PyTorch:详解线性回归实战
线性回归
对于线性回归,相信大家都很熟悉了,各种机器学习的书第一个要讲的内容必定有线性回归,这里简单的回顾一下什么是简单的一元线性回归。即给出一系列的点,找一条直线,使得这条直线与这些点的距离之和最小。
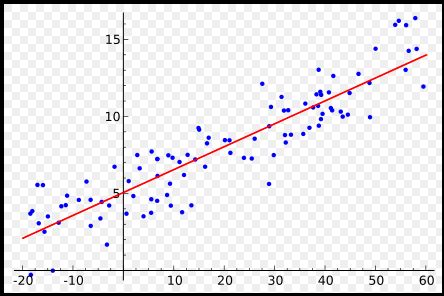
上面这张图就简单地描绘出了线性回归的基本原理,下面我们重点讲讲如何用pytorch写一个简单的线性回归。
这里简单的线性回归模型视为:y=kx+b,其中x是输入数据,k和b是需要学习的参数,y是网络的预测输出。那么学习的目的就是让网络预测输出尽可能接近真实标签y_real,所以损失函数可以使用MSE损失如下:
L=MSE(y,y_real)
优化的目的就是最小化L,从而学习到合适的w和b。
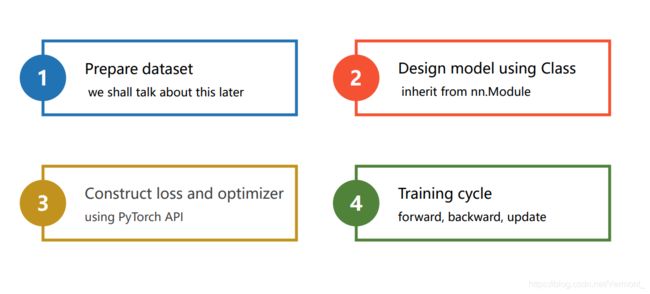
神经网络设计四大步骤:
- 准备数据集;
- 定义模型;
- 定义损失函数和优化器;
- 训练模型;
1. 定义数据
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])Tensor是pytorch里面的基本处理单元,torch.Tensor是一种包含单一数据类型元素的多维矩阵。
2. 定义模型(model)
还是继承pytorch提供的nn.Module()类。通过把nn.Linear()绑定到类实例属性,以及实现forward()方法实现前向传播:
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1) # input and output is 1 dimension
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()这里的nn.Linear表示的是 y=w*x b,里面的两个参数都是1,表示的是x是1维,y也是1维。当然这里是可以根据你想要的输入输出维度来更改的,之前使用的别的框架的同学应该很熟悉。
3. 定义损失函数和优化器
然后需要定义loss和optimizer,就是误差和优化函数
要定义一个优化器,这里使用SGD优化器。
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)这里使用的是最小二乘loss,之后我们做分类问题更多的使用的是cross entropy loss,交叉熵。优化函数使用的是随机梯度下降,注意需要将model的参数model.parameters()传进去让这个函数知道他要优化的参数是那些。
4. 训练
for epoch in range(100):
y_pred = model(x_data) #前向传播
loss = criterion(y_pred, y_data) #计算loss
print(epoch, loss)
optimizer.zero_grad()
loss.backward() #反向传播
optimizer.step() #更新参数
第一个循环表示每个epoch,接着开始前向传播,然后计算loss,然后反向传播,接着优化参数,特别注意的是在每次反向传播的时候需要将参数的梯度归零,即
optimzier.zero_grad()validation
训练完成之后我们就可以开始测试模型了
# Output weight and bias
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print("y_pred = ", y_test.data)loss的结果以及w、b的结果:

将epoch的迭代次数改成1000,得到更加小的损失,和更精确的w、b参数。

ok,在这篇文章中我们使用pytorch实现了简单的线性回归模型,掌握了pytorch的一些基本操作。
附完整代码:
# -*- coding: utf-8 -*-
# @Time : 2020/8/26 20:36
# @Author : jhys
# @FileName: linearReg.py
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = model(x_data) #前向传播
loss = criterion(y_pred, y_data) #计算loss
print(epoch, loss)
optimizer.zero_grad()
loss.backward() #反向传播
optimizer.step() #更新参数
# Output weight and bias
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print("y_pred = ", y_test.data)