java8 stream四大接口_【JDK8特性】Stream接口详解
一、概念普及
Java8新添加了一个特性:流Stream。Stream让开发者能够以一种声明的方式处理数据源(集合、数组等),它专注于对数据源进行各种高效的聚合操作(aggregate operation)和大批量数据操作 (bulk data operation)。
Stream API将处理的数据源看做一种Stream(流),Stream(流)在Pipeline(管道)中传输和运算,支持的运算包含筛选、排序、聚合等,当到达终点后便得到最终的处理结果。
二、特性概述
元素:Stream是一个来自数据源的元素队列,Stream本身并不存储元素。
数据源:(即Stream的来源)包含集合、数组、I/O channel、generator(发生器)等。
聚合操作:类似SQL中的filter、map、find、match、sorted等操作
管道运算:Stream在Pipeline中运算后返回Stream对象本身,这样多个操作串联成一个Pipeline,并形成fluent风格的代码。这种方式可以优化操作,如延迟执行(laziness)和短路( short-circuiting)。
内部迭代:不同于java8以前对集合的遍历方式(外部迭代),Stream API采用访问者模式(Visitor)实现了内部迭代。
并行运算:Stream API支持串行(stream() )或并行(parallelStream() )的两种操作方式。
注意:
1、stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果;
2、stream不会改变数据源,通常情况下会产生一个新的集合;
3、stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
4、对stream操作分为终端操作和中间操作,那么这两者分别代表什么呢?
终端操作:会消费流,这种操作会产生一个结果的,如果一个流被消费过了,那它就不能被重用的。
中间操作:中间操作会产生另一个流。因此中间操作可以用来创建执行一系列动作的管道。
一个特别需要注意的点是:中间操作不是立即发生的。相反,当在中间操作创建的新流上执行完终端操作后,中间操作指定的操作才会发生。
中间操作是延迟发生的,中间操作的延迟行为主要是让流API能够更加高效地执行。
5、stream不可复用,对一个已经进行过终端操作的流再次调用,会抛出异常。
三、创建Stream
1、通过数组创建流
public static voidmain(String[] args) {//1.通过Arrays.stream//1.1基本类型
int[] arr = new int[]{1,2,34,5};
IntStream intStream=Arrays.stream(arr);//1.2引用类型
Student[] studentArr = new Student[]{new Student("s1",29),new Student("s2",27)};
Stream studentStream =Arrays.stream(studentArr);//2.通过Stream.of
Stream stream1 = Stream.of(1,2,34,5,65);//注意生成的是int[]的流
Stream stream2 =Stream.of(arr,arr);
stream2.forEach(System.out::println);
}
2、通过集合创建流
public static voidmain(String[] args) {
List strs = Arrays.asList("11212","dfd","2323","dfhgf");//创建普通流
Stream stream =strs.stream();//创建并行流
Stream stream1 =strs.parallelStream();
}
四、流API详述
1、BaseStream详述
BaseStream是最基础的接口,提供了流的基本功能。BaseStream接口源码如下:
public interface BaseStream> extendsAutoCloseable {
Iteratoriterator();
Spliteratorspliterator();booleanisParallel();
S sequential();
S parallel();
S unordered();
S onClose(Runnable closeHandler);
@Overridevoidclose();
}

2、Stream详述
Stream接口的源码如下:
public interface Stream extends BaseStream>{
Stream filter(Predicate super T>predicate); Stream map(Function super T, ? extends R>mapper);
IntStream mapToInt(ToIntFunction super T>mapper);
LongStream mapToLong(ToLongFunction super T>mapper);
DoubleStream mapToDouble(ToDoubleFunction super T>mapper); Stream flatMap(Function super T, ? extends Stream extends R>>mapper);
IntStream flatMapToInt(Function super T, ? extends IntStream>mapper);
LongStream flatMapToLong(Function super T, ? extends LongStream>mapper);
DoubleStream flatMapToDouble(Function super T, ? extends DoubleStream>mapper);
Streamdistinct();
Streamsorted();
Stream sorted(Comparator super T>comparator);
Stream peek(Consumer super T>action);
Stream limit(longmaxSize);
Stream skip(longn);void forEach(Consumer super T>action);void forEachOrdered(Consumer super T>action);
Object[] toArray(); A[] toArray(IntFunctiongenerator);
T reduce(T identity, BinaryOperatoraccumulator);
Optional reduce(BinaryOperatoraccumulator);U reduce(U identity,
BiFunctionaccumulator,
BinaryOperatorcombiner); R collect(Suppliersupplier,
BiConsumeraccumulator,
BiConsumercombiner); R collect(Collector super T, A, R>collector);
Optional min(Comparator super T>comparator);
Optional max(Comparator super T>comparator);longcount();boolean anyMatch(Predicate super T>predicate);boolean allMatch(Predicate super T>predicate);boolean noneMatch(Predicate super T>predicate);
OptionalfindFirst();
OptionalfindAny();//Static factories
public static Builderbuilder() {return new Streams.StreamBuilderImpl<>();
}public static Streamempty() {return StreamSupport.stream(Spliterators.emptySpliterator(), false);
}public static Streamof(T t) {return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false);
}
@SafeVarargs
@SuppressWarnings("varargs") //Creating a stream from an array is safe
public static Streamof(T... values) {returnArrays.stream(values);
}public static Stream iterate(final T seed, final UnaryOperatorf) {
Objects.requireNonNull(f);final Iterator iterator = new Iterator() {
@SuppressWarnings("unchecked")
T t=(T) Streams.NONE;
@Overridepublic booleanhasNext() {return true;
}
@OverridepublicT next() {return t = (t == Streams.NONE) ?seed : f.apply(t);
}
};returnStreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator,
Spliterator.ORDERED| Spliterator.IMMUTABLE), false);
}public static Stream generate(Suppliers) {
Objects.requireNonNull(s);returnStreamSupport.stream(new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);
}public static Stream concat(Stream extends T> a, Stream extends T>b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator) a.spliterator(), (Spliterator) b.spliterator());
Stream stream = StreamSupport.stream(split, a.isParallel() ||b.isParallel());returnstream.onClose(Streams.composedClose(a, b));
}
}
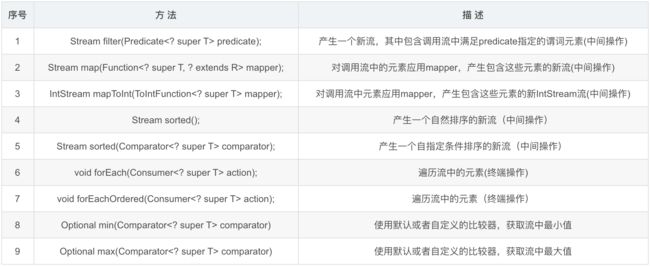
五、Stream流操作
首先提供示例实体列定义以供后续使用:
@Setter
@Getterpublic classPerson {privateString name;private intsalary;public Person(String name, intsalary) {this.name =name;this.salary =salary;
}
}
1、流的筛选与匹配
流的筛选:即filter,是按照一定的规则校验流中的元素,将符合条件的元素提取出来的操作。filter通常要配合collect(收集),将筛选结果收集成一个新的集合。
流的匹配:与筛选类似,也是按照规则提取元素,不同的是,匹配返回的是单个元素或单个结果。
1.1、普通筛选
public static voidmain(String[] args) {
List intList = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
List collect = intList.stream().filter(x -> x > 7).collect(Collectors.toList());
System.out.println(collect);
}//预期结果:[8,9]
1.2、引用类型筛选
public static voidmain(String[] args) {
List collect = personList.stream().filter(x -> x.getSalary() > 8000).collect(Collectors.toList());//预期结果:符合条件的实体类的集合
}
1.3、匹配
public static voidmain(String[] args) {
List list = Arrays.asList(7,6,9,3,8,2,1);//匹配第一个
Optional findFirst = list.stream().filter(x -> x > 6).findFirst();//匹配任意(适用于并行流)
Optional findAny = list.parallelStream().filter(x -> x > 6).findAny();//是否包含
boolean anyMatch = list.stream().anyMatch(x -> x < 6);
System.out.println(findFirst);
System.out.println(findAny);
System.out.println(anyMatch);
}
}//预期结果://1、Optional[7]//2、并行流处理,结果不确定//3、true
2、聚合
在stream中,针对流进行计算后得出结果,例如求和、求最值等,这样的操作被称为聚合操作。聚合操作在广义上包含了max、min、count等方法和reduce、collect。
2.1、max、min和count
2.1.1、获取String集合中最长的元素
public static voidmain(String[] args) {
List list = Arrays.asList("adnm","admmt","pot");
Optional max =list.stream().max(Comparator.comparing(String::length));
System.out.println(max);
}//预期结果:Optional[admmt]
2.1.2、获取Integer集合中的最大值
public static voidmain(String[] args) {
List list = Arrays.asList(7,6,9);
Optional reduce = list.stream().max(new Comparator() {
@Overridepublic intcompare(Integer o1, Integer o2) {returno1.compareTo(o2);
}
});
System.out.println(reduce);
}//输出结果:Optional[9]//或者写法为:
Optional reduce = list.stream().max((o1,o2) -> o1.compareTo(o2));
2.1.3、对象集合最值
public static voidmain(String[] args) {
list.add(new Person("a", 4));
list.add(new Person("b", 4));
list.add(new Person("c", 6));
Optional max =list.stream().max(Comparator.comparingInt(Person::getSalary));
System.out.println(max.get().getSalary());
}//输出结果:6,最小值将max改为min即可
2.1.4、count方法
public static voidmain(String[] args) {
List list = Arrays.asList(7,6,9);long count = list.stream().filter(x -> x > 6).count();
System.out.println(count);
}//预期结果:2
2.2、缩减(reduce)
顾名思义,缩减操作,就是把一个流缩减成一个值,比如对一个集合求和、求乘积等。Stream流定义了三个reduce:
public interface Stream extends BaseStream>{//方法1
T reduce(T identity, BinaryOperatoraccumulator);//方法2
Optional reduce(BinaryOperatoraccumulator);//方法3
U reduce(U identity, BiFunctionaccumulator, BinaryOperatorcombiner);
}
2.2.1、reduce(T identity, BinaryOperatoraccumulator)
第一种缩减方法接收一个BinaryOperator accumulator function(二元累加计算函数)和identity(标示值)为参数,返回值是一个T类型(代表流中的元素类型)的对象。accumulator代表操作两个值并得到结果的函数。identity按照accumulator函数的规则参与计算,假如函数是求和运算,那么函数的求和结果加上identity就是最终结果,假如函数是求乘积运算,那么函数结果乘以identity就是最终结果。
public static void main(String[] args) throwsException {
List list = Arrays.asList(1, 3, 2);//求和
Integer sum = list.stream().reduce(1, (x, y) -> x +y);//结果是7,也就是list元素求和再加上1
System.out.println(sum);//写法2
Integer sum2 = list.stream().reduce(1, Integer::sum);
System.out.println(sum2);//结果:7//求最值
Integer max = list.stream().reduce(6, (x, y) -> x > y ?x : y);
System.out.println(max);//结果:6//写法2
Integer max2 = list.stream().reduce(1, Integer::max);
System.out.println(max2);//结果:3
}
2.2.2、reduce(BinaryOperatoraccumulator)
第二种缩减方式不同之处是没有identity,返回值是Optional(JDK8新类,可以存放null)。
public classMyTest {public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));//求和//预期结果:Optional[24900]
System.out.println(personList.stream().map(Person::getSalary).reduce(Integer::sum));//求最值-方式1
Person person = personList.stream().reduce((p1, p2) -> p1.getSalary() > p2.getSalary() ?p1 : p2).get();//预期结果:Lily:9000
System.out.println(person.getName() + ":" +person.getSalary());//求最值-方式2//预期结果:Optional[9000]
System.out.println(personList.stream().map(Person::getSalary).reduce(Integer::max));//求最值-方式3:
System.out.println(personList.stream().max(Comparator.comparingInt(Person::getSalary)).get().getSalary());
}
}
2.2.3、reduce(U identity, BiFunctionaccumulator, BinaryOperatorcombiner)
第三种缩减操作接收三个参数:标示值(identity)、二元操作累加器(BiFunction accumulator)、二元组合方法(BinaryOperator<.u> combiner)。其中combiner只有在并行流中起作用。
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));//求和-方式1
Integer sumSalary = personList.stream().reduce(0, (sum, p) -> sum +=p.getSalary(),
(sum1, sum2)-> sum1 +sum2);
System.out.println(sumSalary);//24900//求和-方式2
Integer sumSalary2 = personList.stream().reduce(0, (sum, p) -> sum +=p.getSalary(), Integer::sum);
System.out.println(sumSalary2);//24900//求最大值-方式1
Integer maxSalary = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ?max : p.getSalary(),Integer::max);
System.out.println(maxSalary);//9000//求最大值-方式2
Integer maxSalary2 = personList.stream().reduce((max, p) -> max > p.getSalary() ? max : p.getSalary(),(max1, max2) -> max1 > max2 ?max1 : max2);
System.out.println(maxSalary2);//9000
}
验证一下combiner在串行流中不起作用而在并行流中起作用:
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));//验证combiner-串行流
Integer sumSalary = personList.stream().reduce(0, (sum, p) ->{
System.out.format("accumulator: sum=%s; person=%s\n", sum, p.getName());return sum +=p.getSalary();
} , (sum1, sum2)->{
System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2);return sum1 +sum2;
});
System.out.println("总和:" +sumSalary);//输出结果://accumulator: sum=0; person=Tom//accumulator: sum=8900; person=Jack//accumulator: sum=15900; person=Lily//总和:24900//验证combiner-并行流
Integer sumSalary2 = personList.parallelStream().reduce(0, (sum, p) ->{
System.out.format("accumulator: sum=%s; person=%s\n", sum, p.getName());return sum +=p.getSalary();
} , (sum1, sum2)->{
System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2);return sum1 +sum2;
});
System.out.println("总和:" +sumSalary2);//输出结果://accumulator: sum=0; person=Jack//accumulator: sum=0; person=Tom//accumulator: sum=0; person=Lily//combiner: sum1=7000; sum2=9000//combiner: sum1=8900; sum2=16000//总和:24900
}
由上面输出结果可见,并行流中,combiner方法被调用,将并行的累加器分别获得的结果组合起来得到最终结果。
2.3、收集(collect)
collect操作可以接受各种方法作为参数,将流中的元素汇集。
public interface Stream extends BaseStream>{ R collect(Supplier supplier, BiConsumeraccumulator, BiConsumercombiner); R collect(Collector super T, A, R>collector);
}
观察上面接口定义可知,collect使用Collector作为参数,Collector包含四种不同的操作:supplier(初始构造器), accumulator(累加器), combiner(组合器), finisher(终结者)。实际上,Collectors类内置了很多收集操作。
2.3.1、averaging系列
averagingDouble、averagingInt、averagingLong三个方法处理过程是相同的,都是返回stream的平均值,只是返回结果的类型不同。
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));
Double averageSalary=personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
System.out.println(averageSalary);//结果:8300
}
2.3.2、summarizing系列
summarizingDouble、summarizingInt、summarizingLong三个方法可以返回stream的一个统计结果map,不同之处也是结果map中的value类型不一样,分别是double、int、long类型。
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));
DoubleSummaryStatistics collect=personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println(collect);//输出结果://DoubleSummaryStatistics{count=3, sum=24900.000000, min=7000.000000, average=8300.000000, max=9000.000000}
}
2.3.3、joining
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));
String names= personList.stream().map(p -> p.getName()).collect(Collectors.joining(","));
System.out.println(names);
}
2.3.4、reduce
Collectors内置reduce,可以完成自定义归约,如下面例子:
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));
Integer sumSalary= personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> i +j));
System.out.println(sumSalary);//结果:24900
Optional sumSalary2 =list.stream().map(Person::getSalary).reduce(Integer::sum);
System.out.println(sumSalary2);//Optional[24900]
}
2.3.5、groupingBy
groupingBy方法可以将stream中的元素按照规则进行分组,类似mysql中groupBy语句。
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));//单级分组
Map> group =personList.stream().collect(Collectors.groupingBy(Person::getName));
System.out.println(group);//输出结果:{Tom=[mutest.Person@7cca494b],//Jack=[mutest.Person@7ba4f24f],Lily=[mutest.Person@3b9a45b3]}//多级分组:先以name分组,再以salary分组:
Map>> group2 =personList.stream()
.collect(Collectors.groupingBy(Person::getName, Collectors.groupingBy(Person::getSalary)));
System.out.println(group2);//输出结果:{Tom={8900=[mutest.Person@7cca494b]},Jack={7000=[mutest.Person@7ba4f24f]},Lily={9000=[mutest.Person@3b9a45b3]}}
}
2.3.6、toList、toSet、toMap
Collectors内置的toList等方法可以十分便捷地将stream中的元素收集成想要的集合,是一个非常常用的功能,通常会配合filter、map等方法使用。
public static voidmain(String[] args) {
List personList = new ArrayList();
personList.add(new Person("Tom", 8900));
personList.add(new Person("Jack", 7000));
personList.add(new Person("Lily", 9000));
personList.add(new Person("Lily", 5000));//toList
List names =personList.stream().map(Person::getName).collect(Collectors.toList());
System.out.println(names);//toSet
Set names2 =personList.stream().map(Person::getName).collect(Collectors.toSet());
System.out.println(names2);//toMap
Map personMap = personList.stream().collect(Collectors.toMap(Person::getName, p ->p));
System.out.println(personMap);
}
2.4、映射(map)
Stream流中,map可以将一个流的元素按照一定的映射规则映射到另一个流中。
2.4.1、数据>>数据
public static voidmain(String[] args) {
String[] strArr= { "abcd", "bcdd", "defde", "ftr"};
Arrays.stream(strArr).map(x->x.toUpperCase()).forEach(System.out::println);
}//预期结果:ABCD BCDD DEFDE FTR
2.4.2、对象集合>>数据
public static voidmain(String[] args) {//为节省篇幅,personList复用了演示数据中的personList
personList.stream().map(person ->person.getSalary()).forEach(System.out::println);
}//预期结果:8900 7000 9000
2.4.3、对象集合>>对象集合
public static voidmain(String[] args) {//为节省篇幅,personList复用了演示数据中的personList
List collect = personList.stream().map(person ->{
person.setName(person.getName());
person.setSalary(person.getSalary()+ 10000);returnperson;
}).collect(Collectors.toList());
System.out.println(collect.get(0).getSalary());
System.out.println(personList.get(0).getSalary());
List collect2 = personList.stream().map(person ->{
Person personNew= new Person(null, 0);
personNew.setName(person.getName());
personNew.setSalary(person.getSalary()+ 10000);returnpersonNew;
}).collect(Collectors.toList());
System.out.println(collect2.get(0).getSalary());
System.out.println(personList.get(0).getSalary());
}//预期结果://1、18900 18900,说明这种写法改变了原有的personList。//2、18900 8900,说明这种写法并未改变原有personList。
2.5、排序(sorted)
Sorted方法是对流进行排序,并得到一个新的stream流,是一种中间操作。Sorted方法可以使用自然排序或特定比较器。
2.5.1、自然排序
public static voidmain(String[] args) {
String[] strArr= { "abc", "m", "M", "bcd"};
System.out.println(Arrays.stream(strArr).sorted().collect(Collectors.toList()));
}//预期结果:[M, abc, bcd, m]
2.5.2、自定义排序
public static voidmain(String[] args) {
String[] strArr= { "ab", "bcdd", "defde", "ftr"};//1、按长度自然排序,即长度从小到大
Arrays.stream(strArr).sorted(Comparator.comparing(String::length)).forEach(System.out::println);//2、按长度倒序,即长度从大到小
Arrays.stream(strArr).sorted(Comparator.comparing(String::length).reversed()).forEach(System.out::println);//3、首字母倒序
Arrays.stream(strArr).sorted(Comparator.reverseOrder()).forEach(System.out::println);//4、首字母自然排序
Arrays.stream(strArr).sorted(Comparator.naturalOrder()).forEach(System.out::println);
}/*** thenComparing
* 先按照首字母排序
* 之后按照String的长度排序*/@Testpublic voidtestSorted3_(){
Arrays.stream(arr1).sorted(Comparator.comparing(this::com1).thenComparing(String::length)).forEa
ch(System.out::println);
}public charcom1(String x){return x.charAt(0);
}//输出结果://1、ftr bcdd defde//2、defde bcdd ftr ab//3、ftr defde bcdd ab//4、ab bcdd defde ftr
2.6、提取流和组合流
public static voidmain(String[] args) {
String[] arr1= {"a","b","c","d"};
String[] arr2= {"d","e","f","g"};
String[] arr3= {"i","j","k","l"};/*** 可以把两个stream合并成一个stream(合并的stream类型必须相同),只能两两合并
* 预期结果:a b c d e f g*/Stream stream1 =Stream.of(arr1);
Stream stream2 =Stream.of(arr2);
Stream.concat(stream1,stream2).distinct().forEach(System.out::println);/*** limit,限制从流中获得前n个数据
* 预期结果:1 3 5 7 9 11 13 15 17 19*/Stream.iterate(1,x->x+2).limit(10).forEach(System.out::println);/*** skip,跳过前n个数据
* 预期结果:3 5 7 9 11*/Stream.iterate(1,x->x+2).skip(1).limit(5).forEach(System.out::println);
}