共需要运输ai特征单元,每个需求方yj总共需要bj个特征单元。我们的目标是找到一个运输策略π∈R+HW×HW,通过以下方式将从所有供应商X到所有需求方Y的运输损失降至最低:

其中O∈RHW×HW是传输损耗矩阵,ai,bj是边际权重。Oij表示从xi到yj的传递损失,表示方式相似的特征单元之间的传输损耗较少。接下来,可以通过添加熵正则化项来找到方程(2)的近似解,如方程(3)所示:

其中∊是正则化因子,它控制正则化的强度。然后,具有正则化项的最优传输策略π*记为:

其中Q=e-C/∊,向量p和Q可以通过使用Sinkhorn Knopp算法的快速迭代来求解(Cuturi,2013)。当预训练完成时,只保留编码器fθ来生成油菜图像的可靠特征表示,用于随后的亚健康区域检测。然而,由于YOLOX的颈部包含三个尺度的特征管道,因此开发了一种称为多尺度EMD的多尺度预训练策略。如图7所示,MS-EMD可以并行学习特征张量的三个尺度,它们将被输入头部,以检测小、中、大尺度的亚健康区域。因此,MS-EMD的损失函数表示为。

其中LEMD遵循方程(1),上标1、2和3分别表示小尺度、中尺度和大尺度。MSEMD的优点如下。(1) MS-EMD允许网络并行优化多尺度特征张量,以清楚地理解不同尺度之间表示的一致性;(2) 在不破坏多尺度特征张量的语义空间的情况下,预训练的主干可以与三特征管道中的颈部和头部直接匹配。通过这样做,可以完全保留油菜上预先提取的亚健康区域的细粒度特征,有助于提高后续的检测精度。

3.4. 协调对不规范问题的关注
正如我们之前所讨论的,不规范的性质导致难以代表油菜亚健康区域的特征。目前,面向通道的注意力机制,如SENet(Hu et al.,2018)、CBAM(Woo et al,2018)已被广泛用于增强深度视觉模型的特征表示能力。然而,这些方法不适用于局部任务(例如,目标检测、实例分割),因为它们在高度和宽度维度上的全局池化操作破坏了对象的语义空间。因此,我们转向一种新的坐标注意(CA)机制(Hou et al,2021),它能够保存空间结构和位置信息。具体而言,将CA块作为计算单元插入U3 YOLOX的颈部网络中,如图6所示。接下来,我们将描述CA如何在U3YOLOX中工作。
CA块可以将任何中间特征张量X∈RH×W×C作为输入,然后输出与X具有相同维度的增强张量E,如图8所示。具体而言,CA块由以下两个操作组成:
协调信息嵌入。由于全局池化将高度和宽度压缩到通道描述符中,因此很难保留空间和位置信息。在CA中,使用两个独立的池化内核(H,1)和(1,W)分别沿水平和垂直坐标对每个通道进行池化。接下来,通过沿着通道的特征聚合,可以获得一对方向感知特征图oh∈RH×C和ow∈RW×C。
协调注意力的产生。为了充分利用捕获的空间和位置信息,将这对特征图连接起来,然后用卷积核进行变换:

其中[•,•]表示串联运算。f∈RC/r×(H+W)是具有融合的高度和宽度信息的中间特征图,r是用于减少通道数量的缩减率。然后,将f分解为高度特异性特征映射fh∈RC/r×h和宽度特异性特征图fw∈RC/r×W。此外,利用(1,1)卷积核将这两个特征映射分别转化为两个注意映射gh∈RC/r×H和gw∈RC/r×W。特别地,gh c∈RH,gw c∈RW是第c通道的注意向量,gh c(i),gw c(j)表示在第c个通道中的特征点(i,j)处的特征张量X的注意力权重。因此,增强特征向量E的第c通道的输出为:

其中,Xc(i,j)表示输入特征张量X中第c通道的特征点(i,j)。对于油菜上的亚健康区域,CA利用两个方向感知注意力图来显式地对无规则对象在高度和宽度上的复杂模式进行建模,同时用细粒度的注意力向量为每个特征点分配差分权重。CA可以帮助U3 YOLOX更准确地发现和定位亚健康区域。

3.5. 不平衡问题的焦点EIoU和焦点损失
YOLOX的头部被解耦为两个部分:定位头部和分类头部。正如我们之前所讨论的,定位头面临低质量/高质量边界框不平衡问题,分类头面临易样本/硬样本不平衡问题。接下来,我们将详细介绍我们在U3 YOLOX中的解决方案。
•定位头量化了预测边界框和人工标签之间的差异。然而,YOLOX中的IoU只量化了预测和人工标签之间的重叠区域,忽略了许多有用的定位信息,如坐标偏移。在U3 YOLOX中,EIoU被用来代替IoU,添加预测和地面实况之间的质心距离和宽度-高度差,以实现更准确的量化。为了进行清楚的比较,从IoU到EIoU的改进如图9(a)所示。EIoU的计算过程如下:
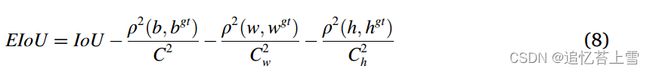
其中ρ2(•,•)表示欧几里得距离函数,(b,w,h)和(bgt,wgt,hgt)分别是预测和地面实况的中心、宽度和高度。C是两个边界框的最小外部矩形的对角线长度,Cw和Ch分别是该矩形的宽度和高度。然而,亚健康区域是不规则的次要对象,这导致在训练期间大多数预测都是低质量的(即EIoU非常低的边界框)。为了避免这种不平衡导致的模型崩溃,在损失函数中使用Focal EIoU(Zhang et al,2021)来自适应地提高高质量边界框的权重,并抑制低质量边界框。损失函数如下:

其中γ是控制权重的参数。在上述等式中,IoU被用作质量指示符。具体来说,对于IoU较小的低质量边界框,其权重IoUγ会较小,旨在减少低质量带来的损失;相反,对于具有大IoU的高质量边界盒,其权重IoUγ将更大,以提供更多的高质量损失。通过这样做,Focal EIoU可以确保高质量的边界框为优化提供更多贡献,避免模型崩溃并加速收敛。
•分类头识别边界框中对象的类别(即油菜的亚健康区域)。以边界框为样本,简单样本非常容易分类,如图9(b)所示。然而,大量的易样本对优化效率低下,导致无法训练分类头的识别能力。例如,在训练过程中,简单样本与硬样本的比例约为1000:1。因此,由于忽略了不同样本的重要性,YOLOX的损失函数中的交叉熵(CE)是不够的。CE的公式如下:

其中y是样本的基本真值,y′是预测样本属于某一类别的概率。我们注意到CE中的所有样本都是同等权重的。油菜的亚健康区域通常很小,因此图像中的大量像素属于背景,这导致大量易样本压倒了少量硬样本的有效利用。为此,将CE替换为Focal Loss(Lin et al,2017b),该方法可用于自适应调整易样本和难样本的权重,包括阳性样本和阴性样本:

其中,α是一个预先固定的值,用于平衡正样本和负样本,这是平衡类别的最常见方法之一。此外,加权项(1¶y′)γ/y′γ平衡了易样本和难样本。例如,对于任何阳性样本(y=1),简单阳性样本的y′较大,例如y′=0.9,因此(1¶y′)γ削弱了其重量;硬阳性样品的y′较小,例如y′=0.3,因此(1¶y′)γ增加了其重量。γ通常采用大于1的值,例如,γ=2。上述分析也适用于阴性样本(y=0)的情况。

4. 实验结果与分析
4.1. 模型性能评估
为了定量评估模型在不同方面的性能,我们选择了三个常用的评估指标AP、准确度和召回率。具体而言,模型的预测包含四种状态:真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)。如图10所示,混淆矩阵显示了特定类别中预测与地面实况之间的关系。因此,评价指标的公式可以写成:
P(精度):

R(召回率):

AP(平均精度):

4.2. 实施细节
我们的实验是在64位windows系统上进行的,该系统采用NVIDIA GeForce GTX 1080Ti GPU,内存为11GB。软件选择python 3.8作为编程语言,pytorch 1.10作为深度学习框架。采用采集的油菜图像作为实验数据,将输入大小归一化为640×640×3,详见第2节。MS-EMD预训练基于所有实验数据,然后按照7:1:2的比例划分训练集:验证集:测试集。选择随机梯度下降(SGD)优化器通过反向传播来训练整个模型。此外,颈部和头部网络的参数是通过从均值=0且方差=1的高斯分布中采样来随机初始化的。骨干网络的参数是由自监督任务MS-EMD预先训练的,而不是从ImageNet分类任务中转移的,这与以前的大多数工作有根本不同。由于边缘计算设备(即1080Ti GPU)的计算能力限制,批量大小只能设置为4。学习率采用预热和余弦退火策略(Ge等人,2021)。具体而言,在前3个时期,初始学习率从0.0001上升到0.001,然后遵循余弦函数,最大T=5在[0.0001,0.001]内波动。此外,重量衰减为0.0005,SGD动量为0.9。epoch的最大值设置为100。同时,与之前的工作(Dai等人,2022a)类似,采用patience为3的早停机制(early stopping)来避免过拟合,这可以在验证集中的损失连续增加3个时期时停止训练。我们的模型在每个时期都会保存,其中只有性能最好的一个作为最终模型保存。
4.3. 消融实验
4.3.1 MS-EMD的作用
YOLOX作为一种最先进的轻型探测器,适用于智能农业中的物体检测。然而,最初的YOLOX是在没有预先训练的情况下建立的,因此无法解决油菜亚健康区域的罕见问题。为了说明这一点,YOLOX在表1中采用不同的预训练策略,包括变体1、2、3和4。具体而言,变体1没有预训练,变体2从ImageNet分类中转移学习,而变体3和4分别使用自EMD和MS-EMD方法在我们收集的油菜数据集上进行预训练。实验结果的可视化如图11所示,我们的分析如下:
•与变体1相比,变体2的改善很小,mAP仅为0.16%。换句话说,在ImageNet分类上进行预训练仅比不进行预训练好0.16%。这一结果支持了我们的假设,即在ImageNet等开源数据集上的迁移学习对于农业任务来说效率低下。
•变体3显示,与变体2相比,mAP增加了0.7%。这一结果支持,与开源数据集相比,农业数据集上的自我监督预训练能够提取更可靠的特征。这是因为自监督方法侧重于挖掘特定领域数据集中的基本模式,而不是一般特征。
•变体4实现了最佳性能,与变体3相比,mAP增加了1.13%。为了证明MSEMD的优势,U3 YOLOX的关键中间层的特征图如图所示。12。我们发现,卷积核很好地捕捉到了油菜的轮廓、颜色和纹理,并且在特征图中清晰地区分了亚健康区域。此外,头部网络的三个尺度清楚地捕捉到了从粗到细的不同粒度的特征。因此,MS-EMD是检测油菜亚健康区域的最佳预训练策略,它提供了高质量的特征来支持U3-YOLOX,以缓解不常见的问题。


4.3.2. 协调注意力的作用
虽然 MS-EMD 预训练提高了特征的质量,但亚健康区域的形状、大小和颜色变化极大,我们的检测任务仍然面临不规则问题。
如图13所示,小物体的频繁缺失导致更多的假阴性样本损害了回忆;复杂背景的检测误差导致更多的假阳性样本损害了精度。为了缓解不规则问题,将坐标注意力(CA)块插入颈部网络,以融合特征张量中的空间、位置和通道信息,从而更好地进行检测。在图13中,发现具有CA块的U3 YOLOX的检测结果明显优于没有CA的U3,其中检测到遗漏的小对象并排除错误对象。这是因为CA块在保留了空间和定位信息的情况下构建了方向感知注意力图,这为图像中的特征点分配了可微分的注意力权重。换句话说,CA块自适应地高亮显示小对象,同时过滤掉复杂的背景。

此外,如图14所示, CA块的插入在所有预训练策略下都带来了积极的效用,尤其是对于改进最高的MSEMD,mAP增加了2.59%。这是因为颈部具有CA块的多尺度流水线与多尺度EMD预训练提供的特征兼容。令人惊讶的是,如表1中的变体5所示,CA的添加显著地将yellow_rape类别的平均准确率从93.24%提高到98.63%。由于大多数Unregular对象属于yellow_rape类别,因此显著的改进进一步说明了CA缓解Unregular问题的有效性。最后,值得注意的是,CA块的参数大小和计算成本非常小,以至于可以忽略,因此插入CA块是非常高效和有效的。
4.3.3. 焦点损失和焦点EIoU的影响
正如我们之前所讨论的,我们的任务中仍然存在不平衡问题。如表2所示,在IoU&Cross熵下,在spot_rape类别中注意到了一个严重的问题,其中预测样本的数量(即852)小于地面实况样本的数目(即896)。在这种情况下,不可能检测到所有真正的亚健康区域。这是由于训练期间的梯度是由大量低质量的边界框和简单样本提供的,这导致模型的检测能力下降。

模型训练过程中损失的变化如图15所示。发现低质量梯度使得IoU和Cross熵的损失急剧振荡,并且仅收敛到大约0.15。因此,IoU和交叉熵被焦点EIoU和焦点损失取代,自适应地增加了高质量边界框和硬样本的权重。在图15中,很明显,焦点EIoU的损失和焦点损失下降得更快、更稳定,收敛性接近0。为了显示我们的优势,图16中绘制了训练阶段整体损失的方框图。焦点EIoU和焦点损失(又名红框)具有以下优点:
•红色方框更平坦,表示损失更稳定。
•红框有更多的异常点,这表明损失下降得更快。


•红框的边界值较小,下限值更接近0,这表明损失收敛得更好。
同时,在表2中,焦点丢失鼓励模型从困难模式中学习分类,从而使spot_rape类别上的积极预测数量从852个大大增加到966个,召回率从82.31%显著增加到92.61%。此外,焦点EIoU的严格定位损失滤除了阳性预测中的许多假阳性,导致准确率略有下降(从86.57%降至85.92%)。最后,焦点EIoU和焦点损失将模型的mAP从90.95%显著提高到94.38%,这主要得益于spot_ape类别召回率的上升。
4.3.4. 数据增强的效果
数据扩充的实施通常源于两个考虑:(1)通过合法扩展原始数据集来提供更多的训练数据;(2) 通过适当地增加数据噪声来提高模型的鲁棒性。为了支持这两种考虑的有效性,数据扩充策略被依次删除,以构建不同的修订数据集:
•-噪声意味着去除了420张含盐噪声的图像,数据集中剩余2580张图像;
•-混合意味着去除810个具有混合的图像,数据集中剩余2190个图像;
•-马赛克意味着去除810幅带有马赛克的图像,数据集中剩余2190幅图像;
•-剪切混合意味着去除960张带有剪切混合的图像,数据集中剩余2040张图像;•-这一切都意味着960张采集的图像没有数据扩充。
然后,使用修正后的数据集对U3 YOLOX和YOLOX的参数进行优化,实验结果如图17所示。首先,值得注意的是,mAP的减少与图像数量的减少呈正相关(虚线),其中最低的mAP对应于最少的图像数量(即-All:没有任何数据扩充)。我们认为,如果没有足够的数据,很难很好地训练深度神经网络,并且去除任何类型的数据增强技术都会减少有价值的数据。
其次,如图17中的条形图所示,去除任何一个数据扩充都会降低模型的mAP,这表明数据扩充提高了模型的鲁棒性。由于四种数据扩充具有不同的语义模式,因此它们在健壮性方面实现了不同程度的改进。具体来说,Cutmix,它剪切目标图像中的一部分像素,并用辅助图像中的部分像素填充它们,实现了最大的改进;噪声均匀地掩盖了目标图像中的像素,实现了最小的改进。一般来说,由于打破了固定的数据依赖关系,更复杂的模式可能具有更好的扩充实用性。
4.4. 与baseline的比较
在本节中,将现有的深度对象检测器作为油菜亚健康区域检测任务的基线,如RCNN系列和YOLO系列,并将其性能与我们的U3 YOLOX进行比较。为了进行公平比较,所有基线的输入大小被归一化为640×640×3;然后,对基线进行训练,直到它们的损失收敛,并利用网格搜索来找到它们的最佳参数组合。为了评估基线在油菜亚健康区域检测任务中的效率,还报告了模型大小和推理延迟的结果。总体实验结果如表3所示。
对于包括Faster RCNN和Mask RCNN的两级检测器,用于检测亚健康区域的mAP值高于单级检测器。然而,两级检测器的效率较差,因为它们在1080ti GPU上的推理延迟接近每张图像300ms。高延迟的原因是RCNN中的区域建议网络,它需要使用选择性搜索或卷积神经网络额外生成区域建议。值得注意的是,区域建议网络允许RCNN在没有特殊预训练策略和注意力块的情况下实现更高的mAP。
对于包括YOLOv3、YOLOv4、YOLOv5和YOLOX在内的一级检测器,由于简化了网络结构,它们的推理延迟显著小于两级检测器。此外,包括YOLOv3tiny、YOLOv4tiny、YOLOv5s和YOLOX在内的轻量级单级检测器,以牺牲mAP为代价,将每张图像的推理延迟降低到33毫秒以内,实现了“实时检测”。然而,如图13(a)(b)(c)(d)所示,经典的轻量级检测器(例如YOLOX)对油菜的小亚健康区域(即假阴性样本)不敏感,并且容易被复杂的背景(即假阳性样本)误导。这两种类型的阴性样品的增加是YOLOX的低mAP的原因。轻量级检测器的主干特征提取能力不足,颈部难以融合多尺度特征。因此,设计了多尺度自监督预训练MS-EMD来提高骨干特征的质量,并引入坐标注意力块来有效融合特征张量中的空间、位置和通道信息,以支持检测。此外,引入了焦点EIoU和焦点损失,以加快损失的收敛速度,提高检测器的识别能力。如图6所示,如图13(e)(f)(g)(h)所示,我们的U3-YOLOX有效地减少了上述阴性样本,并提高了油菜亚健康区域的检测性能。关于评估指标,如表3所示,作为一种轻量级检测器,我们的U3 YOLOX(模型大小71.1MB,mAP 94.38%,每张图像20.4ms)实现了与大型检测器YOLOv4(模型大小245.8MB,mAP 9486%,每张图像46.5ms)相当的性能,并且具有较低的推断延迟。以上结果表明,我们设计的 U3 YOLOXs 是用于油菜亚健康区域检测任务的最佳综合模型。


4.5. MS-EMD的一般研究
预训练策略是影响深部目标探测器性能的关键因素之一。在本节中,将开发的MS-EMD方法用于现有的基线,并测试它是否会带来有意义的改进。如图6所示,18,MSEMD方法的添加导致油菜亚健康区域检测任务的所有基线的性能提高。如表4所示,在MS-EMD预训练后,FastRCNN的最小改进为0.62%,YOLOX的最大改进为1.99%。值得注意的是,ImageNet分类对迁移学习的改进仅为0.16%(如表1所示),而MS-EMD带来的最小改进是它的3倍。因此,与主流迁移学习相比,所开发的MS-EMD预训练对许多现有模型都是有效和通用的。我们对结果的分析如下:
•一级探测器的改进明显高于两级探测器。这是因为YOLO系列都包含多尺度特征管道,MS-EMD能够确保每个尺度的高质量特征图。
•YOLOX和YOLOX的改进高于其他单级探测器。这是因为解耦头允许独立地优化定位和分类的子任务,而其他模型中的耦合头只能组合优化。因此,与解耦头部相比,耦合头部很难收敛到全局最优。
•MaskRCNN的改进高于FasterRCNN。这是由于与FasterRCNN的简单卷积网络相比,MaskRCNN的像素级掩码网络从特征图级别的MS-EMD预训练中受益更多。
总之,我们改进的自监督预训练方法MSEMD在经典的目标检测模型上是有效的,特别是对于轻量级的YOLO系列。


4.6. 农业生产可行性研究
农业生产中的目标检测有三个实际要求:(1)边缘计算设备存储容量小,计算能力低,因此部署的目标检测器的模型大小受到限制。(2) 目标检测器必须实现实时推断,即每个图像的推断延迟小于或等于33ms。(3) 物体检测器的精度是尽可能高的。如表1所示,我们的U3 YOLOX在1080ti GPU上具有94.38%的mAP,每张图像的推理延迟为20.4ms,模型大小为71.1MB,基本满足上述实际要求。为了验证我们的U3 YOLOX在农业生产中的可靠性,图19显示了所有一级检测器的mAP值与推断延迟的关系。发现U3-YOLOX的mAP值与大型探测器YOLOv4和YOLOv5相当,而模型尺寸仅为其尺寸的1/4。同时,U3 YOLOX可以实时检测,而YOLOv4和YOLOv5则不能。此外,发现对象检测器的准确性和推理延迟是矛盾的,一个变得更好,另一个变得更差。在图19中,我们的U3 YOLOX在准确性和推理延迟之间实现了最佳权衡:与YOLOX相比,我们的mAP增加了8.01%,而每个图像的推理延迟仅增加了0.7ms。这是因为MS-EMD、CA块和局灶EIoU和局灶损失的参数增量小到可以忽略,这种优势对于检测油菜的亚健康区域至关重要。

5. 实验评估
本文提出了一种轻量级的对象检测器U3YOLOX来检测油菜的亚健康区域。由于实际农业生产中面临的不常见、不规范和不平衡的挑战,在YOLOX模型的基础上进行了许多改进。具体而言,开发了一种称为MS-EMD的特征图级多尺度自监督策略,以预训练有效的主干,从而缓解特定领域数据集中的不常见问题。然后,将坐标注意力块插入多尺度颈部,以自适应地融合来自特征张量的空间、位置和通道信息,从而更好地进行非规则区域检测。最后,将IoU和交叉熵替换为焦点EIoU和焦点损失,以缓解低质量/高质量边界框和易样本/硬样本的不平衡问题。实验结果表明,U3 YOLOX在斑点油菜类中的AP值为90.09%,在黄色油菜中为98.67%,在mAP中为94.38%。此外,U3 YOLOX的模型大小为71.1MB,每张图像的推理延迟为20.4ms,满足了边缘设备实时检测的需求。
未来,我们将从两个角度重点推进这项研究。首先,我们将在植物工厂培育更多种类的叶绿作物,并研究如何将我们的模型推广到不同种类的叶青作物中。然后,U3 YOLOX探测器将部署到工厂的环境控制平台上,实现从视觉到控制的环境自动调整。例如,斑点油菜和黄色油菜的出现可能是由于营养液中缺乏氮和镁,平台可以在检测到油菜上的亚健康区域后自动调整营养液比例。