Linux学习之进程三
目录
进程控制
fork函数
什么是写时拷贝
进程终止
mian函数的返回值
退出码
错误码
exit()
进程等待
1.什么是进程等待?
2.为什么要进行进程等待?
3.如何进程进程等待?
wait,waitpid:
waitpid
进程替换
1.什么是进程程序替换?
execl
原理
其他exec族的函数
替换我们自己的程序
进程控制
fork函数
在此之前,我们基本已经了解到了fork函数,即用它来创建一个子进程,fork函数无参数,返回值类型pid_t,其次fork函数有两个返回值,在子进程中,返回0,创建失败返回-1,在父进程中,给父进程返回子进程的pid。即等于0,子进程,大于0,父进程,-1,创建失败。
这里重点提一下:写时拷贝
通常情况下,父子进程共享一份代码,父进程在不写入时,数据也是共享的,当一个进程要去往里面写入时,便以写时拷贝的方法各自一份副本。

如图,左边为父进程的代码与数据,子进程拷贝父进程的代码数据。右边为当子进程尝试要写入时,此时会重新申请空间,自己拷贝一份数据段副本,再往里面写,并且修改之前的映射关系。
什么是写时拷贝
其中再在父进程创建子进程时,会将自己的数据区(页表)读写权限改为只读,然后再创建子进程。这个过程用户是不知道的,而用户可能会去对某一批数据进行写入,而页表会因为权限此时会出错,操作系统此时会介入进行判断(是因为越界还是权限问题),重新申请内存写入,从而进行写时拷贝。
通过fork函数我们可以让子进程和父进程执行不同的代码,或者一个进程执行不同的程序。
进程终止
首先如何创建一个多进程呢?我们可以利用循环fork创建多个子进程,
#include
#include
#include
#define N 10
typedef void (*callback_t)();
void worker()
{
int num=10;
while(num--)
{
printf("i am a child process,my pid is%d,ppid is%d,num:%d\n",getpid (),getppid(),num);
sleep(1);
}
}
void creatsubproc(int n,callback_t cb)
{
int i;
for(i=0;i 首先对于进程的运行,我们不关心,操作系统自己调度,我们创建的多进程,当子进程一个个运行完,就变成僵尸状态了。这里创建子进程时让自己才能恒运行自己worker时,我们可以单独写在外面,通过函数指针的方式,传参,这样以便于我们去修改进程数量以及worker内容。
这是我们再用ps指令监控我们的进程:
while :; do ps ajx| head -1&& ps ajx |grep myproc|grep -v grep;echo "---------------------------";sleep 1;done

可以看到进程数量不断增多,且慢慢的从s->z状态,一个个终止了。
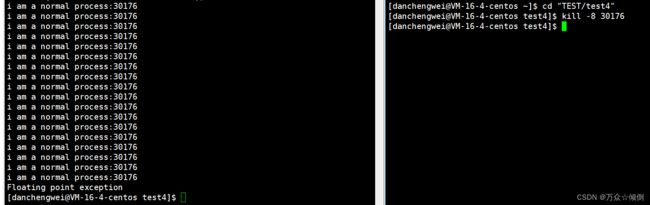
这里进程终止我们是通过调exit()函数,来实现进程终止,进程终止除了这种方式,也会正常终止,我们可以i用echo $?查看错误码。
对于进程终止,它的原理我们应该清楚,无非就是创建的pcb,页表等,终止时销毁了。可是对于进程终止我们需要了解它的应用:
mian函数的返回值
想了解进程终止的应用,首先我们先了解mian函数的返回值,首先我们知道我们一般写c/c++最后都是返回0,为什么呢?
首先当一个进程跑完,他的情况是怎样的呢?无非有三种情况:代码运行完毕,结果正确;代码运行完毕,结果不正确;代码异常终止;对于父进程,我们只看前两种。
在多进程环境中,父进程想知道子进程运行完结果是怎样的,而且该进程并没有任何的打印信息(我们人也无法观察得出),我们如何得知?
退出码
对于main函数的返回值,其实就是一个退出码,0就表示的是运行成功-success,非0通常表示运行结果错误--failed,父进程通过子进程返回的退出码,知晓进程运行结果如何。
错误码
对于进程返回0,运行成功,没什么好说的,可是若是非0,运行不正确,但我们并不知道是哪里的问题,只知道进程运行有问题,那么是因为什么原因失败的?此时我们就需要错误码来告诉我们,因为非0表示错误,非0的数字有很多,我们就可以用他们表示不同的出错原因。
系统里会有一套字符串表示错误信息用来对应每个数字,通过错误码就可以知道运行结果及问题所在。而这个字符串错误信息就是strerror(c语言中的时候我们就接触过),我们通过一个循环来看看它的错误码对应的错误信息,并且有多少个:
int mian()
{
//我们也不知道多少,假定200
for(int i=0;i<200;i++)
{
printf("%d:%s\n",i,strerror(i));
}
return 0;
}
而在linux中,可以用$?查看上一次进程(指令)的错误码,?就如同环境变量一样,存放的是错误信息。
这些内置的错误码,如果没有有你想要的的错误说明,你也是可以自定义的,直接定义这样的字符数组
const char*err_string[]={"success","not find","write errorr"}其下标就是对应的错误码。
对于我们的linux进程的异常,也是有对应的异常信息,对应的异常的错误码如下:
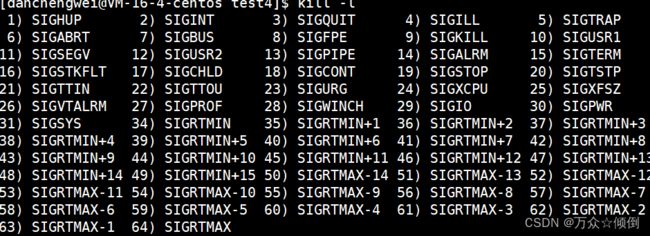
而我们的进程的错误也可以人工向他发出信号给进程从而实现异常:
exit()
我们在上文知道了,进程直接退出可以调用exit(),那么关于exit到底是什么呢?早在学习c语言的时候,我们也许就接触过了,那么它实际是怎么用的呢?
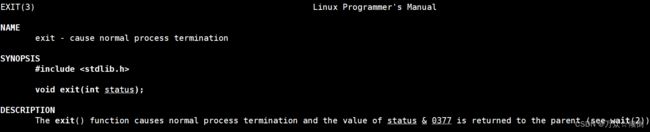
可以看到头文件和参数类型,这里的参数其实就是错误码(退出码),作用就是直接引起进程结束。
我们在意一段代码理解exit,进程退出:
1 #include
2 #include
3 #include
4 int func()
5 {
6 printf("call func function done!\n");
7 return 11;
8 }
9 int main()
10 {
11 func();//调用func函数
12 printf("i am a process,pid: %d,ppid: %d\n",getpid(),getppid());
13 //直接退出进程 exit(0);
14 //对于main函数中直接return返回的是进程的错误码
15 //其他函数return,仅代表该函数结束
16 //return 21;
17 //现在我们不用return 来返回退出码
18 //直接调用exit对应的退出码。,其效果等价return
19 exit(21);
20 }
~
~
~ 我们在这里将他的退出码给21,此时我们运行程序后,在看他的错误码与return是一样的:
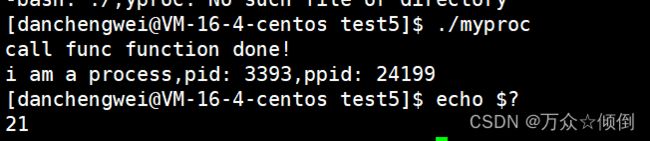
现在我们知道只有在main函数中的return 的是退出码,在子函数的return 只是代表返回该函数的返回值,退出该函数。当我们在其他函数中直接调用exit,此时就会直接退出进程,不会运行下面的代码了。
#include
#include
#include
int func()
{
printf("call func function done!\n");
// return 11;
exit(12);
}
int main()
{
func();//调用func函数
printf("i am a process,pid: %d,ppid: %d\n",getpid(),getppid());
exit(21);
}

可以看到直接退出了进程,退出码为在这个子函数调用的exit的退出码。
除了手册3,man 3 exit 查看到的这个exit,还有man _exit,手册2的一个进程退出函数,用法基本相同,效果也差不多。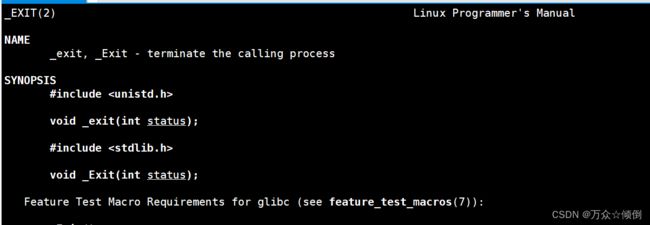
它们有一个区别我们可以用一行代码体现:
printf("hello linu");
printf("hello linu\n");首先对于exit,在终止进程时会刷新缓冲区,比如第一行代码,在没遇到\n之前,除非强制flush,否则只有等到进程终止此时才会想屏幕打印出来。
对于_exit,还是不加\n的时候。我们运行第一句话,这里没有/n,也没flush,此时进程终止,直接就退出来,什么也没打印,故此_exit终止不刷新缓冲区。
而所谓的缓冲区是绝对不在操作系统里,在我们的c库里,因此_exit与exit是存在这样的区别的。
进程等待
1.什么是进程等待?
首先进程等待就是通过wait/waitpid的方式,让父进程(一般)对子进程进行资源回收的等待过程。
2.为什么要进行进程等待?
之前讲过,子进程退出,父进程如果不管不顾,就可能造成 ‘ 僵尸进程 ’ 的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,那就刀枪不入, kill -9 也无能为力,因为谁也没有办法 杀死一个已经死去的进程。最后,父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对, 或者是否正常退出。父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
1.解决子进程僵尸问题带来的内存泄漏 ---必须的
2.子进程对于自己的任务完成的怎么样父进程需要知道---通过进程等待的方式获取子进程退出的信息(退出码与信号编号)。
3.如何进程进程等待?
首先聊凭借两个接口:
wait,waitpid:
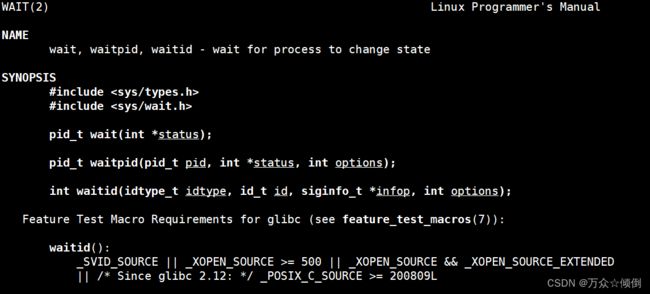
对于wait,waitpid都是wait 2手册里的,调用这两个接口,需要包含头文件两个,参数分别为退出码;pid,退出码,选项。
wait的作用是可以帮父进程等待任意一个子进程的退出
waitpid:利用waitpid返回是否成功退出,返回pid退出成功,返回-1退出失败。
我们用一个例子来看看wait的作用:
void worker()
{
int cnt=5;
while(cnt--)
{
printf("i am a process my pid: %d,my ppid:%d\n",getpid(),getppid()) ;
sleep(1);
}
}
int main()
{
pid_t id=fork();
if(id==0)
{
worker();
exit(0);
}else{
//father
sleep(10);
pid_t rid=wait(NULL);
if(id==rid)
{
//等待成功
printf("wait success,pid:%d\n",getpid());
}
sleep(10);
}
return 0;
}

![]()
刚开始五秒,子进程在运行,五秒后遇到exit直接退出(异常退出),此时状态为僵尸状态,我们之前说过,僵尸进程是无法杀掉的,必须要让父进程接收到子进程的退出信息才行,之后继续运行父进程里的,先休眠10秒,做一下区分,然后父进程中,我们直接调用wait,退出码暂时不设置为null,调用wait之后,可以看到僵尸状态的子进程直接没了(子进程被成功回收),只有父进程,在10秒后,父进程结束。
总的概括就是,父进程通过调用wait函数,来获得子进程的退出信息,然后释放子进程,如果没调用wait,获取不到退出信息,此时进程就无法被释放。
当我们在执行等待时,如果子进程根本就没有退出,父进程就必须在wait时进行阻塞等待,直到自己僵尸进程时候,wait就会自动回收,返回。也就是需要等待子进程运行完成为僵尸进程才能回收。
一般而言,谁先运行我们是不知道的,但是父进程都是最后退出的。
waitpid

wait只能等待当前的进程,没得选,而waitpid可以指定等待的进程。而对于waitdpid我们一般只需要掌握两种参数,首先对于Pid,指定等待进程的Pid,也可以设置为 -1,表示等待任意一个子进程。
参数int *status这里是一个输出型参数(通过函数把这个参数带出来给给操作系统),这里的option默认设置为0,表示的是阻塞等待。
我们将上述的测试再做修改:
void worker()
{
int cnt=5;
while(cnt--)
{
printf("i am a process my pid: %d,my ppid:%d--%d\n",getpid(),getppid(),cnt);
sleep(1);
}
}
int main()
{
pid_t id=fork();
if(id==0)
{
worker();
exit(10);
}else{
//father
printf("wait before\n");
int status=0;
pid_t rid=waitpid(id,&status,0);
if(id==rid)
{
//等待成功
printf("wait success,pid:%d,%d\n",getpid(),status);
}
printf("wait after");
}
return 0;
}
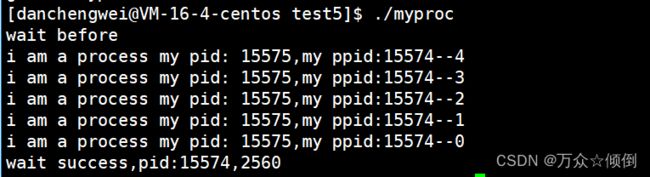
利用同等方式我们也可以实现进程等待,只不过对于这里的status,为什么时2560我们还是不得而知,实际上status是一个整数,一共32位,低16位:
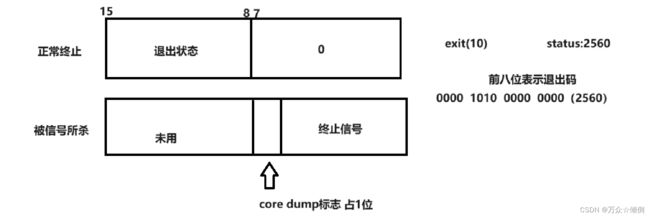
首先我们在waitpid时不能对status整体使用,且我们可以通过等待完毕后的status的二进制分析得出他的退出码。
其次我们还可以通过有意8位在与上0xFF,得出信号位,用来表示是否收到信号。
对于这里的option除了0,一阻塞方式等待,还有一个状态NOHANG(宏),以非阻塞的方式的等待,
总结:
pid_ t waitpid(pid_t pid, int *status, int options);返回值:当正常返回的时候 waitpid 返回收集到的子进程的进程 ID ;如果设置了选项 WNOHANG, 而调用中 waitpid 发现没有已退出的子进程可收集 , 则返回 0 ;如果调用中出错 , 则返回 -1, 这时 errno 会被设置成相应的值以指示错误所在;参数:pid :Pid=-1, 等待任一个子进程。与 wait 等效。Pid>0. 等待其进程 ID 与 pid 相等的子进程。status:WIFEXITED(status): 若为正常终止子进程返回的状态,则为真(查看进程是否是正常退出)WEXITSTATUS(status): 若 WIFEXITED 非零,提取子进程退出码。(查看进程的退出码)options:WNOHANG: 若 pid 指定的子进程没有结束,则 waitpid() 函数返回 0 ,不予以等待。若正常结束,则返回该子进 程的ID 。
进程替换
1.什么是进程程序替换?
之前说过,父进程创建的子进程,子进程的代码和数据都是拷贝父进程的,可是我们如何让紫禁城区执行全新的任务呢,访问全新的数据,不在和父进程有瓜葛。且不是再去创建一个子进程。
这是我们需要程序替换:
我们以一个父进程为例
首先了解一下名来进程替换的接口:exec函数族
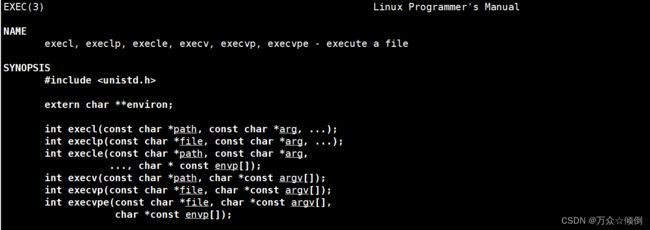
我们先看下一下execl函数的调用
#include
#include
int main()
{
//我们知道我们所使用的命令行指令都是一个个程序
printf("pid:%d,exec command begin\n",getpid());
execl("/usr/bin/ls","ls","-a","-l",NULL);
printf("pid:%d,exec command end\n",getpid());
return 0;
}
我们写一个简单的代码,可以看到如上我们是没有常见任何进程的,但是当我们运行之后
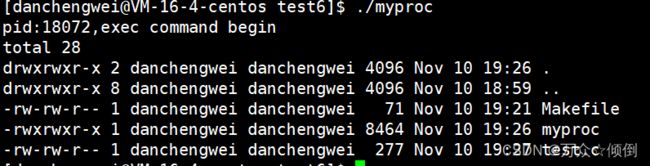
可以看到我们直接调起了指令ls -a -l。但是后面的那一句话没有打印出来
以同样的方式,我们还调用了top指令。
#include
#include
int main()
{
//我们知道我们所使用的命令行指令都是一个个程序
printf("pid:%d,exec command begin\n",getpid());
execl("/usr/bin/top","top",NULL);
printf("pid:%d,exec command end\n",getpid());
return 0;
}

从上述的结果看出,我们可以通过语言调用其他程序。
execl
总结上述,那么通过execl函数可以调用其他程序。调用完之后,后面的代码不在运行。
![]()
execl函数就是其中一个可以替换程序的函数:
对于它的参数,第一个path,表示表示替换程序所在路径+文件名,第二个 const char*arg 以及后面的......其实是可变参数列表,都是表示如何使用该指令。
在此之前我们学习到的命令行参数中参数就与这里的可变参数本质上就是同一个。
即第一个参数找到该程序,后面的参数如何执行该程序(与命令行保持一致)。
注意:无论如何去传递参数,末尾一定是以NULL结尾,表示参数传递完毕!
原理
第二个问题,为什么执行完调用的程序,后面没在执行了?
实际上execl执行完就已经完成了程序的替换,我们知道在mm_struct中管理着进程的内存空间:
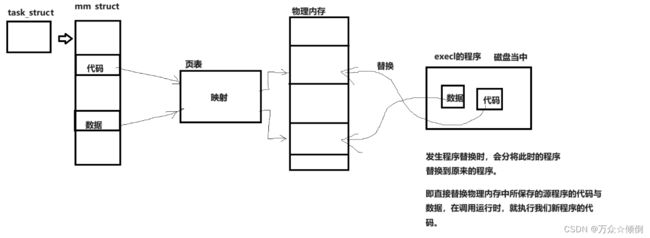
直接替换源程序的数据与代码,我们源程序的pid等其他属性不变,此时在这个过程中,不用产生新的进程就完成了进程的程序替换。
此时我们再通过多进程再来感受一下进程替换:
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{
//子进程
printf("pid:%d,exec command begin\n",getpid());
sleep(1);
execl("/usr/bin/ls","ls","-a","-l",NULL);
printf("pid:%d,exec command end\n",getpid());
}else{
//父进程
pid_t rid=waitpid(-1,NULL,0);//父进程来等待子进程
if (rid>0)
{
printf("wait succees rid:%d\n",rid);
}
}
return 0;
}
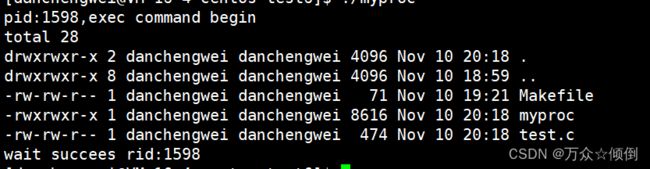
看到结果首先pid是没有变化的,其次还是没有看到command end这句话。
创建子进程的时候,之前我们就说过,子进程与父进程数据共享,代码以写时拷贝的方法各自私有一份,在子进程发生替换时,通过写时拷贝(代码段与数据都重新拷贝),以保持父子的独立性,父进程与子进程不会相互影响。
现在就说一说子进程在替换后,是如何知道我们的代码段该从哪里运行,其次为什么的后面的代码不再执行了?
这个我们之前也提到过(fork创建子进程时运行代码段),其实就是程序计数器,pc指针与 eip会记录函数在运行的过程中,执行到哪一步了,在没替换之前,被记录下来,所以知道从哪里运行,其次,无论是多进程还是单进程,进程替换之后,代码都被替换,eip重新从新的程序开始,下面的代码就不会再执行了,最后被回收。
其他exec族的函数
了解了替换的本质后,我们再来看看exec族的其他函数:
![]()
第一个参数与execl不一样,这里表示的是文件名,即这里的execlp,p指的是path,我们不需要给他完整的路径,他自己会去寻找,给出文件名即可。
int main()
{
printf("pid:%d,exec command begin\n",getpid());
execlp("ls","ls","-a","-l",NULL);
printf("pid:%d,exec command end\n",getpid());
return 0;
} 
再看看exev,这里的vector表示的是vector,技术组,可以看到这里的第二个参数由可变参数变成了字符串数组传参,与我们之前说的命令行参数的形式一样,这里再传入参数时,提前将命令行参数传入数组:
int main()
{
printf("pid:%d,exec command begin\n",getpid());
char*const argv[]={"ls","-a","-l",NULL};
execv("/usr/bin/ls",argv);
printf("pid:%d,exec command end\n",getpid());
return 0;
}
execvp可以看到这里就是与execv的区别就是不用完整路径(也可以用完整路径)。
int main()
{
printf("pid:%d,exec command begin\n",getpid());
char*const argv[]={"ls","-a","-l",NULL};
execv("ls",argv);
printf("pid:%d,exec command end\n",getpid());
return 0;
}
替换我们自己的程序
基本掌握了程序替换,对于上述我们都是举例外壳程序的指令,当然我们是可以替换自己的程序:
我们写一个简单的c++代码--打印hello c++,编译形成可执行,通过execl调用我们的程序:
int mian()
{
execl("./myprocc","myprocc",NULL);
return 0;
} 
当然除了c++,python,汇编程序,其他脚本语言都可以替换,调用。