GPU架构分析
文章目录
- 概要
-
- 整体架构流程
- SIMT
- Fermi架构
- Kepler 架构
-
- Dynamic Parallelism
- Hyper-Q
- GPU内存架构
-
- 概述
- 具体情况
- 参考
概要
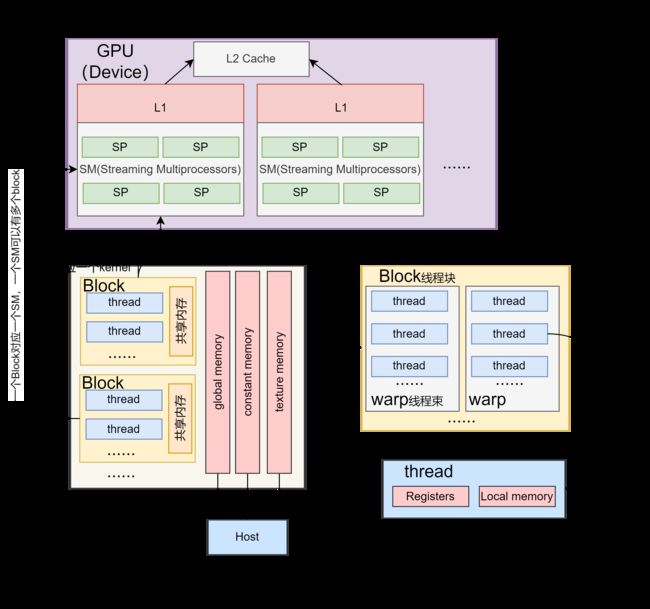
首先概括一下这几个概念。其中SM(Streaming Multiprocessor)和SP(streaming Processor)是硬件层次的,其中一个SM可以包含多个SP。thread是一个线程,多个thread组成一个线程块block,多个block又组成一个线程网格grid。
现在就说一下一个kenerl函数是怎么执行的。一个kernel程式会有一个grid,grid底下又有数个block,每个block是一个thread群组。在同一个block中thread可以通过共享内存(shared memory)来通信,同步。而不同block之间的thread是无法通信的。
CUDA的设备在实际执行过程中,会以block为单位。把一个个block分配给SM进行运算;而block中的thread又会以warp(线程束)为单位,对thread进行分组计算。目前CUDA的warp大小都是32,也就是说32个thread会被组成一个warp来一起执行。同一个warp中的thread执行的指令是相同的,只是处理的数据不同。
基本上warp 分组的动作是由SM 自动进行的,会以连续的方式来做分组。比如说如果有一个block 里有128 个thread 的话,就会被分成四组warp,第0-31 个thread 会是warp 1、32-63 是warp 2、64-95是warp 3、96-127 是warp 4。而如果block 里面的thread 数量不是32 的倍数,那他会把剩下的thread独立成一个warp;比如说thread 数目是66 的话,就会有三个warp:0-31、32-63、64-65 。由于最后一个warp 里只剩下两个thread,所以其实在计算时,就相当于浪费了30 个thread 的计算能力;这点是在设定block 中thread 数量一定要注意的事!
一个SM 会根据其内部SP数目分配warp,但是SM 不见得会一次就把这个warp 的所有指令都执行完;当遇到正在执行的warp 需要等待的时候(例如存取global memory 就会要等好一段时间),就切换到别的warp来继续做运算,借此避免为了等待而浪费时间。所以理论上效率最好的状况,就是在SM 中有够多的warp 可以切换,让在执行的时候,不会有「所有warp 都要等待」的情形发生;因为当所有的warp 都要等待时,就会变成SM 无事可做的状况了。
实际上,warp 也是CUDA 中,每一个SM 执行的最小单位;如果GPU 有16 组SM 的话,也就代表他真正在执行的thread 数目会是32*16 个。不过由于CUDA 是要透过warp 的切换来隐藏thread 的延迟、等待,来达到大量平行化的目的,所以会用所谓的active thread 这个名词来代表一个SM 里同时可以处理的thread 数目。而在block 的方面,一个SM 可以处理多个线程块block,当其中有block 的所有thread 都处理完后,他就会再去找其他还没处理的block 来处理。假设有16 个SM、64 个block、每个SM 可以同时处理三个block 的话,那一开始执行时,device 就会同时处理48 个block;而剩下的16 个block 则会等SM 有处理完block 后,再进到SM 中处理,直到所有block 都处理结束
在CUDA 架构下,GPU芯片执行时的最小单位是thread。
若干个thread可以组成一个线程块(block)。一个block中的thread能存取同一块共享内存,可以快速进行同步和通信操作。
每一个block 所能包含的thread 数目是有限的。执行相同程序的block,可以组成grid。不同block 中的thread 无法存取同一共享内存,因此无法直接通信或进行同步。
不同的grid可以执行不同的程序(kernel)。
举个栗子:
1:一个SM有8个SP,SM执行一个Warp时有32个线程,这32各线程在8个SP上执行4次,实际上是8个8个轮替(注意这里是一个时间周期),严格意义上来讲不是同时执行,只是隐藏延迟,因为软件层我们是将其抽象出来,因此可以说是同时执行。对于下图,一个SM有4个SP,一个warp一共32个thread,每执行一次SM则由4个SP执行4个thread,所以需要8轮。
2:当一个SM中有更多的SP时,例如GP100这种,一个SM上有64个SP,线程也不一定是平摊的,看具体架构的官方文档。一般情况下还是8个sp执行4次,也就是说当你数据跑32个线程的时候,在有64个SP的SM里实际还是8个SP在跑,和一个SM里面只有8个SP的情况是一致的。所以一个SM有64个SP的时候,意味着最多同时可以并行8个warp,8×32线程即256和线程。此时通常情况来说已经满线程了,当架构能进一步降低延迟时,通过抽象可以跑1024个线程。
注意:
一个有8个SP的SM执行一个32 thread的warp是不是要4次:
假设一个 SM 中有 8 个 SP,而一个 warp 包含 32 个线程。在CUDA编程模型中,一个 warp 的指令被执行时,通常是在一个时钟周期内完成的。这是因为 GPU 设计采用了 SIMD(Single Instruction, Multiple Thread)的模型,即一个指令同时应用于 warp 中的所有线程。因此,对于一个 warp,如果有 8 个 SP,理论上,每个 SP 在一个时钟周期内执行一个 warp 的 32 条指令,整个 warp 可以在一个时钟周期内完成。实际上,GPU 可能在一个时钟周期内执行多个 warp 的指令(4次),以充分利用并行性。需要注意的是,这里的 SP 数量和 warp 中的线程数量是两个独立的概念。SP 的数量通常比 warp 中的线程数量大得多,因为每个 SP 在一个时钟周期内可以执行多个 warp 的指令。
整体架构流程
SIMT
SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。
以Fermi架构为例,其包含以下主要组成部分:
- CUDA cores
- Shared Memory/L1Cache
- Register File
- Load/Store Units
- Special Function Units
- Warp Scheduler
GPU中每个SM都设计成支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行,当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
CUDA采用Single Instruction Multiple Thread(SIMT)的架构来管理和执行thread,这些thread以32个为单位组成一个单元,称作warps。warp中所有线程并行的执行相同的指令。每个thread拥有它自己的instruction address counter和状态寄存器,并且用该线程自己的数据执行指令。
SIMT和SIMD(Single Instruction, Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。SIMT有三个SIMD没有的主要特征:
每个thread拥有自己的instruction address counter
每个thread拥有自己的状态寄存器
每个thread可以有自己独立的执行路径
更细节的差异可以看这里。
一个block只会由一个SM调度,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个block。下图显示了软件硬件方面的术语:
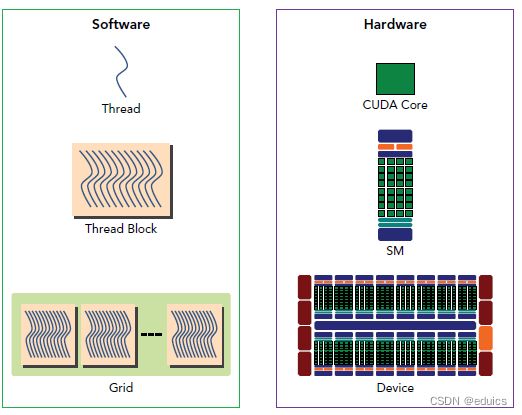
需要注意的是,大部分thread只是逻辑上并行,并不是所有的thread可以在物理上同时执行。这就导致,同一个block中的线程可能会有不同步调,比如上面说的32个线程在一个有8个SP的SM中执行4次。
并行thread之间的共享数据回导致竞态:多个线程请求同一个数据会导致未定义行为。CUDA提供了API来同步同一个block的thread以保证在进行下一步处理之前,所有thread都到达某个时间点。不过,我们是没有什么原子操作来保证block之间的同步的。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以该新调度的warp的状态已经存储在SM中了。
SM可以看做GPU的心脏,寄存器和共享内存是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的thread。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。所以,掌握部分硬件知识,有助于CUDA性能提升。
Fermi架构
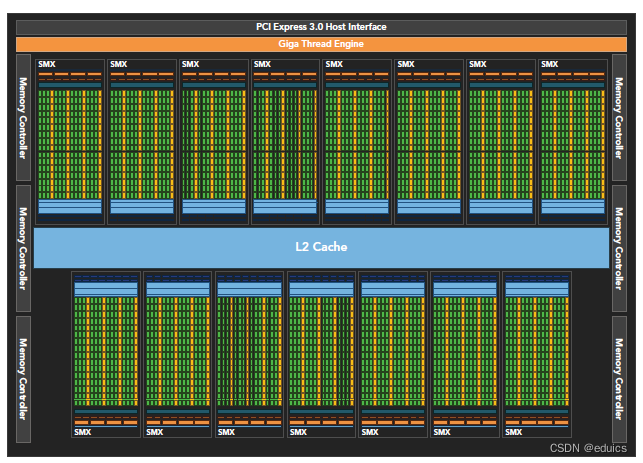
Fermi是第一个完整的第三代GPU计算架构。512 个 CUDA 核心被组织成 16 个 SM,每个 32 个核心。
GPU 有6个 64 位显存分区,用于 384 位显存接口,总共支持高达 6 GB 的 GDDR5 DRAM 显存。
主机接口通过 PCI-Express 将 GPU 连接到 CPU。 GigaThread 全局调度程序将线程块分发给 SM 线程调度程序。
Fermi 的 16 个 SM 位于一个普通的 L2 缓存周围。
每个 SM 是一个垂直的矩形条带,包含橙色部分(调度程序和调度器)、绿色部分(执行单元)和浅蓝色部分(寄存器文件和 L1 缓存)。
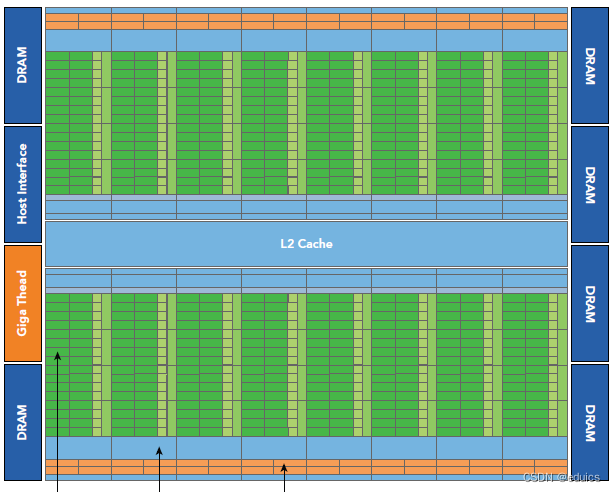
- 512个accelerator cores即所谓CUDA cores(SP)(包含ALU和FPU),为线程的每个时钟执行浮点或整数指令
- 16个SM,每个SM包含32个CUDA core,,比 GT200 高出 4 倍
- 8 倍于 GT200 的峰值双精度浮点性能
- 六个384位 GDDR5 DRAM,支持6GB global on-board memory
- GigaThread engine(图左侧)将thread blocks分配给SM调度
- 768KB L2 cache
- 每个SM有16个load/store单元,允许每个clock cycle为16个thread(即所谓half-warp,不过现在不提这个东西了)计算源地址和目的地址
- Special function units(SFU)用来执行sin cosine 等
- 每个SM两个warp scheduler两个instruction dispatch unit,当一个block被分配到一个SM中后,所有该block中的thread会被分到不同的warp中。Dual Warp Scheduler 2个独立的warp,同时调度和发送指令
- Fermi(compute capability 2.x)每个SM同时可处理48个warp共计1536个thread。
- 64 KB RAM,具有可配置的共享内存和 L1 缓存分区
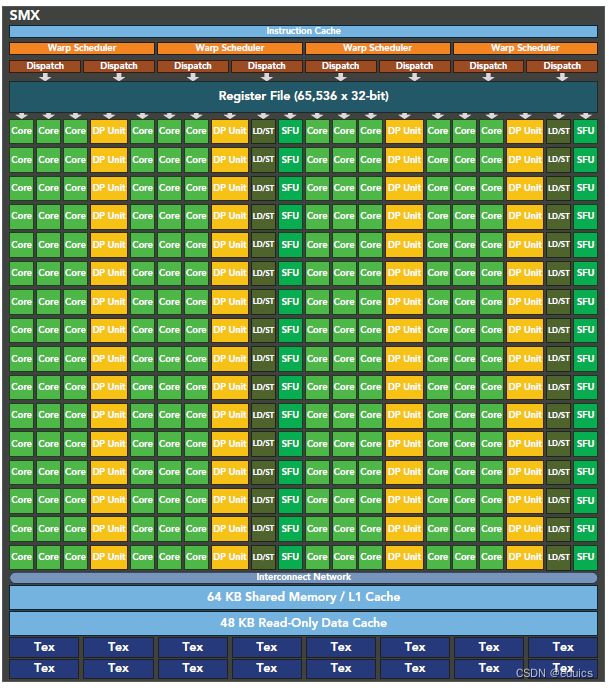
每个SM由一下几部分组成:
- 执行单元(CUDA cores):为线程的每个时钟执行浮点或整数指令
- 寄存器(Register File)
- 调度分配warp的单元
- 共享内存shared memory
- L1 cache
- LDU(Load-Store Units):每个SM有16个Load/Store单元,允许16个线程每个时钟周期计算源和目的地址,支持将每个地址的数据读取和存储到缓存或DRAM中.
关于LDU:SM(Streaming Multiprocessor)上的 Load/Store 单元数量并不直接决定每个时钟周期只能使用多少个 SP(Stream Processor,也称为 CUDA 核心)。这两者是不同的功能单元,它们各自执行不同的任务。Load/Store 单元主要负责处理内存的加载和存储操作。这包括从全局内存读取数据(Load)、将数据写入全局内存(Store)以及进行地址计算等。Load/Store 单元的数量通常与内存带宽和存储器访问效率相关,而不是直接与 SP 的数量相关。SP(CUDA 核心)是负责执行计算操作的单元。每个 SM 中有多个 SP,而且每个 SP 可以在一个时钟周期内执行一个 warp 的指令。SP 的数量通常比 Load/Store 单元多,因为 GPU 的主要任务是执行计算密集型的并行任务。
在某些情况下,Load/Store 单元的数量可能会对计算性能产生影响,特别是在存在大量内存操作的工作负载中。然而,并不是每个 SP 都需要一个对应的 Load/Store 单元。SM 中的 SP 和 Load/Store 单元通常以一种协同的方式工作,以实现对存储器的高效访问。
因此,Load/Store 单元的数量不会直接决定每个时钟周期只能使用多少个 SP。实际上,一个 SM 中的 SP 可以在一个时钟周期内执行一个 warp 的指令,而 Load/Store 单元则负责管理内存操作,这两者是并行工作的。
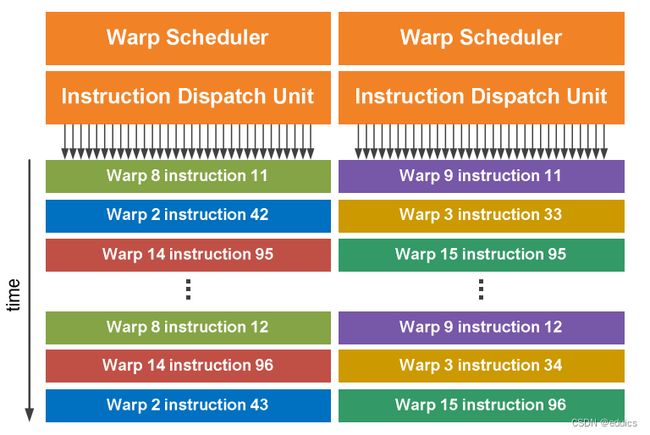
7.特殊函数单元 SFU(Special-Function Units):处理sin、cos、求倒数、开平方函数。每个SFU在每个时钟周期内为每个线程执行一个指令;一个warp需要执行8个时钟周期。SFU流水线与调度单元解耦,使得调度单元可以向其他执行单元发出指令,同时SFU正忙。 - 双warp调度器(Wrap Scheduler):SM将32个并行的线程归为一组称为线程束(即warp),以此为单位进行调度。每个SM具有两个warp调度器和两个指令分派单元,允许同时有两个warp被分派指令和执行。Fermi的双warp调度器选择两个warp,每个warp的指令会发送到16个核心、16个加载/存储单元或4个SFU中。由于warp独立执行,Fermi的调度器不需要从指令流中检查依赖关系。使用这种优雅的双分发模型,Fermi实现了接近硬件峰值的性能。
这种结构通过层级结构组织大量的CUDA计算核,并给各级都分配相应的内存系统,使得GPU具有高并行度计算的能力。
内存接口位数是显卡或其他设备与内存之间传输数据时的数据位数。主要体现在2个方面:
- 内存带宽:内存接口位数越高,设备每秒钟可以传输的数据量就越大,带宽就越大。带宽的大小直接影响设备的性能。
- 内存容量:内存接口位数和内存容量之间有一定的关系。例如,如果显卡的内存接口位数为256位,那么它对应的内存容量通常为2GB或4GB。因为一般来说,内存容量越大,数据位数也就越大,需要更高的内存接口位数才能满足数据传输的需求。
Kepler 架构
Kepler相较于Fermi更快,效率更高,性能更好。
- 15个SM
- 6个64位memory controller
- 192个单精度CUDA cores,64个双精度单元,32个SFU,32个load/store单元(LD/ST)
- 增加register file到64K
- 每个Kepler的SM包含四个warp scheduler、八个instruction dispatchers,
使得每个SM可以同时issue和执行四个warp。注意:Warp Scheduler: Warp Scheduler 是负责从就绪状态的 warp 集合中选择 warp 并将其发送到执行单元的组件。每个 Warp Scheduler 可能能够在一个时钟周期内调度一个 warp。``Instruction Dispatchers: Instruction Dispatchers 是负责将 warp 中的指令发送到执行单元的组件。这些指令包括各种计算和存储操作。八个 Instruction Dispatchers 可能允许同时向多个 warp 中的不同线程分派指令。结合上述两个概念,每个 SM 可以在一个时钟周期内同时 issue 和执行多个 warp。例如,如果每个 Warp Scheduler 在一个时钟周期内可以调度一个 warp,而有四个 Warp Scheduler,那么在这个时钟周期内,SM 可能同时 issue 和执行多达四个 warp。
Kepler K20X(compute capability 3.5)每个SM可以同时调度64个warp共计2048个thread。
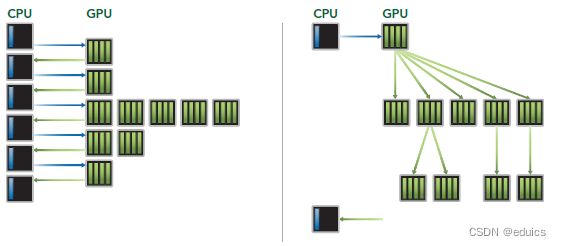
Dynamic Parallelism
Dynamic Parallelism是Kepler的新特性,允许GPU动态的启动新的Grid。有了这个特性,任何kernel内都可以启动其它的kernel了。这样直接实现了kernel的递归以及解决了kernel之间数据的依赖问题。也许D3D中光的散射可以用这个实现。
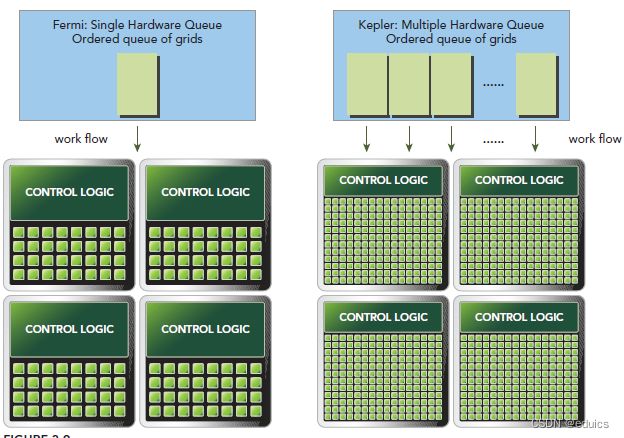
Hyper-Q
Hyper-Q是Kepler的另一个新特性,增加了CPU和GPU之间硬件上的联系,使CPU可以在GPU上同时运行更多的任务。这样就可以增加GPU的利用率减少CPU的闲置时间。Fermi依赖一个单独的硬件上的工作队列来从CPU传递任务给GPU,这样在某个任务阻塞时,会导致之后的任务无法得到处理,Hyper-Q解决了这个问题。相应的,Kepler为GPU和CPU提供了32个工作队列。
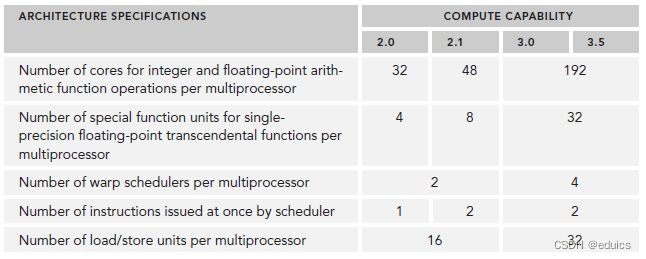
不同arch的主要参数对比
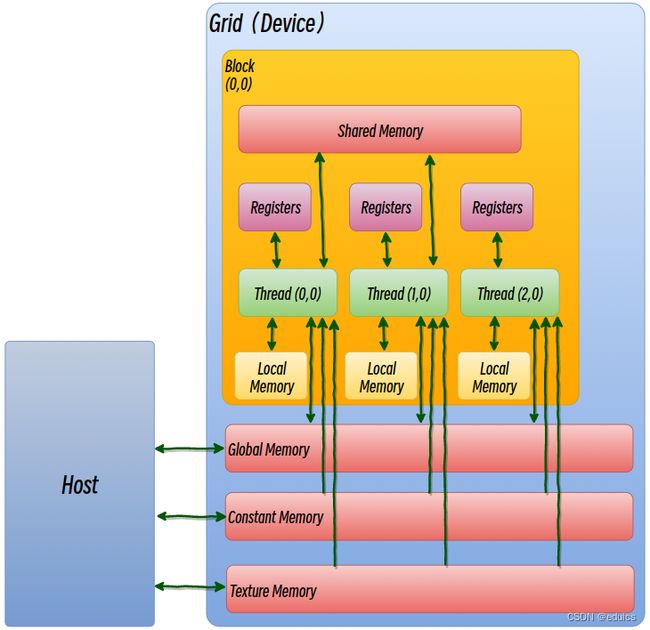
GPU内存架构
概述
GPU内存(1为片上内存,234为片下内存,片上内存与片下内存之间有L1,L2Cache,下面未画出):
- 寄存器(Register):寄存器是GPU上运行速度最快的内存空间,带宽为8TB/s,延迟为1个时钟周期。尽量将数据声明为局部变量,尽量使用寄存器
- 共享内存(Shared memory):GPU上可受用户控制的一级缓存。具有更高的带宽与更低的延迟,通常其带宽为1.5TB/s左右,延迟为1~32个时钟周期。当存在重复利用的数据时,将数据放在共享内存里。如果数据不被重用,则直接将数据从全局内存或常量内存读入寄存器即可。
- 常量内存(Constant Memory)
- 全局内存(Global Memory):
GPU中最大、延迟最高并且最常使用的内存。在编程中对全局内存访问的优化以最大化程度提高全局内存的数据吞吐量是十分重要的。尽量减少内存子系统再次发出访问操作的次数
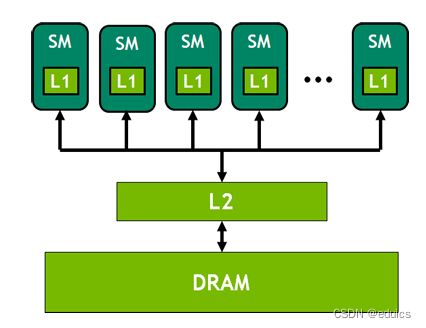
所有的 SM 共享 L2 缓存。整个 GPU 内存结构如下图所示:
具体情况
具体来说,GPU 的内部存储
按照存储功能进行细分,GPU 内存可以分为:局部内存(local memory)、全局内存(global memory)、常量内存(constant memory)、共享内存(shared memory)、寄存器(register)、L1/L2 缓存等。
其中全局内存、局部内存、常量内存都是片下内存,储存在 HBM (HBM,全称为High Bandwidth Memory,是一种用于图形处理器(GPU)和其他高性能计算设备的先进内存技术。HBM 旨在提供比传统GDDR(Graphics Double Data Rate)内存更高的带宽和更低的功耗)上。所以我们说 HBM 的大部分作为全局内存。
-
全局内存
全局内存(global memory)能被 GPU 的所有线程访问,全局共享。它是片下(off chip)内存,前面提到的硬件 HBM 中的大部分都是用作全局内存。跟 CPU 架构一样,运算单元不能直接使用全局内存的数据,需要经过缓存,其过程如下图所示:

-
L1/L2缓存
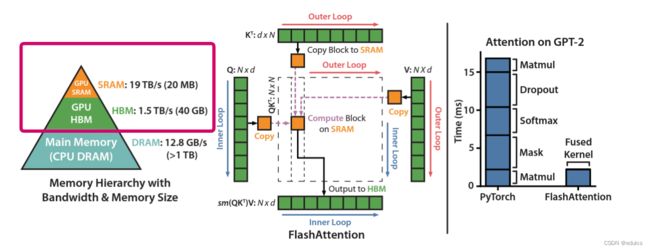
L1 缓存用于存储 SM 内的数据,被 SM 内的 CUDA cores 共享,但是跨 SM 之间的 L1 不能相互访问;L2 缓存可以被所有 SM 访问,速度比全局内存快。``合理运用 L2 缓存能够提速运算。A100 的 L2 缓存能够设置至多 40MB 的持续化数据 (persistent data),能够拉升算子 kernel 的带宽和性能。Flash attention 的思路就是尽可能地利用 L2 缓存,减少 HBM 的数据读写时间。
关于 SRAM 与 DRAM:
RAM 分为静态 RAM(SRAM)和动态 RAM(DRAM)。SRAM 只要存入数据后,即使不刷新也不会丢失记忆;而 DRAM 的电容需要周期性地充电,否则无法确保记忆长存。
DRAM 密度高、成本低、访问速度较慢、耗电量大。SRAM 则刚好相反。因此 SRAM 首选用于带宽要求高,或者功耗要求低的情境。如:CPU Cache、GPU On-Chip Buffer。DRAM 则一般用于系统内存、显存。
根据 What is the type of on-chip memories in NVIDIA gpus!? 这个讨论,GPU 的片上内存都是 SRAM。 -
局部内存
局部内存 (local memory) 是线程独享的内存资源,线程之间不可以相互访问。局部内存属于片下内存,所以访问速度跟全局内存一样。它主要是用来应对寄存器不足时的场景,即在线程申请的变量超过可用的寄存器大小时,nvcc 会自动将一部数据放置到片下内存里。 -
寄存器
寄存器(register)是线程能独立访问的资源,它是片上(on chip)存储,用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小,只有几百甚至几十 KB,而且要被许多线程均分。 -
共享内存
共享内存(shared memory) 是一种在线程块内能访问的内存,是片上(on chip)存储,访问速度较快。
共享内存主要是缓存一些需要反复读写的数据。
注:共享内存与 L1 缓存的位置、速度极其类似,区别在于共享内存的控制与生命周期管理与 L1 不同:共享内存受用户控制,L1 受系统控制。共享内存更利于线程块之间数据交互。 -
常量内存
常量内存(constant memory)是片下(off chip)存储,但是通过特殊的常量内存缓存(constant cache)进行缓存读取,它是只读内存。常量内存主要是解决一个 warp scheduler 内多个线程访问相同数据时速度太慢的问题。假设所有线程都需要访问一个 constant_A 的常量,在存储介质上 constant_A 的数据只保存了一份,而内存的物理读取方式决定了多个线程不能在同一时刻读取到该变量,所以会出现先后访问的问题,这样使得并行计算的线程出现了运算时差。常量内存正是解决这样的问题而设置的,它有对应的 cache 位置产生多个副本,让线程访问时不存在冲突,从而保证并行度。
参考
- https://www.cnblogs.com/1024incn/p/4539754.html
- https://blog.csdn.net/moneymyone/article/details/131465920