RAG相关内容介绍
本文记录在查找RAG相关内容时所整合的一些资料与内容,还有一个组会报告的PPT
文章目录
- 定义
-
- LLM的知识更新难题
- RAG是什么?-“开卷考试”
- RAG原理与技术
-
- RAG技术细节
-
- 一、数据索引
-
- • 数据提取
- • 分块(Chunking)
-
- 分块方式
- 确定应用程序的最佳块大小
- 影响分块策略的因素
- • 向量化(embedding)
- 二、检索环节(Retriever)
- 三、生成(Gen)
- 大模型+检索增强
-
- 检索增强模型Atlas
- YuLan-RETA-LLM
- Self-RAG( Self-Reflective Retrieval-Augmented Generation )
- 其他一些模型
- RAG优缺点与改进
- 提高RAG性能
- 其他
- 组会PPT
定义
LLM的知识更新难题
在进入RAG的介绍之前,需要首先理解一个概念:LLM的知识更新是很困难的,主要原因在于:
- LLM的训练数据集是固定的,一旦训练完成就很难再通过继续训练来更新其知识。
- LLM的参数量巨大,随时进行fine-tuning需要消耗大量的资源,并且需要相当长的时间。
- LLM的知识是编码在数百亿个参数中的,无法直接查询或编辑其中的知识图谱。
因此,LLM的知识具有静态、封闭和有限的特点。为了赋予LLM持续学习和获取新知识的能力,RAG应
运而生。
RAG是什么?-“开卷考试”
检索增强生成(RAG,Retrieval Augmented Generation)
顾名思义,在我的理解中,RAG就是通过引入外部知识语料(数据库,现有文档等),增加生成模型的检索能力,并通过知识库中的检索到的相关知识结合LLM进行生成问题的答案。
在问答和对话的场景下,通常可以通过检索和生成两种方式得到一个回复。检索式回复是在外部知识库中检索出满意的回复,较为可靠和可控,但回复缺乏多样性;而生成式回复则依赖于强大的语言模型中储存的内部知识,不可控,解释性差,但能生成更丰富的回复。把检索和生成结合起来,Facebook AI research 联合 UCL 和纽约大学于 2020 年提出:外部知识检索加持下的生成模型,Retrieval-Augmented Generation (RAG) 检索增强生成。
- 检索:这是指系统搜索庞大的数据库或存储库以查找相关信息的过程。
- 生成:检索后,系统生成类似人类的文本,整合获取的数据。
检索增强生成(RAG,Retrieval Augmented Generation)检索增强生成是用从其他地方检索到的附加信息来补充用户输入到大型语言模型 (LLM)(例如 ChatGPT)的过程。然后,LLM可以使用该信息来增强其生成的响应。它结合了一个检索系统和一个LLM,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。
检索增强方法来克服大型语言模型(Large Language Model)的局限性,比如幻觉问题(胡言乱语)和知识有限问题(常用于补充最新知识、公司内部知识)。检索增强方法背后的思想是维护一个外部知识库,在提问时检索外部数据,并将其提供给LLM,以增强其生成准确和相关答案的能力。
RAG不仅仅面向文本,它还可以面向语音、视频和图像等多模态场景,只要可以embedding的内容就可以,有关多模态RAG我也看了一个综述,也是未来发展趋势之一,不过还有许多问题需要解决,比如:如何将多模态知识索引映射到一个统一的空间仍然是一个长期的挑战。RAG 也有一些局限性。例如,在归因和流畅性之间存在权衡 (Aksitov et al. 2023),由于检索知识的额外限制,输出质量会受到影响。
RAG原理与技术
我们对RAG可以总概方式地理解为“索引、检索和生成”。
RAG的主要组成:用户提问——数据提取——embedding(向量化)——创建索引——检索——自动排序(Rerank)——LLM归纳生成。
RAG技术细节
一、数据索引
• 数据提取
o 数据清洗:包括数据Loader,提取文档存储库:PDF、word、markdown以及网页抓取、实时数据库和API等;
o 数据处理:包括数据格式处理,不可识别内容的剔除,压缩和格式化等;
o 元数据提取:提取文件名、时间、章节title、图片alt等信息,非常关键。
• 分块(Chunking)
我们在向量数据库中索引的任何内容都需要首先向量化。分块的主要目的是为了确保我们向量化的内容尽可能少,但在语义上仍然相关。
分块注意事项
•被索引的内容的性质是什么?是否正在处理长文档(例如文章或书籍)或较短的内容(例如推文或即时消息)?答案将决定哪种模型更适合目标,以及应用哪种分块策略。
•使用哪种向量化模型,它在什么块大小上表现最佳?例如,sentence-transformer模型在单个句子上效果很好,但像text-embedding-ada-002这样的模型在包含 256 或 512 的块上表现更好。
•对用户查询的长度和复杂性有何期望?它们会简短而具体,还是长而复杂?这也可能会告诉你选择对内容进行分块的方式,以便嵌入式查询和嵌入式块之间有更紧密的相关性。
•检索到的结果将如何在特定应用程序中使用?例如,它们会用于语义搜索、问答、摘要或其他目的吗?例如,如果结果需要输入到具有令牌限制的另一个 LLM 中,必须考虑到这一点,并根据想要适应请求的块数量来限制块的大小
分块方式
o 固定大小的分块方式:一般是256/512个tokens,取决于embedding模型的情况。但是这种方式的弊端是会损失很多语义,比如“我们今天晚上应该去吃个大餐庆祝一下”,很有可能就会被分在两个chunk里面——“我们今天晚上应该”、“去吃个大餐庆祝一下”。这样对于检索是非常不友好的,解决方法是增加冗余量,比如512tokens的,实际保存480tokens,一头一尾去保存相邻的chunk头尾的tokens内容;
基于意图的分块方式:
o 句分割:最简单的是通过句号和换行来做切分。当然也有通过专业的意图包来切分的,常用的意图包有基于NLP的NLTK和spaCy;
o 递归分割:通过分而治之的思想,用递归切分到最小单元的一种方式;
确定应用程序的最佳块大小
如果常见的分块方法(如固定分块)不容易适用于当前用例,这里有一些指针可以帮助找到最佳的块大小:
– 预处理数据:在确定应用程序的最佳块大小之前,需要首先预处理数据以确保质量。例如,如果数据是从网络检索的,可能需要删除 HTML 标签或增加噪音的特定元素。
– 选择块大小范围:数据经过预处理后,下一步是选择要测试的潜在块大小范围。如前所述,选择时应考虑内容的性质(例如,短消息或冗长的文档)、使用的向量化模型及其功能(例如,长度限制)。目标是在保留上下文和保持准确性之间找到平衡。首先探索各种块大小,包括用于捕获更细粒度语义信息的较小块(例如,128 或 256 个tokens)和用于保留更多上下文的较大块(例如,512 或 1024 个tokens)。
– 评估每个块大小的性能:为了测试各种块大小,可以使用多个索引或具有多个命名空间的单个索引。使用代表性数据集,为要测试的块大小创建嵌入并将它们保存在索引中。然后,可以运行一系列查询,可以评估其质量,并比较不同块大小的性能。这很可能是一个迭代过程,可以针对不同的查询测试不同的块大小,直到可以确定内容和预期查询的最佳性能块大小。
影响分块策略的因素
o 取决于索引类型,包括文本类型和长度,文章和微博推文的分块方式就会很不同;
o 取决于模型类型:你使用什么LLM也会有不同,因为ChatGLM、ChatGPT和Claude.ai等的tokens限制长度不一样,会影响你分块的尺寸;
o 取决于问答的文本的长度和复杂度:最好问答的文本长度和你分块的尺寸差不多,这样会对检索效率更友好;
o 应用类型:RAG的应用是检索、问答和摘要等,都会对分块策略有不同的影响。
• 向量化(embedding)
这是将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解的格式,embedding模型的好坏会直接影响到后面检索的质量,特别是相关度。

目前比较好的embedding模型有这些:
– BGE:该模型可以将任何文本映射到低维密集向量,这些向量可用于检索、分类、聚类或语义搜索等任务。此外,它还可以用于LLMs的向量数据库。
– GTE:它基于BERT框架构建,并分为三个版本。该模型在大规模的多领域文本对语料库上进行训练,确保其广泛适用于各种场景。因此,GTE可以应用于信息检索、语义文本相似性、文本重新排序等任务。
– E5-embedding:E5的设计初衷是为各种需要单一向量表示的任务提供高效且即用的文本Embedding,与其他Embedding模型相比,E5在需要高质量、多功能和高效的文本Embedding的场景中表现尤为出色。
– Jina Embedding:它基于Jina AI的Linnaeus-Clean数据集进行训练,这是一个包含了3.8亿对句子的大型数据集,涵盖了查询与文档之间的配对。这些句子对涉及多个领域,并已经经过严格的筛选和清洗。
– Instructor:该模型可以生成针对任何任务(例如分类、检索、聚类、文本评估等)和领域(例如科学、金融等)的文本Embedding,只需提供任务指导,无需任何微调。
– XLM-Roberta:它是在大量的多语言数据上进行预训练的,目的是为了提供一个能够处理多种语言的强大的文本表示模型。XLM-Roberta模型在多种跨语言自然语言处理任务上都表现出色,包括机器翻译、文本分类和命名实体识别等。
– Text-embedding-ada-002:该模型提供了一个与Hugging Face库兼容的版本的text-embedding-ada-002分词器,该分词器是从openai/tiktoken适应而来的。这意味着它可以与Hugging Face的各种库一起使用,包括Transformers、Tokenizers和Transformers.js。
二、检索环节(Retriever)
检索环节一般分为下面五部分工作:
• 元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度。比如,我们问“帮我整理一下XX部门今年5月份的所有合同中,包含XX设备采购的合同有哪些?”。这时候,如果有元数据,我们就可以去搜索“XX部门+2023年5月”的相关数据,检索量一下子就可能变成了全局的万分之一;
• 图关系检索:如果可以将很多实体变成node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。特别是针对一些多跳问题,利用图数据索引会让检索的相关度变得更高;
• 检索技术:前面说的是一些前置的预处理的方法,检索的主要方式还是这几种:
o 相似度检索:相似度算法:包括欧氏距离、曼哈顿距离、余弦距离等。

o 关键词检索:刚才我们说的元数据过滤也是一种关键词检索,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率。据说Claude.ai也是这么做的;
o SQL检索:对于一些本地化的企业应用来说,SQL查询是必不可少的一步,比如销售数据,就需要先做SQL检索。
• 重排序(Rerank)
很多时候我们的检索结果并不理想,原因是chunks在系统内数量很多,我们检索的维度不一定是最优的,一次检索的结果可能就会在相关度上面没有那么理想。这时候我们需要有一些策略来对检索的结果做重排序,比如使用planB重排序,或者把组合相关度、匹配度等因素做一些重新调整,得到更符合我们业务场景的排序。因为在这一步之后,我们就会把结果送给LLM进行最终处理了,所以这一部分的结果很重要。这里面还会有一个内部的判断器来评审相关度,触发重排序。
• 查询轮换
这是查询检索的一种方式,一般会有几种方式:
– 子查询:可以在不同的场景中使用各种查询策略,比如可以使用LlamaIndex等框架提供的查询器,采用树查询
(从叶子结点,一步步查询,合并),采用向量查询,或者最原始的顺序查询chunks等;
– 重新表达:如果系统找不到与查询相关的上下文,可以让LLM重新表达查询并重试。两个在人类看来相同的问题
在嵌入空间中不一定看起来很相似。
– HyDE(Hypothetical Document Embeddings):通过假设答案生成的丰富且细致入微的嵌入来强化信息检索,生
成相似的或者更标准的prompt模板。
三、生成(Gen)
生成部分包括内部运转的驱动器,ReAct,Prompt优化工程,框架。
这一步真正发挥巨大作用的是LLM,有许多现成框架:如Langchain和LlamaIndex等,一旦检索到相关数据,就会连同用户的查询或任务一起传递给生成器(LLM)。LLM 使用检索到的数据和用户的查询或任务生成输出。输出结果的质量取决于数据的质量和检索策略。生成输出结果的指令也会对输出结果的质量产生很大影响。
因为有许多现成框架,我们更多需要关注的就是Prompt工程,在Prompt里面其实还是有很多决定因素的,这和大家对所处行业的knowhow有关。比如在文旅行业,你要知道游客或者观众一般会怎么提问,真正需要得到的是什么内容。
大模型+检索增强
这里介绍一些在网上查到的用检索增强生成的一些大模型:
论文题目:Few-shot Learning with Retrieval Augmented Language Models
论文链接
代码地址

首先是检索增强模型Atlas,它成功试验了检索增强在小样本学习中的应用我们介绍了Atlas,这是一个检索增强语言模型,在知识任务上表现出强大的小样本学习性能,并在预训练和微调期间使用检索。如图所示,该图用询问百慕大三角的位置作为例子解释了Atlas的运行过程,中间的生成的和百慕大三角位置最相关的文档内容:百慕大三角是一个城市传说,聚焦于北大西洋西部一个定义松散的地区。
在预训练时用Masked Language Modelling带掩码机制的语言模型:百慕大三角位于大西洋的某个地方,通过Atlas检索后mask部分为西部
在对于其他小样本学习时,比如事实核查:百慕大三角位于喜马拉雅山脉的西部。通过Atlas检索后回答为false
问题回答:百慕大三角在哪里?通过Atlas检索后回答为北大西洋西部
检索增强模型Atlas
Atlas 拥有两个子模型,一个检索器与一个语言模型。当面对一个任务时,Atlas 依据输入的问题使用检索器从大量语料中生成出最相关的 top-k 个文档,之后将这些文档与问题 query 一同放入语言模型之中,进而产生出所需的输出。
下图是知识密集型语言任务中不同任务的查询和输出对示例
谁将在2016年超级碗中场表演 coldplay
实体链接NTFS-3G是一个开源的跨平台实现的Microsoft Windows NTFS文件系统,具有读写支持。 跨平台软件
Atlas 模型的基本训练策略在于,将检索器与语言模型使用同一损失函数共同训练。检索器与语言模型都基于预训练的 Transformer 网络。
作者对比试验了四种损失函数以及不做检索器与语言模型联合训练的情况,结果如下图:

可以看出,在小样本环境下,使用联合训练的方法所得到的正确率显著高于不使用联合训练的正确率,因此,作者得出结论,检索器与语言模型的这种共同训练是 Atlas 获得小样本学习能力的关键。
其他一些实验结果大家感兴趣的可以自行查找论文进行学习:在大规模多任务语言理解任务,开放域问答,事实核查任务,自家发布的知识密集型自然语言处理任务基准上Atlas在小样本的表现都优于其他模型
YuLan-RETA-LLM
论文题目:WebBrain: Learning to Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus
论文地址
代码地址
大规模基准数据集:https://github.com/RUC-GSAI/YuLan-IR/tree/main/WebBrain
YuLan-RETA-LLM,是一个由中国人民大学高瓴人工智能学院的研究团队开源的一个检索增强大型语言模型的工具包。该工具包提供了请求改写、文档检索、段落提取、答案生成和事实检查等多个模块,旨在帮助LLM更好地使用检索。此外,工具包还提供了一个完整的流程,可协助研究人员和用户构建他们定制的领域内问答系统。下图是RETA-LLM的框架。
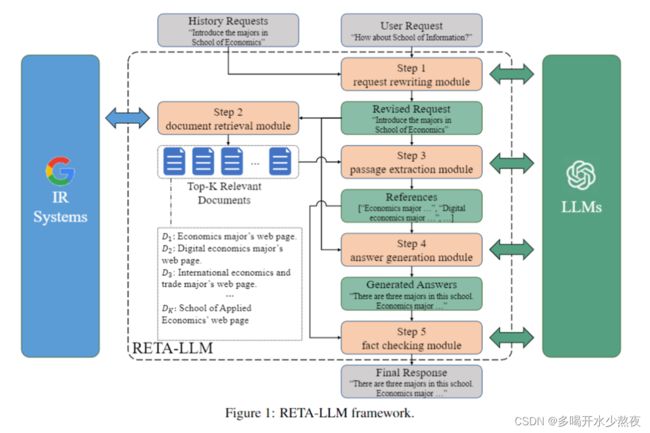
首先,RETA-LLM使用请求改写模块来修改当前用户请求,使其变得完整和清晰。由于用户会对RETA-LLM提出一系列问题,可能会出现当前请求的表述不完整的情况。例如,用户的当前的请求是“信息学院呢?”, 而其历史请求是”介绍经济学院的专业”。在这种情况下,用户实际希望进行的请求是“介绍信息学院的专业”。由于LLM在对话式稠密检索中表现出了出色的请求改写能力,在这一模块中,RETA-LLM将当前用户请求和之前的对话记录输入LLM进行请求改写。
其次,RETA-LLM使用文档检索模块从外部知识库中召回与改写后查询相关的文档。文档检索模块是与信息检索系统交互的模块,其利用改写后的用户请求,从外部知识库中召回相关的文档。
接下来,RETA-LLM使用段落提取模块抽取出文档与用户请求相关的片段,并将其组合为参考内容。由于本身具有输入长度限制(一般为2048或4096个token),LLM无法接受直接将所有相关的文档内容作为参考一并输入并生成回答。而如果直接将文档内容进行截断以符合输入长度限制,可能会损失其中的重要信息。为了解决这一问题,RETA-LLM再次利用LLM从检索到的文档中提取出相关的片段,以缩减输入的参考内容长度。由于单个文档的长度也可能超出LLM的输入限制,RETA-LLM中使用了滑动窗口策略逐段落地提取文档片段。在抽取完成后,RETA-LLM将抽取出的所有片段拼接作为参考内容。
之后,RETA-LLM使用答案生成模块生成对用户请求的回答。如先前研究结果所证明的,通过将检索到的参考资料输入LLM,可以生成事实更加准确的答案。
最终,RETA-LLM使用事实检查模块来验证生成的答案是否包含事实性错误,并输出符合用户请求的回答。尽管为答案的生成提供了额外的参考资料,LLM仍可能出现幻觉问题。因此,需要设计一个模块来进一步进行事实验证。由于LLM具有强大的自然语言理解能力,REAT-LLM将参考资料和生成的答案提供给它们来做出判断。最终,RETA-LLM可以决定是输出生成的答案还是说“我无法回答这个问题”。
注意到,对LLM的所有输入都被包裹在prompt中,以方便LLM对输入理解。如整体框架图中所示,研究团队在RETA-LLM中完全解耦了信息检索系统和LLM。这种分离式设计使得用户可以自定义其个人搜索引擎和LLM。
与以前的通用LLM增强工具包如LangChain等不同,RETA-LLM专注于检索增强大型语言模型,并提供了更多的插件模块。
通常,检索增强LLM使用具有两个模块的检索-生成两步策略:
除了对文档检索模块和答案生成模块的支持以外,RETA-LLM还提供了三个可选模块:
(1)请求改写模块,使用户当前的请求更加完整和清晰;
(2) 段落提取模块,用于从检索到的整个文档内容中提取相关段落或片段;
(3)事实检查模块,用于验证生成的答案中是否存在事实错误。
这些可选模块可以使信息检索系统和LLM之间的交互更加有效和顺畅。同时,在RETA-LLM中,LLM和检索系统之间的解耦更加彻底,这使得搜索引擎和LLM的定制更加方便。此外,为了让用户使用更容易,RETA-LLM为研究人员和用户提供了一个完整、即用的流程,以基于他们自己的资源库从头开始构建他们的RETA-LLM工具包,用于域内问题回答。
Self-RAG( Self-Reflective Retrieval-Augmented Generation )
论文题目:SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
论文链接
项目地址
最近的工作引入了一个名为"自我反思检索-增强生成"(SELF-RAG)的框架,通过检索和自我反思来提高LM的质量和事实性。
其思想在于,训练一个单一的任意LM,该LM可按需自适应性地检索段落,并使用特殊标记(称为反思标记)生成和反思检索到的段落及其自身的生成。反思标记的生成使LM在推理阶段具有可控性,使其能够根据不同的任务要求调整自己的行为。
具体来说,在给定输入提示和前几代的情况下,SELF-RAG首先会判断用检索到的段落来增强继续生成是否有帮助。如果有帮助,它就会输出一个检索标记,按需调用检索模型(步骤1)。
随后,SELF-RAG同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤2)。然后,它生成批判标记来批判自己的输出,并从事实性和整体质量方面选择最佳输出(第3步)。
这一过程不同于传统的RAG(图1左),后者无论检索的必要性如何(例如,下图示例不需要事实性知识),都会持续检索固定数量的文档进行生成,而且从不对生成质量进行二次检查。
此外,SELF-RAG还会为每个段落提供引文,并对输出结果是否得到段落支持进行自我评估,从而更容易进行事实验证。
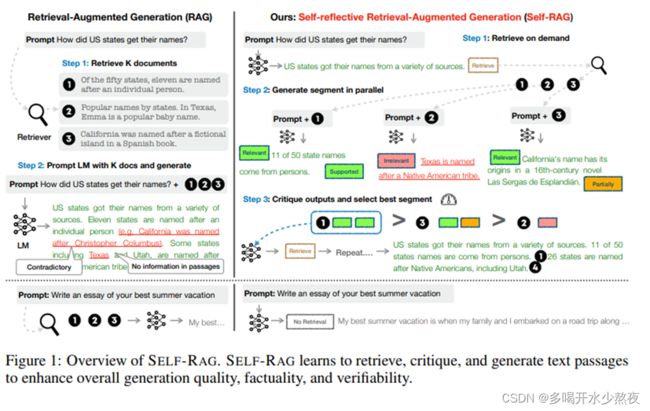
Self-RAG是一个新的框架,通过自我反射令牌(Self-reflection tokens)来训练和控制任意LM。它主要分为三个步骤:检索、生成和批评。
检索:首先,Self-RAG解码检索令牌(retrieval token)以评估是否需要检索,并控制检索组件。如果需要检索,LM将调用外部检索模块查找相关文档。
生成:如果不需要检索,模型会预测下一个输出段。如果需要检索,模型首先生成批评令牌(critique token)来评估检索到的文档是否相关,然后根据检索到的段落生成后续内容。
批评:如果需要检索,模型进一步评估段落是否支持生成。最后,一个新的批评令牌(critique token)评估响应的整体效用。
反射令牌(reflection tokens)


Self-RAG 的训练包括三个模型:检索器(Retriever)、评论家(Critic)和生成器(Generator)。
首先,训练评论家,使用检索器检索到的段落以及反射令牌增强指令-输出数据。
然后,使用标准的下一个 token 预测目标来训练生成器 LM,以学习生成 自然延续(continuations)以及特殊 tokens (用来检索或批评其自己的生成内容).
其他详细内容可以自己去网上查找相关论文或者公众号讲解,本篇PPT也有更具体的介绍。
其他一些模型
模型:REPLUG
论文题目:REPLUG: Retrieval-Augmented Black-Box Language Models
论文地址

模型:RETRO(Retrieval-Enhanced Transformer )
论文题目:Improving language models by retrieving from trillions of tokens
论文地址

模型:RALMs
论文题目:Making Retrieval-Augmented Language Models Robust to Irrelevant Context
论文地址
模型:RA-DIT
论文题目:RA-DIT: Retrieval-Augmented Dual Instruction Tuning
论文地址
RAG优缺点与改进
优点
•可以利用大规模外部知识改进LLM的推理能力和事实性。
•使用LangChain等框架可以快速实现原型。
•第一阶段的知识索引可以随时新增数据,延迟非常低,可以忽略不计。因此RAG架构理论上能做到知识的实时更新。
•可解释性强,RAG可以通过提示工程等技术,使得LLM生成的答案具有更强的可解释性,从而提高了用户对于答案的
信任度和满意度
优势
•增强的 LLM 内存。 RAG 解决了传统语言模型 (LLM) 的信息容量限制。
•改进的情境化。 RAG 通过检索和整合相关的上下文文档来增强对 LLM 的上下文理解。
•可更新内存。 RAG 的一个突出优势是它能够适应实时更新和新来源,而无需进行大量的模型重新训练。
•来源引用文献。 配备 RAG 的模型可以为其响应提供来源,从而提高透明度和可信度。
•减少幻觉。 研究表明,RAG 模型表现出更少的幻觉和更高的反应准确性。
缺点
•知识检索阶段依赖相似度检索技术,并不是精确检索,因此有可能出现检索到的文档与问题不太相关。
•在第三阶段生产答案时,由于LLM基于检索出来的知识进行总结,可能缺乏一些基本世界知识,从而导致无法应
对用户询问知识库之外的基本问题。
•向量数据库是一个尚未成熟的技术,缺乏处理大量数据规模的通用方案,因此数据量较大时,速度和性能存在挑战。
•在推理时需要对用户输入进行预处理和向量化等操作,增加了推理的时间和计算成本。
•外部知识库的更新和同步,需要投入大量的人力、物力和时间。
•需要额外的检索组件,增加了架构的复杂度和维护成本。
如何改进
•检查和清洗输入数据质量。
•调优块大小、top k检索和重叠度。
•利用文档元数据进行更好的过滤。
•优化prompt以提供有用的说明。
提高RAG性能
• 混合搜索:将语义搜索与关键词搜索结合起来,从向量存储中检索相关数据已被证明对大多数用例都能获得更好的结果。
• 摘要:对块进行摘要并将摘要存储在向量存储中,而不是原始块。例如,如果您的数据包含很多填充词,那么总结块以去除填充词并将摘要存储在向量存储中是一个好主意。这将改善生成质量,因为我们除了帮标记数量外还消除了数据中的干扰叠块:当将数据分割检索的块时,在语义搜索程中可能会选择具有相邻块相关和有用上下文信息的情况。如果没有周围上下文环境就直接传递该块给LLM进行生成,则可能导输出质量较差。为避免这种情况,我们可以将重叠部分传递给LLM进行生成。例如,如果我们将数据分割成100个标记大小的块,则可以通过50个标记大小来使这些块重叠。这样可以确保我们为LLM生成时传递了周围上下文信息。
• 微调嵌入模型:使用BERT、ada等现成的嵌入模型为数据块生成嵌入可能适用于大多数用例。但是如果您正在处理特定领域,请注意这些模型可能无法很好地表示该领域,在向量空间内导致检索质量较差。在这种情况下,我们可以对该领域内微调并使用一个自定义化后续使用embedding模型以提高检索质量。
• 元数据:提供关于上下文中传递的块的来源等元数据,将有助于LLM更好地理解上下文,从而产生更好的输出生成。
• 重新排序:在使用语义搜索时,可能会出现前k个结果相似的情况(Top-k)。在这种情况下,我们应该考虑根据其他因素(如元数据、关键词匹配等)对结果进行重新排序。
• 丢失问题:观察到LLMs并不给予输入中所有标记相同权重。中间标记似乎比输入开头和结尾处的标记被赋予较低权重。这被称为中间丢失问题。为了避免这种情况,我们可以重新排列上下文片段,使最重要的片段位于输入开头和结尾,并将次要片段放置在中间位置。
还可以通过探索不同的索引类型,尝试不同的分块方法,尝试不同的基本提示,使用查询路由,考虑查询转换等方式提高RAG性能。
其他
一些网上RAG代码和例子的搜集

此示例展示了通过索引进行问答。
https://python.langchain.com/docs/use_cases/question_answering/vector_db_qa
Retrieval-Augmented Generation (RAG) Applications with AutoGen
https://microsoft.github.io/autogen/blog/2023/10/18/RetrieveChat/
RAG-Token Model :Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
该模型由Question_encoder、检索器和生成器组成。检索器从上面链接的wiki_dpr数据集中提
取相关段落。 trainQuestion_encoder 和检索器基于facebook/dpr-question_encoder-single-nq-base和facebook/bart-large,它们以端到端的方式在wiki_dpr QA 数据集上联合微调。
https://huggingface.co/facebook/rag-token-nq#usage
在下面的使用示例中,仅使用wiki_dpr的虚拟检索器,因为完整的lecagy索引需要超过 75 GB 的 RAM。该模型可以生成任何事实问题的答案,如下所示:
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
input_dict = tokenizer.prepare_seq2seq_batch("who holds the record in 100m freestyle", return_tensors="pt")
generated = model.generate(input_ids=input_dict["input_ids"])
print(tokenizer.batch_decode(generated, skip_special_tokens=True)[0])
组会PPT
https://download.csdn.net/download/m0_52695557/88524980