Text2Room:第一个从文本生成室内三维场景的方法!
欢迎关注『CVHub』官方微信公众号!

Title: Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
Paper: https://arxiv.org/pdf/2303.11989.pdf
Code: https://github.com/lukasHoel/text2room
导读
本文提出了Text2Room方法,用于从给定的文本提示符生成房间规模的纹理三维网格模型。为此,文章利用预先训练过的二维text-to-image的模型来合成来自不同位姿的一系列图像。为了将这些输出提升到一个一致的三维场景表示中,文章将单目深度估计与一个text-conditioned的图像修复模型相结合,提出了一种连续对齐策略,迭代地将生成的场景帧与现有的几何模型融合,以创建一个无缝的网格。与现有的专注于从文本中生成单个对象或小规模场景的工作不同,论文的方法生成完整的具有多个对象和显式三维几何的大规模3D场景。论文使用定性和定量的度量来评估所提方法,证明它是第一种仅从文本生成引人注目的房间规模的完整纹理三维网格模型的方法。
贡献

如上图所示,论文使用2D text-to-image模型从给定的文本提示符生成纹理三维网格,论文主要贡献如下:
- 从任何文本输入中生成具有引人注目的纹理和几何图形的房间规模的室内场景的三维网格
- 一个利用二维text-to-image模型和单目深度估计在迭代场景生成中将二维帧提升到三维空间的框架。论文提出的深度对齐和网格融合步骤,使算法能够创建无缝和不扭曲的几何图形和纹理。
- 一个两阶段的定制的视点选择,从最佳位置采样相机的位姿。首先创建房间布局和家具,然后补全剩余的孔洞,创建一个完整的三维网格。
方法

论文通过两阶段的视点选择(Two-Stage Viewpoint Selection),迭代地创建一个纹理的三维网格。
- 首先,论文采样预定义的相机位姿和文本,以生成完整的场景布局和家具。在Iterative 3D Scene Generation方案中,每个新相机位姿(用绿色标记)都将新生成的几何图形,通过Depth Alignment Step和Mesh Fusion Step添加到现有的网格(用绿色三角形表示)中(详见上图)。蓝色位姿/三角形表示在上一次迭代中创建几何图形的视点。
- 其次,在场景布局之后,论文通过采样额外的位姿(红色标记)来填充剩余的未观察到的区域。
Iterative 3D Scene Generation
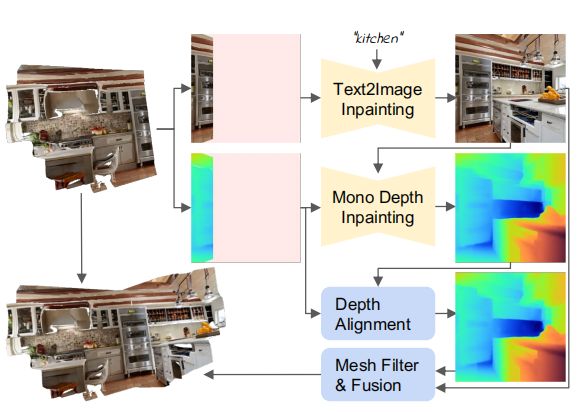
输入一组任意的问题提示,它对应于所选择的位姿 { E t z } t = 1 T ∈ R 3 × 4 \left\{E_{t} z\right\}_{t=1}^{T} \in \mathbb{R}^{3 \times 4} {Etz}t=1T∈R3×4 ,论文按照"渲染-细化-重复"模式迭代地构建场景。整个迭代迭的流程如上图所示。
对于每轮生成步骤,首先从一个新的视角渲染出当前场景:
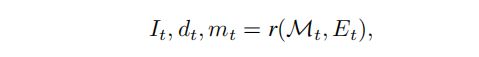
其中 r r r 是一个没有阴影的经典渲染光栅化函数, I t I_t It是渲染出来的图像, d t d_t dt是渲染深度, m t m_t mt是图像空间掩模,它标记了没有观察到的内容的像素。
然后,论文使用一个固定的text-to-image模型 F t 2 i \mathcal{F}_{t 2 i} Ft2i,根据文本提示来绘制未观察到的像素:
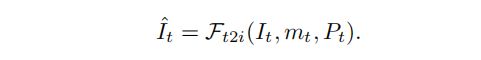
接下来,利用单目深度估计 F d \mathcal{F}_d Fd来估计生成的image的深度,将其与渲染深度进行深度对齐得到未观察到场景的深度:
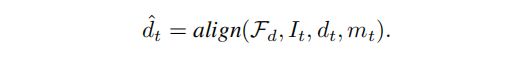
最终,通过融合方案将生成的新的场景 { I ^ t , d ^ t , m t } \{\hat I_t,\hat d_t,mt\} {I^t,d^t,mt}与现有的场景网格相结合

Depth Alignment Step
对于输入的每一帧,论文通过将单目深度模型预测的深度转换为3D点云,然后与之前生成的模型相拼接。但是这会导致三维几何图形中的深度切割和不连续,因为不同视点的单目深度估计之间的尺度不一致(见后面的消融实验)。
论文使用一个两阶段的深度对齐:
-
第一阶段,使用一个最先进的深度补全网络IronDepth,将之前场景中渲染得到的ground-truth的深度 d d d和新视角生成的image作为输入,得到预测的深度补全后的深度: d ^ p = F d ( I , d ) \hat{d}_{p}=\mathcal{F}_{d}(I, d) d^p=Fd(I,d)(如框架图中Mono Depth Inpainting部分所示)
-
第二阶段,将预测的补全后的深度与渲染的部分ground-truth的深度进行对齐。论文通过优化尺度和位移参数 γ , β ∈ R \gamma, \beta \in \mathbb{R} γ,β∈R,在使用最小二乘对齐预测的和渲染的视差。

其中,通过 m m m来掩盖未被观察到的像素。然后可以得到对齐的深度a d ^ = γ ⋅ d ^ p + β \hat{d}=\gamma\cdot\hat{d}_p+\beta d^=γ⋅d^p+β。最后再使用一个5×5高斯核进行平滑。
Mesh Fusion Step
为了将新生成的场景插入现有场景中,首先需要将生成的深度图投影到世界坐标系的点云中,然后对投影的点云进行三角化进行三维重建。
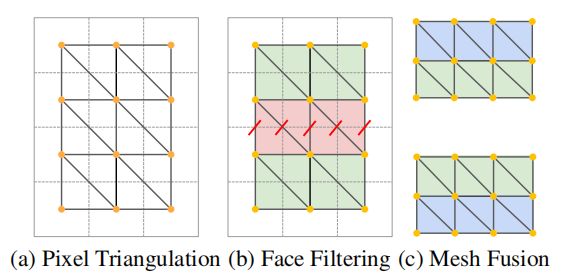
一种简单的三角化方式如上图a所示,但是由于估计的深度是有噪声的,会导致整体的三维场景部分面被异常拉伸(见消融实验)。为了缓解这个问题,论文提出两种滤波方法来去除被拉伸的面:
- 根据面的边长来过滤面。如果任何面的边的都是距离大于阈值贼被滤除
- 根据面的法线和视点方向之间的角度过滤面。避免了从图像中相对较少的像素数为网格的大区域创建纹理。
最后,将过滤后的新生成的网格patch和现有的网格融合在一起,如上图b,c所示。
Two-Stage Viewpoint Selection

论文方法的场景合成的一个关键部分是选择文本提示和相机位姿。原则上,用户可以任意选择这些输入来创建任何所需的室内场景。然而,如果随意选择摄像机位姿,生成的场景可能会退化并包含拉伸和孔的伪影。为此,论文提出了一种两阶段的视点选择策略,即从最优位置对每个下一个摄像机位姿进行采样,并随后细化空区域。
Generation Stage


第一阶段,论文创建了场景的主要部分,包括总的布局和家具。在创建封闭的房间布局时,需要选取多个视点,组合成一个重建轨迹,最终覆盖整个房间。实验发现,这些预定义的轨迹需要从一个大多未观察到的区域开始(上图b),对于每个视点,需要对位姿进行平移和旋转,采样额外的位姿,使该场景"FOV"变大,这种轨迹生成的场景是最好的。也即每个视点需要保持一定的观测距离,如果视点变化过小,如上图(e-g),重建结果就会变差。
论文发现,通过相应地设计文本提示,它有助于阻止文本到图像生成器在不需要的区域生成家具。例如,对于查看地板或天花板的相机位姿,论文会分别选择只包含单词“地板”或“天花板”的文本提示。
Completion Stage
在第一阶段之后,就完成定义了场景布局和家具。然而,不可能先验地选择足够的位姿。由于场景是动态生成的,所以网格包含了任何摄像机都没有观察到的空洞。论文通过对额外的面向这些空洞的相机位姿进行采样来填充剩余的未观察到的区域。。
如何找到这些面向空洞的相机位姿?论文将场景体素化为密集的均匀cells,在每个cell中随机采样位姿,丢弃那些太接近现有几何形状的位姿,最终为每个cell选择一个位姿来查看大多数未被观察到的像素

注意这里未被观察到的区域可以有任意大小的(上图b),直接从(b)的掩蔽区域会给出扭曲的结果(上图c),因为孔可能太小。论文用经典的修补方法绘制小孔,并将剩余的孔膨胀到更大尺寸的(上图d),重新绘制后可以得到的图像包含了更合理的结构(上图e)。
然后运行Iterative 3D Scene Generation,最后,再在场景网格上运行泊松曲面重建,这将在完成后关闭任何剩余的孔洞,并平滑不连续点,最终生成场景的Watertight geometry Mesh。
实验
Qualitative Results
如上图所示,论文方法创建了高细节纹理和几何,融合成一个完整的没有孔洞的高细节3D场景网格。生成的场景包含平面地板、墙壁和天花板,以及分布在整个场景中的三维对象。
如上图所示,论文方法使用相应的文本提示显示生成的场景,其渲染得到的颜色和阴影,能够很好地满足文本描述。
Quantitative Results
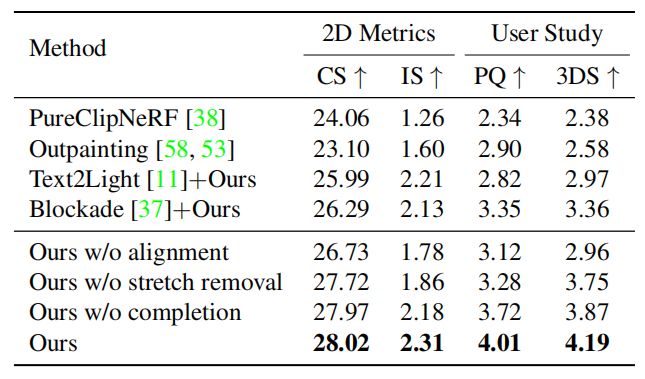
表1显示了多个场景的平均定量结果。论文为每个场景从新的视角渲染60幅图像,以计算二维指标。论文的方法获得了最高的分数,因为渲染从任意的新位姿都是完整的,满足给定的文本提示,且包含高分辨率的图像特征。
论文向用户展示来自每个场景的多个图像,就3D结构的完整性(问题1)和整体感知质量(问题2)进行打分,最终结果显示用户更喜欢论文的方法,它突出了该方法更加准确和完整的几何图形的质量,以及更加丰富的RGB纹理。
消融实验
Depth alignment creates seamless scenes
如上图a所示,来自后续帧的单目深度预测可能在尺度上不一致,场景的不同部分被撕裂开,不会融合成无缝网格。论文提出的深度对齐策略允许融合多帧生成的场景成一个无缝的网格,最终创建一个具有平面地板,墙壁,天花板,没有洞的完整的场景。
Stretch removal creates undistorted scene geometry
如上图b所示,没有三角化过程中边缘和表面法线阈值,许多面被不自然地拉伸。论文提出了两个滤波器(边缘长度和表面法线阈值)来缓解这个问题。
Two-stage generation creates complete scenes
**如上图c所示,从预定义的轨迹生成场景后,场景仍然包含一些孔。**因为场景是随着时间的推移而形成的,所以不可能预先选择照相机的位姿,即查看所有未被观察到的区域。论文的方法在使用一个Two-Stage的相机视角选择,以创建一个没有孔洞的完整场景。
总结
论文展示了一种仅从文本输入生成纹理三维网格的方法。论文使用text-to-image的2D生成器来创建一个图像序列。论文的方法的核心洞察力是一个定制的视点选择,它允许创建一个具有无缝的几何图形和引人注目的纹理的3D网格。具体来说,论文通过使用深度对齐策略,将图像提升到一个尺度一致的三维场景中,该对齐策略迭代地将所有图像融合到网格中。论文的输出网格表示可以用经典的光栅化渲染pipeline的得到任意室内场景。研究者相信,论文的方法展示了大规模3D资产创建的一个令人兴奋的应用,它只需要文本作为输入。
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!