韩顺平JAVA2022-正则表达式笔记
正则表达式
帮助提取文本的利器
体验(试用)
-
提取一段文字中的字母
// Pattern pattern = Pattern.compile("[a-zA-z]+"); Matcher matcher = pattern.matcher(content1); while (matcher.find()){ System.out.println("找到: "+matcher.group(0)); } -
提取一段文字中的数字
-
// Pattern pattern = Pattern.compile("[0-9]+"); Matcher matcher = pattern.matcher(content1); while (matcher.find()){ System.out.println("找到: "+matcher.group(0)); } -
提取字母和数字
// Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-z]+)"); Matcher matcher = pattern.matcher(content1); while (matcher.find()){ System.out.println("找到: "+matcher.group(0)); } -
提取网页中的标题
-
提取IP地址
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+"); Matcher matcher = pattern.matcher(content1); while (matcher.find()){ System.out.println("找到: "+matcher.group(0)); }
帮助解决字符匹配问题
对字符串执行模式匹配技术
字符匹配符(正则)

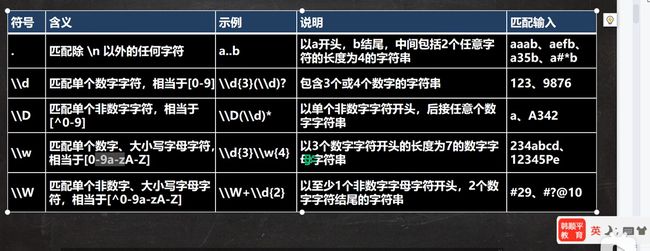


不区分大小写
(?i)
(?i)后面紧跟的字符不区分大小写
Pattern.CASE_INSENSITIVE compile(regex,Pattern.CASE_INSENSITIVE)//不区分大小写
\\代表转义符
在匹配一些特殊字符时使用
例如:
匹配点 \\.
\\d表示一个任意数字
例子:
匹配模式
\\d\\d\\d\\d表示任意四位数字
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");
//一个正则表达式对象
//\\d+\\.\\d+\\.\\d+\\.\\d+,表示匹配模式
//当匹配模式中含有括号时()
*代表将其分组
//创建一个适配对象
//匹配器
Matcher matcher = pattern.matcher(content1);
matcher.find();
//根据人规定的匹配模式,纪录字符串的位置,放在int的matcher.group()数组中
/**
放入规则:
从匹配的第一个数的位置,放入group[0]
匹配最后一个数的位置+1,放入group[1]
如果匹配模式中含有()即将其分组后
每一个()代表一个分组,
放入规则:
先分组整体-从匹配的第一个数的位置放入group[0]
匹配最后一个数的位置+1放入group[1]
第一个小括号分组-从匹配的第一个数的位置放入group[2]
匹配最后一个数的位置+1放入group[3]
后面依次增加
但用匹配器取出时是按源码:
/**
* public String group(int group) {
* if (first < 0)
* throw new IllegalStateException("No match found");
* if (group < 0 || group > groupCount())
* throw new IndexOutOfBoundsException("No group " + group);
* if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
* return null;
* return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
* }
*/
**/
取出对应的group()
如果未组将其取出,会出现超过分组的错误.
注意:正则表达式模式匹配中,匹配的是一段字符串中出现自己规定模式出现的位置[起始位置,末位置]等价于[起始位置,末位置+1),匹配完成后存入的int数组,存入的也是位置,分组后存入的也是位置,只是存入不同的数组.
例如:
存入group[0]起始位置,group[1]末位置+1
()分组存入的也是group[0]起始位置,group[1]末位置+1
取出时matcher.group()根据源码算法取出对应位置段的字符串
限定符(正则)
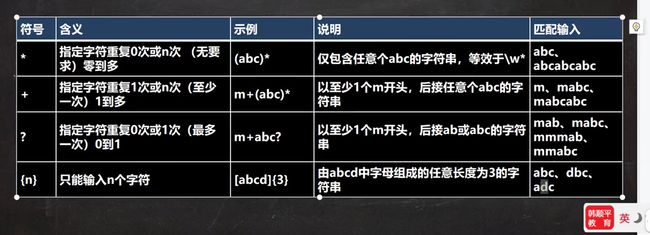

字符后面紧跟限定定符,对该字符起效果;
控制重复个数符号 .va
*(0到多)
+(1到多)
?(0到1)
当匹配模式中含有这些符号时,表示字符能重复的次数.
例子:
a1+ 因为 + 在1后面,所以表示当匹配字符a1时,1的个数为1个或者多个,至少匹配a1
a1* 因为 * 在1后面,所以表示当匹配字符a1时,1的个数为0个或者多个,可以匹配a
a1? 因为 ? 在1后面,所以表示当匹配字符a1时,1的个数为0个或者1个,可以匹配a,a1
注意:也遵循贪婪匹配
控制字符个数符号
{n}只有n个字符
{n,}至少n个字符
{n,m}至少n个字符,至多m个字符
*java服从贪婪匹配,尽可能匹配多的字符
定位符(正则)
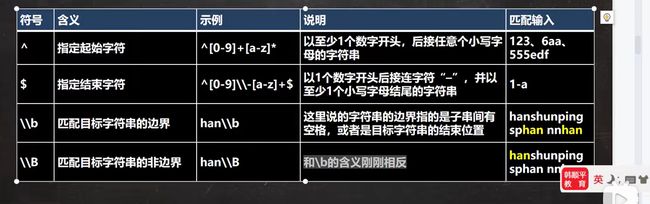
^ 开始
$ 结束
\\b 有空格 ,\\B 无空格,\\b可以作为边界,可以避免匹配字符子集的产生.
捕获分组

捕获分组就是将匹配模式进一步划分.
示例:
String regex = "(?\\d\\d)(?\\d\\d)" ;
Pattern pattern = Pattern.compile(regex);
//创建一个适配对象
Matcher matcher = pattern.matcher(regexp.content);
while (matcher.find()){
System.out.println("找到: "+matcher.group(0));
// System.out.println("找到第一组:"+matcher.group(1));//第一个括号的值,即是group[2]-group[3]中存储的数
// System.out.println("找到第二组:"+matcher.group(2));//找到group[4]-group[5]中存储的数
System.out.println("找到是s1\t"+matcher.group("s1"));
System.out.println("找到是s2\t"+matcher.group("s2"));
}
非捕获分组
不会进一步划分group()
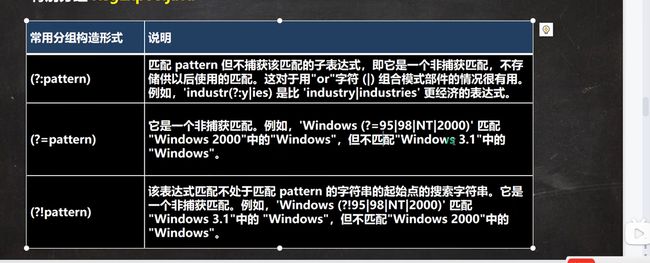
示例:
String content = "tom猫,tom狗,tom鼠";
String regex = "(tom(?:猫|狗|鼠))+";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到不区分大小写匹配"+matcher.group(0));
System.out.println("找到不区分大小写匹配"+matcher.group(1));//这里有group(1),因为外面有大括号,和里面大括号形成一个内外分组.但结果相同
示例2:
String regex = "tom(?!猫|狗|鼠)";//只匹配不满足tom猫,tom狗,tom鼠的tom
//注意返回的是tom
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到不区分大小写匹配"+matcher.group(0));
非贪婪匹配
当限定符 * 或+ 与?一起使用时遵从非贪婪匹配
正则表达式元字符-详细说明.docx
案例
/**
* 1,汉字
* 2,邮政编码:1-9开头的一个六位数
* 3,qq号码
* 要求:是1-9开头的一个[5位数-10位数]
* 4,手机号码
* 要求:必须以13,14,15,18开头的11位数,
* 5,URL
*
*/
// String content = "你好梨";
// String regex= "^[\u0391-\uffe5]+$";
// String content ="117000";
// String regex = "^[1-9]\\d{5}$";
// String content = "1540785688";
// String regex = "^[1-9]\\d{4,9}$";
// String regex = "^1(?:3|4|5|8)+";
String regex = "^1[3|4|5|8]\\d{9}$";
String regex = "^((http|https)://)([\\w-]+\\.)+([\\w-])+(\\/[\\w-%?=&.]+)*";//匹配URL
常用类(正则)
Pattern类
Matches(regrx,content),尝试整体去匹配,底层还是创建正则对象,匹配器去匹配。
相当于是封装的一个方法,可以传入匹配字符串,和匹配模式,去减少代码量。
String content = "https://www.msn.cn";
String regex = "^((http|https)://)?([\\w-]+\\.)+([\\w-])+(\\/[\\w-%?=&.]+)*$";
boolean matches = Pattern.matches(regex,content);
System.out.println(matches);
matcher类
start(),end(),返回匹配字符串,在原字符串中出现的位置(源码那一样,开始位置,末位置加1)
String content = "tom猫, tom狗, tom鼠";
String regex= "tom";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.start()+" "+matcher.end());
}
replaceAll(替换后的)
//整体替换replaceAll(),将自动所有匹配到的,替换为另一个
String content = "tom猫, tom狗, tom鼠";
String regex= "tom";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
String tom = matcher.replaceAll("汤姆");
System.out.println(tom);
反向引用
1,分组
用()组成一个比较复杂的匹配模式,每一个括号可以看成一个子表达式.
2,捕获
将()里的内容保存到一个以数字编号或命名的组里,方便后面引用,从左向右,依次增加.第一个()为1,第二个()为2
3,反向引用
()捕获后,在()后使用括号捕获的内容,
内部反向引用方法: \\子表达式的数字编号
外部反向引用方法: $子表达式的数字编号
案例:这个案例中匹配模式会出现结果有子集,
如果不想有子集合需要添加边界符\\b.
String content = "11,22,33,123123,11111,22222,1221,2222,12321-333999111";
String regex = "(\\d)\\1";
// String regex = "\\d";
// String regex = "(\\d)\\1{4}";
// String regex = "^(\\d)(\\d)\\2\\1$";
// String regex = "(\\d)(\\d)\\d\\2\\1-(\\d)\\3{2}(\\d)\\4{2}(\\d)\\5";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.group(0));
}
实例2:无子集
String content = "11,22,33,123123,11111,22222,1221,2222,12321-333999111";
// String regex = "\\b(\\d)\\1\\b";
// String regex = "\\b(\\d)\\1{4}\\b";
// String regex = "\\b(\\d)(\\d)\\2\\1\\b";
String regex = "\\b(\\d)(\\d)\\d\\2\\1-(\\d)\\3{2}(\\d)\\4{2}(\\d)\\5{2}\\b";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.group(0));
}
案例3外部引用
//将"我....我要....学学学学....编程java!"通过正则修改为
//"我要学编程Java"
public static void main(String[] args) {
//去重,替换
//1,先去掉.
String content = "我....我要....学学学学....编程java!";
String regex = "\\.";
String regex1 = "";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
content = matcher.replaceAll(regex1);
System.out.println(content);
//2,去掉重复的字,将其分组,供给外部replaceAll来使用
String regex2 = "(.)\\1+";
pattern = Pattern.compile(regex2);
//因为字符串已经修改需要重新匹配
matcher = pattern.matcher(content);
String s = matcher.replaceAll("$1");
System.out.println(s);
String方法中的正则
//替换
/**public String replaceAll(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}**/
String s = content.replaceAll(regex, replace);
System.out.println(s);
//
//验证
//验证手机号为13,14,15开头11位手机号
String content1 = "13881775886";
boolean matches = content.matches(".*1[3|4|5]\\d{9}.*");
Pattern pattern = Pattern.compile("1[3|4|5]\\d{9}");
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.group(0));
}
//分割功能
/**
* public String[] split(String regex) {
* return split(regex, 0);
* }
*/
//按逗号,:分割
String[] strings = content.split(",|:");
for (String s1: strings){
System.out.println(s1);
}
老韩给定练习
练习1
* 1,只能有一个@
* 2,@前面是用户名,可以是a-zA-z0-9_-字符
* 3,@后面是域名,并且只能是英文字母 如sohu.com
* 4,写出对应的正则表达式,验证输入的字符串是否满足规则
*
// String matches方法是整体匹配matches
String content = "[email protected]";
String regex = "^[\\w-]+@([a-z|A-z]+\\.)+[a-z|A-z]+$";
boolean matches = content.matches(regex);
System.out.println(matches);
练习2
//验证是不是整数或者小数
//考虑正数负数
String content = "-0.89";
// String regex = "\\d+|-\\d+|\\d+\\.\\d+|-\\d+\\.\\d+";
String regex = "^[-+]?([1-9]\\d*|0)(\\.\\d+)?$";
//老韩将验证分为三部分
//1,+-号 ^[-+]?
//2,整数小数 ([1-9]\\d*|0)
//3,小数点及后面数字 (\\.\\d+)?
boolean matches = content.matches(regex);
System.out.println(matches);
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println(matcher.group(0));
}
练习3
正则表达式是根据需求来配置的,具体需求更改具体匹配模式,在分组时注意前面和后面来指定位置,得到具体想要的分组
//要求
//1,要求得到的协议是什么 http
//2,域名是什么 www.sohu.com
//3,端口是什么 8080
//4, 文件名是什么 index.htm
// String content = "https://www.sohu.com:8080/abc/index.htm";
// String regex = ""
String content = "https://mini.eastday.com/nsa/230524161756251559988.html?qid=02034";
/**
* 拆分:
* 1,https,([a-zA-z]+)
* 2,://
* 3,mini.eastday.com 由字母数字或点组成的1个,或多个字符串([\w.]+)
* 4,/nsa由/字母数字或其他组成的任意一字符或多字符 字符串[\w-/]*
* 5./
* 5,230524161756251559988.html 由数字字母点组成([\w.]+)
* 6,?qid=02034 [\w.?=]*
*/
// String regex = "(http|https)|(www\\.\\w+\\.\\w+)|(\\d+)|(\\w+\\.\\w+)";
// String regex = "^([a-zA-z]+)://([a-zA-z.]+):(\\d+)[\\w-/]*/([\\w.@#$%]+)$";
String regex = "^([a-zA-z]+)://([\\w.]+)[\\w-/]*/([0-9a-zA-z.]+)[\\w.?=]*$";
Pattern compile = Pattern.compile(regex);
Matcher matcher = compile.matcher(content);
if (matcher.matches()){
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
System.out.println(matcher.group(3));
}