国产分布式数据库StarDB核心技术 一:内核分解之数据分片
前言
作者:徐力权(StarDB架构师)
数据分片是分布式数据库主要特性之一,好的分片设计能让数据库服务器资源得到最大化利用,提升系统吞吐量。灵活的分片策略实现是StarDB的重要特性之一,StarDB在京东内部经过大量的实战积累了上百种分片算法。针对不同的业务需求,StarDB提供了多种多样的分片方案,首先介绍一下StarDB数据分片的设计。
一、数据分片设计原理
StarDB采用模块化分层设计思想,路由模块是专门针对数据分片和路由做设计的一个模块,StarDB对路由模块做了高度抽象,每一级路由采用了递归算法实现,能支持任意多级的路由,每一级的路由又可以自定义实现,故而组成了多种多样的路由算法类库。
首先看下路由模块执行流程:
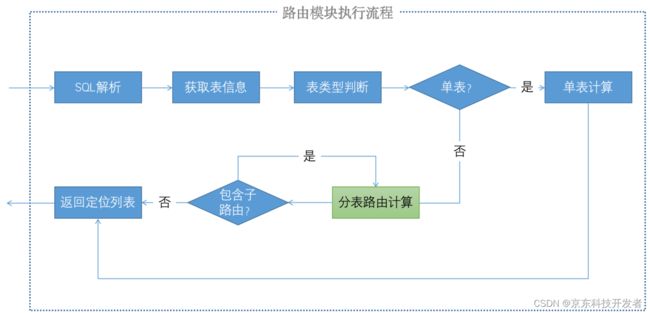
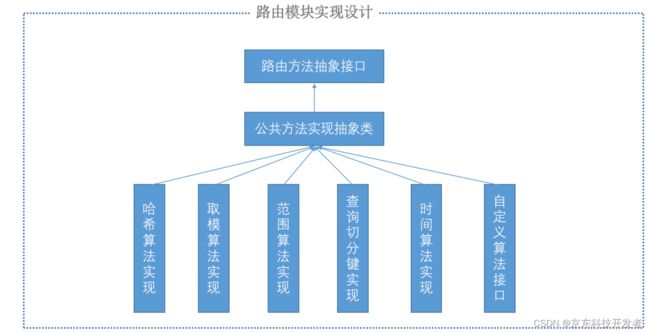
再来看下路由模块的实现设计:
二、数据分片主要特性
1.业务层无感知
StarDB提供Driver和Proxy访问模式,用JDBC或MySQL协议访问,业务代码基本不用改造,对于业务使用透明,只需对逻辑表操作:
DDL不用对某个分表操作,由底层完全封装
2. 灵活的路由算法 (内部使用达上百种)
哈希取模算法
范围算法
日期处理算法
自定义算法
指定库表强制路由算法
……
3. 多种算法自由组合
先分库后分表
查询切分键
按业务类型和时间组合
指定分表路由
……
三、经典案例
1.常规哈希取模
这种是最常规的路由方式,适合按某个字段打散数据,常规的像按订单号、用户pin、商户号等路由的场景都可以用哈希取模的方式。StarDB在此基础上,扩展了路由算法,比如有如下表
CREATE TABLE order (
id int(11) NOT NULL AUTO_INCREMENT,
order_no varchar(255) DEFAULT NULL COMMENT '订单号',
creation_date timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间,非空',
modification_date timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间,非空',
PRIMARY KEY (id),
) ENGINE=InnoDB COMMENT='订单表';
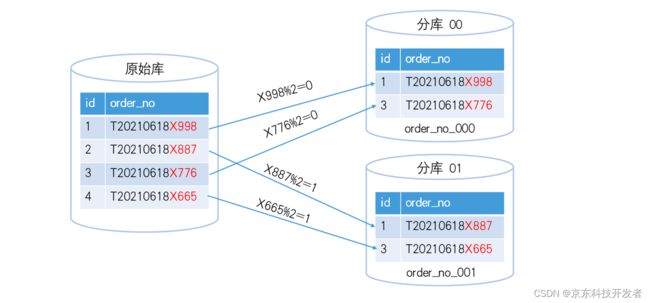
常规设计按order_no做切分,只要订单号是均匀的,数据就能随机打散;但是某些业务有些特殊,希望按订单号某几位做路由,比如订单号的格式如下:固定前缀(1位)+时间戳(8位)+随机序号(4位),他只希望按随机序号做路由,那StarDB可自定义他的实现算法只取最后8位做路由:
route_key = order.substring(9,13) % mod_size
如下图简化实现:
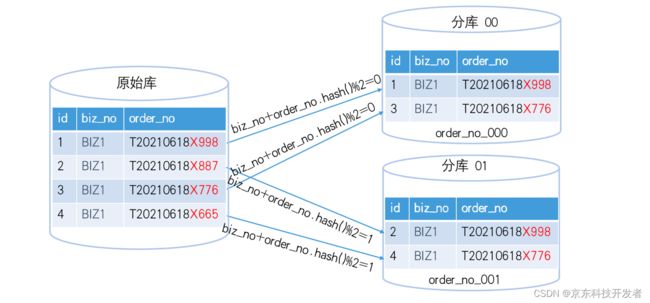
另外有些业务,业务设计希望按biz_no取模,但是biz_no又是一个不均匀的数,可以通过与一个其他随机性较强的字段组成一个复合切分键,以上述表为例
route_key = (biz_no+order_no).hash();
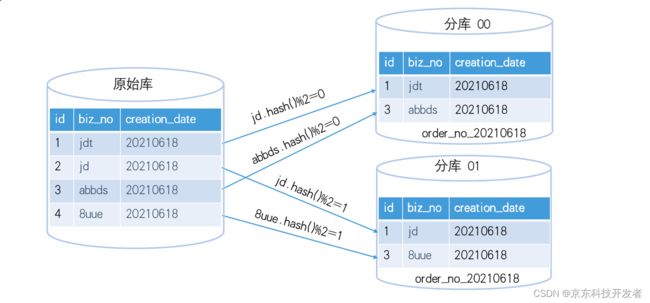
2. 按时间和业务id多级路由
有的业务,时间属性很强,比如3个月以前的数据就很少再做变更,而每天的增量数据又很大,像这些业务,可以用biz_no+时间做二级路由,如上述表,可以用biz_no先做一级分库,再根据creation_date做二级分表,每天一个分表,最终表后缀格式:order_yyyyMMdd。按上述设计,有SQL如下
select * from order where creation_date = '2021-06-18 12:00:00' and biz_no = 'jdt'
先计算出biz_no = 'jdt' 对应的分库,再根据creation_date = '2021-06-18 12:00:00' 算出分表后缀,得出最终的分表后缀:order_20210618@db_1
3. 级联路由的某一级缺省实现
对于级联路由,StarDB对每一级都允许用户实现当这一级缺省时候的算法实现,比如上述例子,当SQL语句缺省了biz_no时,即SQL如下
select * from order where creation_date = '2021-06-18 12:00:00'
StarDB会去每个分库找符合分表后缀满足的分表,即返回的是一个列表
order_20210618@db_0 order_20210618@db_1 order_20210618@db_2
同样,当SQL语句缺省creation_date时,StarDB返回当前库,所有的分表,假设biz_no定位到1号分库,则返回分表情况如下:
order_20210101@db_1 ~ order_20211231@db_1
这样做的好处是每一级路由都能缩小一定的查询范围,从而让业务有更大的灵活性。
上述是比较典型的拆分案例,还有的业务先按时间一级路由,每天又根据biz_no拆分成多个分表分摊到多个分库里,表后缀的格式如下:order_yyyyMMdd_xx,其中yyyyMMdd通过时间计算,xx对应每个分库,如20210618年分6个分库,每个分库都这一天的分表,0号库对应的分表后缀就是order_20210618_00,依次类推,这样做的好处是能让每个分库每天都能利用起来,比较适合数据量大的业务。
4.查询切分键
当前切分键不做写入路由,只做查询路由,当前字段能根据一定的算法计算出路由结果的切分键,StarDB称之为查询切分键,这类切分键有很广泛的用途,尤其是对于业务不能经常按切分键路由的时候,StarDB碰到了很多场景,举例如下:
CREATE TABLE trade_info (
id int(11) NOT NULL AUTO_INCREMENT,
out_trade_no varchar(255) DEFAULT NULL COMMENT '外部订单号',
trade_no varchar(255) DEFAULT NULL COMMENT '内部订单号',
creation_date timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间,非空',
modification_date timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间,非空',
PRIMARY KEY (id),
) ENGINE=InnoDB COMMENT='订单表';
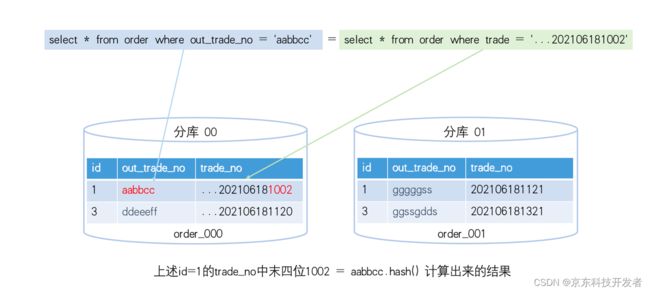
上述是一个交易系统的核心表部分字段,里面主要有两个字段,一个是out_trade_no,另一个是trade_no,其中out_trade_no由于是外部传入的订单号,所以不能修改这个订单号,但是业务很多时候需要用trade_no去计算,而trade_no的生成规则是业务自己控制的,所以这里就可以用查询切分键的方式进行设计,假设trade_no的生成规则如下:
固定前缀(8位)+时间戳(14位)+随机序号(8位)+外部订单的哈希值(4位)
外部订单的哈希值(4位)=out_trade_no的哈希值,这样,即使再SQL语句中没有使用切分键out_trade_no,照样能根据trade_no定位到对应的分表,即:
select * from trade_info where out_trade_no = xxx
和
select * from trade_info where trade_no =xxx
能达到同样的效果,这样给业务在设计分片的时候提供了非常大的灵活性,目前这种方案已被广泛用在交易、支付、营销等核心业务。StarDB在信通院性能评测时,性能比平均值提升 50% 也是借助查询切分键的设计方案实现的。
5. 大小商户方案
企业级用户会存在很多商户,而每个商户的运营能力、业务能力是不一样的,这样会导致每个商户的数据量差别很大,小商户可能一年的数据量是百万级,而大商户可能1天的数据量就达到百万级;小商户如果运营良好经过不断的推广运作之后,数据量可能会呈指数级增长,逐渐达到了大商户这样的数据增长量,此时小商户的数据表已经存不下这些商户数据了,同样,也有大商户因为经营不善,导致业务急剧流失,慢慢的,就变成了小商户规模,而这些大商户就不能再用一整套大商户数据表了,资源太浪费。针对这种场景,普通的根据日期或者商户号做分片已经无法满足业务需求。要满足数据尽量均匀,同时还需要考虑大小商户的动态切换过程,为此,StarDB设计了一套大小商户的分片解决方案,方案设计如下:
(1) 数据存储设计
StarDB从业务侧拿到商户的数据量统计,拿大商户的单表日增量平均值,计算大商户每天单表的数据量 = 1658486236 /366 = 4531383.15 ≈ 500w;DBA建议单表的数据量不超过500W,根据这些信息StarDB采用如下策略:对于大型商户,StarDB采用一天一个商户一个分表。
(2) 库利用率设计
为了提高数据库的利用率,让每天每个库都能发挥它的资源价值,StarDB对分表算法做了下调整:用商户序号+时间错开模值,大商户一年的366天数据分配到16个库(8个服务器),每个库平均分22个表,最后一个库分25表:
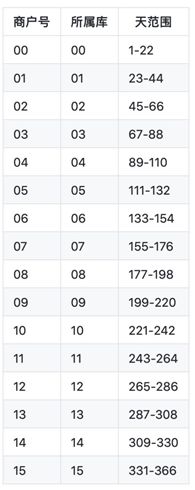
计算方式:商户序号 * 每个库步长(22) + 天序号 = 当前商户当前天存的分表,按这个算法,比如商户号0的,第一天的数据存放的是 0 * 22 + 1 = 1 (库1),商户号1的,1*22 +1 =23(库2),商户号2的 2 *22 + 1 =45 (库3)… 15 * 22 +1 =331(16号库) 依次类推,这样每天的数据每个库都能利用起来。
(3) 大小商户设计
StarDB统计了每个商户年数据增量,并且根据数据量设定三个商户级别,即大型商户,中型商户,小型商户,结果如下:
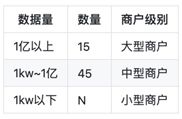
从数据量分析,其实没必要大商户都单独一套表,所以StarDB根据商户类型做如下处理:
小商户:商户号取模,存2000个分表
中型商户:2~4个商户公用一套表
大商户:一个商户一套表
根据上述信息,假如按4个中型商户一套表,一共需要 15 + 45 /4 ≈ 27,StarDB创建 30套大商户表以及2000个小商户分表,方便存放大小商户数据,以及转大商户的时候动态扩容。
(4) 路由方案设计
采用级联路由,用三级级联算法,第一级区分大小商户,第二级按年,第三级路由到具体的周,表后缀形式:table_aa_yyyy_xxx
其中:aa,标识大商户序号,此处多个中型商户指向同一个序号,yyyy为年,xxx为具体的一年的那个天的模值,xxx的计算按上述库利用率中描述的算法实现。
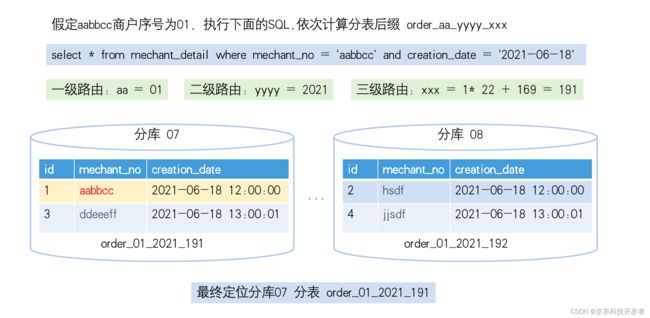
5.大小商户动态切换设计
要实现大小商户的动态切换,最重要的两点,一个是建表,第二个是导数据。
建表:
如果是大商户到小商户,那不用建表,按小商户路由就行
如果是小商户到大商户,一般不太可能一个小商户直接到大商户,而是先到一个中型商户,而多个小商户可以共用一个中型商户,所以上述设计中,预留了3套大商户的表,给小商户升级,按设计,4个小商户公用一套表,那可以服务12个小商户升级,不用建表。
导数据:
为降低复杂度,尽量不倒数,StarDB在算法里做了标识大小商户。当前设计第一个字段是商户号,StarDB把商户号和时间两个字段合起来计算是不是大小商户,因为这两个字段是必传的,大商户的map可以按如下定义:
序号:商户号>时间和商户号<时间;
规则定义:0:112226644451111#20190801>20200101<,1:11221112153221#
通过算法判断,如果后面带大于时间的,那么当时间大于这个值的,走大商户逻辑,否则走小商户逻辑,这样就不用迁移数据了,而这个切换过程,只需要修改商户定义配置,走一次应用发布即可。而且能查询出历史状态下的分表,比如某商户20210618以前是小商户,那么当碰到SQL语句包含跨临界区时,会将小商户的路由表和大商户当前的路由表都查出来。同样,如果商户号后面带小于时间的,那么当这个时间过后,路由走小商户逻辑,也不用迁移数据了。如此设计可以避免建表和导数据,大小商户可以动态切换。
大小商户方案自2018年落地后,到目前已稳定运行3年,每个实例的CPU、磁盘空间等资源利用率都非常平均,由于单表数据量不大,因此业务ddl也没有任何影响(MySQL单表上亿的DDL基本就是一场灾难)。
五个常用切分模板
平拆分配置,不用关心分片配置的详细过程,也能引导用户根据模板去设计他们的切分方案,下面介绍这五个模板:
第一个:常规哈希取模模板
按某个字段哈希取模,将数据打散在各个分表,常用于普通的数据分片策略,比如按pin分片,或者按订单号,流水号,这种方式的好处是简单,数据分布均匀。分片键需要选择合理,否则容易造成数据倾斜。
第二个:日期类分片模板
根据日期分片,常用于按日期计算的场景,或者定期归档的场景,支持年、年月、年月日、月日、日这几种常见日期格式;该模板还支持先按某个字段分库,再按日期再每个分库进行分表
第三个:先分库后分表模板
常用于主表和明细表,主表和明细表一般数据量不是一个等级,故分表数量也不相同,但是两者要保证事务,故可以先按某个字段分库,再按另一个字段分表。
第四个:一致性哈希模板
这个模板采用一致性哈希算法,专门为StarDB弹性设计,StarDB的弹性只需迁移小部分表,就能实现数据自动rehash,这部分将在《StarDB内核分解之弹性篇》进行讲解,这里不再展开。
第五个:完全自定义路由
根据上边的《数据分片设计原理》,StarDB预留了一个完全自定义路由的接口,业务只要实现两个固定的接口,就能自定义路由算法,管控端提供模拟执行页面,方便用户调试,整个算法支持热加载,能做到所见即所得。
StarDB能支持的分片算法已经很丰富了,但是有的业务的确有他特殊的场景,普通的算法方案无法满足,比如京东之前碰到过一个供应链金融的业务,切分键配了51个!不同类型的分表有不同的路由方式,每种切分规则都用到了三到四级路由,最开始StarDB采用配置的方式,实现了业务需求,但是当去维护的时候发现,这么多的配置,只有设计者能搞明白,为此StarDB把这个业务的路由算法用自定义算法实现了,这样只要维护这个算法类就能维护整个路由,极大降低了运维难度。
总结
StarDB经过在京东多年的沉淀,已经总结出相当丰富的实战经验,而这些实战案例都离不开StarDB灵活的分片实现以及用户丰富的应用场景,未来StarDB还会继续增加规则模板,一方面帮助研发屏蔽分布式数据库水平拆分的门槛要求,帮业务快速实现数据分片,另一方面也能引导业务去更好的发挥数据库资源的能力。