10分钟就可以秒懂计算机体系结构与CPU工作原理
文章目录
- 前言
- 一、芯片的‘破壳’
-
- 1.1、从沙子到单晶硅
- 1.2、芯片电路
- 1.3、芯片的封装
- 二、CPU原理
-
- 2.1、CPU的工作原理
- 2.2、CPU的设计
- 三、计算机体系结构
-
- 3.1、冯·诺依曼架构
- 3.2、哈弗架构
- 3.3、混合架构
- 四、Cache 机制
-
- 4.1、Cache 机制工作原理
- 五、总线和地址
-
- 5.1、地址
- 5.2、总线的概念
- 六、指令集与微架构
-
- 6.1、什么是指令集
- 6.2什么是微架构
前言
我初识STM32时,通常好奇这个芯片是怎么造出来的呢?它的工作原理是是什么?CPU是怎么设计的,在计算机是如何进行工作的,它的底层原理是什么?
一、芯片的‘破壳’
芯片是半导体。而半导体是介于导体和绝缘体之间的一类物质,硅、锗、硒、硼的单质都属于半导体。
而目前在集成电路中大规模应用的只有硅,硅充当着继承电路的原材料。并且硅在地球上大量存在,是含量第二丰富的元素,如沙子,它本质就是二氧化硅。可以说制造芯片的原材料是极其丰富、取之不尽的。沙子不仅仅可以和水泥混合成为混凝土,建成高楼大厦;也可以在熊熊烈火中、浴火重生,变成集成电路高科技产品。
1.1、从沙子到单晶硅
经过碳元素的还原作用,将二氧化硅还原成粗硅,再通过盐酸氯化、蒸馏等步骤。提取的硅单质纯度越来越高,同时为了增强硅的导电性能,一般会在多晶硅中掺杂一些硼元素或磷元素,待多晶硅融化后,在溶液中加入硅晶体晶种,同时通过拉杆不停旋转上拉,就可以拉出圆柱形的单晶硅棒。根据不同的需求和工艺,单晶硅棒可以做成不同的尺寸,如 6 寸、8 寸、12 寸等。
接下来,将这些单晶硅切成一片一片的,每一片称为晶圆。晶圆是设计集成电路的载体,我们设计的模拟电路或数字电路,最终都要在晶圆上实现。晶圆上的芯片电路尺寸随着半导体工艺的发展也变得越来越小,目前已经达到了纳米级,越来越精密的半导体工艺除了要求单晶硅的纯度极高,晶圆的表面也必须光滑平整,切好的晶圆还需要进一步打磨抛光。
晶圆上的每一个小格子都是一个芯片电路的物理实现,我们称之为晶粒。接下来还要对晶圆上的这些芯片电路进行切割、封装、引出管脚,然后就变成了市场上常见的芯片产品,最后才能焊接到我们的开发板上,做成整机产品。
晶圆:

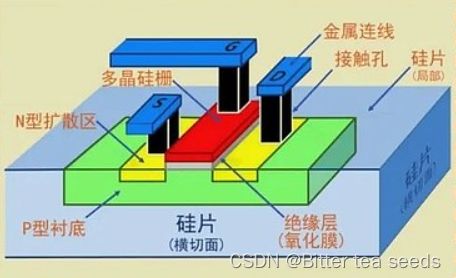
电路一般由大量的三极管、二极管、CMOS 管、电阻、电容、电感、导线等组成。这些电子元器件的实现原理,其实就是 PN 结的实现原理。PN 结是构成二极管、三极管、CMOS 管等半导体元器件的基础。
1.2、芯片电路
无论二极管、三极管还是 MOSFET 场效应管,其内部都是基于 PN 结原理实现的。
半导体工艺大部分都会涉及PN 结的实现,包括氧化、光刻、显影、刻蚀、扩散、离子注入、薄膜沉淀、金属化等主要流程。
在晶圆上进行离子注入掺杂(离子注入就是掺杂)之前,首先要根据电路版图制作一个个掺杂窗口,这一步需要光刻胶来协助完成:在硅衬底上涂上一层光刻胶,通过紫外线照射掩膜版,将电路图形投影到光刻胶上,生成一个个掺杂窗口,并将不需要掺杂的区域保护起来。
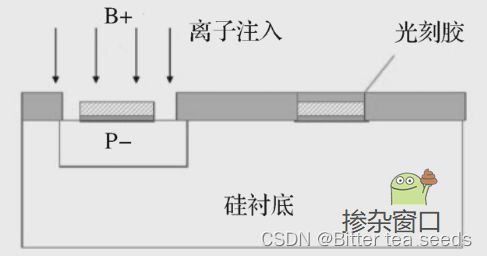
如何产生这个掺杂窗口需要一个,叫作光刻掩膜版的东西。
光刻掩膜版原理和我们照相用的胶片差不多,由透明基板和遮光膜组成,通过投影和曝光,我们可以将芯片的电路版图保存在掩膜版上。然后通过光刻机的紫外线照射,利用光刻胶的感光溶解特性,被电路图形遮挡的阴影部分的光刻胶保存下来,而被光照射的部分的光刻胶就会溶解,成为一个个掺杂窗口。
最后通过离子注入,掺杂三价元素和五价元素,就会在晶圆的硅衬底上生成主要由 PN 结构成的各种 CMOS 管、晶体管电路。我们设计的芯片物理版图的每一层电路,都需要制作对应的掩膜版,重复以上过程,就可以在晶圆上制作出迷宫式的 3D 立体电路结构。而更加微小的掺杂则需要光刻机来进行。
光刻机主要用来将你设计的电路图映射到晶圆上,通过光照将你设计的电路图形投影到光刻胶上,光刻胶中被电路遮挡的部分被保留,溶解的部分就是掺杂的窗口。晶体管越多,电路越复杂,工艺制程越先进,对光刻机的要求越高,因为需要非常精密地把复杂的电路图形投影到晶圆的硅衬底上。
一台光刻机一亿欧元。
光刻机的作用是根据电路版图制作掩膜版,开凿各种掺杂窗口,然后通过离子注入,生成 PN 结,进而构建千千万万个元器件。将这些工艺流程走一遍之后,在一个晶圆上就生成了一个个芯片的原型:芯片电路
1.3、芯片的封装
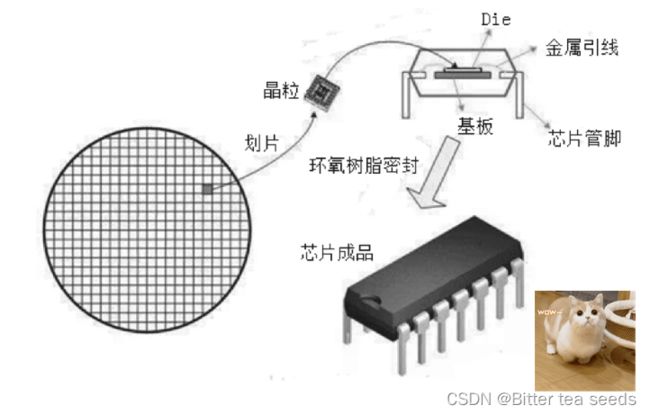
芯片的封装就是给它套个壳子,把管脚引出来。
常见的封装形式有 DIP、QFP、BGA、CSP、MCM 等。
我们用到的51单片机用的就是DIP封装;
STM32则是用到球栅阵列封装(BGA);
使用 BGA 的芯片管脚不再从芯片周边引出,而是采用表面贴装型封装:在印刷基板的背面按照阵列方式制作出球形凸点来代替管脚,然后将芯片电路装配到基板的正面,最后用膜压树脂或灌封方法进行密封。
二、CPU原理
图灵机是现代计算机的祖宗
任何复杂运算都可以用几个基本的运算指令实现。
2.1、CPU的工作原理
CPU 内部构造包含基本的算术逻辑运算单元、控制单元、寄存器等,仅支持有限个指令。CPU 支持的有限个基本指令集合,称为指令集。程序代码存储在内部存储器(内存)中,CPU 可以从内存中一条一条地取指令、翻译指令并执行它。
而早期 CPU 的工作频率和内存 RAM 相比,差距不是一般的大。控制单元从 RAM 中加载数据到 CPU,或者将 CPU 内部的数据存储到 RAM 中,一般要经过多个时钟读写周期才能完成:找地址、取数据、配置、输出数据等。
运算速度再快的 CPU,也只能干等几个时钟周期,等数据传输成功后才可以接着执行下面的指令。内存带宽的瓶颈会拖 CPU 的后腿,影响 CPU 的性能。为了提高性能,防止 RAM 拖后腿,CPU 一般都会在内部配置一些寄存器,用来保存 CPU 在计算过程中的各种临时结果和状态值。
ALU 在运算过程中,当运算结果为 0、为负、数据溢出时,也会有一些 Flags 标志位输出,这些标志位对控制单元特别有用,如一些条件跳转指令,其实就是根据运算结果的这些标志位进行跳转的。CPU 跳转指令的实现其实也很简单:根据 ALU 的运算结果和输出的 Flags 标志位,直接修改 PC 寄存器的地址即可,控制单元会自动到 PC 指针指向的内存地址取指令、翻译指令和运行指令。跳转指令的实现,改变了程序按顺序逐步执行的线性结构,可以让程序执行更加灵活,可以实现更加复杂的程序逻辑,如程序的分支结构、循环结构等。
CPU 所支持的加、减、乘、与、或、非、跳转、Load/Store、IN/OUT 等基本指令,一般称为指令集。任何复杂的运算都可以分解为指令集中的基本指令。
由基本指令组成的不同组合,我们称为程序。为了编程方便,我们给每个二进制指令起一个别名,使用一个助记符表示,这些助记符就是汇编语言,由助记符组成的指令序列就是汇编程序。汇编语言的可读性虽然比二进制的机器指令好了很多,但是当汇编程序很大、程序的逻辑很复杂时,维护也会变得无比艰难,这时候高级语言就开始问世了,如 C、C++、Java 等。高级语言的读写更符合人类习惯,更适合开发和阅读,编写好的高级语言程序通过编译器,就可以翻译成 CPU 所能识别的二进制机器指令。
2.2、CPU的设计
集成电路(IC)设计一般分为模拟 IC 设计、数字 IC 设计和数模混合 IC 设计。数字 IC 设计一般都是通过 HDL 编程和 EDA 工具来实现一个特定逻辑功能的数字集成电路的。
三、计算机体系结构
计算机主要用来处理数据。我们编写的程序,除了指令,还有各种各样的数据。指令和数据都需要保存在存储器中,根据保存方式的不同,计算机可分为两种不同的架构:冯·诺依曼架构和哈弗架构。
3.1、冯·诺依曼架构
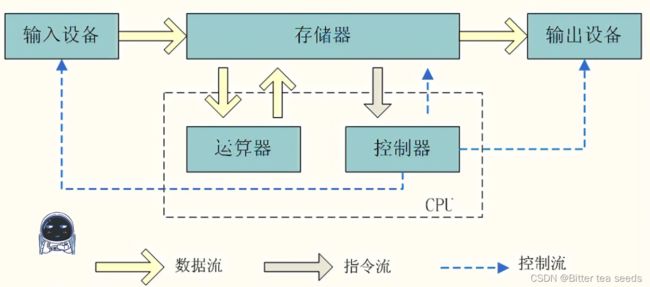
特点是程序中的指令和数据混合存储,存储在同一块存储器上
冯·诺依曼架构的计算机中,程序中的指令和数据同时存放在同一个存储器的不同物理地址上,一般我们会把指令和数据存放到外存储器中。
当程序运行时,再把这些指令和数据从外存储器加载到内存储器(内存储器支持随机访问并且访问速度快),如 :X86、ARM7、MIPS 等。
3.2、哈弗架构
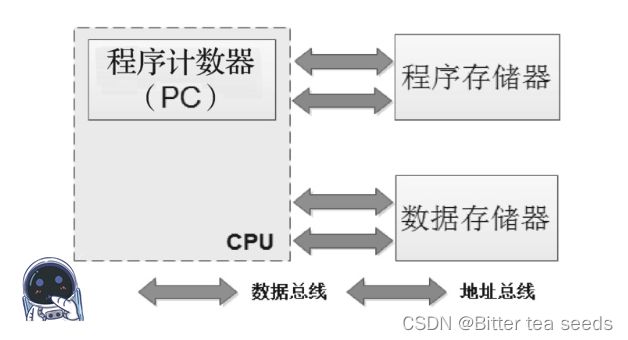
哈弗架构的特点是:指令和数据被分开独立存储,它们分别被存放到程序存储器和数据存储器。每个存储器都独立编址,独立访问,而且指令和数据可以在一个时钟周期内并行访问。
使用哈弗架构的处理器运行效率更高,但缺点是 CPU 实现会更加复杂。51 系列的单片机、DSP和现在正在学习的STM32采用的就是哈弗架构。
3.3、混合架构
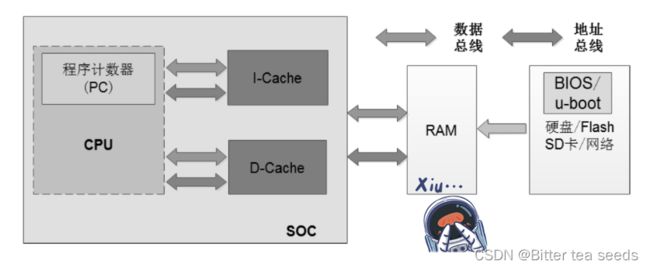
ARM SoC 芯片内部的 Cache 层采用哈弗架构,集成了指令 Cache 和数据 Cache。
SoC 芯片外部则采用冯·诺依曼架构
当 CPU 到 RAM 中读数据时,内存 RAM 不是一次只传输要读取的指定字节,而是一次缓存一批数据到 Cache 中,等下次 CPU 再去取指令和数据时,可以先到这两个 Cache 中看看要读取的数据是不是已经缓存到这里了,如果没有缓存命中,再到内存中读取。当 CPU 写数据到内存 RAM 时,也可以先把数据暂时写到 Cache 里,然后等待时机将 Cache 中的数据刷新到内存中。
四、Cache 机制
Cache 的运行速度介于 CPU 和内存 DRAM 之间,是在 CPU 和内存之间插入的一组高速缓冲存储器,用来解决两者速度不匹配带来的瓶颈问题。
4.1、Cache 机制工作原理
Cache 在物理实现上其实就是静态随机访问存储器。Cache 的工作原理很简单,就是利用空间局部性和时间局部性原理,通过自有的存储空间,缓存一部分内存中的指令和数据,减少 CPU 访问内存的次数,从而提高系统的整体性能。
Cache 里存储的内存地址,一般要经过地址映射,转换为更易存储和检索的形式。
而且为了提高性能,一般都会设计多级Cache。
而我在查看STM32芯片结构的时候就发现,STM32芯片没有Cache,在看看51单片机芯片结构也没有Cache处理器。我找了资料,知道了原因:
是因为这些处理器都是低功耗、低成本处理器,在 CPU 内集成 Cache 会增加芯片的面积和发热量,不仅功耗增加,芯片的成本也会增加不少。而且功耗增加也会影响时钟的稳定性。
其次是因为这些处理器本来工作频率就不高(从几十兆赫到几百兆赫不等),和 RAM 之间不存在带宽问题,有些处理器甚至不需要外接 RAM,直接使用片内SRAM(易失性存储器)就可满足面向控制领域的软件开发需求。
最后是因为使用 Cache 无法保证实时性。当缓存未命中时,CPU 从 RAM 中读取数据的时间是不确定的,这是嵌入式实时控制场景无法接受的。
五、总线和地址
CPU 与内存、各种外部设备等 IP 之间都是通过总线相连的。
5.1、地址
地址的本质其实就是由 CPU 管脚发出的一组地址控制信号。因为这些信号是由 CPU 管脚直接发出的,因此也被称为物理地址。
地址信号线的位数决定了寻址空间的大小,如上面的两根 A1A0 地址信号线,有 4 字节的寻址空间;CSA1A0 三根地址信号线有 8 字节的寻址空间。在一个 32 位的计算机系统中,32 位的地址线有 4GB 大小的寻址空间。
5.2、总线的概念
总线其实就是各种数字信号的集合,包括地址信号、数据信号、控制信号等。有的总线还可以为挂到总线上的设备提供电源。
一个计算机系统中可能会有各种不同的总线,不同的总线读写时序、工作频率不一样,不同的总线之间通过桥(bridge)来连接。桥一般是一个芯片组电路,用来将总线的电子信号翻译成另一种总线的电子信号。
桥用来将 CPU 从系统总线发过来的电子信号转换成内存能识别的内存总线信号,或者显卡能识别的 PCI 总线信号,进而完成后续的数据传输和读写过程。
六、指令集与微架构
不同架构的处理器支持的指令类型是不同的。ARM 架构的处理器只支持 ARM 指令,X86 架构的处理器只支持 X86 指令。如果你在 ARM 架构的处理器上运行 X86 指令,就无法运行,报未定义指令的错误,因为 ARM 架构的处理器只支持 ARM 指令集中定义的指令。CPU 支持的有限个指令的集合,我们称之为指令集。
6.1、什么是指令集
指令集架构(Instruction Set Architecture,ISA)是计算机体系架构的一部分。指令集是一个标准规范。
作为 CPU 和编译器的设计规范和参考标准,主要用来定义指令的格式、操作数的类型、寄存器的分配、地址的格式等,指令集主要由以下内容组成
● 指令的分发、预取、解码、执行、写回。
● 操作数的类型、存储、存取、旁路转移。
● Load/Store 架构。
● 寄存器。
● 地址的格式、大端模式、小端模式。
● 字节对齐、边界对齐等。
6.2什么是微架构
微架构,就是处理器架构。
集成电路工程师在设计处理器时,会按照指令集规定的指令,设计具体的译码和运算电路来支持这些指令的运行;指令集在 CPU 处理器内部的具体硬件电路的实现,我们就称为微架构。
一套相同的指令集,可以由不同形式的电路实现,可以有不同的微架构。
以 ARM V7 指令集为例,基于该套指令集,面向高性能、低功耗等不同的市场定位,ARM 公司设计出了 Cortex-A7、Cortex-A8、Cortex-A9、Cortex-A15、Cortex-A17 等不同的微架构。
基于一款相同的微架构,通过不同的配置,也可以设计出不同的处理器类型。
主要参考资料《嵌入式C语言自我修养》