大数据高级开发工程师——HBase学习笔记(1)
文章目录
- 大数据数据库之HBase
-
- HBase是什么
-
- HBase的概念
- HBase的特点
- HBase在实际场景中的应用
- HBase集群安装部署
-
- 准备安装包
- 修改配置文件
- 分发安装包
- 创建软链接
- 添加 HBase 环境变量
- HBase的启动与停止
- 访问WEB页面
- HBase表的数据模型
-
- rowkey 行键
- Column Family 列族
- Column 列
- Cell 单元格
- Timestamp 时间戳
- HBase整体架构
-
- Client客户端
- ZooKeeper集群
- HMaster
- HRegionServer
- Region
- HBase Shell命令基本操作
-
- 创建表并插入数据
- 查询数据操作
-
- 1. get命令
- 2. scan命令
- 3. count命令
- 更新数据操作
- 删除数据操作
- 管理操作
-
- 1. status
- 2. whoami
- 3. list
- 4. count
- 5. describe
- 6. exists
- 7. is_enabled、is_disabled
- 8. alter
- 9. disable、enable
- 10. drop
- 11. truncate
- HBase的JavaAPI操作
-
- 创建myuser表
- 向表中添加数据
- 查询数据
-
- 1. Get查询
- 2. Scan查询
- 过滤器查询
-
- 1. 过滤器说明
- 2. 使用比较过滤器
- 3. 使用专用过滤器
大数据数据库之HBase
HBase是什么
HBase的概念
- HBase基于Google的BigTable论文,是建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统。
- 在需要实时读、写随机访问、超大规模数据集时,可以使用HBase。
HBase的特点
- 极易扩展,海量存储
- 底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点就可以了
- 可以通过增加服务器来对集群的存储进行扩容
- 列式存储
- HBase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
- 高并发
- 支持高并发的读写请求
- 稀疏
- 稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
- 数据的多版本
- HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
- 数据类型单一
- 所有的数据在HBase中是以字节数组进行存储
HBase在实际场景中的应用
- 交通方面:船舶GPS信息,全长江的船舶GPS信息,每天有1千万左右的数据存储。
- 金融方面:消费信息、贷款信息、信用卡还款信息等。
- 电商方面:电商网站的交易信息、物流信息、游览信息等。
- 电信方面:通话信息、语音详单等。
总结:海量明细数据的存储,并且后期需要有很好的查询性能。
HBase集群安装部署
准备安装包
- 下载安装包到 node01 服务器,并解压到指定目录
wget https://archive.apache.org/dist/hbase/2.2.6/hbase-2.2.6-bin.tar.gz
# 解压缩
tar -zxvf hbase-2.2.6-bin.tar.gz -C /bigdata/install/
修改配置文件
- 修改 hbase-env.sh
$ pwd
/bigdata/install/hbase-2.2.6/conf
vim hbase-env.sh
# 修改如下两项内容
export JAVA_HOME=/usr/apps/jdk1.8.0_241
export HBASE_MANAGES_ZK=false
- 修改 hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://node01:8020/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node01,node02,node03:2181value>
property>
<property>
<name>hbase.master.info.portname>
<value>60010value>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
configuration>
- 修改 regionservers,原内容清空,添加如下三行
node01
node02
node03
- 创建 backup-masters 配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
vim backup-masters
node02
分发安装包
- 将 node 01 上的 HBase 安装包,拷贝到其它机器
cd /bigdata/install/
scp -r hbase-2.2.6/ node02:$PWD
scp -r hbase-2.2.6/ node03:$PWD
创建软链接
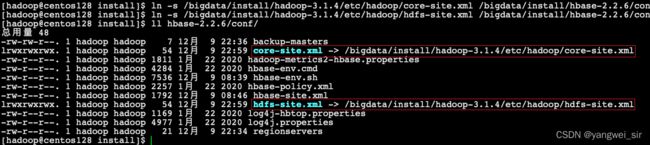
- 因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们三台机器都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /bigdata/install/hadoop-3.1.4/etc/hadoop/core-site.xml /bigdata/install/hbase-2.2.6/conf/core-site.xml
ln -s /bigdata/install/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /bigdata/install/hbase-2.2.6/conf/hdfs-site.xml
添加 HBase 环境变量
- 三台机器均执行如下命令
sudo vim /etc/profile
export HBASE_HOME=/bigdata/install/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin
# 让环境变量生效
source /etc/profile
HBase的启动与停止
- 需要提前启动HDFS及ZooKeeper集群
- 如果没开启hdfs,请在node01运行
start-dfs.sh命令 - 如果没开启zookeeper,请在3个节点分别运行
zkServer.sh start命令
- 如果没开启hdfs,请在node01运行
- 第一台机器node01(HBase主节点)执行以下命令,启动HBase集群
start-hbase.sh
- 启动完后,查看 HBase 相关进程

- 我们也可以执行以下命令,单节点启动相关进程
# HMaster节点上启动HMaster命令
hbase-daemon.sh start master
# 启动HRegionServer命令
hbase-daemon.sh start regionserver
- 停止HBase集群的正确顺序,node01上运行,关闭hbase集群
- 关闭ZooKeeper集群
- 关闭Hadoop集群
- 关闭虚拟机
- 关闭笔记本
stop-hbase.sh
访问WEB页面
- 浏览器页面访问:http://node01:60010

HBase表的数据模型

rowkey 行键
- 表的主键,表中的记录安装 rowkey 的字典序进行排序
- rowkey 行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10~100 bytes)
Column Family 列族
- 列族或列簇
- HBase表中的每个列,都归属与某个列族
- 列族是表的schema的一部分(而列不是),即建表时至少指定一个列族
- 比如创建一张表,名为
user,有两个列族,分别是info和data,建表语句create 'user', 'info', 'data'
Column 列
- 列肯定是表的某一列族下的一个列,用
列族名:列名表示,如info列族下的name列,表示为info:name - 属于某一个ColumnFamily,类似于我们mysql当中创建的具体的列
Cell 单元格
- 指定row key行键、列族、列,可以确定的一个cell单元格
- cell中的数据是没有类型的,全部是以字节数组进行存储
Timestamp 时间戳
- 可以对表中的Cell多次赋值,每次赋值操作时的时间戳timestamp,可看成Cell值的版本号 version number
- 即一个 Cell 可以有多个版本的值
HBase整体架构

Client客户端
- Client是操作HBase集群的入口
- 对于管理类的操作,如表的增、删、改,Client通过RPC与HMaster通信完成
- 对于表数据的读写操作,Client通过RPC与RegionServer交互,读写数据
- Client类型:
- HBase shell
- Java编程接口
- Thrift、Avro、Rest等
ZooKeeper集群
-
实现了HMaster的高可用,多HMaster间进行主备选举
-
保存了HBase的元数据信息meta表,提供了HBase表中region的寻址入口的线索数据
-
对HMaster和HRegionServer实现了监控
HMaster
- HBase集群也是主从架构,HMaster是主的角色,是老大,主要负责Table表和Region的相关管理工作
- 关于Table
- 管理Client对Table的增删改的操作
- 关于Region
- 在Region分裂后,负责新Region分配到指定的HRegionServer上
- 管理HRegionServer间的负载均衡,迁移region分布
- 当HRegionServer宕机后,负责其上的region的迁移
HRegionServer
- HBase集群中从的角色,是小弟
- 响应客户端的读写数据请求
- 负责管理一系列的Region
- 切分在运行过程中变大的region
Region
- HBase集群中分布式存储的最小单元
- 一个Region对应一个Table表的部分数据
HBase Shell命令基本操作
hbase shell进入 hbase 客户端
创建表并插入数据
# help 命令查看帮助信息
> help
> help 'create'
# 查看当前数据库中有哪些表
> list
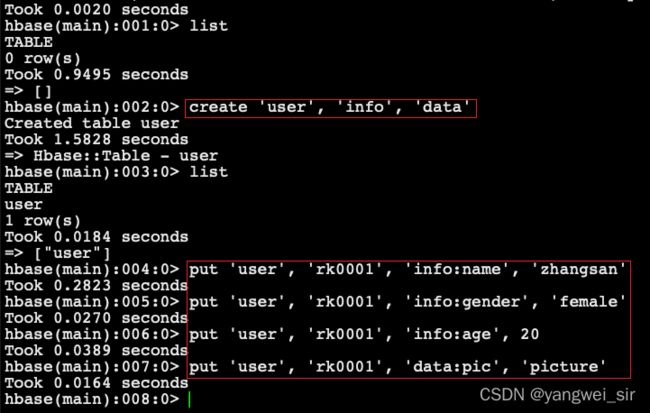
# 使用 create 命令,创建user表,包含info、data两个列族
> create 'user', 'info'
# 或者
> create 'user',{NAME => 'info', VERSIONS => '3'},{NAME => 'data'}
# 向表中插入数据
# 向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
> put 'user', 'rk0001', 'info:name', 'zhangsan'
# 向user表中插入信息,row key为rk0001,列族info中添加名为gender的列,值为female
> put 'user', 'rk0001', 'info:gender', 'female'
# 向user表中插入信息,row key为rk0001,列族info中添加名为age的列,值为20
> put 'user', 'rk0001', 'info:age', 20
# 向user表中插入信息,row key为rk0001,列族data中添加名为pic的列,值为picture
> put 'user', 'rk0001', 'data:pic', 'picture'
查询数据操作
1. get命令
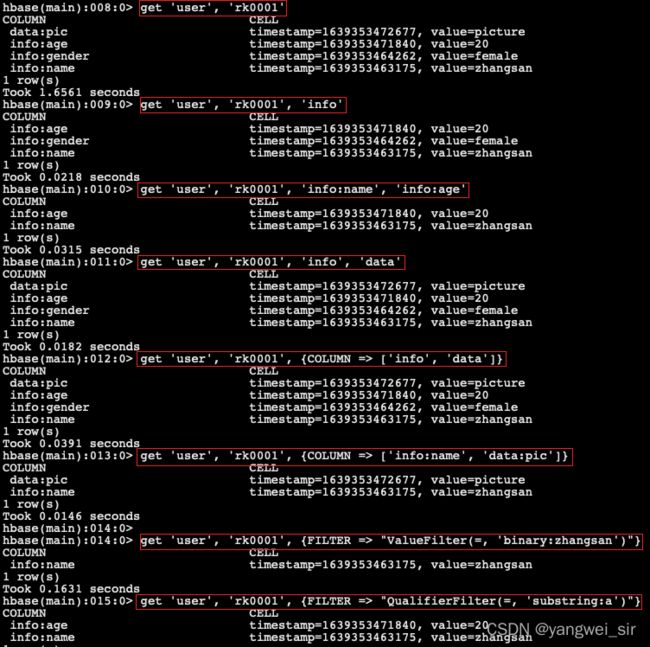
# 1、通过rowkey查询: 获取user表中row key为rk0001的所有信息(即所有cell的数据)
> get 'user', 'rk0001'
# 2、查看rowkey下某个列族的信息: 获取user表中row key为rk0001,info列族的所有信息
> get 'user', 'rk0001', 'info'
# 3、查看rowkey指定列族指定字段的值: 获取user表中row key为rk0001,info列族的name、age列的信息
> get 'user', 'rk0001', 'info:name', 'info:age'
# 4、查看rowkey指定多个列族的信息: 获取user表中row key为rk0001,info、data列族的信息
> get 'user', 'rk0001', 'info', 'data'
# 或者可以这样写
get 'user', 'rk0001', {COLUMN => ['info', 'data']}
# 或者也可以这样写,也行
get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
# 5、指定rowkey与列值过滤器查询: 获取user表中row key为rk0001,cell的值为zhangsan的信息
> get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}
# 6、指定rowkey与列名模糊查询: 获取user表中row key为rk0001,列标示符中含有a的信息
> get 'user', 'rk0001', {FILTER => "QualifierFilter(=, 'substring:a')"}
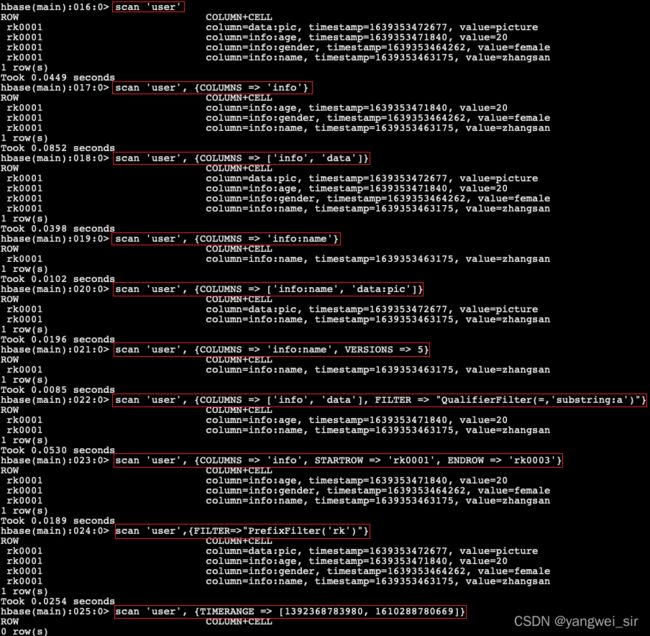
2. scan命令
# 1、查询所有行的数据: 查询user表中的所有信息
> scan 'user'
# 2、列族查询: 查询user表中列族为info的信息
> scan 'user', {COLUMNS => 'info'}
# 当把某些列的值删除后,具体的数据并不会马上从存储文件中删除;查询的时候,不显示被删除的数据;如果想要查询出来的话,RAW => true
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
# 3、多列族查询: 查询user表中列族为info和data的信息
> scan 'user', {COLUMNS => ['info', 'data']}
# 4、指定列族与某个列名查询: 查询user表中列族为info、列标示符为name的信息
> scan 'user', {COLUMNS => 'info:name'}
# 查询info:name列、data:pic列的数据
> scan 'user', {COLUMNS => ['info:name', 'data:pic']}
# 查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
> scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
# 5、指定多个列族与条件模糊查询: 查询user表中列族为info和data且列标示符中含有a字符的信息
> scan 'user', {COLUMNS => ['info', 'data'], FILTER => "QualifierFilter(=,'substring:a')"}
# 6、指定rowkey的范围查询: 查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan 'user', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
# 7、指定rowkey模糊查询: 查询user表中row key以rk字符开头的数据
> scan 'user',{FILTER=>"PrefixFilter('rk')"}
# 8、指定数据版本的范围查询: 查询user表中指定范围的数据(前闭后开)
> scan 'user', {TIMERANGE => [1392368783980, 1610288780669]}
3. count命令
# 统计一张表有多少行数据
> count 'user'
更新数据操作
- 更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加
- 更新数据值,使用put命令
- 更新版本号,使用alter命令
# 将user表的info列族版本数改为5
alter 'user', NAME => 'info', VERSIONS => 5
删除数据操作
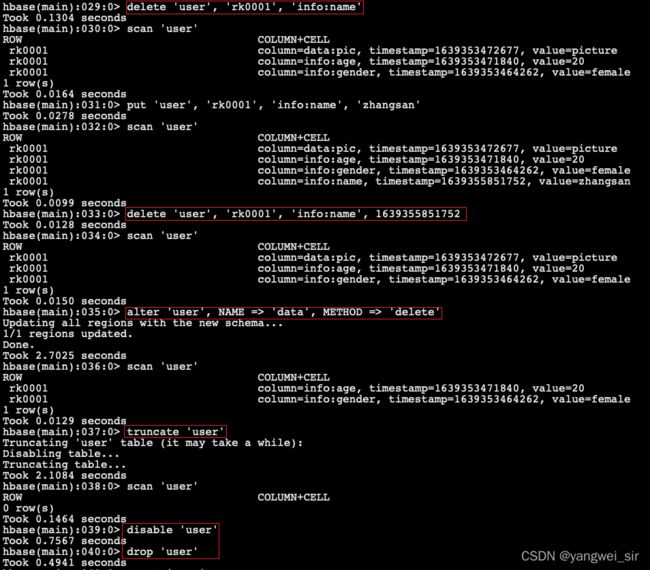
# 1、指定rowkey以及列名进行删除: 删除user表row key为rk0001,列标示符为info:name的数据
> delete 'user', 'rk0001', 'info:name'
# 2、指定rowkey,列名以及版本号进行删除: 删除user表row key为rk0001,列标示符为info:name,timestamp为 1639355851752 的数据
> delete 'user', 'rk0001', 'info:name', 1639355851752
# 3、删除一个列族
> alter 'user', NAME => 'data', METHOD => 'delete'
#或
> alter 'user', 'delete' => 'info'
# 4、清空表数据
> truncate 'user'
# 5、删除表: 首先需要先让该表为disable状态,然后使用drop命令删除这个表
# 注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled
> disable 'user'
> drop 'user'
管理操作
1. status
- 显示服务器状态
status 'node01'
2. whoami
- 显示 HBase 当前用户
whoami
3. list
- 显示当前所有的表
list
4. count
- 统计指定表的记录数
count 'user'
5. describe
- 展示表结构信息
describe 'user'
6. exists
- 检查表是否存在,适用于表量特别多的情况
exists 'user'
7. is_enabled、is_disabled
- 检查表是否启用或禁用
is_enabled 'user'
is_disabled 'user'
8. alter
- 可以改变表和列族的模式
# 为当前表增加列族
alter 'user', NAME => 'CF2', VERSIONS => 2
# 为当前表删除列族
alter 'user', 'delete' => 'CF2'
9. disable、enable
- 禁用/启用一张表
disable 'user'
enable 'user'
10. drop
- 删除一张表,记得在删除表之前必须先禁用
11. truncate
- 禁用表-删除表-创建表

HBase的JavaAPI操作
- HBase是一个分布式的NoSql数据库,在实际工作当中,我们一般都可以通过JavaAPI来进行各种数据的操作,包括创建表,以及数据的增删改查等。
- jar 包依赖:
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>2.2.6version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>2.2.6version>
dependency>
创建myuser表
public class HbaseCreateTableTest {
/**
* 创建表 myuser,有两个列组 f1、f2
* 步骤:1、获取连接
* 2、获取客户端对象
* 3、操作数据库
* 4、关闭流
*/
@Test
public void createTable() throws IOException {
Configuration configuration = HBaseConfiguration.create();
// 指定hbase的zk集群地址
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
// 创建连接对象
Connection connection = ConnectionFactory.createConnection(configuration);
// 获取管理员对象,创建一张表
Admin admin = connection.getAdmin();
// 指定表名
TableDescriptor tableDescriptor = TableDescriptorBuilder.newBuilder(TableName.valueOf("myuser"))
// 指定两个列族
.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder("f1".getBytes()).build())
.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder("f2".getBytes()).build())
.build();
admin.createTable(tableDescriptor);
// 关闭
admin.close();
connection.close();
}
}
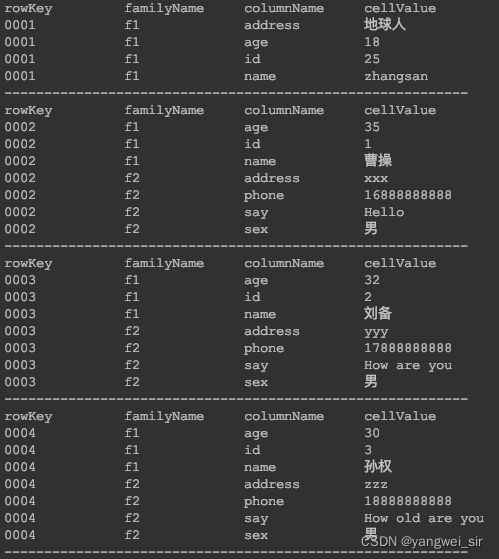
向表中添加数据
- 单条插入和批量插入
public class HbaseInsertTest {
private static final String TABLE_NAME = "myuser";
private Connection connection;
private Table table;
@Before
public void init() throws IOException {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
connection = ConnectionFactory.createConnection(configuration);
table = connection.getTable(TableName.valueOf(TABLE_NAME));
}
/**
* 向myuser表中添加数据
*/
@Test
public void insertOne() throws IOException {
// 创建 put 对象,并指定 rowkey
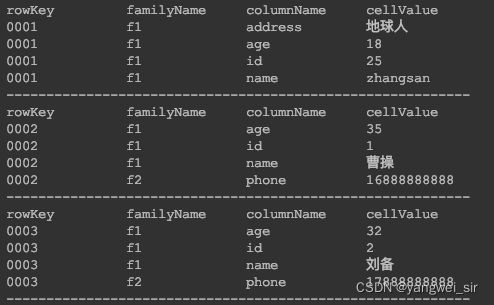
Put put = new Put("0001".getBytes());
put.addColumn("f1".getBytes(), "name".getBytes(), "zhangsan".getBytes());
put.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(18));
put.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(25));
put.addColumn("f1".getBytes(), "address".getBytes(), Bytes.toBytes("地球人"));
table.put(put);
}
@Test
public void batchInsert() throws IOException {
// 创建 put 对象,并指定 rowkey
Put put1 = new Put("0002".getBytes());
put1.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(1));
put1.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("曹操"));
put1.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(35));
put1.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("男"));
put1.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("xxx"));
put1.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("16888888888"));
put1.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("Hello"));
Put put2 = new Put("0003".getBytes());
put2.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(2));
put2.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("刘备"));
put2.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(32));
put2.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("男"));
put2.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("yyy"));
put2.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("17888888888"));
put2.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("How are you"));
Put put3 = new Put("0004".getBytes());
put3.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(3));
put3.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("孙权"));
put3.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(30));
put3.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("男"));
put3.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("zzz"));
put3.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("18888888888"));
put3.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("How old are you"));
table.put(Arrays.asList(put1, put2, put3));
}
@After
public void close() throws IOException {
table.close();
connection.close();
}
}
查询数据
1. Get查询
- 按照rowkey进行查询,获取所有列的所有值
/**
* 查询rowkey为0003的数据
*/
@Test
public void getData() throws IOException {
Get get = new Get(Bytes.toBytes("0003"));
// 限制只查询f1列族下面所有列的值
get.addFamily("f1".getBytes());
// 查询f2 列族 phone 这个字段
get.addColumn("f2".getBytes(), "phone".getBytes());
// 通过get查询,返回一个result对象,所有的字段的数据都是封装在result里面了
Result result = table.get(get);
// 获取一条数据所有的cell,所有数据值都是在cell里面
printData(result.listCells());
}
private void printData(List<Cell> cells) {
if (CollectionUtils.isEmpty(cells)) {
return;
}
System.out.printf("%-15s%-15s%-15s%-15s\n", "rowKey", "familyName", "columnName", "cellValue");
for (Cell cell : cells) {
// 获取rowKey
byte[] rowKey = CellUtil.cloneRow(cell);
// 获取列族名
byte[] familyName = CellUtil.cloneFamily(cell);
// 获取列名
byte[] columnName = CellUtil.cloneQualifier(cell);
// 获取cell值
byte[] cellValue = CellUtil.cloneValue(cell);
// 需要判断字段的数据类型,使用对应的转换的方法,才能够获取到值
if ("age".equals(Bytes.toString(columnName)) || "id".equals(Bytes.toString(columnName))) {
System.out.printf("%-15s%-15s%-15s%-15s\n", Bytes.toString(rowKey), Bytes.toString(familyName),
Bytes.toString(columnName), Bytes.toInt(cellValue));
} else {
System.out.printf("%-15s%-15s%-15s%-15s\n", Bytes.toString(rowKey), Bytes.toString(familyName),
Bytes.toString(columnName), Bytes.toString(cellValue));
}
}
}
2. Scan查询
/**
* 不知道rowkey的具体值,想查询rowkey范围是0001到0003
*/
@Test
public void scanData() throws IOException {
Scan scan = new Scan();
scan.addFamily("f1".getBytes());
scan.addColumn("f2".getBytes(), "phone".getBytes());
scan.withStartRow("0001".getBytes()).withStopRow("0004".getBytes()); // 左闭右开
printResult(table.getScanner(scan));
}
private void printResult(ResultScanner scanner) {
for (Result result : scanner) {
printData(result.listCells());
System.out.println("----------------------------------------------------------");
}
}
过滤器查询
1. 过滤器说明
- 过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
- 过滤器的类型很多,但是可以分为两大类
- 比较过滤器
- 专用过滤器
- HBase过滤器的比较运算符:
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <> 不等于
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
- HBase比较过滤器的比较器(指定比较机制):
BinaryComparator 按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator 跟前面相同,只是比较左端前缀的数据是否相同
NullComparator 判断给定的是否为空
BitComparator 按位比较
RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator 判断提供的子串是否出现在中
2. 使用比较过滤器
- rowKey过滤器RowFilter
/**
* 通过RowFilter过滤比rowKey = 0003小的所有值出来
*/
@Test
public void testRowFilter() throws IOException {
Scan scan = new Scan().setFilter(
/**
* rowFilter需要加上两个参数:
* 第一个参数就是我们的比较规则
* 第二个参数就是我们的比较对象
*/
new RowFilter(CompareOperator.LESS, new BinaryComparator("0003".getBytes()))
);
printResult(table.getScanner(scan));
}

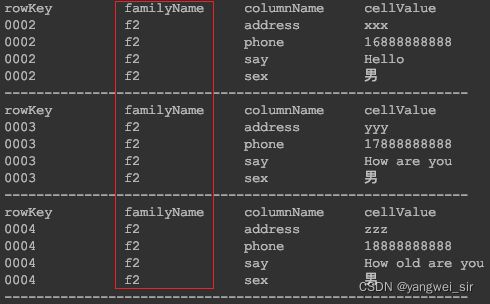
- 列族过滤器FamilyFilter
/**
* 通过 FamilyFilter 查询列族名包含f2的所有列族下面的数据
*/
@Test
public void testFamilyFilter() throws IOException {
Scan scan = new Scan().setFilter(
new FamilyFilter(CompareOperator.EQUAL, new SubstringComparator("f2"))
);
printResult(table.getScanner(scan));
}
- 列过滤器QualifierFilter
/**
* 通过 QualifierFilter 只查询列名包含`name`的列的值
*/
@Test
public void testQualifierFilter() throws IOException {
Scan scan = new Scan().setFilter(
new QualifierFilter(CompareOperator.EQUAL, new SubstringComparator("name"))
);
printResult(table.getScanner(scan));
}
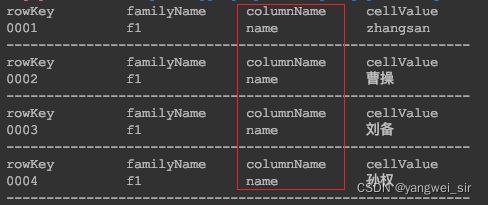
- 列值过滤器ValueFilter
/**
* 通过 ValueFilter 查询所有列当中包含8的数据
*/
@Test
public void testValueFilter() throws IOException {
Scan scan = new Scan().setFilter(
new ValueFilter(CompareOperator.EQUAL, new SubstringComparator("8"))
);
printResult(table.getScanner(scan));
}
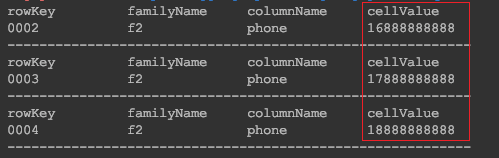
3. 使用专用过滤器
- 单列值过滤器 SingleColumnValueFilter:SingleColumnValueFilter会返回满足条件的cell,所在行的所有cell的值
/**
* 通过 SingleColumnValueFilter 查询 f1 列族 name 列值为 刘备 的数据
*/
@Test
public void testSingleColumnValueFilter() throws IOException {
Scan scan = new Scan().setFilter(
new SingleColumnValueFilter("f1".getBytes(), "name".getBytes(),
CompareOperator.EQUAL, new SubstringComparator("刘备"))
);
printResult(table.getScanner(scan));
}
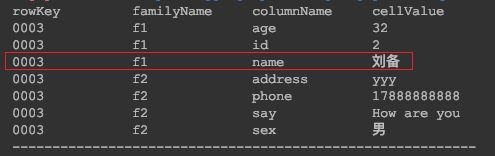
- 列值排除过滤器SingleColumnValueExcludeFilter,与SingleColumnValueFilter相反
- 如果指定列的值符合filter条件,则会排除掉row中指定的列,其他的列全部返回
- 如果列不存在或不符合filter条件,则不返回row中的列
/**
* 通过 SingleColumnValueExcludeFilter 查询排出了 f1 列族 name 列值为 刘备 的数据
*/
@Test
public void testSingleColumnValueExcludeFilter() throws IOException {
Scan scan = new Scan().setFilter(
new SingleColumnValueExcludeFilter("f1".getBytes(), "name".getBytes(),
CompareOperator.EQUAL, new SubstringComparator("刘备"))
);
printResult(table.getScanner(scan));
}
- rowkey前缀过滤器PrefixFilter
/**
* 通过 PrefixFilter 查询以00开头的所有前缀的rowkey
*/
@Test
public void testPrefixFilter() throws IOException {
Scan scan = new Scan().setFilter(
new PrefixFilter("00".getBytes())
);
printResult(table.getScanner(scan));
}
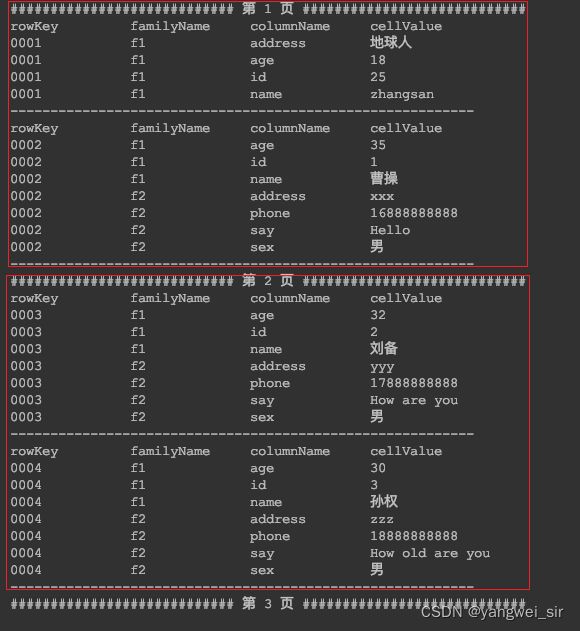
- 分页过滤器PageFilter
/**
* 通过 PageFilter 实现分页查询
*/
@Test
public void testPageFilter() throws IOException {
int pageNum = 1, pageSize = 2;
byte[] startRow = null;
do {
Scan scan = new Scan().setFilter(
new PageFilter(pageSize)
).withStartRow(startRow)
// 设置一步往前扫描多少条数据
.setMaxResultSize(pageSize);
ResultScanner scanner = table.getScanner(scan);
System.out.println("############################ 第 " + (pageNum++) + " 页 ############################");
int i = 0;
for (Result result : scanner) {
printData(result.listCells());
System.out.println("----------------------------------------------------------");
startRow = result.getRow();
i++;
}
if (startRow != null) startRow[startRow.length - 1]++;
if (i < pageSize) startRow = null;
} while (startRow != null);
}
- 多过滤器综合查询FilterList
/**
* 通过 FilterList 组合多个过滤器
* 实现SingleColumnValueFilter查询f1列族,name为刘备的数据,并且同时满足rowkey的前缀以00开头的数据(PrefixFilter)
*/
@Test
public void testFilterList() throws IOException {
FilterList filterList = new FilterList();
filterList.addFilter(Arrays.asList(
new SingleColumnValueFilter("f1".getBytes(), "name".getBytes(), CompareOperator.EQUAL, "刘备".getBytes()),
new PrefixFilter("00".getBytes())
));
Scan scan = new Scan().setFilter(filterList);
printResult(table.getScanner(scan));
}
- github代码地址:https://github.com/shouwangyw/bigdata/tree/master/hbase-demo