文本信息抽取 | 基于 LSTM 的命名实体识别
Hi,大家好啊!本文主要了解文本信息抽取的内容,以《基于LSTM的命名实体识别》这一项目作为示例展示文本信息抽取的意义。
目录
一、Bi-LSTM—CRF 模型
二、LSTM 介绍
三、基于LSTM的命名实体识别
1. 导入相关库
2. 数据加载
3. 构造dataloder
4. 网络构建
5. 网络配置
6. 模型训练
7. 模型评估
8. 模型预测
一、Bi-LSTM—CRF 模型
命名实体识别任务的一个经典解决方法是 Bi-LSTM—CRF 模型。它由双向长短期记忆网络叠加一个CRF层组成。结构如下图:

二、LSTM 介绍
长短期记忆 (Long Short-Term Memory, LSTM) 是一种时间递归神经网络(RNN),它是一种基于机器学习理论的循环网络时间序列预测方法。该模型可有效处理并解决RNN中人为很难实现的延长时间任务的问题,并预测时间序列中间隔和延迟非常长的重要事件,同时削减了RNN中梯度消失问题对预测研究的影响,总的来说LSTM模型是一种特殊的RNN循环神经网络。
RNN循环神经网络结构如图所示。
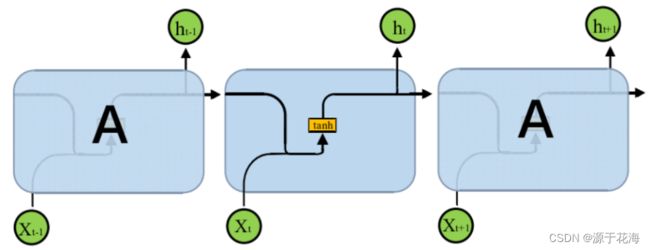

在原始的 RNN 循环神经网络训练中,随着训练时间的加长以及网络层数的增多,很容易出现梯度爆炸或者梯度消失的问题,导致无法处理较长序列数据,进而无法获取长距离数据的信息。据此 LSTM 神经网络在 RNN 中增加一个神经状态,用来储存长期的数据时序特征,其中增加3个开关控制内部神经元参数变化,采用一种“门”的结构让信息选择式通过,分别是遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate),适合处理和预测较长时间序列数据的预测工作,能够深入挖掘存储于数据中的时序信息和语义信息。长短时记忆神经网络结构如上图1所示。
如下图所示模型中间矩形方框被称为记忆块(Memory block),记忆块内上方如同传送带的水平线可以控制信息传递给下一个状态。其中  表示上一时刻的输出,
表示上一时刻的输出, 为当前最终输出,
为当前最终输出, 表示当前状态的数据输入,
表示当前状态的数据输入, 为遗忘门输出,
为遗忘门输出,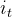 为输入门输出,
为输入门输出, 为当前输出门的输出,
为当前输出门的输出,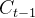 表示上一时刻结构的单元状态,
表示上一时刻结构的单元状态,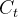 表示当前结构的单元状态,
表示当前结构的单元状态,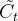 表示当前暂时单元状态,
表示当前暂时单元状态, 表示神经网络层,
表示神经网络层, 、
、![]() 分别为加法和乘法运算操作符号。
分别为加法和乘法运算操作符号。
其中, 一般选择 Sigmoid 作为激励函数,目的是起到门控作用。Sigmoid 函数的输出数值范围为0~1,符合物理意义上的开与关。Tanh 函数作为候选记忆C的选项,因为其输出数值范围为-1~1,符合以0为中心的分布特征,且梯度在接近0值时,收敛速度比 Sigmoid 函数快,这是选择 tanh 函数为候选记忆C选项的另一原因。不过 LSTM 模型的激励函数以及模型结构形式可以根据实际需求进行更改。
一般选择 Sigmoid 作为激励函数,目的是起到门控作用。Sigmoid 函数的输出数值范围为0~1,符合物理意义上的开与关。Tanh 函数作为候选记忆C的选项,因为其输出数值范围为-1~1,符合以0为中心的分布特征,且梯度在接近0值时,收敛速度比 Sigmoid 函数快,这是选择 tanh 函数为候选记忆C选项的另一原因。不过 LSTM 模型的激励函数以及模型结构形式可以根据实际需求进行更改。

输入门(Input gate)的计算:

遗忘门(Forget gate)的计算:

候选记忆单元的计算:
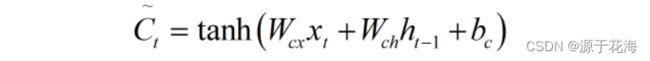
记忆单元状态更新的计算:

输出门的计算:
![]()
隐藏状态(output)的计算:

三、基于LSTM的命名实体识别
本项目是基于飞桨 AI Studio 平台,首先进行数据集查看的和路径持久化,以及 PaddlePaddle 系统环境的搭建,具体内容详见项目飞桨AI Studio星河社区-人工智能学习与实训社区 (baidu.com)。
# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory.
# This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
# 如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
# If a persistence installation is required,
# you need to use the persistence path as the following:
!mkdir /home/aistudio/external-libraries
!pip install beautifulsoup4 -t /home/aistudio/external-libraries
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
# Also add the following code,
# so that every time the environment (kernel) starts,
# just run the following code:
import sys
sys.path.append('/home/aistudio/external-libraries')1. 导入相关库
import paddle
import paddle.nn as nn
import paddlenlp
from paddlenlp.datasets import MapDataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.layers import LinearChainCrf, ViterbiDecoder, LinearChainCrfLoss
from paddlenlp.metrics import ChunkEvaluator2. 数据加载
接下来进行数据集(包括训练集和测试集)的加载:
from paddlenlp.datasets import load_dataset
# 由于MSRA_NER数据集没有dev dataset,我们这里重复加载test dataset作为dev_ds
train_ds, dev_ds, test_ds = load_dataset(
'msra_ner', splits=('train', 'test', 'test'), lazy=False)
label_vocab = {label:label_id for label_id, label in enumerate(train_ds.label_list)}
words = set()
word_vocab = []
for item in train_ds:
word_vocab += item['tokens']
word_vocab = {k:v+2 for v,k in enumerate(set(word_vocab))}
word_vocab['PAD'] = 0
word_vocab['OOV'] = 1
lens = len(train_ds)+len(dev_ds)
print(len(train_ds)/lens,len(dev_ds)/lens,len(test_ds)/lens)
def convert_tokens_to_ids(tokens, vocab, oov_token='OOV'):
token_ids = []
oov_id = vocab.get(oov_token) if oov_token else None
for token in tokens:
token_id = vocab.get(token, oov_id)
token_ids.append(token_id)
return token_ids
def convert_example(example):
tokens, labels = example['tokens'],example['labels']
token_ids = convert_tokens_to_ids(tokens, word_vocab, 'OOV')
label_ids = labels #convert_tokens_to_ids(labels, label_vocab, 'O')
return token_ids, len(token_ids), label_ids
train_ds.map(convert_example)
dev_ds.map(convert_example)
test_ds.map(convert_example)
# print(train_ds)
3. 构造dataloder
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=word_vocab.get('OOV')), # token_ids
Stack(), # seq_len
Pad(axis=0, pad_val=label_vocab.get('O')) # label_ids
): fn(samples)
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=32,
shuffle=True,
drop_last=True,
return_list=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=32,
drop_last=True,
return_list=True,
collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_size=32,
drop_last=True,
return_list=True,
collate_fn=batchify_fn)4. 网络构建
class BiLSTMWithCRF(nn.Layer):
def __init__(self,
emb_size,
hidden_size,
word_num,
label_num,
use_w2v_emb=False):
super(BiLSTMWithCRF, self).__init__()
self.word_emb = nn.Embedding(word_num, emb_size)
self.lstm = nn.LSTM(emb_size,
hidden_size,
num_layers=2,
direction='bidirectional')
self.fc = nn.Linear(hidden_size * 2, label_num + 2) # BOS EOS
self.crf = LinearChainCrf(label_num)
self.decoder = ViterbiDecoder(self.crf.transitions)
def forward(self, x, lens):
embs = self.word_emb(x)
output, _ = self.lstm(embs)
output = self.fc(output)
_, pred = self.decoder(output, lens)
return output, lens, pred
# Define the model netword and its loss
network = BiLSTMWithCRF(300, 300, len(word_vocab), len(label_vocab))
model = paddle.Model(network)5. 网络配置
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
crf_loss = LinearChainCrfLoss(network.crf)
chunk_evaluator = ChunkEvaluator(label_list=label_vocab.keys(), suffix=True)
model.prepare(optimizer, crf_loss, chunk_evaluator)6. 模型训练
model.fit(train_data=train_loader,
eval_data=dev_loader,
epochs=1,
save_dir='./results',
log_freq=100)
7. 模型评估
model.evaluate(eval_data=test_loader, log_freq=10)
8. 模型预测
def parse_decodes(ds, decodes, lens, label_vocab):
decodes = [x for batch in decodes for x in batch]
lens = [x for batch in lens for x in batch]
print(len(decodes),len(decodes))
id_label = dict(zip(label_vocab.values(), label_vocab.keys()))
# print(id_label)
outputs = []
i=0
for idx, end in enumerate(lens):
sent = ds.data[idx]['tokens'][:end]
tags = [id_label[x] for x in decodes[idx][:end]]
sent_out = []
tags_out = []
words = ""
for s, t in zip(sent, tags):
# {'B-PER': 0, 'I-PER': 1, 'B-ORG': 2, 'I-ORG': 3, 'B-LOC': 4, 'I-LOC': 5, 'O': 6}?
if t.startswith('B-') or t == 'O':
if len(words):
sent_out.append(words) # 上一个实体保存
tags_out.append(t.split('-')[-1]) # 保存该实体的类型
words = s
else: # 保存实体的
words += s
if len(sent_out) < len(tags_out):
sent_out.append(words)
if len(sent_out) != len(tags_out):
print(len(sent_out),len(tags_out))
continue
cs = [str((s, t)) for s, t in zip(sent_out, tags_out)]
ss = ''.join(cs)
i+=1
outputs.append(ss)
return outputs
outputs, lens, decodes = model.predict(test_data=test_loader)
print(len(decodes),len(decodes[0]))
print(len(lens),len(lens[0]))
preds = parse_decodes(test_ds, decodes, lens, label_vocab)
print(preds[0])
print('----------------')
print(preds[1])
print('----------------')
print(preds[2])