一切为了多学习 node各方面的面试巩固知识点
node的核心模块
-
fs模块
fs模块是用来操作文件的模块, 提供了一系列的方法和属性,用来满足用户对文件的操作需求
fs.readFile(path,[option],callback);参数1:Path:必选参数,字符串,表示文件的路径。
参数2:option:可选参数,表示以什么编码格式来读取文件。
参数3:callback:必选参数,文件读取完成后,通过回调函数拿到读取的结果。
// 导入fs模块
const fs=require('fs');
// 调用 fs.readFile()读取文件的内容
fs.readFile('./成绩.txt','utf-8',function(err,dataStr){
// 是否读取成功
if(err){
return console.log('读取文件失败'+err.message);
}
// 获取成功
// console.log('读取成功'+dataStr);
// 1.把成绩的数据按空格进行分割
const arrOld=dataStr.split(' ')
// console.log(arrOld);
// 2.循环分割后的数组,对每一项数据,进行字符串的替换操作
const arrNew=[];
arrOld.forEach(item=>{
arrNew.push(item.replace('=',':'))
})
// console.log(arrNew);
// 3.把新数组中的每一项进行合并,得到一个新的字符串
const newStr=arrNew.join('\r\n');
// console.log(newStr);
// 调用fs.writeFile()方法,把处理完毕的成绩,写入新文件中
fs.writeFile('./成绩ok.txt',newStr,function(err){
if(err){
return console.log('写入失败'+err.message);
}
console.log('写入成功');
});
})
2. path模块
path模块是用来处理路径的模块,提供了一系列方法和属性,用来满足用户对路径的处理需求。
1.path.join()实现路径拼接
2.path.basename()获取对应文件的名称加后缀名
3.path.dirname()获取该文件夹的路径名
4.path.parse()将路径解析成对象
5.path.format()将对象整合成路径字符串
6.path.isAbsolute()是否是一个绝对路径
3. http模块
用来创建web服务器的模块,通过HTTP模块提供的http.createServe()方法,就可以把一台普通电脑变为一台web服务器。
// 导入http模块
const http=require('http');
// 创建web服务器实例
const server=http.createServer();
// 为服务器实例绑定request事件,监听客户端的请求
server.on('request',(req,res)=>{
console.log('someone visit our web server');
})
// 启动服务器
server.listen(8080,()=>{
console.log('server running at http://127.0.0.1:8080');
})
4.url模块
URL模块可以将获得的URL进行解析
const {URL}=require('url');//解构赋值,引入URL,并且URL是构造函数
let url='http://192.168.0.3:3000/soul/users/hb/sjz/xh.json?sex=1&age=[18,26]';
let myurl=new URL(url);
console.log(myurl);
es6语法
-
在es6中我们通常用let来定义变量和const来定义常量 ,它们都是块级作用域 ,在同一个代码块中不允许重复声明
var
在JavaScript中之前定义变量,我们用 var 关键字;它对比let有如下主要缺点:
存在变量提升问题,降低 js 代码的可阅读性(变量会提升,变量值不会提升,所以输出a=undefined)没有块级作用域,容易造成变量污染(var 定义的变量 i 在大括号外依然可以输出结果10)
const 主要特性:
不存在变量提升问题,只有定义之后才能使用
此变量const 定义的常量,无法被重新赋值
当定义常量的时候,必须定义且初始化,否则报语法错误
const 定义的常量,也有 块级作用域
-
模版字符串
用一对反引号(`模板字符串`)标识 ,它可以当普通字符串使用('普通字符串'),也可以用来定义多行字符串 ,在模板字符串中可以嵌入变量 ,js表达式或函数等 ,变量,js表达式或函数需要写在${}中
-
变量的解构赋值
Es6允许按照一定的模式 ,从数组和对象中提取值 ,对变量进行赋值 ,这被称作解构赋值 ,意思就是把 某个对象中的属性,当作变量,给解放出来,这样,今后就能够当作变量直接使用了;
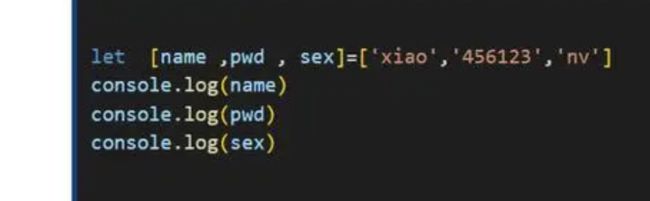
数组
数组中的会自动解析到对应接收该值的变量中 ,数组的解构赋值要一一对应 ,否则就是undefined
对象
对象的与数组不同的是 ,对象不需要一一对应 ,但是变量必须和属性同名(不同名要把属性名赋值给变量 username:name) ,才能取到正确的值

4.箭头函数
在es6中 ,提供了函数的简洁写法 ,我们称之为箭头函数 ,箭头函数,本质上就是一个匿名函数 ,箭头函数的特性: 箭头函数内部的 this, 永远和 箭头函数外部的 this 保持一致 ,:函数的参数放在=>前面的括号中,函数体跟在=>后的花括号中
箭头函数this指向
-
箭头函数没有this,this是父级的
-
定义时候绑定,就是this是继承自父执行上下文!!中的this
-
ES5中,this指调用者,ES6中,this指定义时候绑定
简写方法有三种变体:
变体1:如果箭头函数,左侧的形参列表中,只有一个参数,则,左侧小括号可以省略;
变体2:如果右侧函数体中,只有一行代码,则,右侧的{ }可以省略;
变体3:如果箭头函数左侧 只有一个 形参,而且右侧只有一行代码,则 两边的()和{}都可以省略
ES6 新增字符串方法
//字符串新增方法:
方法 返回值 作用
includes('str') boolean 判断字符串中包含子串
endWith('str') boolean 判断字符串以"str"结尾
startWith('str') boolean 判断字符串以"str"开头
repeat(n) 重复拼接自身 重复n次输出字符串 repeat + repeat
//不全方法: 补全字符串长度
padStart(length, s); 字符串开头补全
endStart(length, s); 字符串末尾补全5.ES6 Promise 解决回调地狱
js如何实现数组元素倒序
arr.reverse()在 NodeJS 中延迟执行函数方法代码
使用异步/等待
你可以使用异步/等待着与 Promise, 推迟执行,而没有回调。
function delay(time) {
return new Promise(resolve => setTimeout(resolve, time));
}
run();
async function run() {
await delay(1000);
console.log('This printed after about 1 second');
}使用sleep命令
mysql 查询重复的数据
使用group by 分组
、查关键字:姓名,以姓名进行分组,看潜在条件:重复,也就是count(name)>1,使用having过滤条件,不可使用where(where子句无法与聚合函数count()一起使用)
select employee_name,count(*) as c from employee group by employee_name having c>1;
mysql建表注意什么
-
字段类型
如果字符串长度固定,或者差别不大,可以选择char类型。如果字符串长度差别较大,可以选择varchar类型。
是否字段,可以选择bit类型。
枚举字段,可以选择tinyint类型。
主键字段,可以选择bigint类型。
金额字段,可以选择decimal类型。
时间字段,可以选择timestamp或datetime类型。
-
字段长度
bigint/int 指定没有意义,会自动填充0
-
字段个数
一般不超过20个
redis
数据类型
string list set sorted set hash
使用场景
-
通过list取最新N条数据
-
token需要设置过期时间的场景
-
发布订阅消息
-
定时器 计数器
功能
-
定时更新数据
-
持久化
-
复制高可用
为什么发会生缓存雪崩?
什么情况下出现缓存雪崩呢?总结起来有以下两个方面的原因:
大量Redis缓存数据同时过期,导致所有的发送到Redis请求都无法命中数据,只能到数据库中进行查询。
Redis服务器宕机,所有请求都无法经Redis来处理,只能转向数据库查询数据。
如何避免缓存雪崩?
针对导致缓存雪崩的原因,有不同的解决方法:
针对大量缓存随机过期时间,解决方法就是在原始过期时间的基础上,再加一个随机过期时间,比如1到5分钟之间的随机过期时间,这样可以避免大量的缓存数据在同一时间过期。
而针对Redis解决宕机的导致的缓存雪崩,可以提前搭建好Redis的主从服务器进行数据同步,并配置哨兵机制,这样在Redis服务器因为宕机而无法提供服务时,可以由哨兵将Redis从服务器设置为主服务器,继续提供服务。
1. 什么是缓存击穿
缓存击穿是指缓存中没有数据但数据库中有数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,导致短时间内数据库压力剧增,导致崩溃。
缓存击穿的解决方案:
1.设置热点数据永远不过期(热点数据key快要过期时,后台异步线程重新设置缓存)
2.设置互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
缓存穿透
1. 什么是缓存穿透
缓存穿透是指要查找的数据既不在缓存当中,也不在数据库中,因为不在缓存中,所以请求一定会到达数据库,Redis缓存形同虚设,
2. 为什么会发生缓存穿透
什么条件下会发生缓存穿透呢?主要有以下三种情况:
-
用户恶意攻击请求
-
误操作把Redis和数据库里的数据删除了
-
用户还未产生内容时,比如用户的文章列表,用户还未写文章,所以缓存和数据库都没有数据
3. 如何避免缓存穿透?
a. 缓存空值或缺省值
当在Redis缓存中查询不到数据时,再从数据库查询,如果同样没有数据,就直接缓存一个空间或缺省值,这样可以避免下次再去查询数据库;不过为了防止之后已经数据库已经相应数据库,再返回空值问题,应该为缓存设置过期时间,或者在产生数据时直接清除对应的缓存空值。
b. 布隆过滤器
虽然缓存空值可以解决缓存穿透问题,但仍然需要查询一次数据库才能确定是否有数据,如果有用户恶意攻击,高并发地使用系统不存在的数据id进行查询,所有的查询都要经过数据库,这样仍然会给数据库带来很大的压力。
所以,有没有不用查询数据库就能确定数据是否存在的办法呢?有的,用布隆过滤器。
布隆过滤器主要是两个部分:bit数组+N个哈希函数,其原理为:
使用N个哈希函数对所要标记的数据进行哈希值计算。
将计算到的哈希值对bit数组的长度取模,这样可以得到每个哈希值在bit数组的位置。
把bit数组中对应的位置标记为1。
| 问题 |
原因 |
解决方法 |
| 缓存雪崩 |
大量数据过期或Redis服务器宕机 |
1. 随机过期时间 2. 主从+哨兵的集群 |
| 缓存击穿 |
热点数据过期 |
1. 不设置过期时间 2. 加互斥锁 3. 冗余逻辑过期时间 |
| 缓存穿透 |
请求数据库和Redis都没有的数据 |
1. 缓存空值或缺省值 2. 布隆过滤器 |
在Node.js中,我们可以通过两种方式来读取文件:
-
使用fs.readFile()一次性将文件内容全部读取出来,考虑到可能将来会操作几G大的文件,所以放弃了这种方式;
-
使用fs.createReadStream()创建一个读文件流,这种方式可不受限于文件的大小;
Linux 有哪些系统日志文件?
-
比较重要的是 /var/log/messages 日志文件。
-
创建文件 touch
-
Linux面试题(总结最全面的面试题)-CSDN博客
webSocket
能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。它是一种在单个 TCP 连接上进行全双工通讯的协议。
WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,然后,浏览器和服务器之间就形成了一条快速通道,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
特点:
服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话。
建立在 TCP 协议之上,服务器端的实现比较容易。
与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
数据格式比较轻量,性能开销小,通信高效。
可以发送文本,也可以发送二进制数据。
没有同源限制,客户端可以与任意服务器通信。
协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。websocket 详解,与node.js完成即时通讯案例_node.js实现websocket的即时通讯详解-CSDN博客
tcp http
TCP、HTTP详解_tcp和http-CSDN博客
mongodb数据库
特点
-
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
-
Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
-
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
-
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
-
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
插入文档
insert
3.2 版本之后新增了 db.collection.insertOne() 和 db.collection.insertMany()。
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
MongoDB remove() 函数是用来移除集合中的数据。
MongoDB 数据更新可以使用 update() 函数。在执行 remove() 函数前先执行 find() 命令来判断执行的条件是否正确,这是一个比较好的习惯。
remove() 方法已经过时了,现在官方推荐使用 deleteOne() 和 deleteMany() 方法。
MongoDB 查询文档使用 find() 方法。
pretty() 方法以格式化的方式来显示所有文档。
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
排序
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
索引
MongoDB使用 createIndex() 方法来创建索引。
聚合
MongoDB中聚合的方法使用aggregate()。
RabbitMQ 是一个消息中间件:它接收消息并且转发,就类似于一个快递站,卖家把快递通过快递站,送到我们的手上,MQ也是这样,接收并存储消息,再转发。
就是在访问量剧增的情况下,但是应用仍然不能停,比如“双十一”下单的人多,但是淘宝这个应用仍然要运行,所以就可以使用消息中间件采用队列的形式减少突然访问的压力
为什么要用mq
-
流量峰值
-
应用解藕
-
异步处理
MQ特点
1、先进先出
不能先进先出,都不能说是队列了。消息队列的顺序在入队的时候就基本已经确定了,一般是不需人工干预的。而且,最重要的是,数据是只有一条数据在使用中。 这也是MQ在诸多场景被使用的原因。
2、发布订阅
发布订阅是一种很高效的处理方式,如果不发生阻塞,基本可以当做是同步操作。这种处理方式能非常有效的提升服务器利用率,这样的应用场景非常广泛。
3、持久化
持久化确保MQ的使用不只是一个部分场景的辅助工具,而是让MQ能像数据库一样存储核心的数据。
4、分布式
在现在大流量、大数据的使用场景下,只支持单体应用的服务器软件基本是无法使用的,支持分布式的部署,才能被广泛使用。而且,MQ的定位就是一个高性能的中间件。
以下场景比较适合使用Kafka。如果有大量的事件(10万以上/秒)、你需要以分区的,顺序的,至少传递成功一次到混杂了在线和打包消费的消费者、希望能重读消息、你能接受目前是有限的节点级别高可用就可以考虑kafka。
b) 以下场景比较适合使用RabbitMQ。如果是较少的事件(2万以上/秒)并且需要通过复杂的路由逻辑去找到消费者、你希望消息传递是可靠的、并不关心消息传递的顺序、而且需要现在就支持集群-节点级别的高可用就可以考虑rabbitmq。
nest
是一个用于构建高效、可扩展的 Node.js 服务器端应用程序的开发框架。它利用 JavaScript 的渐进增强的能力,使用并完全支持 TypeScript (仍然允许开发者使用纯 JavaScript 进行开发),并结合了 OOP (面向对象编程)、FP (函数式编程)和 FRP (函数响应式编程)。
NestJS和Egg.js的区别以及对比
1、Egg.js是和Nest.js 都是为企业级框架和应用而生。
2、 Egg.js和Nest.js都是非常优秀的Nodejs框架。Egg.js基于Koa,Nest.js默认基于Express,nest也可以基于其他框架
3、 Egg.js文档相比Nestjs优秀很多
4、 Express、Koa 是 Node.js 社区广泛使用的框架,简单且扩展性强,非常适合做个人项目。但框架本身缺少约定,标准的 MVC 模型会有各种千奇百怪的写法。Egg 和Nestjs都是按照约定进行开发的。但是Egg相比Nestjs约定更标准。
5、 面向对象方面Nestjs优于Egg.js,Nestjs基于TypeScript, 如果你会angular或者java学习Nestjs非常容易。
Egg.js的特性:
提供基于 Egg 定制上层框架的能力
高度可扩展的插件机制
内置多进程 egg中的master、worker和agent - 知乎
Node.js官方提供的解决方案是Cluster模块,用户可以通过集群化模块很方便地创建子进程,那Cluster是什么那?
在服务器上同时启动多个进程。
每一个进程里跑的是同一份源代码(类似把以前的一个进程的工作分给多个进程来做)。
这些进程可以同时监听一个端口。
负责启动其他进程的叫做Master进程,不做具体的工作,只负责启动其他进程。
其他被启动的进程叫Worker进程,它们接收请求,对外提供服务。
Worker进程的数量一般根据服务器的CPU核数来定,以充分利用多核资源
管理基于 Koa 开发,
性能优异框架稳定,
测试覆盖率高
渐进式开发(抽成独立插件 沉淀到框架,代码的共建,复用和下沉)
-
一般来说,当应用中有可能会复用到的代码时,直接放到 lib/plugin 目录去,如例子中的 egg-ua。
-
当该插件功能稳定后,即可独立出来作为一个 node module 。
-
如此以往,应用中相对复用性较强的代码都会逐渐独立为单独的插件。
-
当你的应用逐渐进化到针对某类业务场景的解决方案时,将其抽象为独立的 framework 进行发布。
-
当在新项目中抽象出的插件,下沉集成到框架后,其他项目只需要简单的重新 npm install 下就可以使用上,对整个团队的效率有极大的提升。
Eggjs教程:Egg.js视频教程_Eggjs仿小米商城企业级Nodejs项目实战视频教程(大地)(已更新131讲)_IT营
Nestjs的特性:
依赖注入容器
模块化封装
可测试性
内置支持 TypeScript
可基于Express或者fastify
Nestjs教程:Nest教程_Nestjs仿小米商城企业级Nodejs RBAC 微服务项目实战视频教程+Docker Swarm K8s云原生分布式部署(大地)-更新于2023年2月_IT营
Nginx
1.正向代理(代理客户端)
用户知道目标服务器地址,由于网络限制等原因,无法直接访问,这时候需要先连接代理服务器 ,然后通过代理服务器访问目标服务器。
2.反向代理 (代理服务器端)
客户端访问一个ip,自动选取空闲服务器,ip不变,负载均衡,各个服务器权重都为1,请求依次分配。
javascript应用在前端,全局对象是windows,考虑兼容性。
nodejs可以让javascript运行在后端,node是global(全局的),无需考虑兼容性,解释性语言。弱类型。
nodejs 开发效率高,前后端工具包可通用,适合处理密集i/o任务,通过事件循环机制,多个并行的任务,不同任务分配给不同的线程,处理速度非常快,有很高的实时性。
多线程:nodejs使用cluster模块创建子进程,
cluster.setupMaster()创建子进程。
当前进程是否为主进程:cluster.ismaster()
一旦work进程挂了,主进程无法知道。
主进程部署一个online 事件和exit事件的监听函数()重启一个work进程 cluster.fork()
TCP/IP
3次握手
4次挥手
websocket 请求 ---应答 主动下发消息给客户端,实时双向通信的能力,可以在浏览器使用,(经纬度实时上传,站内信,在线聊天 ,)socket.emit()发送,socket.on()监听
redis的消息发布订阅
广播消息,客户端--->发送消息值publish到chat频道上,监听chat频道,收到消息,通过socket传到app端
jenkins开源的、可扩展的持续集成、交付、部署(软件/代码的编译、打包、部署)的基于web界面的平台。 自动化部署,它可以在代码上传仓库(如github,gitee,gitlab)后,在jenkins(一个网站界面)中通过获取代码仓库中最新代码,进行自动化部署,而省去手动打包、上传服务器、部署这一系列步骤,非常方便。
功能:打包发布;
是流程化工具
ci 持续集成 开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。
cd 持续交付 将集成后的代码部署到更贴近真实运行环境(类生产环境)中。比如,我们完成单元测试后,可以把代码部署到连接数据库的Staging环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境