机器学习第14天:KNN近邻算法

☁️主页 Nowl
专栏《机器学习实战》 《机器学习》
君子坐而论道,少年起而行之

文章目录
介绍
实例
回归任务
缺点
实例
分类任务
如何选择最佳参数
结语
介绍
KNN算法的核心思想是:当我们要判断一个数据为哪一类时,我们找与它相近的一些数据,以这些数据的类别来判断新数据
实例
我们生成一些数据,看下面这张图
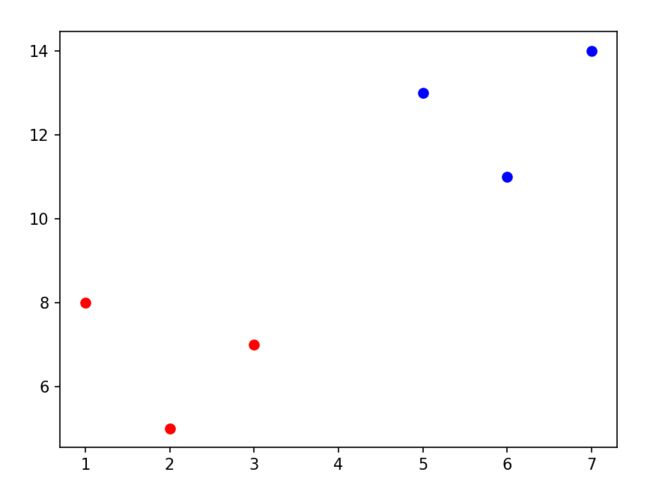
有两类点,红色与蓝色,这时我们再加入一个灰色的点
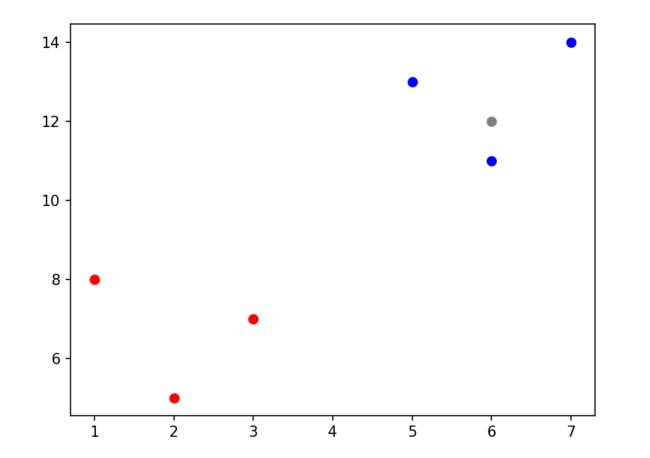
我们设置模型选择周围的三个点,可以看到最近的三个都是蓝色点,那么模型就会将新的数据判别为蓝色点
回归任务
尽管KNN算法主要用来做分类任务,但它也可以用来回归,新数据的值就是相近样本的平均值
缺点
由于它没有拟合参数,仅仅是找到周围样本点的平均值,在一些有趋势的曲线中它的预测往往不会很好
实例
我们创建几个样本点,可以看到这是一个完美的线性曲线,我们看看k近邻算法在这个简单任务上的表现
# 导入必要的库
from sklearn.neighbors import KNeighborsRegressor
# 生成一些示例数据(假设是二维特征)
X = [[1], [2], [3], [4], [5]]
y = [[3], [6], [9], [12], [15]]
x_new = [[6]]
# 创建 KNN 回归器,假设 K=3
knn = KNeighborsRegressor(n_neighbors=3)
# 在训练数据上拟合模型
knn.fit(X, y)
# 在测试数据上进行预测
y_pred = knn.predict(x_new)
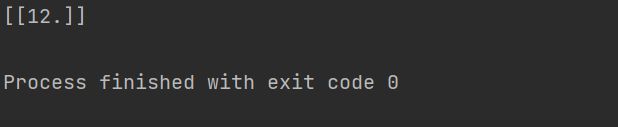
print(y_pred)在这个数据集上x为6的点y值应该是18,可是k近邻回归的特点取周围样本点的平均值,结果就会是12
分类任务
我们以上图的数据为例
# 导入KNN分类库
from sklearn.neighbors import KNeighborsClassifier
# 生成一些示例数据
X = [[1, 8], [2, 5], [3, 7], [5, 13], [6, 11], [7, 14]]
y = [0, 0, 0, 1, 1, 1]
x_new = [[6, 12]]
# 创建 KNN 分类器,设置k=3
knn = KNeighborsClassifier(n_neighbors=3)
# 在训练数据上拟合模型
knn.fit(X, y)
# 进行预测
y_pred = knn.predict(x_new)
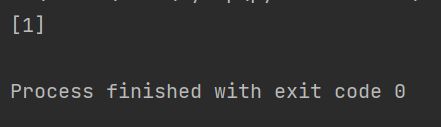
print(y_pred)
n_neighbors参数设置了新数据要参考周围的多少个点,这里设置为3,代表参考相近的三个点的值
结果为1
如何选择最佳参数
由以上知识可以知道,影响KNN算法的参数是n_neighbors,那么我们可以更新n_neighbors,然后记录下每个参数模型在测试集上的损失来获得最优参数
绘制代码如下,这里主要学习思想,数据可能会在之后的机器学习实战系列中遇到
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, cross_val_score
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv("datasets/data-science-london-scikit-learn/train.csv", header=None)
y = pd.read_csv("datasets/data-science-london-scikit-learn/trainLabels.csv", header=None)
y = np.ravel(y)
# 将数据分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data, y, test_size=0.2, random_state=42)
N = range(2, 26)
kfold = 10
test_acc = []
val_acc = []
# 记录不同参数的准确率
for n in N:
knn = KNeighborsClassifier(n_neighbors=n)
knn.fit(x_train, y_train)
test_acc.append(knn.score(x_train, y_train))
val_acc.append(np.mean(cross_val_score(knn, x_test, y_test, cv=kfold)))
# 绘制准确率曲线
plt.plot(range(2, 26), test_acc, c='b', label='test_acc')
plt.plot(range(2, 26), val_acc, c='r', label='val_acc')
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
plt.title('K Neighbors vs Accuracy')
plt.legend()
plt.show()
得到准确率与交叉验证误差曲线,
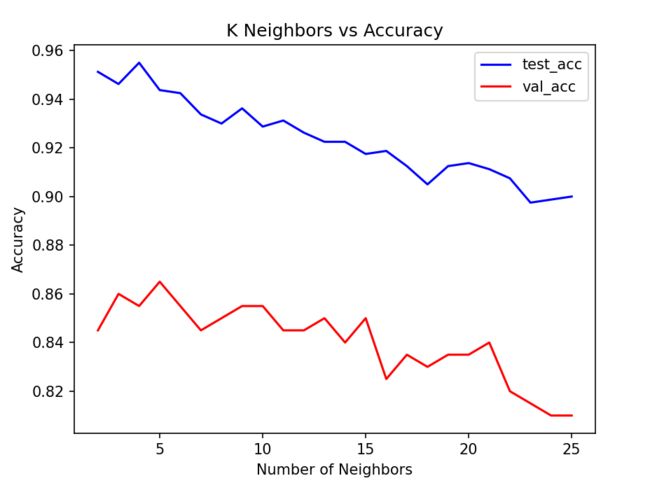
可以看到n_neighbors=5时模型的准确率最好,我们最后就可以使用这个参数
结语
- k近邻算法几乎没有训练过程,它只需要记住训练集的特征就行,以便之后进行比较,它不需要拟合什么参数
- 可以绘制准确率曲线来找到最好的k值
- 可以进行回归任务,但在模型情况下效果不是很好
感谢阅读,觉得有用的话就订阅下本专栏吧