- 访问者模式【行为模式C++】
GoWjw
设计模式访问者模式
1.概述访问者模式是一种行为设计模式,它能将算法与其所作用的对象隔离开来。访问者模式主要解决的是数据与算法的耦合问题,尤其是在数据结构比较稳定,而算法多变的情况下。为了不污染数据本身,访问者会将多种算法独立归档,并在访问数据时根据数据类型自动切换到对应的算法,实现数据的自动响应机制,并确保算法的自由扩展。访问者模式在实际开发中使用的非常少,因为它比较难以实现并且应用该模式肯能会导致代码的可读性变差
- 【重温设计模式】访问者模式及其Java示例
万猫学社
重温设计模式及其Java实现设计模式访问者模式java
访问者模式的基本概念访问者模式,一种行为型设计模式,其基本定义是:允许一个或者多个操作应用到一组对象上,解耦操作和对象的具体类,使得操作的添加可以独立于对象的类结构变化。在面向对象编程中,访问者模式的重要性不言而喻。它将数据操作和数据结构分离,使得在不改变数据结构的前提下,可以添加新的操作,从而增强了系统的灵活性和可扩展性。在访问者模式中,数据结构是稳定的,而操作是易变的。这就像一座博物馆,展品(
- 访问者模式
烟沙九洲
设计模式访问者模式java
访问者(Visitor)模式属于行为型模式的一种。访问者模式主要用于分离算法和对象结构,从而在不修改原有对象的情况下扩展新的操作。它适用于数据结构相对稳定,而操作(行为)容易变化的场景。访问者模式允许在不修改现有类的情况下,为类层次结构中的对象定义新的操作。访问者模式通过将操作封装到一个独立的类(即访问者)中,使得对象结构与操作解耦。访问者模式使用了一种名为双分派(在运行时根据两个对象的类型动态选
- ngx_http_conf_port_t
若云止水
http网络协议网络
定义在src\http\ngx_http_core_module.htypedefstruct{ngx_int_tfamily;in_port_tport;ngx_array_taddrs;/*arrayofngx_http_conf_addr_t*/}ngx_http_conf_port_t;该结构体用于在Nginx配置阶段存储监听端口的配置信息,是listen指令解析后的核心数据结构。它将同一
- AtCoder备赛冲刺必刷题(C++) | 洛谷 AT_abc396_a Triple Four
热爱编程的通信人
c++算法开发语言
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。欢迎大家订阅我的专栏:算法题解:C++与Python实现!附上汇总贴:算法竞赛备考冲刺必刷题(C++)|汇总【题目来源】洛谷:AT_abc396_a[ABC396A]
- 算法及数据结构系列 - 滑动窗口
诺亚凹凸曼
算法及数据结构算法数据结构java
系列文章目录算法及数据结构系列-二分查找算法及数据结构系列-BFS算法算法及数据结构系列-动态规划算法及数据结构系列-双指针算法及数据结构系列-回溯算法算法及数据结构系列-树文章目录滑动窗口框架思路经典题型76.最小覆盖子串567.字符串的排列438.找到字符串中所有字母异位词3.无重复字符的最长子串滑动窗口框架思路/*滑动窗口算法框架*/voidslidingWindow(strings,str
- 数据结构二叉树进阶
z一一m
数据结构数据结构算法
1.根据二叉树创建字符串1.题目2.分析原理要把二叉树元素按照前序顺序取出来,并且以字符串的形式返回,还要添加括号对于左子树和右子树,那么第一步就是向定义一个string类型来接收取出的元素,需要用到to_string函数把整型变成string类型,第二步就是递归来深度遍历了,但是需要判断一下,题目有些情况是省略了括号,有些没有省去,题目例子可以知道左为空右不为空就不能省略括号,左不为空右为空就可
- C/C++数据类型--整型类型
蓝心湄
C/C++数据类型c语言
概念数据类型表示的是数据的身份决定它可以进行什么操作、占用多少空间与数据结构的区别数据类型更倾向于表示数据的身份数据结构表示的是怎么操作数据(是在类型的基础上进行对数据的操作的)C语言允许使用的类型类型的分类算术类型:基本类型和枚举类型纯量类型:算术类型和指针类型组合类型:数组类型和结构体类型整型数据基本整型(int)长度为2字节或4字节短整型(shortint)长度为2字节长整型(longint
- 7种数据结构
就很对
数据结构windows
7种数据结构顺序表sqlite.hseqlite.c单链表linklist.clinklist.h双链表doulinklist.cdoulinklist.h链式栈linkstack.clinkstack.h队列SeqQueue.cSeqQueue.h树tree.c哈希表hash.c顺序表sqlite.h#ifndef__SEQLIST_H__#define__SEQLIST_H__typedefs
- python爬虫Redis数据库
Æther_9
Python爬虫零基础入门数据库python爬虫
Redis数据库Redis简介Redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。Redis与其他key-value缓存产品有以下三个特点:Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。redis:半持
- C语言动态顺序表的实现
しかし118114
数据结构数据库c语言经验分享数据结构链表
目录(一)静态顺序表(二)动态顺序表顺序表是数据结构的入门,本篇文章将详细介绍动态顺序表的增删改补。我们先了解一下静态顺序表。(一)静态顺序表静态顺序表是顺序表的一种,由于静态顺序表的大小固定,很容易溢出或浪费空间,所以我们一般不用静态顺序表。所有顺序表的实现都是基于数组实现的,其实顺序表是顺序表的pro版,可以装更多的数据。#defineTypedataint//这里定义的顺序表是int类型的/
- 什么是C++对象之间的view proxies
东北豆子哥
C++c++
在C++中,viewproxies是一种轻量级的对象,用于提供对另一个对象的间接访问或视图,而不直接拥有或管理该对象的数据。它们通常用于简化对复杂数据结构的访问,或在不需要复制数据的情况下提供特定的视图。1.ViewProxies的核心概念轻量级:Viewproxies通常不拥有数据,而是引用或包装另一个对象的数据。间接访问:通过viewproxies,可以以特定的方式访问或操作底层数据,而不需要
- 《Hello 算法》火了!!!一本写给算法初学者的入门算法书籍
遇码
分享算法hellohello算法算法书籍
曾经也放出豪言壮语,决心要刷遍力扣上的所有算法题目。然而现实就很快啪啪的打脸。不知道多少人和我有过一样的经历。在读到《Hello算法》的序中,作者靳宇栋给了我们一个“台阶”。随后就表达了针对我们的现状,他特地写了《Hello算法》这本书,代表广大算法初学者表示感激涕零。《Hello算法》为什么适合入门动画图解、一键运行的数据结构与算法教程全书采用动画图解,内容清晰易懂、学习曲线平滑,引导初学者探索
- java队列实现限流_如何使用队列实现微服务限流算法?
纽太普
java队列实现限流
队列在平时开发中可能是出现频率最高的数据结构之一了,但是大部分情况下,我们都是用别人已经实现好的,比如kafka,比如redis里的list,以至于让人怀疑为什么还要去学习队列呢?希望今天的内容可以给你一些启发。什么是队列为了整个文章的完整性,我们还是来介绍一下什么是队列。我们举个生活中常见的案例,假设你在周杰伦的奶茶店买奶茶,由于人很多,为了保持公平和秩序,你被要求排队,最先来的人排到最前面,这
- 麒麟服务器操作系统Redis部署手册
太极淘
麒麟操作系统管理工具服务器redis运维
软件简介Redis****介绍REmoteDIctionaryServer(Redis)是一个由SalvatoreSanfilippo写的key-value存储系统,是跨平台的非关系型数据库。Redis是一个开源的使用ANSIC语言编写、遵守BSD协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的API。Redis通常被称为数据结构服务器,因为
- 零基础上手Python数据分析 (7):Python 面向对象编程初步
kakaZhui
python数据分析excel
写在前面回顾一下,我们已经学习了Python的基本语法、数据类型、常用数据结构和文件操作、异常处理等。到目前为止,我们主要采用的是面向过程(ProceduralProgramming)的编程方式,即按照步骤一步一步地编写代码,解决问题。这种方式对于简单的任务已经足够,但当程序变得越来越复杂,代码量越来越大时,面向过程编程可能会显得力不从心,代码难以组织、复用和维护。代码复杂性带来的挑战:面向过程v
- JavaScript数组-遍历数组
咖啡の猫
javascript开发语言
在JavaScript开发过程中,数组是一种非常常见且强大的数据结构,用于存储一系列有序的数据项。遍历数组是处理这些数据项的基础操作之一,无论是为了显示、转换还是过滤数据。本文将详细介绍几种常见的遍历数组的方法及其应用场景,帮助你选择最适合当前任务的方式。一、为什么需要遍历数组?遍历数组意味着逐一访问数组中的每个元素,以便执行特定的操作,如打印输出、修改值或基于条件筛选数据。不同的场景可能需要不同
- Python列表的创建
只是没遇到
python
Python3列表序列是Python中最基本的数据结构。序列中的每个值都有对应的位置值,称之为索引,第一个索引是0,第二个索引是1,依此类推。Python有6个序列的内置类型,但最常见的是列表和元组。列表都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现
- 零基础上手Python数据分析 (6):Python 异常处理,告别程序崩溃的烦恼!
kakaZhui
python数据分析数据库excel数据挖掘
回顾一下,前几篇博客我们学习了Python的基本语法、数据结构和文件操作。现在,我们已经掌握了Python编程的基础知识,可以开始编写更复杂的数据分析代码了。但是,在实际的数据分析工作中,程序并非总能一帆风顺地运行,总会遇到各种意外情况,例如:文件找不到:程序尝试读取一个不存在的数据文件。数据格式错误:数据文件中包含非预期的格式,例如本应是数字的列包含了文本。网络连接中断:程序尝试从网络获取数据,
- 使用Annoy进行高效的近似最近邻搜索
eahba
前端javascriptangular.jspython
在处理大型数据集时,我们经常面临需要快速、准确地查找与给定查询点相近的数据点的问题。Annoy(ApproximateNearestNeighborsOhYeah)就是为解决此类问题而生的一个强大工具。Annoy是一个用C++编写并具有Python绑定的库,专用于在空间中搜索与给定查询点相近的点。它能够创建大型的只读文件数据结构,并映射到内存中,以便于多个进程共享相同的数据。技术背景介绍Annoy
- 平衡二叉树(AVL树):数据结构特性与自平衡技术详解
One Key Variable
课程设计
摘要平衡二叉树,尤其是AVL树,在追求高效数据存储与检索的场景中占据重要地位。本文深入剖析AVL树的数据结构特性,详细解读其自平衡技术原理与实现,帮助读者理解AVL树如何在动态数据操作中维持高效性能。一、引言在数据处理过程中,二叉搜索树虽能实现快速查找,但在频繁插入和删除节点时,可能因结构失衡导致查找效率大幅下降。AVL树作为一种自平衡二叉搜索树,通过严格的平衡条件和自平衡技术,确保树在动态操作下
- C++中map和set的详解
程序员Hagei
c++算法开发语言
C++中map和set的介绍与使用在C++编程中,map和set是标准模板库(STL)中两种非常重要的关联容器。它们基于平衡二叉搜索树(通常是红黑树)的数据结构来实现,提供了高效的数据存储和检索功能。本文将详细介绍map和set的特点、用法以及一些常见的操作示例。一、map的介绍与使用1.map的基本概念map是一个键值对容器,其中每个键都是唯一的,且按照升序排序。map的内部结构是红黑树,这使得
- 堆数据结构:从基础原理到高效算法实现的技术探讨
Everyrt
课程设计
摘要堆作为一种特殊的树形数据结构,在多种算法场景中发挥着核心作用。本文深入剖析堆的基础原理,详细阐述堆的构建、插入、删除等操作的实现细节,并探讨其在优先队列、堆排序等高效算法中的应用,助力读者全面掌握堆数据结构及其应用技术。一、引言堆数据结构以其独特的特性,能够高效地获取集合中的最大(或最小)元素。无论是操作系统中的进程调度,还是搜索算法中的最优解筛选,堆都扮演着不可或缺的角色。理解堆的原理与实现
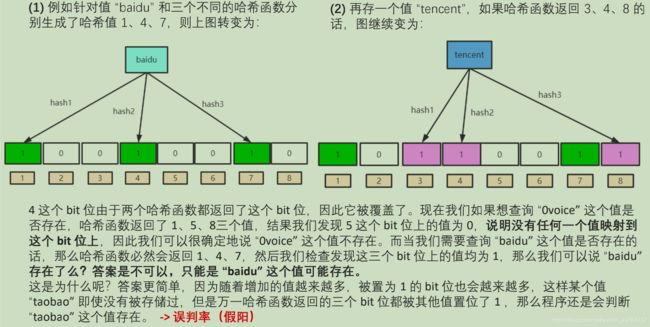
- 位图思想详解:用一个小小的比特征服整个世界
Joseit
优选算法java算法
位图思想详解:用一个小小的比特征服整个世界一、什么是位图?二、位图的形象理解三、位图的Java实现四、位图的算法原理剖析五、实际应用案例:网站用户活跃度统计五、真实的应用场景:布隆过滤器的基础六、算法题:判断字符是否唯一(easy)一、什么是位图?位图是一种超级节省空间的数据结构,他利用二进制位(0/1)来表示某个元素是否存在或某种状态是否为真。想象一下,用一个小小的比特位就能记录一个信息,这简直
- 算法及数据结构系列 - 动态规划
诺亚凹凸曼
算法及数据结构算法数据结构动态规划
系列文章目录算法及数据结构系列-二分查找算法及数据结构系列-BFS算法文章目录框架思路子序列问题解题模板一维dp数组二维dp数组经典题型322.零钱兑换暴力递归带备忘录的暴力递归动态规划300.最长上升子序列1143.最长公共子序列72.编辑距离框架思路动态规划问题的一般形式就是求最值。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如说求最长递增子序列,最小编辑距离等等。
- 深度剖析哈希表数据结构:原理、冲突解决与优化策略
麻辣酸甜
笔记
摘要哈希表作为一种高效的数据结构,在计算机科学领域广泛应用。本文深入探讨哈希表的工作原理,详细分析常见的冲突解决方法,如开放地址法、链地址法等,并进一步研究哈希表在不同场景下的优化策略,旨在帮助读者全面理解哈希表数据结构及其应用。一、引言在计算机程序中,快速查找和插入数据是常见需求。哈希表以其平均时间复杂度为O(1)的高效查找和插入特性,成为解决这类问题的有力工具。从数据库索引到编程语言的集合类实
- CSP-J备考冲刺必刷题(C++) | AcWing 1253 家谱
热爱编程的通信人
c++开发语言
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。欢迎大家订阅我的专栏:算法题解:C++与Python实现!附上汇总贴:算法竞赛备考冲刺必刷题(C++)|汇总【题目来源】Acwing:1253.家谱-AcWing题库
- 栈和队列基础
Luther coder
算法
目录一.队列简述二.栈三.例题一.队列简述队列多用于辅助,很少有单独的题目。例如图的BFS,需要队列辅助实现。常见运用:单调队列:概念和单调栈类似。应用很少,多用于对一些算法的优化(动态规划等),不再赘述。优先队列:普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出的特征。基于堆(
- 创建Datas
一一代码
python
核心数据结构创建DataFrame```pythonimportpandasaspd#从字典创建DataFramedata={'Name':['Alice','Bob','Charlie'],'Age':[25,30,35],'City':['NewYork','LosAngeles','Chicago']}df=pd.DataFrame(data)print(df)```输出:```NameAg
- 算法之魂:深入剖析数据结构中的七大排序算法
GeminiGlory
数据结构数据结构排序算法算法
目录1.冒泡排序(BubbleSort)2.选择排序(SelectionSort)3.插入排序(InsertionSort)4.希尔排序(ShellSort)5.快速排序(QuickSort)6.归并排序(MergeSort)7.堆排序(HeapSort)在计算机科学领域,排序是一项基础但至关重要的操作。无论你是处理数据库查询结果还是优化搜索效率,了解不同的排序算法及其适用场景都至关重要。本文将介
- java数字签名三种方式
知了ing
javajdk
以下3钟数字签名都是基于jdk7的
1,RSA
String password="test";
// 1.初始化密钥
KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance("RSA");
keyPairGenerator.initialize(51
- Hibernate学习笔记
caoyong
Hibernate
1>、Hibernate是数据访问层框架,是一个ORM(Object Relation Mapping)框架,作者为:Gavin King
2>、搭建Hibernate的开发环境
a>、添加jar包:
aa>、hibernatte开发包中/lib/required/所
- 设计模式之装饰器模式Decorator(结构型)
漂泊一剑客
Decorator
1. 概述
若你从事过面向对象开发,实现给一个类或对象增加行为,使用继承机制,这是所有面向对象语言的一个基本特性。如果已经存在的一个类缺少某些方法,或者须要给方法添加更多的功能(魅力),你也许会仅仅继承这个类来产生一个新类—这建立在额外的代码上。
- 读取磁盘文件txt,并输入String
一炮送你回车库
String
public static void main(String[] args) throws IOException {
String fileContent = readFileContent("d:/aaa.txt");
System.out.println(fileContent);
- js三级联动下拉框
3213213333332132
三级联动
//三级联动
省/直辖市<select id="province"></select>
市/省直辖<select id="city"></select>
县/区 <select id="area"></select>
- erlang之parse_transform编译选项的应用
616050468
parse_transform游戏服务器属性同步abstract_code
最近使用erlang重构了游戏服务器的所有代码,之前看过C++/lua写的服务器引擎代码,引擎实现了玩家属性自动同步给前端和增量更新玩家数据到数据库的功能,这也是现在很多游戏服务器的优化方向,在引擎层面去解决数据同步和数据持久化,数据发生变化了业务层不需要关心怎么去同步给前端。由于游戏过程中玩家每个业务中玩家数据更改的量其实是很少
- JAVA JSON的解析
darkranger
java
// {
// “Total”:“条数”,
// Code: 1,
//
// “PaymentItems”:[
// {
// “PaymentItemID”:”支款单ID”,
// “PaymentCode”:”支款单编号”,
// “PaymentTime”:”支款日期”,
// ”ContractNo”:”合同号”,
//
- POJ-1273-Drainage Ditches
aijuans
ACM_POJ
POJ-1273-Drainage Ditches
http://poj.org/problem?id=1273
基本的最大流,按LRJ的白书写的
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
#define INF 0x7fffffff
int ma
- 工作流Activiti5表的命名及含义
atongyeye
工作流Activiti
activiti5 - http://activiti.org/designer/update在线插件安装
activiti5一共23张表
Activiti的表都以ACT_开头。 第二部分是表示表的用途的两个字母标识。 用途也和服务的API对应。
ACT_RE_*: 'RE'表示repository。 这个前缀的表包含了流程定义和流程静态资源 (图片,规则,等等)。
A
- android的广播机制和广播的简单使用
百合不是茶
android广播机制广播的注册
Android广播机制简介 在Android中,有一些操作完成以后,会发送广播,比如说发出一条短信,或打出一个电话,如果某个程序接收了这个广播,就会做相应的处理。这个广播跟我们传统意义中的电台广播有些相似之处。之所以叫做广播,就是因为它只负责“说”而不管你“听不听”,也就是不管你接收方如何处理。另外,广播可以被不只一个应用程序所接收,当然也可能不被任何应
- Spring事务传播行为详解
bijian1013
javaspring事务传播行为
在service类前加上@Transactional,声明这个service所有方法需要事务管理。每一个业务方法开始时都会打开一个事务。
Spring默认情况下会对运行期例外(RunTimeException)进行事务回滚。这
- eidtplus operate
征客丶
eidtplus
开启列模式: Alt+C 鼠标选择 OR Alt+鼠标左键拖动
列模式替换或复制内容(多行):
右键-->格式-->填充所选内容-->选择相应操作
OR
Ctrl+Shift+V(复制多行数据,必须行数一致)
-------------------------------------------------------
- 【Kafka一】Kafka入门
bit1129
kafka
这篇文章来自Spark集成Kafka(http://bit1129.iteye.com/blog/2174765),这里把它单独取出来,作为Kafka的入门吧
下载Kafka
http://mirror.bit.edu.cn/apache/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz
2.10表示Scala的版本,而0.8.1.1表示Kafka
- Spring 事务实现机制
BlueSkator
spring代理事务
Spring是以代理的方式实现对事务的管理。我们在Action中所使用的Service对象,其实是代理对象的实例,并不是我们所写的Service对象实例。既然是两个不同的对象,那为什么我们在Action中可以象使用Service对象一样的使用代理对象呢?为了说明问题,假设有个Service类叫AService,它的Spring事务代理类为AProxyService,AService实现了一个接口
- bootstrap源码学习与示例:bootstrap-dropdown(转帖)
BreakingBad
bootstrapdropdown
bootstrap-dropdown组件是个烂东西,我读后的整体感觉。
一个下拉开菜单的设计:
<ul class="nav pull-right">
<li id="fat-menu" class="dropdown">
- 读《研磨设计模式》-代码笔记-中介者模式-Mediator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/*
* 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
* 中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
*
* 在我看来,Mediator模式是把多个对象(
- 常用代码记录
chenjunt3
UIExcelJ#
1、单据设置某行或某字段不能修改
//i是行号,"cash"是字段名称
getBillCardPanelWrapper().getBillCardPanel().getBillModel().setCellEditable(i, "cash", false);
//取得单据表体所有项用以上语句做循环就能设置整行了
getBillC
- 搜索引擎与工作流引擎
comsci
算法工作搜索引擎网络应用
最近在公司做和搜索有关的工作,(只是简单的应用开源工具集成到自己的产品中)工作流系统的进一步设计暂时放在一边了,偶然看到谷歌的研究员吴军写的数学之美系列中的搜索引擎与图论这篇文章中的介绍,我发现这样一个关系(仅仅是猜想)
-----搜索引擎和流程引擎的基础--都是图论,至少像在我在JWFD中引擎算法中用到的是自定义的广度优先
- oracle Health Monitor
daizj
oracleHealth Monitor
About Health Monitor
Beginning with Release 11g, Oracle Database includes a framework called Health Monitor for running diagnostic checks on the database.
About Health Monitor Checks
Health M
- JSON字符串转换为对象
dieslrae
javajson
作为前言,首先是要吐槽一下公司的脑残编译部署方式,web和core分开部署本来没什么问题,但是这丫居然不把json的包作为基础包而作为web的包,导致了core端不能使用,而且我们的core是可以当web来用的(不要在意这些细节),所以在core中处理json串就是个问题.没办法,跟编译那帮人也扯不清楚,只有自己写json的解析了.
- C语言学习八结构体,综合应用,学生管理系统
dcj3sjt126com
C语言
实现功能的代码:
# include <stdio.h>
# include <malloc.h>
struct Student
{
int age;
float score;
char name[100];
};
int main(void)
{
int len;
struct Student * pArr;
int i,
- vagrant学习笔记
dcj3sjt126com
vagrant
想了解多主机是如何定义和使用的, 所以又学习了一遍vagrant
1. vagrant virtualbox 下载安装
https://www.vagrantup.com/downloads.html
https://www.virtualbox.org/wiki/Downloads
查看安装在命令行输入vagrant
2.
- 14.性能优化-优化-软件配置优化
frank1234
软件配置性能优化
1.Tomcat线程池
修改tomcat的server.xml文件:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" maxThreads="1200" m
- 一个不错的shell 脚本教程 入门级
HarborChung
linuxshell
一个不错的shell 脚本教程 入门级
建立一个脚本 Linux中有好多中不同的shell,但是通常我们使用bash (bourne again shell) 进行shell编程,因为bash是免费的并且很容易使用。所以在本文中笔者所提供的脚本都是使用bash(但是在大多数情况下,这些脚本同样可以在 bash的大姐,bourne shell中运行)。 如同其他语言一样
- Spring4新特性——核心容器的其他改进
jinnianshilongnian
spring动态代理spring4依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- Linux设置tomcat开机启动
liuxingguome
tomcatlinux开机自启动
执行命令sudo gedit /etc/init.d/tomcat6
然后把以下英文部分复制过去。(注意第一句#!/bin/sh如果不写,就不是一个shell文件。然后将对应的jdk和tomcat换成你自己的目录就行了。
#!/bin/bash
#
# /etc/rc.d/init.d/tomcat
# init script for tomcat precesses
- 第13章 Ajax进阶(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Troubleshooting Crystal Reports off BW
blueoxygen
BO
http://wiki.sdn.sap.com/wiki/display/BOBJ/Troubleshooting+Crystal+Reports+off+BW#TroubleshootingCrystalReportsoffBW-TracingBOE
Quite useful, especially this part:
SAP BW connectivity
For t
- Java开发熟手该当心的11个错误
tomcat_oracle
javajvm多线程单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 正则表达式大全
yang852220741
html编程正则表达式
今天向大家分享正则表达式大全,它可以大提高你的工作效率
正则表达式也可以被当作是一门语言,当你学习一门新的编程语言的时候,他们是一个小的子语言。初看时觉得它没有任何的意义,但是很多时候,你不得不阅读一些教程,或文章来理解这些简单的描述模式。
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$