mit6.824 2022 lab2
MIT6.824 2022 Raft
- Raft
-
- leader election
- log
- persistence
- log compaction
- 整体测试
- 后面发现的问题
- 参考代码
汇总博客:MIT6.824 2022
Raft
leader election
不论是访问还是修改Raft可变类成员,都需要加锁
rf.mu.Lock()
if rf.state != Leader {
rf.mu.Unlock()
return
}
args := AppendEntriesArgs{Term: rf.currentTerm, LeaderId: rf.me}
rf.mu.Unlock()
可以改为
rf.mu.Lock()
flag := (rf.state == Leader)
args := AppendEntriesArgs{Term: rf.currentTerm, LeaderId: rf.me}
rf.mu.Unlock()
if !flag {
return
}
2A时就尽可能实现更多功能,而不是仅仅通过测试,中文版论文用来大致了解raft算法,对照英文版论文编写代码。
问题:
RequestVote RPC中 at least as up-to-date对应于:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
由于是at least as,还包括相等的情况。
votedFor:candidateId that received vote in current term (or null if none)
当前任期接受到的选票的候选者 ID(初值为 null)
这意味着每当term改变,votedFor都需要重置。
If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
如果选举定时器超时时,没有收到 leader 的的追加日志请求 或者没有投票给候选者,该机器转化为候选者。
注意不要忽略granting vote to candidate这一条
参考:
MIT 6.824 Spring 2020 Lab2 Raft 实现笔记
log
2B阶段实现起来没用多久,但一直在调试。发现vscode自带的调试功能挺好用的(go test插件?)
一些细节:
currentTerm: latest term server has seen (initialized to 0 on first boot, increases monotonically)
当前看到的最新任期,所以每当看到更大的任期,都需设置为该任期
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower
votedFor:candidateId that received vote in current term (or null if none)
当前任期接收投票的候选者ID,所以任期改变时,votedFor也需要重置
log[]:log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1)
日志记录,起始索引为1,可以在初始化时加入term为0的假日志,便于程序统一处理(lastLogTerm prevLogTerm)
commitIndex:将被提交的日志记录索引,可以通过matchIndex拷贝后排序来得到新的commitIndex
AppendEntries RPC:
rule3:只有现有条目与entries中的条目才需要删除其后所有日志,如果不冲突则不需要删除,注意比较时取二者索引较小值,以免数组越界
rule 5:index of last new entry而不是本地日志最大索引值,prevLogIndex+len(entries)
注意不需要对空日志进行特殊处理
RequestVote RPC:
rule2两个条件:
condition1 := (rf.votedFor == InvalidId) || (rf.votedFor == args.CandidateId)
condition2 := (args.LastLogTerm > lastLogTerm) || ((args.LastLogTerm == lastLogTerm) && (args.LastLogIndex >= lastLogIndex))
遇到的一些问题:
问题表现:各节点一直在选举,却迟迟没有选出leader
问题原因:写2A的时候没有对lastLogIndex lastLogTerm赋值,RequestVote在对比时一直通不过。
问题表现:测试刚显示通过,然后程序就runtime error,单独运行某个测试样例又无法复现
问题原因:没有考虑RPC调用的返回值就直接对reply结果进行处理
偶发性问题:
在明显的问题解决完后后,运行一次go test -run 2B -race显示全部通过,但执行脚本运行100次有时候却出现了几次错误。这种一定几率出现的问题就比较麻烦了。
for i in {1..100}; do go test -run 2B -race; done
Test (2B): concurrent Start()s ...
--- FAIL: TestConcurrentStarts2B (31.27s)
config.go:549: only 1 decided for index 6; wanted 3
Test (2B): RPC counts aren't too high ...
--- FAIL: TestCount2B (32.34s)
config.go:549: only 2 decided for index 11; wanted 3
这种的一遍就需要先阅读一遍测试样例,并在样例合适的地方添加一些打印(有可能打印语句也会影响测试结果),并一次次点击测试按钮,思考问题原因了。
不过我另辟蹊径,懒得debug,直接把lab2前面建议的一些文章认真看了一遍(之前看太长就只是粗略地看了一遍)
Students’ Guide to Raft
Raft Q&A
Debugging by Pretty Printing
Instructors’ Guide to Raft
发现我遇到的一些问题都在Students’ Guide to Raft提到了,不过我也对这些点记忆深刻了。
Students’ Guide to Raft记录
1 论文中的表述大多时候是must而不是should,例如不是说每当server接收RPC调用时都应该重置选举定时器,而是在receiving AppendEntries RPC from current leader or granting vote to candidate时候才重置选举定时器。
2 心跳信息不应该被视作特殊的一种消息,当follower接收了该心跳消息,则隐式地表明当前日志已于该server匹配,而后进行错误的提交。
3 当接收心跳消息后,简单地切断server日志prevLogIndex的部分,这同样是不对的,论文中的表述为If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it,以上为一个条件语句。
4 当选举定时器过期后,即使上一任选举尚未完成,也应该进行下次的选举。
5 reply false意味着立即返回
6 AppendEntries处理过程中即使prevLogIndex对应位置条目不存在,同样视作日志不匹配
7 检查AppendEntries函数,即使entries为空也同样能执行成功,同样考虑本地日志越界的情况
8 认真理解last new entry与at least as up-to-date的含义
9 注意更新commitIndex时log[N].term == currentTerm
10 nextIndex是乐观估计,matchIndex是悲观估计,即使在很多时候赋值都为nextIndex = matchIndex + 1
11 在接收的旧的RPC回复时,比较当前term与arg中term,如果不一样,则直接返回,不进行处理
看完一遍文章后发现我的代码存在四个问题:
1:对心跳消息的回复进行特殊处理,只检查返回的term是否大于当前term,没有涉及到nextIndex与matchIndex的设置与重试。
2:对旧的RPC回复没有处理。
3:matchIndex没有保证单调递增
4:对于RPC调用失败直接返回而不是重试(return而不是continue)
1 对于心跳消息可以直接复用Start调用的日志协商函数,心跳消息同样可以用来同步各server的日志
2 在判断RPC是否成功之后,reply处理之前比对当前Term与参数Term,如果不一致则直接返回
3 避免matchIndex的后退
rf.matchIndex[server] = Max(rf.matchIndex[server], args.PrevLogIndex+len(args.Entries))
rf.nextIndex[server] = rf.matchIndex[server] + 1
4 我认为论文中重试不是立即重试,而是等到定时器过期时再进行重试。
选举时RPC失败,则选举定时器过期,进行下一次选举时重试RequestVote RPC
协商时RPC失败,则心跳定时器过期,同步日志时重试AppendEntries RPC
故我认为应该直接返回,而且写成continue也会变成无限循环,不符合实际情况。
在执行1000次go test时,以上的两个问题都没再出现,而是出现data race的警告
Test (2B): leader backs up quickly over incorrect follower logs ...
==================
WARNING: DATA RACE
Write at 0x00c0005b0988 by goroutine 277:
runtime.slicecopy()
/usr/lib/go-1.13/src/runtime/slice.go:197 +0x0
6.824/raft.(*Raft).AppendEntries()
/root/mit6.824/6.824/src/raft/raft.go:291 +0x663
runtime.call32()
/usr/lib/go-1.13/src/runtime/asm_amd64.s:539 +0x3a
reflect.Value.Call()
/usr/lib/go-1.13/src/reflect/value.go:321 +0xd3
6.824/labrpc.(*Service).dispatch()
/root/mit6.824/6.824/src/labrpc/labrpc.go:496 +0x811
6.824/labrpc.(*Server).dispatch()
/root/mit6.824/6.824/src/labrpc/labrpc.go:420 +0x607
6.824/labrpc.(*Network).processReq.func1()
/root/mit6.824/6.824/src/labrpc/labrpc.go:240 +0x93
Previous read at 0x00c0005b0988 by goroutine 323:
encoding/gob.encInt()
/usr/lib/go-1.13/src/reflect/value.go:976 +0x1df
encoding/gob.(*Encoder).encodeStruct()
/usr/lib/go-1.13/src/encoding/gob/encode.go:328 +0x436
encoding/gob.encOpFor.func4()
/usr/lib/go-1.13/src/encoding/gob/encode.go:581 +0xf0
encoding/gob.(*Encoder).encodeArray()
/usr/lib/go-1.13/src/encoding/gob/encode.go:351 +0x26f
encoding/gob.encOpFor.func1()
/usr/lib/go-1.13/src/encoding/gob/encode.go:551 +0x1a3
encoding/gob.(*Encoder).encodeStruct()
/usr/lib/go-1.13/src/encoding/gob/encode.go:328 +0x436
encoding/gob.(*Encoder).encode()
/usr/lib/go-1.13/src/encoding/gob/encode.go:701 +0x1fe
encoding/gob.(*Encoder).EncodeValue()
/usr/lib/go-1.13/src/encoding/gob/encoder.go:251 +0x666
encoding/gob.(*Encoder).Encode()
/usr/lib/go-1.13/src/encoding/gob/encoder.go:176 +0x5b
6.824/labgob.(*LabEncoder).Encode()
/root/mit6.824/6.824/src/labgob/labgob.go:36 +0x7b
6.824/labrpc.(*ClientEnd).Call()
/root/mit6.824/6.824/src/labrpc/labrpc.go:93 +0x198
6.824/raft.(*Raft).sendAppendEntries()
/root/mit6.824/6.824/src/raft/raft.go:336 +0xd5
6.824/raft.(*Raft).agreementTask.func1()
/root/mit6.824/6.824/src/raft/raft.go:388 +0x562
Goroutine 277 (running) created at:
6.824/labrpc.(*Network).processReq()
/root/mit6.824/6.824/src/labrpc/labrpc.go:239 +0x174
Goroutine 323 (running) created at:
6.824/raft.(*Raft).agreementTask()
/root/mit6.824/6.824/src/raft/raft.go:376 +0xa3
==================
--- FAIL: TestBackup2B (16.85s)
testing.go:853: race detected during execution of test
这个问题在于构建AppendEntries时entries对rf.log进行浅拷贝,在远程调用过程中会读取arg,如果该server一直为leader,其日志不会被更改,倒不会引发竞态问题。但当leader下台,日志就可以被更改,此时AppendEntries对日志进行修改,远程调用Call函数中读取该参数且未加rf.mu.lock,就引发了竞态问题,故应该对log进行深拷贝。
// 错误的
args.Entries = rf.log[rf.nextIndex[server]:]
// 正确的
args.Entries = append([]logEntry{}, rf.log[rf.nextIndex[server]:]...)
go语言为什么空切片,nil切片可以继续使用?append()函数
可以直接在bash脚本中设置次数为10000,啥时候不想跑crtl+z就可以了。
persistence
2C编写的代码比较简单,只需要照着persist/readPersist的example实现对应函数,然后在3个持久状态改变后调用persist函数。AppendEntries RPC的next index优化参照guidance中提供的方法
The accelerated log backtracking optimization is very underspecified, probably because the authors do not see it as being necessary for most deployments. It is not clear from the text exactly how the conflicting index and term sent back from the client should be used by the leader to determine what nextIndex to use. We believe the protocol the authors probably want you to follow is:
If a follower does not have prevLogIndex in its log, it should return with conflictIndex = len(log) and conflictTerm = None.
If a follower does have prevLogIndex in its log, but the term does not match, it should return conflictTerm = log[prevLogIndex].Term, and then search its log for the first index whose entry has term equal to conflictTerm.
Upon receiving a conflict response, the leader should first search its log for conflictTerm. If it finds an entry in its log with that term, it should set nextIndex to be the one beyond the index of the last entry in that term in its log.
If it does not find an entry with that term, it should set nextIndex = conflictIndex.
the one beyond the index不怎么能理解,就直接设置成最后一个等于该term的索引。next index只影响效率,不怎么影响正确性。如果2B没啥问题,2C也应该没啥问题,如果2C有问题,就应该运行几千次2B测试,验证一下。
问题:
Test (2C): basic persistence ...
... Passed -- 4.1 3 216 46172 6
Test (2C): more persistence ...
2022/10/30 06:44:20 next index retry. cur term:5 me:3 server:1 value:2 reply:term:-1 index:2
2022/10/30 06:44:20 next index retry. cur term:5 me:3 server:2 value:2 reply:term:-1 index:2
2022/10/30 06:44:22 next index retry. cur term:9 me:1 server:4 value:5 reply:term:-1 index:5
2022/10/30 06:44:22 next index retry. cur term:9 me:1 server:0 value:5 reply:term:-1 index:5
2022/10/30 06:44:24 next index retry. cur term:13 me:4 server:3 value:8 reply:term:-1 index:8
2022/10/30 06:44:24 next index retry. cur term:13 me:4 server:2 value:8 reply:term:-1 index:8
2022/10/30 06:44:29 next index retry. cur term:16 me:2 server:1 value:11 reply:term:-1 index:11
2022/10/30 06:44:29 next index retry. cur term:16 me:2 server:0 value:11 reply:term:-1 index:11
2022/10/30 06:44:31 next index retry. cur term:20 me:0 server:4 value:14 reply:term:-1 index:14
2022/10/30 06:44:31 next index retry. cur term:20 me:0 server:3 value:14 reply:term:-1 index:14
... Passed -- 16.0 5 982 207944 16
Test (2C): partitioned leader and one follower crash, leader restarts ...
2022/10/30 06:44:35 next index retry. cur term:3 me:2 server:1 value:2 reply:term:-1 index:2
... Passed -- 1.9 3 51 12120 4
Test (2C): Figure 8 ...
2022/10/30 06:44:37 next index retry. cur term:4 me:0 server:1 value:3 reply:term:-1 index:3
2022/10/30 06:44:41 next index retry. cur term:11 me:2 server:1 value:9 reply:term:-1 index:9
2022/10/30 06:44:41 next index retry. cur term:12 me:1 server:4 value:4 reply:term:-1 index:4
2022/10/30 06:44:41 next index retry. cur term:12 me:1 server:3 value:5 reply:term:-1 index:5
2022/10/30 06:44:43 next index retry. cur term:13 me:3 server:2 value:9 reply:term:8 index:9
2022/10/30 06:44:43 next index retry. cur term:14 me:4 server:1 value:10 reply:term:-1 index:10
2022/10/30 06:44:44 next index retry. cur term:15 me:2 server:3 value:11 reply:term:-1 index:11
2022/10/30 06:44:45 next index retry. cur term:16 me:3 server:0 value:10 reply:term:-1 index:10
2022/10/30 06:44:45 next index retry. cur term:16 me:3 server:0 value:9 reply:term:8 index:9
2022/10/30 06:44:46 next index retry. cur term:17 me:0 server:2 value:13 reply:term:-1 index:13
2022/10/30 06:44:47 next index retry. cur term:19 me:1 server:4 value:12 reply:term:-1 index:12
2022/10/30 06:44:48 next index retry. cur term:20 me:2 server:3 value:14 reply:term:-1 index:14
2022/10/30 06:44:49 next index retry. cur term:22 me:4 server:0 value:16 reply:term:-1 index:16
2022/10/30 06:44:50 next index retry. cur term:24 me:3 server:2 value:19 reply:term:-1 index:19
2022/10/30 06:44:52 next index retry. cur term:27 me:3 server:0 value:23 reply:term:-1 index:23
2022/10/30 06:44:52 next index retry. cur term:27 me:3 server:2 value:23 reply:term:-1 index:23
2022/10/30 06:44:53 next index retry. cur term:29 me:3 server:2 value:25 reply:term:-1 index:25
2022/10/30 06:44:53 next index retry. cur term:29 me:3 server:0 value:25 reply:term:-1 index:25
2022/10/30 06:44:54 next index retry. cur term:30 me:0 server:1 value:17 reply:term:-1 index:17
2022/10/30 06:44:54 next index retry. cur term:31 me:2 server:4 value:21 reply:term:-1 index:21
2022/10/30 06:44:55 next index retry. cur term:34 me:4 server:2 value:29 reply:term:-1 index:29
2022/10/30 06:44:55 next index retry. cur term:34 me:4 server:1 value:29 reply:term:-1 index:29
2022/10/30 06:44:57 next index retry. cur term:36 me:2 server:0 value:28 reply:term:-1 index:28
2022/10/30 06:44:58 next index retry. cur term:37 me:1 server:3 value:27 reply:term:-1 index:27
2022/10/30 06:44:58 next index retry. cur term:39 me:3 server:0 value:33 reply:term:-1 index:33
2022/10/30 06:44:58 next index retry. cur term:39 me:3 server:4 value:32 reply:term:-1 index:32
2022/10/30 06:44:59 next index retry. cur term:40 me:4 server:2 value:33 reply:term:-1 index:33
2022/10/30 06:45:00 next index retry. cur term:41 me:2 server:1 value:34 reply:term:-1 index:34
2022/10/30 06:45:01 next index retry. cur term:42 me:0 server:3 value:35 reply:term:-1 index:35
2022/10/30 06:45:02 next index retry. cur term:43 me:1 server:4 value:35 reply:term:40 index:35
2022/10/30 06:45:02 next index retry. cur term:43 me:1 server:3 value:35 reply:term:-1 index:35
race: limit on 8128 simultaneously alive goroutines is exceeded, dying
协程数目超出限制,参照Kill函数的注释,在每个定时任务中加入 !rf.killed()判断,以便在测试完成后退出协程。
//
// the tester doesn't halt goroutines created by Raft after each test,
// but it does call the Kill() method. your code can use killed() to
// check whether Kill() has been called. the use of atomic avoids the
// need for a lock.
//
// the issue is that long-running goroutines use memory and may chew
// up CPU time, perhaps causing later tests to fail and generating
// confusing debug output. any goroutine with a long-running loop
// should call killed() to check whether it should stop.
//
func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
// Your code here, if desired.
}
// 向各节点发送心跳消息
func (rf *Raft) heartBeatTask() {
for !rf.killed() {
rf.mu.Lock()
flag := (rf.state == Leader)
rf.mu.Unlock()
if !flag {
return
}
go rf.agreementTask()
time.Sleep(HeartBeatInterval)
}
}
// 向server提交命令(存在错误,见下文)
func (rf *Raft) Submitter() {
for !rf.killed() {
rf.mu.Lock()
if rf.lastApplied < rf.commitIndex {
rf.lastApplied++
msg := ApplyMsg{CommandValid: true, Command: rf.log[rf.lastApplied].Command, CommandIndex: rf.lastApplied}
rf.applyCh <- msg
}
rf.mu.Unlock()
time.Sleep(10 * time.Millisecond)
}
}
log compaction
2D实现起来更多的是细节问题,是否将所有访问log的操作,访问log长度都修改为以某个数为起点的操作
访问index位置上的日志
rf.log[index] -> rf.log[index-X]
日志长度/nextIndex
len(rf.log) -> X+len(rf.log)
本地日志最大索引
len(rf.log) - 1 -> X+len(rf.log)-1
在2B实现中,我在log[0]处放置了一条term为0的假日志,便于统一处理。在2D修改日志起点的时候一直出问题,我突然想到可以直接在日志0位放置快照的最后一条记录,也就是X=lastIncludeIndex,这样程序处理起来也比较一致。也就是说,快照为空时对应的lastInclude日志是初始化加入的假日志,其余时候均为真实快照的lastInclude日志(command成员不关心)。
我实现的2D的一些约束为
- 日志永远不能为空
- follower日志lastIncludeIndex/commitIndex之前的term默认与leader的term匹配
- 在AppendEntries函数中ConflictIndex应大于lastIncludedIndex
- 在AppendEntriesRPC处理重传时,find same term的范围应该大于lastIncludedIndex
- 在同一个协程中apply快照与日志
第一条很容易理解,无论如何,日志都应该存在一条lastIncludeIndex日志,故在InstallSnapshot的step7中虽然写的是discard the entire log,也要加上一条快照对应的lastIncludeIndex日志,Snapshot函数中,少删除一条日志,保证0位为lastIncludeIndex日志。
第二条 leader拥有所有已提交的日志,对于已提交日志相同索引的日志内容一致,所以没必要检查term(可用于AppendEntries中step2 preLogIndex 匹配与step3 different term),要时时刻刻想到这一点。
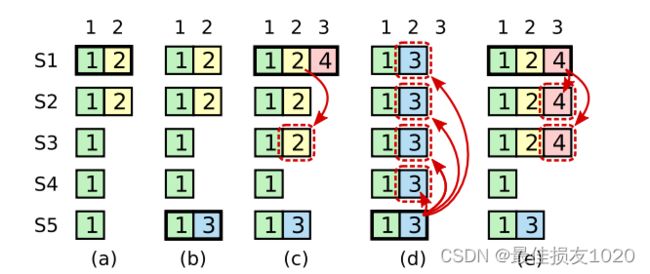
Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
第三第四条实际上描述的事情差不多,日志0位的term最好只在RequestVote RPC相关的LastLogTerm被用到,preLogTerm可根据第二条规则默认匹配,nextIndex相关的操作不访问日志0位。
第五条实际上和以下这段提示有关,我刚开始虽然没实现一个CondInstallSnapshot,但实现了一个单独提交快照的函数,在接收到其他server的快照或重新Make时直接发送快照至service。在crash之前的测试还可以通过,一到crash测试就直接卡死,其他server一直无法访问crash的主机,显示RPC调用失败。
Previously, this lab recommended that you implement a function called CondInstallSnapshot to avoid the requirement that snapshots and log entries sent on applyCh are coordinated. This vestigal API interface remains, but you are discouraged from implementing it: instead, we suggest that you simply have it return true.
// crash test测试函数
func snapcommon(t *testing.T, name string, disconnect bool, reliable bool, crash bool) {
iters := 30
servers := 3
cfg := make_config(t, servers, !reliable, true)
defer cfg.cleanup()
cfg.begin(name)
cfg.one(rand.Int(), servers, true)
leader1 := cfg.checkOneLeader()
for i := 0; i < iters; i++ {
victim := (leader1 + 1) % servers
sender := leader1
if i%3 == 1 {
sender = (leader1 + 1) % servers
victim = leader1
}
DPrintf("%v time,vicitm is %v\n", i, victim)
if disconnect {
cfg.disconnect(victim)
cfg.one(rand.Int(), servers-1, true)
}
if crash {
cfg.crash1(victim)
DPrintf("%v crash", victim)
cfg.one(rand.Int(), servers-1, true)
}
// perhaps send enough to get a snapshot
nn := (SnapShotInterval / 2) + (rand.Int() % SnapShotInterval)
for i := 0; i < nn; i++ {
cfg.rafts[sender].Start(rand.Int())
}
// let applier threads catch up with the Start()'s
if disconnect == false && crash == false {
// make sure all followers have caught up, so that
// an InstallSnapshot RPC isn't required for
// TestSnapshotBasic2D().
cfg.one(rand.Int(), servers, true)
} else {
cfg.one(rand.Int(), servers-1, true)
}
if cfg.LogSize() >= MAXLOGSIZE {
cfg.t.Fatalf("Log size too large")
}
if disconnect {
// reconnect a follower, who maybe behind and
// needs to rceive a snapshot to catch up.
cfg.connect(victim)
cfg.one(rand.Int(), servers, true)
leader1 = cfg.checkOneLeader()
}
if crash {
cfg.start1(victim, cfg.applierSnap)
DPrintf("%v restart\n", victim)
cfg.connect(victim)
cfg.one(rand.Int(), servers, true)
leader1 = cfg.checkOneLeader()
}
}
cfg.end()
}
在test_test.go添加打印后发现,vicitm server一直卡在crash和restart中间阶段,检查代码发现卡死在Make函数中发送快照至service的操作。故修改实现,接收到 InstallSnapshot RPC调用或重启时只修改commitIndex,不提交至service,只在一个协程中修改lastApplied。
遇到的问题:
一: 快照编码错误
在刚开始实现的时候,我将lastIncludeIndex和lastIncludeTerm持久化到Persister的snapshot成员中,一到crash测试就显示snapshot decode error。
Test (2D): install snapshots (crash) ...
2022/11/19 05:26:22 0 become leader
2022/11/19 05:26:24 2 become leader
2022/11/19 05:26:24 snapshot decode error
exit status 1
阅读config.go相关代码
// 生成快照
if (m.CommandIndex+1)%SnapShotInterval == 0 {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(m.CommandIndex)
var xlog []interface{}
for j := 0; j <= m.CommandIndex; j++ {
xlog = append(xlog, cfg.logs[i][j])
}
e.Encode(xlog)
rf.Snapshot(m.CommandIndex, w.Bytes())
}
// 读取快照
if cfg.saved[i] != nil {
cfg.saved[i] = cfg.saved[i].Copy()
snapshot := cfg.saved[i].ReadSnapshot()
if snapshot != nil && len(snapshot) > 0 {
// mimic KV server and process snapshot now.
// ideally Raft should send it up on applyCh...
err := cfg.ingestSnap(i, snapshot, -1)
if err != "" {
cfg.t.Fatal(err)
}
}
}
func (cfg *config) ingestSnap(i int, snapshot []byte, index int) string {
if snapshot == nil {
log.Fatalf("nil snapshot")
return "nil snapshot"
}
r := bytes.NewBuffer(snapshot)
d := labgob.NewDecoder(r)
var lastIncludedIndex int
var xlog []interface{}
if d.Decode(&lastIncludedIndex) != nil ||
d.Decode(&xlog) != nil {
log.Panic()
log.Fatalf("snapshot decode error")
return "snapshot Decode() error"
}
if index != -1 && index != lastIncludedIndex {
err := fmt.Sprintf("server %v snapshot doesn't match m.SnapshotIndex", i)
return err
}
cfg.logs[i] = map[int]interface{}{}
for j := 0; j < len(xlog); j++ {
cfg.logs[i][j] = xlog[j]
}
cfg.lastApplied[i] = lastIncludedIndex
return ""
}
可以看出snapshot成员只应该是上层生成的快照,不应该加上其他状态,所有的状态都编码到raftstate成员中;另外快照中还额外编码了lastIncludedIndex。
二:InstallSnapshot RPC理解错误
If existing log entry has same index and term as snapshot’s last included entry, retain log entries following it and reply
对于InstallSnapshot RPC的step 6理解错误,理解成是否存在相同的快照,比对lastIncludeIndex与lastIncludeTerm去了。实际上直接检查相同index term是否一致即可,commit之前默认一致。
logIndex := args.LastIncludedIndex - rf.lastIncludedIndex
if logIndex < 0 {
WPrintf("server snapshot is newer. server id:%v lastIncludedIndex:%v log len:%v\n", rf.me, rf.lastIncludedIndex, len(rf.log))
return
}
if logIndex < len(rf.log) && rf.log[logIndex].Term == args.LastIncludedTerm { // step 5
DPrintf("same log entry. server id:%v lastIncludedIndex:%v log len:%v\n", rf.me, rf.lastIncludedIndex, len(rf.log))
return
}
第一个分支从来没打印过
DPrintf打印一些普通信息
WPrintf打印一些异常情况
log.Panicf打印一些逻辑错误情况
记得时不时commit一下,便于查看代码修改情况。
三:没看出具体作用的修改
1 垃圾回收
Raft must discard old log entries in a way that allows the Go garbage collector to free and re-use the memory; this requires that there be no reachable references (pointers) to the discarded log entries.
进行如下语句的替换
// rf.log = rf.log[index-rf.lastIncludedIndex:]
rf.log = append([]logEntry{}, rf.log[index-rf.lastIncludedIndex:]...)
很多博客都使用copy来实现深拷贝,以指向不同的底层数组,但我觉得用append更方便一点。
切片(slice)性能及陷阱
2
If, when the server comes back up, it reads the updated snapshot, but the outdated log, it may end up applying some log entries that are already contained within the snapshot. This happens since the commitIndex and lastApplied are not persisted, and so Raft doesn’t know that those log entries have already been applied. The fix for this is to introduce a piece of persistent state to Raft that records what “real” index the first entry in Raft’s persisted log corresponds to. This can then be compared to the loaded snapshot’s lastIncludedIndex to determine what elements at the head of the log to discard.
Students’ Guide to Raft
比对快照编码的lastIncludeIndex与state中的lastIncludeIndex,去掉一些日志
func (rf *Raft) compareStateAndSnapshot() {
if rf.snapshot == nil || len(rf.snapshot) < 1 {
return
}
r := bytes.NewBuffer(rf.snapshot)
d := labgob.NewDecoder(r)
var lastIncludedIndex int
if d.Decode(&lastIncludedIndex) != nil {
log.Panicf("compareStateAndSnapshot: snapshot decode error")
}
if rf.lastIncludedIndex != lastIncludedIndex {
WPrintf("snapshot lastIncludedIndex is different. snapshot:%v state:%v\n", lastIncludedIndex, rf.lastIncludedIndex)
rf.log = append([]logEntry{}, rf.log[lastIncludedIndex-rf.lastIncludedIndex:]...)
rf.lastIncludedIndex = lastIncludedIndex
rf.lastIncludedTerm = rf.log[0].Term // 日志0位的term
rf.commitIndex = rf.lastIncludedIndex
}
}
没啥用,WPrintf语句没打印过
由于3B在快照中编码了其他数据,也就不再做这个比较了
四:不知道有没有用的修改
在2D测试跑通后跑全部的测试,其中几次在2D的各个测试出现了panic: test timed out after 10m0s问题,看了看打印的goroutine堆栈,发现许多goroutine都在获取锁,并且apply协程阻塞在通道发送那一步(在当时实现中此时该线程持有锁),觉得有可能是service没有接收ApplyMsg,导致server一直无法推进,故修改提交协程实现,在发送消息时不持有锁。
// 向service发送命令(仍然存在问题,见下文)
func (rf *Raft) applyTask() {
for !rf.killed() {
var msg ApplyMsg
sendMsg := false
rf.mu.Lock()
if rf.lastApplied < rf.commitIndex {
sendMsg = true
if rf.lastApplied < rf.lastIncludedIndex {
msg = ApplyMsg{CommandValid: false, SnapshotValid: true, Snapshot: rf.snapshot, SnapshotIndex: rf.lastIncludedIndex, SnapshotTerm: rf.lastIncludedTerm}
DPrintf("applySnapshot. server id:%v commitIndex:%v lastApplied:%v lastIncludedIndex:%v\n", rf.me, rf.commitIndex, rf.lastApplied, rf.lastIncludedIndex)
rf.lastApplied = rf.lastIncludedIndex
} else {
rf.lastApplied++
msg = ApplyMsg{CommandValid: true, Command: rf.log[rf.lastApplied-rf.lastIncludedIndex].Command, CommandIndex: rf.lastApplied}
}
}
rf.mu.Unlock()
if sendMsg {
rf.applyCh <- msg
}
time.Sleep(10 * time.Millisecond)
}
}
不过有没有真的解决问题我也不知道,反正之后测试没再出现这个问题了。
这个实验最麻烦的一点就在于永远不知道是否真正解决了某个问题,在2B阶段有时候测试到一千多次才出现错误,都有点无从调试,只能看看raft论文,Students’ Guide,自我完善一下代码,并时时检查一些关键变量,打印一些异常情况。
整体测试
在基本写完ABCD阶段后,再看一遍相关文章,重新看一遍代码,写一些注释,跑上一天全部测试,如果没有错就当lab2实现完成了(有限的正确性保证)。
6.824 Lab 2: Raft
Students’ Guide to Raft
Raft Q&A
Raft Locking Advice
Raft Structure Advice
Debugging by Pretty Printing
Lab guidance
摘录一些片段加深印象:
Rule 1: Whenever you have data that more than one goroutine uses, and at least one goroutine might modify the data, the goroutines should use locks to prevent simultaneous use of the data.
Rule 2: Whenever code makes a sequence of modifications to shared data, and other goroutines might malfunction if they looked at the data midway through the sequence, you should use a lock around the whole sequence.
Rule 3: Whenever code does a sequence of reads of shared data (orreads and writes), and would malfunction if another goroutine modified the data midway through the sequence, you should use a lock around the whole sequence.
Rule 4: It’s usually a bad idea to hold a lock while doing anything that might wait: reading a Go channel, sending on a channel, waiting for a timer, calling time.Sleep(), or sending an RPC (and waiting for the reply).
Rule 5: Be careful about assumptions across a drop and re-acquire of a lock. One place this can arise is when avoiding waiting with locks held.
commitIndex is volatile because Raft can figure out a correct value for it after a reboot using just the persistent state. Once a leader successfully gets a new log entry committed, it knows everything before that point is also committed. A follower that crashes and comes back up will be told about the right commitIndex whenever the current leader sends it an AppendEntries RPC.
lastApplied starts at zero after a reboot because the Figure 2 design assumes the service (e.g., a key/value database) doesn’t keep any persistent state. Thus its state needs to be completely recreated by replaying all log entries. If the service does keep persistent state, it is expected to persistently remember how far in the log it has executed, and to ignore entries before that point. Either way it’s safe to start with lastApplied = 0 after a reboot.


Instead, the best approach is usually to work backwards and narrow down the size of phase 2 until it is as small as possible, so that the location of the fault is readily apparent. This is done by expanding the instrumentation of your code to surface errors sooner, and thereby spend less time in phase 2. This generally involves adding additional debugging statements and/or assertions to your code.
When possible, consider writing your code to “fail loudly”. Instead of trying to tolerate unexpected states, try to explicitly detect states that should never be allowed to happen, and immediately report these errors. Consider even immediately calling the Go ‘panic’ function in these cases to fail especially loudly. See also the Wikipedia page on Offensive programming techniques. Remember that the longer you allow errors to remain latent, the longer it will take to narrow down the true underlying fault.
When you’re failing a test, and it’s not obvious why, it’s usually worth taking the time to understand what the test is actually doing, and which part of the test is observing the problem. It can be helpful to add print statements to the test code so that you know when events are happening.
注意检查是否所有持久状态改变时都调用了persist函数,快照改变时都调用了SaveStateAndSnapshot函数。
每个server commit index之前的日志都一模一样且无法更改
遇到的问题:
2D时为解决panic: test timed out after 10m0s问题,向service发送消息时不再持有锁
// 向service发送命令
func (rf *Raft) applyTask() {
for !rf.killed() {
var msg ApplyMsg
sendMsg := false
rf.mu.Lock()
if rf.lastApplied < rf.commitIndex {
sendMsg = true
if rf.lastApplied < rf.lastIncludedIndex {
msg = ApplyMsg{CommandValid: false, SnapshotValid: true, Snapshot: rf.snapshot, SnapshotIndex: rf.lastIncludedIndex, SnapshotTerm: rf.lastIncludedTerm}
DPrintf("applySnapshot. server id:%v commitIndex:%v lastApplied:%v lastIncludedIndex:%v\n", rf.me, rf.commitIndex, rf.lastApplied, rf.lastIncludedIndex)
rf.lastApplied = rf.lastIncludedIndex
} else {
rf.lastApplied++
msg = ApplyMsg{CommandValid: true, Command: rf.log[rf.lastApplied-rf.lastIncludedIndex].Command, CommandIndex: rf.lastApplied}
}
}
rf.mu.Unlock()
if sendMsg {
rf.applyCh <- msg
}
time.Sleep(10 * time.Millisecond)
}
}
然后运行所有测试样例,TestReliableChurn2C时不时报以下错误
config.go:628: one(6739062427422661052) failed to reach agreement
在相应的语句前面加上log.Panicf语句,显示调用栈
goroutine 19 [running]:
testing.tRunner.func1(0xc0000e6100)
/usr/lib/go-1.13/src/testing/testing.go:874 +0x3a3
panic(0x5b28c0, 0xc00031ec50)
/usr/lib/go-1.13/src/runtime/panic.go:679 +0x1b2
log.Panicf(0x604122, 0x21, 0xc000127d70, 0x1, 0x1)
/usr/lib/go-1.13/src/log/log.go:345 +0xc0
6.824/raft.(*config).one(0xc0000e2140, 0x5b1d40, 0xc0002c7188, 0x5, 0x301, 0xc0009f2000)
/root/mit6.824/6.824/src/raft/config.go:628 +0x73b
6.824/raft.internalChurn(0xc0000e6100, 0xbf8db3b4c200)
/root/mit6.824/6.824/src/raft/test_test.go:1079 +0xace
6.824/raft.TestReliableChurn2C(0xc0000e6100)
/root/mit6.824/6.824/src/raft/test_test.go:1107 +0x30
testing.tRunner(0xc0000e6100, 0x609aa8)
/usr/lib/go-1.13/src/testing/testing.go:909 +0xc9
created by testing.(*T).Run
/usr/lib/go-1.13/src/testing/testing.go:960 +0x350
exit status 2
// 测试函数 协商某项日志
// do a complete agreement.
// it might choose the wrong leader initially,
// and have to re-submit after giving up.
// entirely gives up after about 10 seconds.
// indirectly checks that the servers agree on the
// same value, since nCommitted() checks this,
// as do the threads that read from applyCh.
// returns index.
// if retry==true, may submit the command multiple
// times, in case a leader fails just after Start().
// if retry==false, calls Start() only once, in order
// to simplify the early Lab 2B tests.
func (cfg *config) one(cmd interface{}, expectedServers int, retry bool) int {
t0 := time.Now()
starts := 0
for time.Since(t0).Seconds() < 10 && cfg.checkFinished() == false {
// try all the servers, maybe one is the leader.
index := -1
for si := 0; si < cfg.n; si++ {
starts = (starts + 1) % cfg.n
var rf *Raft
cfg.mu.Lock()
if cfg.connected[starts] {
rf = cfg.rafts[starts]
}
cfg.mu.Unlock()
if rf != nil {
index1, _, ok := rf.Start(cmd)
if ok {
index = index1
break
}
}
}
if index != -1 {
// somebody claimed to be the leader and to have
// submitted our command; wait a while for agreement.
t1 := time.Now()
for time.Since(t1).Seconds() < 2 {
nd, cmd1 := cfg.nCommitted(index)
if nd > 0 && nd >= expectedServers {
// committed
if cmd1 == cmd {
// and it was the command we submitted.
return index
}
}
time.Sleep(20 * time.Millisecond)
}
if retry == false {
cfg.t.Fatalf("one(%v) failed to reach agreement", cmd)
}
} else {
time.Sleep(50 * time.Millisecond)
}
}
if cfg.checkFinished() == false {
for si := 0; si < cfg.n; si++ {
starts = (starts + 1) % cfg.n
var rf *Raft
cfg.mu.Lock()
if cfg.connected[starts] {
rf = cfg.rafts[starts]
}
cfg.mu.Unlock()
if rf != nil {
rf.mu.Lock()
DPrintf("%+v", rf)
rf.mu.Unlock()
}
}
log.Panicf("one(%v) failed to reach agreement", cmd)
cfg.t.Fatalf("one(%v) failed to reach agreement", cmd)
}
return -1
}
func internalChurn(t *testing.T, unreliable bool) {
servers := 5
cfg := make_config(t, servers, unreliable, false)
defer cfg.cleanup()
if unreliable {
cfg.begin("Test (2C): unreliable churn")
} else {
cfg.begin("Test (2C): churn")
}
stop := int32(0)
// create concurrent clients
cfn := func(me int, ch chan []int) {
var ret []int
ret = nil
defer func() { ch <- ret }()
values := []int{}
for atomic.LoadInt32(&stop) == 0 {
x := rand.Int()
index := -1
ok := false
for i := 0; i < servers; i++ {
// try them all, maybe one of them is a leader
cfg.mu.Lock()
rf := cfg.rafts[i]
cfg.mu.Unlock()
if rf != nil {
index1, _, ok1 := rf.Start(x)
if ok1 {
ok = ok1
index = index1
}
}
}
if ok {
// maybe leader will commit our value, maybe not.
// but don't wait forever.
for _, to := range []int{10, 20, 50, 100, 200} {
nd, cmd := cfg.nCommitted(index)
if nd > 0 {
if xx, ok := cmd.(int); ok {
if xx == x {
values = append(values, x)
}
} else {
cfg.t.Fatalf("wrong command type")
}
break
}
time.Sleep(time.Duration(to) * time.Millisecond)
}
} else {
time.Sleep(time.Duration(79+me*17) * time.Millisecond)
}
}
ret = values
}
ncli := 3
cha := []chan []int{}
for i := 0; i < ncli; i++ {
cha = append(cha, make(chan []int))
go cfn(i, cha[i])
}
for iters := 0; iters < 20; iters++ {
if (rand.Int() % 1000) < 200 {
i := rand.Int() % servers
cfg.disconnect(i)
}
if (rand.Int() % 1000) < 500 {
i := rand.Int() % servers
if cfg.rafts[i] == nil {
cfg.start1(i, cfg.applier)
}
cfg.connect(i)
}
if (rand.Int() % 1000) < 200 {
i := rand.Int() % servers
if cfg.rafts[i] != nil {
cfg.crash1(i)
}
}
// Make crash/restart infrequent enough that the peers can often
// keep up, but not so infrequent that everything has settled
// down from one change to the next. Pick a value smaller than
// the election timeout, but not hugely smaller.
time.Sleep((RaftElectionTimeout * 7) / 10)
}
time.Sleep(RaftElectionTimeout)
cfg.setunreliable(false)
for i := 0; i < servers; i++ {
if cfg.rafts[i] == nil {
cfg.start1(i, cfg.applier)
}
cfg.connect(i)
}
atomic.StoreInt32(&stop, 1)
values := []int{}
for i := 0; i < ncli; i++ {
vv := <-cha[i]
if vv == nil {
t.Fatal("client failed")
}
values = append(values, vv...)
}
time.Sleep(RaftElectionTimeout)
lastIndex := cfg.one(rand.Int(), servers, true)
发现停留在lastIndex这行语句中,其中的expectedServers参数为servers,即所有server都需提交命令成功。
在出错前打印的DPrintf(“%+v”, rf)语句显示信息中可以看到
commitIndex:1153 lastApplied:996 nextIndex:[] matchIndex:[] state:0 leaderId:2
commitIndex:1153 lastApplied:1153 nextIndex:[] matchIndex:[] state:0 leaderId:2
commitIndex:1153 lastApplied:1153 nextIndex:[] matchIndex:[] state:0 leaderId:2
commitIndex:1153 lastApplied:1153 nextIndex:[] matchIndex:[] state:0 leaderId:2
commitIndex:1153 lastApplied:1153 nextIndex:[1154 1154 1154 1154 1154] matchIndex:[1153 1153 1153 1153 1153] state:2 leaderId:2
实际上有一个server commitIndex已经变成了1153,只不过还没来得及发送至service,故简单修改一下applyTask,不再是发送一次就休眠,变成本次成功发送则再进行一次尝试。
// 向service发送命令
func (rf *Raft) applyTask() {
for !rf.killed() {
var msg ApplyMsg
sendMsg := false
rf.mu.Lock()
if rf.lastApplied < rf.commitIndex {
sendMsg = true
if rf.lastApplied < rf.lastIncludedIndex { // 发送快照
rf.lastApplied = rf.lastIncludedIndex
msg = ApplyMsg{CommandValid: false, SnapshotValid: true, Snapshot: rf.snapshot, SnapshotIndex: rf.lastIncludedIndex, SnapshotTerm: rf.lastIncludedTerm}
DPrintf("applySnapshot. server id:%v commitIndex:%v lastApplied:%v lastIncludedIndex:%v\n", rf.me, rf.commitIndex, rf.lastApplied, rf.lastIncludedIndex)
} else { // 发送日志
rf.lastApplied++
msg = ApplyMsg{CommandValid: true, Command: rf.log[rf.lastApplied-rf.lastIncludedIndex].Command, CommandIndex: rf.lastApplied}
}
}
rf.mu.Unlock()
if sendMsg { // 向service发送消息
rf.applyCh <- msg
} else { // 此次未发送消息,休眠10ms后再次查询
time.Sleep(10 * time.Millisecond)
}
}
}
跑了一天测试,233次PASS,lab2基本正确
Test (2A): initial election ...
... Passed -- 3.0 3 58 15996 0
Test (2A): election after network failure ...
... Passed -- 5.1 3 124 24683 0
Test (2A): multiple elections ...
... Passed -- 7.0 7 600 120200 0
Test (2B): basic agreement ...
... Passed -- 1.1 3 22 5338 3
Test (2B): RPC byte count ...
... Passed -- 1.5 3 48 113842 11
Test (2B): agreement after follower reconnects ...
... Passed -- 5.7 3 131 35047 8
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.6 5 200 42417 3
Test (2B): concurrent Start()s ...
... Passed -- 0.5 3 20 5838 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 6.2 3 193 46403 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 16.6 5 2100 1576435 102
Test (2B): RPC counts aren't too high ...
... Passed -- 2.0 3 58 17896 12
Test (2C): basic persistence ...
... Passed -- 4.1 3 86 21883 6
Test (2C): more persistence ...
... Passed -- 15.7 5 932 198468 16
Test (2C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 1.7 3 37 9365 4
Test (2C): Figure 8 ...
... Passed -- 31.4 5 870 188356 47
Test (2C): unreliable agreement ...
... Passed -- 2.2 5 1056 348389 246
Test (2C): Figure 8 (unreliable) ...
... Passed -- 29.9 5 9385 19728838 106
Test (2C): churn ...
... Passed -- 16.2 5 4892 9100813 1114
Test (2C): unreliable churn ...
... Passed -- 16.1 5 6409 10687659 1013
Test (2D): snapshots basic ...
... Passed -- 2.1 3 480 164064 220
Test (2D): install snapshots (disconnect) ...
... Passed -- 35.1 3 1442 637310 324
Test (2D): install snapshots (disconnect+unreliable) ...
... Passed -- 45.8 3 1674 652143 313
Test (2D): install snapshots (crash) ...
... Passed -- 28.0 3 1174 488096 339
Test (2D): install snapshots (unreliable+crash) ...
... Passed -- 36.4 3 1206 602020 297
Test (2D): crash and restart all servers ...
... Passed -- 8.5 3 276 79532 62
PASS
ok 6.824/raft 325.469s
后面发现的问题
在测试3A的时候发现Leader节点自身的matchIndex为0,其余均为146,这与我的预想不符。在开始的设计中,在节点被选为Leader时matchIndex都为0,在Start函数中对自身的matchIndex赋值,在计算commitIndex时把自身的matchIndex也算进去了,这样比较便于理解。
// leader选举
// 初始化Leader专属变量
rf.nextIndex = make([]int, rf.peerNumber)
nextIndex := rf.lastIncludedIndex + len(rf.log)
for i := 0; i < rf.peerNumber; i++ {
rf.nextIndex[i] = nextIndex
}
rf.matchIndex = make([]int, rf.peerNumber)
// Start函数
// 同时更新自身nextIndex与matchIndex,便于计算commit index
rf.nextIndex[rf.me] = rf.lastIncludedIndex + len(rf.log)
rf.matchIndex[rf.me] = rf.lastIncludedIndex + len(rf.log) - 1
// 重新计算提交索引
func (rf *Raft) changeCommitIndex() { // leader rule 4
matchIndex := append([]int{}, rf.matchIndex...) // 深拷贝
sort.Ints(matchIndex)
// If there exists an N such that N > commitIndex, a majority
// of matchIndex[i] ≥ N, and log[N].term == currentTerm:
// set commitIndex = N
for i := matchIndex[rf.peerNumber-rf.majorityPeer]; i > rf.commitIndex; i-- {
if rf.log[i-rf.lastIncludedIndex].Term == rf.currentTerm {
// DPrintf("%d change commindex from %d to %d\n", rf.me, rf.commitIndex, i)
rf.commitIndex = i
return
}
}
}
在绝大部分情况这种方式没啥问题,但当节点被选为leader,但一直未收到客户的命令,并且节点与半数节点在一个分区,其余节点在另一个分区,那么commit index永远无法增加。
例子:
节点0为leader,节点1 2与leader在一个分区
节点3 4在另一个分区
节点0在被选举后log长度为10,将这些日志同步到节点1 2
节点0的match index[0,10,10,0,0] commit index永远为0
这个的解决方法也很简单,可以在计算commit index忽略leader自身,或者保证leader自身match index永远为日志最大索引(实际上可以为无穷大值),我选择了第二种。
// 重新计算提交索引
func (rf *Raft) changeCommitIndex() { // leader rule 4
rf.matchIndex[rf.me] = rf.lastIncludedIndex + len(rf.log) - 1 // 默认与自己匹配
matchIndex := append([]int{}, rf.matchIndex...) // 深拷贝
sort.Ints(matchIndex)
// If there exists an N such that N > commitIndex, a majority
// of matchIndex[i] ≥ N, and log[N].term == currentTerm:
// set commitIndex = N
for i := matchIndex[rf.peerNumber-rf.majorityPeer]; i > rf.commitIndex; i-- {
if rf.log[i-rf.lastIncludedIndex].Term == rf.currentTerm {
// DPrintf("%d change commindex from %d to %d\n", rf.me, rf.commitIndex, i)
rf.commitIndex = i
return
}
}
}
这说明很多时候代码实际的效果与预想的效果不太一样,另外vscode的运行调试功能真好用。
参考代码
// 节点状态
type PeerState int
const (
Follower PeerState = iota
Candidate
Leader
)
// 常量定义
const (
InvalidId = -1
NoneTerm = -1
HeartBeatInterval = 100 * time.Millisecond
)
type ApplyMsg struct {
CommandValid bool
Command interface{}
CommandIndex int
// For 2D:
SnapshotValid bool
Snapshot []byte
SnapshotTerm int
SnapshotIndex int
}
type logEntry struct {
Command interface{}
Term int
}
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
currentTerm int
votedFor int // 当前任期接受到的选票的候选者ID
log []logEntry
commitIndex int
lastApplied int
nextIndex []int
matchIndex []int
// 自定义变量
state PeerState
leaderId int // 未用到
// 使用三个变量只是表示更新选举定时器的三个条件,实际上用一个就可以
lastHeartBeat time.Time
lastVote time.Time
lastInstallSnapshot time.Time
// 快照相关变量
snapshot []byte
lastIncludedIndex int
lastIncludedTerm int
// 自定义常量(初始化一次后不再改变)
applyCh chan ApplyMsg
peerNumber int
majorityPeer int
}
func Min(n1, n2 int) int {
if n1 > n2 {
return n2
}
return n1
}
func Max(n1, n2 int) int {
if n1 > n2 {
return n1
}
return n2
}
// 将raft当前状态持久化
func (rf *Raft) persist() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
e.Encode(rf.lastIncludedIndex)
e.Encode(rf.lastIncludedTerm)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
// 读取raft状态
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var raftLog []logEntry
var lastIncludedIndex int
var lastIncludedTerm int
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil || d.Decode(&raftLog) != nil || d.Decode(&lastIncludedIndex) != nil || d.Decode(&lastIncludedTerm) != nil {
log.Panicf("state decode error")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.log = raftLog
rf.lastIncludedIndex = lastIncludedIndex
rf.lastIncludedTerm = lastIncludedTerm
rf.commitIndex = rf.lastIncludedIndex // 同时设置commitIndex
}
}
// 将raft当前状态与快照持久化
func (rf *Raft) persistStateAndSnapshot() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
e.Encode(rf.lastIncludedIndex)
e.Encode(rf.lastIncludedTerm)
state := w.Bytes()
rf.persister.SaveStateAndSnapshot(state, rf.snapshot)
}
// 比对raft state编码的lastIncludedIndex与快照中编码的lastIncludedIndex
func (rf *Raft) compareStateAndSnapshot() {
if rf.snapshot == nil || len(rf.snapshot) < 1 {
return
}
// DPrintf("exist snapshot\n")
r := bytes.NewBuffer(rf.snapshot)
d := labgob.NewDecoder(r)
var lastIncludedIndex int
if d.Decode(&lastIncludedIndex) != nil {
log.Panicf("compareStateAndSnapshot: snapshot decode error")
}
if rf.lastIncludedIndex != lastIncludedIndex {
WPrintf("snapshot lastIncludedIndex is different. snapshot:%v state:%v\n", lastIncludedIndex, rf.lastIncludedIndex)
// 丢掉快照lastIncludedIndex之前的日志并重新设置相关变量
rf.log = append([]logEntry{}, rf.log[lastIncludedIndex-rf.lastIncludedIndex:]...)
rf.lastIncludedIndex = lastIncludedIndex
rf.lastIncludedTerm = rf.log[0].Term // 日志0位的term
rf.commitIndex = rf.lastIncludedIndex
rf.persist()
}
}
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
return true
}
func (rf *Raft) Snapshot(index int, snapshot []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
if index <= rf.lastIncludedIndex { // 至少得比当前快照更新
WPrintf("server%v no use snapshot.this index:%v last index:%v\n", rf.me, rf.lastIncludedIndex, index)
return
}
// rf.log = rf.log[index-rf.lastIncludedIndex:]
rf.log = append([]logEntry{}, rf.log[index-rf.lastIncludedIndex:]...)
rf.lastIncludedIndex = index
rf.lastIncludedTerm = rf.log[0].Term // 日志0位的term
rf.snapshot = snapshot
rf.persistStateAndSnapshot()
// DPrintf("generate Snapshot. server id:%v Snapshot index:%v log len:%v commmit index:%v apply index:%v", rf.me, index, len(rf.log), rf.commitIndex, rf.lastApplied)
}
type RequestVoteArgs struct {
Term int
CandidateId int
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
Term int
VoteGranted bool
}
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []logEntry
LeaderCommit int
}
type AppendEntriesReply struct {
Term int
Success bool
ConflictIndex int
ConflictTerm int
}
type InstallSnapshotArgs struct {
Term int
LeaderId int
LastIncludedIndex int
LastIncludedTerm int
Data []byte
}
type InstallSnapshotReply struct {
Term int
}
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
if rf.currentTerm > args.Term { // RequestVote rule 1
reply.VoteGranted = false
return
}
needPersist := false // 是否需要持久化
if rf.currentTerm < args.Term { // set currentTerm = T, convert to follower
rf.currentTerm = args.Term
rf.votedFor = InvalidId // 更新votedFor变量
rf.state = Follower
needPersist = true
}
lastLogIndex := rf.lastIncludedIndex + len(rf.log) - 1 // 本地日志最大索引值
lastLogTerm := rf.log[lastLogIndex-rf.lastIncludedIndex].Term
// votedFor is null or candidateId
condition1 := (rf.votedFor == InvalidId) || (rf.votedFor == args.CandidateId)
// at least as up-to-date
condition2 := (args.LastLogTerm > lastLogTerm) || ((args.LastLogTerm == lastLogTerm) && (args.LastLogIndex >= lastLogIndex))
// DPrintf("arg:%v %v rf:%v %v\n", args.LastLogTerm, args.LastLogIndex, lastLogTerm, lastLogIndex)
reply.VoteGranted = condition1 && condition2
if reply.VoteGranted {
rf.votedFor = args.CandidateId // 设置本次选择候选者ID
rf.lastVote = time.Now() // 更新投票时间
needPersist = true
// DPrintf("%d vote to %d\n", rf.me, args.CandidateId)
}
if needPersist {
rf.persist()
}
}
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
reply.Success = true
if rf.currentTerm > args.Term { // AppendEntries rule 1
reply.Success = false
return
}
needPersist := false
if rf.currentTerm < args.Term { // set currentTerm = T, convert to follower
rf.currentTerm = args.Term
rf.votedFor = InvalidId // 更新votedFor变量
rf.state = Follower
needPersist = true
}
// 重置Follower状态
rf.lastHeartBeat = time.Now()
rf.leaderId = args.LeaderId
maxLocalLogIndex := rf.lastIncludedIndex + len(rf.log) - 1 // 本地最大日志索引
var matchResult bool
if maxLocalLogIndex < args.PrevLogIndex { // 不存在该日志项,匹配失败
matchResult = false
} else if rf.commitIndex >= args.PrevLogIndex { // 该日志项已提交,默认匹配成功
// DPrintf("commited log is same: PrevLogIndex %v lastIncludedIndex %v commitIndex %v\n", args.PrevLogIndex, rf.lastIncludedIndex, rf.commitIndex)
matchResult = true
} else if rf.lastIncludedIndex <= args.PrevLogIndex { // 比对PrevLogIndex处term是否一致
matchResult = (rf.log[args.PrevLogIndex-rf.lastIncludedIndex].Term == args.PrevLogTerm)
} else {
log.Panicf("unexpected condition. match error\n")
}
if !matchResult { // AppendEntries rule 2
reply.Success = false
// If a follower does not have prevLogIndex in its log, it should return with conflictIndex = len(log) and conflictTerm = None.
// If a follower does have prevLogIndex in its log, but the term does not match, it should return conflictTerm = log[prevLogIndex].Term, and then search its log for the first index whose entry has term equal to conflictTerm.
if maxLocalLogIndex < args.PrevLogIndex {
reply.ConflictIndex = rf.lastIncludedIndex + len(rf.log) // conflictIndex = len(log)
reply.ConflictTerm = NoneTerm
} else {
// next index相关,不应该涉及lastIncludedTerm
reply.ConflictTerm = rf.log[args.PrevLogIndex-rf.lastIncludedIndex].Term
reply.ConflictIndex = rf.commitIndex + 1 // ConflictIndex应大于commitIndex
for i := args.PrevLogIndex; i > rf.commitIndex+1; i-- {
if rf.log[i-1-rf.lastIncludedIndex].Term != reply.ConflictTerm { // 上一个entry term不匹配,该位置即为第一个为该term的entry
reply.ConflictIndex = i
break
}
}
}
DPrintf("prelog term doesn't match. server id:%v commit index:%d maxLocalLogIndex:%v args.PrevLogIndex:%v rf.lastIncludedIndex:%v ConflictTerm:%v ConflictIndex:%v \n", rf.me, rf.commitIndex, maxLocalLogIndex, args.PrevLogIndex, rf.lastIncludedIndex, reply.ConflictTerm, reply.ConflictIndex)
if needPersist {
rf.persist()
}
return
}
// DPrintf("%d preIndex %d entry size:%d\n", rf.me, args.PrevLogIndex, len(args.Entries))
// 找到第一个term不同的索引
lastNewEntryIndex := args.PrevLogIndex + len(args.Entries)
minLogIndex := Max(rf.commitIndex+1, args.PrevLogIndex+1) // 已提交日志的term一定一致,不用检查
maxLogIndex := Min(lastNewEntryIndex, maxLocalLogIndex) // 取本地日志与消息日志最大索引的较小值
diffItemIndex := maxLogIndex + 1
for i := minLogIndex; i <= maxLogIndex; i++ {
if rf.log[i-rf.lastIncludedIndex].Term != args.Entries[i-args.PrevLogIndex-1].Term {
diffItemIndex = i
break
}
}
// AppendEntries rule 3
if diffItemIndex != maxLogIndex+1 { // 只有存在不一致日志时才delete
rf.log = rf.log[:diffItemIndex-rf.lastIncludedIndex]
needPersist = true
}
if diffItemIndex-args.PrevLogIndex-1 <= len(args.Entries)-1 { // 起始索引小于最大索引,还有日志未加入本地日志
rf.log = append(rf.log, args.Entries[diffItemIndex-args.PrevLogIndex-1:]...) // AppendEntries rule 4
needPersist = true
}
// 取LeaderCommit与消息日志最大索引的较小值
if rf.commitIndex < args.LeaderCommit { // AppendEntries rule 5
rf.commitIndex = Min(args.LeaderCommit, lastNewEntryIndex)
// DPrintf("%d change commit index to %d LeaderCommit:%d lastNewEntryIndex:%d\n", rf.me, rf.commitIndex, args.LeaderCommit, lastNewEntryIndex)
}
if needPersist {
rf.persist()
}
}
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
if rf.currentTerm > args.Term {
return
}
if rf.currentTerm < args.Term { // // set currentTerm = T, convert to follower
rf.currentTerm = args.Term
rf.votedFor = InvalidId // 更新votedFor变量
rf.state = Follower
rf.persist() // 直接持久化
}
rf.lastInstallSnapshot = time.Now() // 更新接收快照时间
rf.leaderId = args.LeaderId
logIndex := args.LastIncludedIndex - rf.lastIncludedIndex // leader快照与本地快照对比
if logIndex < 0 {
// WPrintf("local server snapshot is newer. server id:%v lastIncludedIndex:%v log len:%v\n", rf.me, rf.lastIncludedIndex, len(rf.log))
return
}
if logIndex < len(rf.log) && rf.log[logIndex].Term == args.LastIncludedTerm { // step 5
DPrintf("same log entry. server id:%v lastIncludedIndex:%v log len:%v\n", rf.me, rf.lastIncludedIndex, len(rf.log))
return
}
// 设置快照相关状态并持久化
rf.snapshot = args.Data
rf.lastIncludedIndex = args.LastIncludedIndex
rf.lastIncludedTerm = args.LastIncludedTerm
rf.log = append([]logEntry{}, logEntry{Term: rf.lastIncludedTerm}) // 删除所有日志,重新加入0位日志
// 更新日志commitIndex
rf.commitIndex = rf.lastIncludedIndex
rf.persistStateAndSnapshot()
DPrintf("%v recv snapshot. lastIncludedIndex:%v log len:%v commit index:%v apply index:%v\n", rf.me, rf.lastIncludedIndex, len(rf.log), rf.commitIndex, rf.lastApplied)
}
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
// 在远程调用函数中解锁加锁,便于使用defer
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
rf.mu.Unlock()
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
rf.mu.Lock()
return ok
}
// 在远程调用函数中解锁加锁,便于使用defer
func (rf *Raft) sendInstallSnapshot(server int, args *InstallSnapshotArgs, reply *InstallSnapshotReply) bool {
rf.mu.Unlock()
ok := rf.peers[server].Call("Raft.InstallSnapshot", args, reply)
rf.mu.Lock()
return ok
}
func (rf *Raft) GetState() (int, bool) {
rf.mu.Lock()
term := rf.currentTerm
isleader := (rf.state == Leader)
rf.mu.Unlock()
return term, isleader
}
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Leader {
isLeader = false
return index, term, isLeader
}
entry := logEntry{Term: rf.currentTerm, Command: command}
rf.log = append(rf.log, entry)
index = rf.lastIncludedIndex + len(rf.log) - 1
term = rf.currentTerm
// // 同时更新自身nextIndex与matchIndex,便于计算commit index
// rf.nextIndex[rf.me] = rf.lastIncludedIndex + len(rf.log)
// rf.matchIndex[rf.me] = rf.lastIncludedIndex + len(rf.log) - 1
rf.persist()
go rf.agreementTask() // 进行一轮日志协商
return index, term, isLeader
}
func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
}
func (rf *Raft) killed() bool {
z := atomic.LoadInt32(&rf.dead)
return z == 1
}
// 重新计算提交索引
func (rf *Raft) changeCommitIndex() { // leader rule 4
rf.matchIndex[rf.me] = rf.lastIncludedIndex + len(rf.log) - 1 // 默认与自己匹配
matchIndex := append([]int{}, rf.matchIndex...) // 深拷贝
sort.Ints(matchIndex)
// If there exists an N such that N > commitIndex, a majority
// of matchIndex[i] ≥ N, and log[N].term == currentTerm:
// set commitIndex = N
for i := matchIndex[rf.peerNumber-rf.majorityPeer]; i > rf.commitIndex; i-- {
if rf.log[i-rf.lastIncludedIndex].Term == rf.currentTerm {
// DPrintf("%d change commindex from %d to %d\n", rf.me, rf.commitIndex, i)
rf.commitIndex = i
return
}
}
}
// 进行一次日志协商
func (rf *Raft) agreementTask() {
for i := 0; i < rf.peerNumber; i++ {
if i == rf.me {
continue
}
go func(server int) {
rf.mu.Lock()
defer rf.mu.Unlock()
for !rf.killed() {
if rf.state != Leader {
return
}
if rf.nextIndex[server] <= rf.lastIncludedIndex { // 所需日志包含在快照中
if rf.snapshot == nil || len(rf.snapshot) < 1 {
log.Panicf("agreementTask: wrong snapshot.\n")
}
DPrintf("%v send snapshot to %v LastIncludedInde:%v\n", rf.me, server, rf.lastIncludedIndex)
args := InstallSnapshotArgs{Term: rf.currentTerm, LeaderId: rf.me, LastIncludedIndex: rf.lastIncludedIndex, LastIncludedTerm: rf.lastIncludedTerm, Data: rf.snapshot}
reply := InstallSnapshotReply{}
res := rf.sendInstallSnapshot(server, &args, &reply) // 在函数中解锁加锁
if !res {
// DPrintf("%v send InstallSnapshot to %v failed\n", server, rf.me)
return
}
if rf.state != Leader {
return
}
if args.Term != rf.currentTerm { // old rpc reply
DPrintf("old InstallSnapshot rpc reply\n")
return
}
if rf.currentTerm < reply.Term { // set currentTerm = T, convert to follower
rf.currentTerm = reply.Term
rf.votedFor = InvalidId
rf.state = Follower
rf.persist()
return
}
// 发送快照成功
rf.matchIndex[server] = Max(rf.matchIndex[server], args.LastIncludedIndex)
rf.nextIndex[server] = rf.matchIndex[server] + 1
rf.changeCommitIndex()
} else {
args := AppendEntriesArgs{Term: rf.currentTerm, LeaderId: rf.me, LeaderCommit: rf.commitIndex}
args.PrevLogIndex = rf.nextIndex[server] - 1
args.PrevLogTerm = rf.log[args.PrevLogIndex-rf.lastIncludedIndex].Term
args.Entries = append([]logEntry{}, rf.log[rf.nextIndex[server]-rf.lastIncludedIndex:]...) // 深拷贝
reply := AppendEntriesReply{}
res := rf.sendAppendEntries(server, &args, &reply) // 在函数中解锁加锁
if !res {
// DPrintf("%v send AppendEntries to %v failed\n", server, rf.me)
return
}
if rf.state != Leader {
return
}
if args.Term != rf.currentTerm { // old rpc reply
DPrintf("old AppendEntries rpc reply\n")
return
}
if reply.Success {
// 仔细设置nextIndex与matchIndex
rf.matchIndex[server] = Max(rf.matchIndex[server], args.PrevLogIndex+len(args.Entries))
rf.nextIndex[server] = rf.matchIndex[server] + 1
rf.changeCommitIndex()
return
}
if rf.currentTerm < reply.Term { // set currentTerm = T, convert to follower
rf.currentTerm = reply.Term
rf.votedFor = InvalidId
rf.state = Follower
rf.persist()
return
}
// Upon receiving a conflict response, the leader should first search its log for conflictTerm. If it finds an entry in its log with that term, it should set nextIndex to be the one beyond the index of the last entry in that term in its log.
// If it does not find an entry with that term, it should set nextIndex = conflictIndex.
if reply.ConflictTerm == NoneTerm {
rf.nextIndex[server] = reply.ConflictIndex
} else {
rf.nextIndex[server] = reply.ConflictIndex
for i := args.PrevLogIndex; i > rf.lastIncludedIndex; i-- {
if rf.log[i-rf.lastIncludedIndex].Term == reply.ConflictTerm {
rf.nextIndex[server] = i
break
}
}
}
if rf.nextIndex[server] < 1 {
log.Panicf("next index set wrong value.")
}
DPrintf("next index retry. cur term:%v leader:%d server:%d commit index:%d next index:%d\n", rf.currentTerm, rf.me, server, rf.commitIndex, rf.nextIndex[server])
}
}
}(i)
}
}
// 向各节点发送心跳消息
func (rf *Raft) heartBeatTask() {
for !rf.killed() {
rf.mu.Lock()
flag := (rf.state == Leader)
rf.mu.Unlock()
if !flag {
return
}
go rf.agreementTask()
time.Sleep(HeartBeatInterval)
}
}
// 向各节点发送投票信息
func (rf *Raft) sendVoteTask(args RequestVoteArgs) {
ticket := 1
for i := 0; i < rf.peerNumber; i++ {
if i == rf.me {
continue
}
go func(server int) {
reply := RequestVoteReply{}
res := rf.sendRequestVote(server, &args, &reply)
if !res {
// DPrintf("sendRequestVote failed server:%d me:%d\n", server, rf.me)
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Candidate { // 若当前状态不是候选者则直接返回
return
}
if args.Term != rf.currentTerm {
DPrintf("old RequestVote reply\n")
return
}
if reply.VoteGranted {
ticket++
if ticket >= rf.majorityPeer { // 得到超过半数投票,转变为leader,并开启心跳任务
rf.state = Leader
rf.leaderId = rf.me
// 初始化Leader专属变量
rf.nextIndex = make([]int, rf.peerNumber)
nextIndex := rf.lastIncludedIndex + len(rf.log)
for i := 0; i < rf.peerNumber; i++ {
rf.nextIndex[i] = nextIndex
}
rf.matchIndex = make([]int, rf.peerNumber)
DPrintf("%d become leader. commit index:%d next index:%d\n", rf.me, rf.commitIndex, rf.nextIndex[0])
go rf.heartBeatTask()
}
} else if rf.currentTerm < reply.Term { // 返回的任期大于本身任期,转变为Follower,更新任期
rf.currentTerm = reply.Term
rf.state = Follower
rf.votedFor = InvalidId
rf.persist()
}
}(i)
}
}
func (rf *Raft) ticker() {
for !rf.killed() {
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// time.Sleep().
sleepTime := time.Duration(rand.Intn(300)+300) * time.Millisecond // 300~600ms
time.Sleep(sleepTime)
rf.mu.Lock() // 读取状态前加锁
// && time.Since(rf.lastInstallSnapshot) > sleepTime 论文中没写,就不加上去了
if rf.state != Leader && time.Since(rf.lastHeartBeat) > sleepTime && time.Since(rf.lastVote) > sleepTime {
rf.currentTerm++
rf.votedFor = rf.me
rf.lastHeartBeat = time.Now()
rf.state = Candidate
lastLogIndex := rf.lastIncludedIndex + len(rf.log) - 1
lastLogTerm := rf.log[lastLogIndex-rf.lastIncludedIndex].Term
args := RequestVoteArgs{Term: rf.currentTerm, CandidateId: rf.me, LastLogIndex: lastLogIndex, LastLogTerm: lastLogTerm}
// DPrintf("%d join vote term:%d\n", rf.me, rf.currentTerm)
rf.persist()
go rf.sendVoteTask(args)
}
rf.mu.Unlock()
}
}
// 向service发送命令
func (rf *Raft) applyTask() {
for !rf.killed() {
var msg ApplyMsg
sendMsg := false
rf.mu.Lock()
if rf.lastApplied < rf.commitIndex {
sendMsg = true
if rf.lastApplied < rf.lastIncludedIndex { // 发送快照
rf.lastApplied = rf.lastIncludedIndex
msg = ApplyMsg{CommandValid: false, SnapshotValid: true, Snapshot: rf.snapshot, SnapshotIndex: rf.lastIncludedIndex, SnapshotTerm: rf.lastIncludedTerm}
DPrintf("applySnapshot. server id:%v commitIndex:%v lastApplied:%v lastIncludedIndex:%v\n", rf.me, rf.commitIndex, rf.lastApplied, rf.lastIncludedIndex)
} else { // 发送日志
rf.lastApplied++
msg = ApplyMsg{CommandValid: true, Command: rf.log[rf.lastApplied-rf.lastIncludedIndex].Command, CommandIndex: rf.lastApplied}
}
}
rf.mu.Unlock()
if sendMsg { // 向service发送消息
rf.applyCh <- msg
} else { // 此次未发送消息,休眠10ms后再次查询
time.Sleep(10 * time.Millisecond)
}
}
}
func Make(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
rf.currentTerm = 0
rf.votedFor = InvalidId
rf.log = nil
rf.commitIndex = 0
rf.lastApplied = 0
rf.nextIndex = nil
rf.matchIndex = nil
rf.state = Follower
rf.leaderId = InvalidId
rf.lastHeartBeat = time.Now()
rf.lastVote = time.Now()
rf.lastInstallSnapshot = time.Now()
rf.lastIncludedIndex = 0
rf.lastIncludedTerm = 0
rf.log = append(rf.log, logEntry{Term: 0}) // 增加一条无效命令,作为最开始的lastInclude项
rf.applyCh = applyCh
rf.peerNumber = len(peers)
rf.majorityPeer = (len(peers) / 2) + 1
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
rf.snapshot = persister.ReadSnapshot()
// rf.compareStateAndSnapshot()
rand.Seed(time.Now().Unix()) // 设置随机种子
DPrintf("%v start. start index:%v log len:%v commit index:%v term:%v", rf.me, rf.lastIncludedIndex, len(rf.log), rf.commitIndex, rf.currentTerm)
// start ticker goroutine to start elections
go rf.ticker()
go rf.applyTask()
return rf
}