MyBatis入门概述,内置连接池源码分析
MyBatis是什么:
MyBatis是基于Java的持久层框架(持久:将程序数据在持久状态和瞬时状态之间转化的过程),底层封装的JDBC,帮助Java开发人员更好的操作数据库。(只关注SQL语句,而不需要关注JDBC的相关操作)
MyBatis通过XML配置文件,实现了SQL与代码的分离。
MyBatis开发方式:
MyBatis使用XML配置文件或注解的方式(实际开发中,使用XML配置文件的情况更多),将Statement对象(执行SQL需要使用的对象)进行配置,并可以使用SQL动态参数映射,执行SQL语句,最后将结果以Java对象返回。
MyBati采用配置文件的方式,需要配置两种配置文件:
一种是主配置文件,文件一般命名为SqlMapConfig.xml,只有一个。另一种是映射配置文件,文件名格式为XxxMapper.xml,每个实体类(表结构)对应一个映射文件,存在多个映射文件。
使用Maven工程构建,pom文件需要如下坐标依赖:
<dependencies>
<!--mybatis核心包-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.5</version>
</dependency>
<!--mysql驱动包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
MyBatis框架中 ,配置文件使用DTD约束(Document Type Definition),来规定MyBatis配置文件的定义规范。
主配置文件部分内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--主配置文件的标签是有顺序的-->
<!--properties>settings>
typeAliases>typeHandlers>
objectFactory>objectWrapperFactory>
reflectorFactory>plugins>
environments>databaseIdProvider>mappers
-->
<configuration>
<!--定义属性文件信息,定义后,其他标签内需要使用时,可以通过${对应name}来获取
项目开发中,一般会直接配置一个属性文件,然后加载, 在properties中加属性resource="属性文件路径"
-->
<properties>
<property name="jdbc.driver" value="com.mysql.jdbc.Driver"/>
</properties>
<!--<properties resource="db.properties"></properties>-->
<settings>
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
<!-- 开启延迟加载 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 将积极加载改为消极加载及按需加载 -->
<setting name="aggressiveLazyLoading" value="false"/>
<!--开启驼峰命名自动映射-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--配置类别名,如同java.lang.String,框架内进行优化,可以简写为string,我们对POJO对象类型也可以进行配置简写-->
<typeAliases>
<!--type为配置类的全路径,alias为简写别名(不区分大小写)-->
<typeAlias type="cn.cx.domain.User" alias="User"></typeAlias>
<!--该包下的所有类,都可以使用别名(类名首字母小写)访问-->
<package name="cn.cx.domain"/>
</typeAliases>
<!--配置环境,可以有多个环境,default表示用该标签下的那个具体环境environment-->
<environments default="mysql">
<!--环境名称-->
<environment id="mysql">
<!--事务管理类型-->
<transactionManager type="JDBC"></transactionManager>
<!--是否使用连接池,POOLED使用内置连接池,UNPOOLED不使用内置连接池(底层是创建连接方式),JNDI,用JNDI方式使用连接池-->
<dataSource type="POOLED">
<!--使用驱动类-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<!--使用数据库-->
<property name="url" value="jdbc:mysql:///mybatis_db"/>
<!--用户名-->
<property name="username" value="root"/>
<!--密码-->
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--加载注册映射配置文件-->
<mappers>
<mapper resource="mapper/UserMapper.xml"></mapper>
<mapper resource="mapper/AccountMapper.xml"></mapper>
<mapper resource="mapper/RoleMapper.xml"></mapper>
<!--引入注解所在类,如果使用class方式,则不能与resource方式起冲突-->
<!--<mapper class="cn.cx.mapper.RoleMapper"/>-->
</mappers>
</configuration>
映射文件部分内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--映射配置文件,namespace是名称空间,表示映射的类,应使用完全限定类名-->
<mapper namespace="cn.cx.mapper.UserMapper">
<!--提取公共的SQL-->
<sql id="findAllSql">
select * from user
</sql>
<!--表示该类使用二级缓存-->
<cache></cache>
<!--id是方法名,resultType是方法返回类型(集合中则表示泛型类型)-->
<select id="findAll" resultType="cn.cx.domain.User" >
select * from user;
</select>
<!--parameterType表示方法参数类型,可以写全路径:java.lang.Integer,但框架给我们进行了优化,可以直接写类型int,integer,Integer
如果是基本数据类型,要在类型前写_,如_int,_integer-->
<select id="findUserById" resultType="cn.cx.domain.User" parameterType="int" useCache="true">
<!--mybatis中,不能使用?做占位符,取而代之用#{}或者${}做占位符,可以直接取到实体类中的属性-->
select * from user where id = #{id}
</select>
<!--#{OGNL表达式},对象图导航语言,表达式语言。语法和EL表达式类似,EL只能在JSP页面使用,而OGNL表达式既可以在页面中使用,也可以在配置文件中使用-->
<insert id="insert" parameterType="cn.cx.domain.User">
<!--查询主键并封装到实体类的对应属性,keyProperty表示封装数据的属性,order表示操作顺序,resultType表示返回值类型-->
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Integer">
select last_insert_id()
</selectKey>
<!--前者是表中字段,后者是实体类属性-->
insert into user(username, birthday, sex, address) values(#{username}, #{birthday}, #{sex}, #{address})
</insert>
<update id="update" parameterType="cn.cx.domain.User">
update user set username = #{username}, birthday = #{birthday}, sex = #{sex}, address = #{address} where id = #{id}
</update>
<!--
#{}和${}的区别:
如果parameterType是引用数据类型(User等实体类),两者无区别
如果parameterType是普通数据类型(int,Integer,String,double):#{}内表示形参,可以随便写;而${}内必须写value
-->
<delete id="delete" parameterType="java.lang.Integer">
delete from user where id = ${value}
</delete>
<!--模糊查询-->
<select id="findUserByUsername" parameterType="java.lang.String" resultType="User">
<!--第一种方式:如果没有拼接%,当我们查询时,要自己在代码中写。此方式可以防止SQL注入问题,相当于JDBC的预编译-->
select * from user where username like #{username}
<!--第二种方式,拼接的情况:select * from user where username like '%${value}%' 此方式不能防止SQL注入问题 -->
</select>
<!--聚合函数查询数据总条数-->
<select id="findCount" resultType="java.lang.Integer">
select count(*) from user
</select>
<!--POJO包装对象查询-->
<select id="findQueryVo" resultType="cn.cx.domain.User" parameterType="cn.cx.domain.QueryVo">
select * from user where username = #{user.username}
</select>
<!--
if拼接查询
使用if标签,可以进行值的判断
test=-"OGNL表达式",如果为true,拼接if标签内的sql,反之不执行,没有if..else的说法
此外还有choose和when的用法,相当于java中的switch和case,作用也相同,只会选择其中一个条件拼接。
-->
<select id="findByIf" resultType="cn.cx.domain.User" parameterType="cn.cx.domain.User">
<!--此处1=1是为了拼接时不出现语法错误,因为不能直接在where关键词后直接拼and
如果不添加1=1,可以使用<where>标签将if标签包起来,使用该标签可以代替sql语句中的where关键词
-->
select *from user where 1=1
<!--如果username不为null或者空串,则进行拼接-->
<if test="username != null and username != ''">
and username like #{username}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
</select>
<!--update时,经常使用set标签,解决拼接,的问题-->
<update id="updateUser" parameterType="map">
update user
<set>
<if test="username != null">
username = #{username},
</if>
<if test="password != null">
username = #{password},
</if>
</set>
</update>
<!--
foreach查询
实现:select * from user where id = ? or id = ? or id = ?
JavaBean实体类中存在一个id集合,需要从该集合中取出值,给占位符,此时可以用foreach语句
collection 表示遍历的集合
open sql语句开始字符串
close sql语句结束字符串,如果没有字符可以省略
separator ?与?之间的公有切割字符
item 遍历后变量
index 索引下标,可以省略
<select id="findByForeach" resultType="cn.cx.domain.User" parameterType="cn.cx.domain.User">
select * from user
<where>
<foreach collection="ids" open="id = " separator="or id = " item="i">
#{i}
</foreach>
</where>
</select>-->
<!--
foreach查询
实现:select * from user where id in (?,?,?)
-->
<select id="findByForeach" resultType="cn.cx.domain.User" parameterType="cn.cx.domain.User">
<!--使用公共sql语句-->
<include refid="findAllSql"/>
<where>
<foreach collection="ids" open="id in (" close=")" separator="," item="i">
#{i}
</foreach>
</where>
</select>
<!--一对多查询(立即加载)-->
<select id="findTables" resultMap="userMap">
select u.*,a.id aid, a.uid, a.money from account a,user u where a.uid = u.id
</select>
<!--当数据库表中字段和JavaBean实体类属性名不相同时,无法进行自动封装,这时需要我们手动配置resultMap(结果集映射)
当需要使用时,引用其id值,type表示对应的类
只需要配置不相同的字段与属性即可,相同的不需要配置。
-->
<resultMap id="userMap" type="cn.cx.domain.User">
<!--property是JavaBean中属性名、column是数据库表字段名-->
<result property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!--collection,一对多数据封装使用的标签。property:属性名、ofType:集合内泛型类型-->
<!--若复杂属性为对象,使用association标签;若复杂属性为集合,使用collection标签-->
<!--一对多重点在对多,多对一重点在对一-->
<collection property="accounts" ofType="cn.cx.domain.Account">
<!--如果不进行区分,column取的还是用户的主键id,正确情况下应该取账户主键id
所以为了避免出现这种错误,在编写sql语句时,可以起别名
-->
<result property="id" column="aid"/>
<result property="uid" column="uid"/>
<result property="money" column="money"/>
</collection>
</resultMap>
<!--一对多查询(延迟加载)
例子:
立即加载:当前查询用户的时候,默认也把该用户所拥有的帐户信息查询出来了。
延迟加载:当前查询用户的时候,没有把该用户所拥有的帐户信息查询出来,而是使用帐户数据的时候,再去查询账户的数据。
场景:
一般情况下,一对多推荐使用延迟加载;多对一使用立即加载(并不会浪费内存空间)
-->
<select id="findUserLazy" resultMap="userMapLazy">
select * from user
</select>
<select id="findUserByUId" resultType="cn.cx.domain.Account" parameterType="int">
select a.id aid, a.uid, a.money from acccount where uid = #{uid}
</select>
<resultMap id="userMapLazy" type="cn.cx.domain.User">
<result property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!--
column:延迟加载语句select需要的参数
select:延迟加载语句,但是该语句要封装到另一个select中,而不是直接写在字符串中
fetchType:lazy表示延迟加载
-->
<collection property="accounts" ofType="cn.cx.domain.Account" column="id" select="cn.cx.mapper.AccountMapper.findByUId" fetchType="lazy">
<result property="id" column="aid"/>
<result property="uid" column="uid"/>
<result property="money" column="money"/>
</collection>
</resultMap>
</mapper>
简单的MyBatis程序:
public class UserMapperTest {
/**
* 测试查询所有数据的方法,User对应数据库表结构的实体类,UserMapper是其对应的接口类
* */
@org.junit.Test
public void testFindAll() throws Exception {
//加载主配置文件,获取字节输入流对象
InputStream inputStream = inputStream = Resources.getResourceAsStream("SqlMapConfig.xml");
//通过流对象,构建SqlSessionFactory工程对象
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//使用SqlSessionFactory工厂对象创建SqlSession对象,参数设置为true,表示开启事务的自动提交(不建议使用)
SqlSession sqlSession = sessionFactory.openSession();
//通过SqlSession创建UserMapper接口的代理对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//获取结果,从代理对象调用方法才去获取连接池中对象,
List<User> userList = mapper.findAll();
//遍历数据
for (User user : userList) {
System.out.println(user);
}
//释放资源,归还连接对象到连接池中
sqlSession.close();
//关闭流
inputStream.close();
}
}
MyBatis执行流程,内置连接池源码分析:
首先按流程走,到使用连接池的时候解释源码。
第9行很简单,根据主配置文件,获取流对象。
//加载主配置文件,获取字节输入流对象
InputStream inputStream = inputStream = Resources.getResourceAsStream("SqlMapConfig.xml");
当进行到第12行,我们可以看到debug显示的变量情况,变量名并不陌生,全部都是主配置文件的标签名。.build(inputStream)后,解析主配置文件的流对象,配置文件中的数据就被封装到SqlSessionFactory中的configuration中去了。
//通过流对象,构建SqlSessionFactory工程对象
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(inputStream);

到第15行,SqlSessionFactory对象继续将configuration对象传给SqlSession对象。
第18行,通过getMapper方法,获得了一个动态代理对象。
//通过SqlSession创建UserMapper接口的代理对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);

连接池作为存储连接的容器,会提前创建一些连接存到其中,使用时获取,使用后归还。提升程序性能。
直到第21行通过代理对象执行方法,才开始从连接池中去获取连接对象,源码分析如下:
MyBatis内置连接池,在源码内的体现是两个ArrayList集合:
![]()
其中idleConnections代表空闲连接池,activeConnections代表活动连接池,我们所使用的连接对象,无非都是从这两个集合里来拿。
当获取连接时,会调用PooledDataSource的popConnection方法来获取,关键源码解释:

获取到连接,执行SQL语句后,我们还需要释放资源,归还连接操作就是在这里执行的,会调用PooledDataSource的pushConnection方法来归还,关键源码解释:
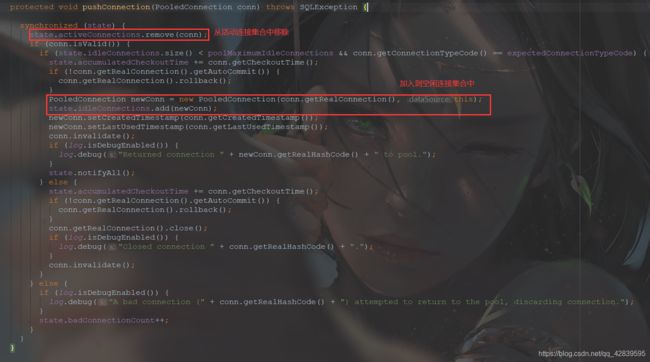
源码分析文字描述:
当需要获取连接时,调用底层PoleDataSource的popConnetion(),先判断空闲连接池集合idleConnection是否为null。
如果不为null,说明存在连接,从空闲连接池中移除该连接对象,赋值给conn。
如果为nul,先判断活动连接池集合activeConnection内连接对象个数是否小于最大连接数。
如果小于,则创建一个新的连接对象,赋值给conn。
如果大于或等于最大连接数,就判断下标为0的连接对象是否超时。
如果超时,移除该对象,创建一个新的连接对象,赋值给conn。
如果没有超时,则继续等待,直到活动连接池归还连接对象到空闲连接池。(当conn被赋值,跳出while后,会将conn加入到活动连接集合中)
当SqlSession调用close()释放资源时,会调用底层PoleDataSource的pushConnetion()进行连接对象归还。从activeConnection中移除该连接对象,把该对象加入到idleConnection中。
MyBatis三大对象生命周期:
使用MyBatis,需要创建并使用三个对象:SqlSessionFactoryBuilder、SqlSessionFactory、SqlSession。
SqlSessionFactoryBuilder:其作用就是调用内部build(),获得SqlSessionFactory对象,一旦获得,就不再需要此对象了,因此 SqlSessionFactoryBuilder适合作为局部变量使用。
SqlSessionFactory:其作用是获得SqlSession对象,可以想象成一个连接池对象,因此一旦被创建就应该在运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例,可使用单例模式做到。
SqlSession:其对象作用是调用SQL方法,可以想象成连接池中的连接对象,SqlSession线程不安全,所以无法共享,最佳作用域是方法或请求作用域,用完后就要关闭资源。
MyBatis立即加载和延迟加载:
拿用户和账户两张表举例,当前查询用户的时候,默认也把该用户所拥有的帐户信息查询出来,这就是立即加载;当前查询用户的时候,没有把该用户所拥有的帐户信息查询出来,而是使用帐户数据的时候,再去查询账户的数据,这就是延迟加载。
两种加载并没有优劣之分,但要注意使用场景和业务需求。一般情况下,一对多推荐使用延迟加载;多对一使用立即加载(并不会浪费内存空间)
延迟加载需要在主配置文件进行配置:
<settings>
<!-- 开启延迟加载 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 将积极加载改为消极加载及按需加载 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
对应映射文件的相关配置:
<select id="findUserLazy" resultMap="userMapLazy">
select * from user
</select>
<resultMap id="userMapLazy" type="cn.cx.domain.User">
<result property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!--
column:延迟加载语句select需要的参数
select:延迟加载语句,但是该语句要封装到另一个select中,而不是直接写在字符串中
fetchType:lazy表示延迟加载
-->
<collection property="accounts" ofType="cn.cx.domain.Account" column="id" select="cn.cx.mapper.AccountMapper.findByUId" fetchType="lazy">
<result property="id" column="aid"/>
<result property="uid" column="uid"/>
<result property="money" column="money"/>
</collection>
</resultMap>
MyBatis缓存:
在内存中临时存储数据,速度快,可以减少数据库的访问次数。
MyBatis内部提供缓存供自己使用,与Redis这种业务级别缓存不同,无法操作。
MyBatis缓存分为一级缓存和二级缓存,其中一级缓存(SqlSeesion级别,默认存在)生命周期较短,和对象生命周期一致;二级缓存(namespace级别,需要手动开启),是对一级缓存的增强,生命周期延长,与服务器一致。所有的数据,一开始都在一级缓存中,当一级缓存被清空时,会将其放到二级缓存中。
一级缓存底层是一个Map集合,key是封装SQL语句的对象,value是查询出的对象,commit和colse等方法会清空缓存。
查询顺序为:先查询二级缓存,再查询一级缓存,最后再查数据库。
需要注意的是,缓存只在select语句中有效,且增删改操作都会清空缓存。
使用二级缓存需要在主配置文件进行配置:
<settings>
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
在对应映射配置文件加入cache标签:
<!--表示该类使用二级缓存-->
<cache></cache>
在对应select标签使用useCache:
<select id="findUserById" resultType="cn.cx.domain.User" parameterType="int" useCache="true">
select * from user where id = #{id}
</select>