SELECT a1,a2,a3 FROM tableA Where condition 
能够看得出来,该语句是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成。分别相应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描写叙述的。
那么,SQL语句在实际的执行过程中是怎么处理的呢?一般的数据库系统先将读入的SQL语句(Query)先进行解析(Parse)。分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等等。这一步就能够推断SQL语句是否规范,不规范就报错,规范就继续下一步过程绑定(Bind),这个过程将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定,假设相关的Projection、Data Source等等都是存在的话,就表示这个SQL语句是能够运行的;而在运行前,一般的数据库会提供几个运行计划,这些计划一般都有运行统计数据。数据库会在这些计划中选择一个最优计划(Optimize)。终于运行该计划(Execute)。并返回结果。当然在实际的运行过程中。是按Operation-->Data Source-->Result的次序来进行的。和SQL语句的次序刚好相反。在执行过程有时候甚至不须要读取物理表就能够返回结果,比方又一次执行刚执行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。


以下我们先来看看sparkSQL中的两个重要概念Tree和Rule、然后再介绍一下sparkSQL的两个分支sqlContext和hiveContext、最后再综合看看sparkSQL的优化器Catalyst。
- Tree的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees
- Logical Plans、Expressions、Physical Operators都能够使用Tree表示
- Tree的详细操作是通过TreeNode来实现的
- sparkSQL定义了catalyst.trees的日志,通过这个日志能够形象的表示出树的结构
- TreeNode能够使用scala的集合操作方法(如foreach, map, flatMap, collect等)进行操作
- 有了TreeNode,通过Tree中各个TreeNode之间的关系,能够对Tree进行遍历操作,如使用transformDown、transformUp将Rule应用到给定的树段,然后用结果替代旧的树段;也能够使用transformChildrenDown、transformChildrenUp对一个给定的节点进行操作,通过迭代将Rule应用到该节点以及子节点。

- TreeNode能够细分成三种类型的Node:
- UnaryNode 一元节点。即仅仅有一个子节点。如Limit、Filter操作
- BinaryNode 二元节点。即有左右子节点的二叉节点。如Jion、Union操作
- LeafNode 叶子节点,没有子节点的节点。主要用户命令类操作。如SetCommand

- Rule的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules
- Rule在sparkSQL的Analyzer、Optimizer、SparkPlan等各个组件中都有应用到
- Rule是一个抽象类。详细的Rule实现是通过RuleExecutor完毕
- Rule通过定义batch和batchs,能够简便的、模块化地对Tree进行transform操作
- Rule通过定义Once和FixedPoint。能够对Tree进行一次操作或多次操作(如对某些Tree进行多次迭代操作的时候。达到FixedPoint次数迭代或达到前后两次的树结构没变化才停止操作,详细參看RuleExecutor.apply)
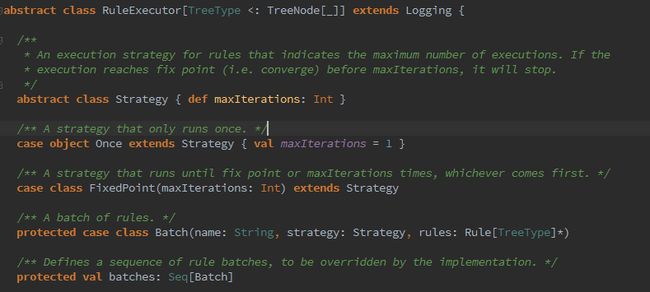


sparkSQL有两个分支,sqlContext和hivecontext,sqlContext如今仅仅支持sql语法解析器(SQL-92语法)。hiveContext如今支持sql语法解析器和hivesql语法解析器。默觉得hivesql语法解析器,用户能够通过配置切换成sql语法解析器,来执行hiveql不支持的语法,如select 1。关于sqlContext和hiveContext的详细应用请參看第六部分。
/**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
def sql(sqlText: String): SchemaRDD = {
if (dialect == "sql") {
new SchemaRDD(this, parseSql(sqlText)) //parseSql(sqlText)对sql语句进行语法解析
} else {
sys.error(s"Unsupported SQL dialect: $dialect")
}
}/**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
protected[sql] val parser = new catalyst.SqlParser
protected[sql] def parseSql(sql: String): LogicalPlan = parser(sql)
/**源自sql/core/src/main/scala/org/apache/spark/sql/SchemaRDD.scala */
class SchemaRDD(
@transient val sqlContext: SQLContext,
@transient val baseLogicalPlan: LogicalPlan)
extends RDD[Row](sqlContext.sparkContext, Nil) with SchemaRDDLike/**源自sql/core/src/main/scala/org/apache/spark/sql/SchemaRDDLike.scala */
private[sql] trait SchemaRDDLike {
@transient val sqlContext: SQLContext
@transient val baseLogicalPlan: LogicalPlan
private[sql] def baseSchemaRDD: SchemaRDD
lazy val queryExecution = sqlContext.executePlan(baseLogicalPlan)/**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =
new this.QueryExecution { val logical = plan }/**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
protected abstract class QueryExecution {
def logical: LogicalPlan
//对Unresolved LogicalPlan进行analyzer。生成resolved LogicalPlan
lazy val analyzed = ExtractPythonUdfs(analyzer(logical))
//对resolved LogicalPlan进行optimizer,生成optimized LogicalPlan
lazy val optimizedPlan = optimizer(analyzed)
// 将optimized LogicalPlan转换成PhysicalPlan
lazy val sparkPlan = {
SparkPlan.currentContext.set(self)
planner(optimizedPlan).next()
}
// PhysicalPlan运行前的准备工作,生成可运行的物理计划
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
//运行可运行物理计划
lazy val toRdd: RDD[Row] = executedPlan.execute()
......
}- SQL语句经过SqlParse解析成UnresolvedLogicalPlan。
- 使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
- 使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
- 使用SparkPlan将LogicalPlan转换成PhysicalPlan。
- 使用prepareForExecution()将PhysicalPlan转换成可运行物理计划。
- 使用execute()运行可运行物理计划;
- 生成SchemaRDD。

/**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
override def sql(sqlText: String): SchemaRDD = {
// 使用spark.sql.dialect定义採用的语法解析器
if (dialect == "sql") {
super.sql(sqlText) //假设使用sql解析器。则使用sqlContext的sql方法
} else if (dialect == "hiveql") { //假设使用和hiveql解析器,则使用HiveQl.parseSql
new SchemaRDD(this, HiveQl.parseSql(sqlText))
} else {
sys.error(s"Unsupported SQL dialect: $dialect. Try 'sql' or 'hiveql'")
}
}/**源自src/main/scala/org/apache/spark/sql/hive/HiveQl.scala */
/** Returns a LogicalPlan for a given HiveQL string. */
def parseSql(sql: String): LogicalPlan = {
try {
if (条件) {
//非hive命令的处理,如set、cache table、add jar等直接转化成command类型的LogicalPlan
.....
} else {
val tree = getAst(sql)
if (nativeCommands contains tree.getText) {
NativeCommand(sql)
} else {
nodeToPlan(tree) match {
case NativePlaceholder => NativeCommand(sql)
case other => other
}
}
}
} catch {
//异常处理
......
}
}- 首先考虑一些非hive语句的处理,这些命令属于sparkSQL本身的命令语句,如设置sparkSQL执行參数的set命令、cache table、add jar等,将这些语句转换成command类型的LogicalPlan;
- 假设是hive语句,则调用getAst(sql)使用hive的ParseUtils将该语句先解析成AST树,然后依据AST树中的keyword进行转换:类似命令型的语句、DDL类型的语句转换成command类型的LogicalPlan;其它的转换通过nodeToPlan转换成LogicalPlan。
/**源自src/main/scala/org/apache/spark/sql/hive/HiveQl.scala */
/** * Returns the AST for the given SQL string. */
def getAst(sql: String): ASTNode = ParseUtils.findRootNonNullToken((new ParseDriver).parse(sql))/**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
override protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =
new this.QueryExecution { val logical = plan }/**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
protected[sql] abstract class QueryExecution extends super.QueryExecution {
// TODO: Create mixin for the analyzer instead of overriding things here.
override lazy val optimizedPlan =
optimizer(ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed))))
override lazy val toRdd: RDD[Row] = executedPlan.execute().map(_.copy())
......
}/**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
/* A catalyst metadata catalog that points to the Hive Metastore. */
@transient
override protected[sql] lazy val catalog = new HiveMetastoreCatalog(this) with OverrideCatalog {
override def lookupRelation(
databaseName: Option[String],
tableName: String,
alias: Option[String] = None): LogicalPlan = {
LowerCaseSchema(super.lookupRelation(databaseName, tableName, alias))
}
}/**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
/* An analyzer that uses the Hive metastore. */
@transient
override protected[sql] lazy val analyzer =
new Analyzer(catalog, functionRegistry, caseSensitive = false)/**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
@transient
override protected[sql] val planner = hivePlanner- SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析。
- 使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定。生成resolved LogicalPlan;
- 使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
- 使用hivePlanner将LogicalPlan转换成PhysicalPlan;
- 使用prepareForExecution()将PhysicalPlan转换成可运行物理计划;
- 使用execute()运行可运行物理计划。
- 运行后,使用map(_.copy)将结果导入SchemaRDD。
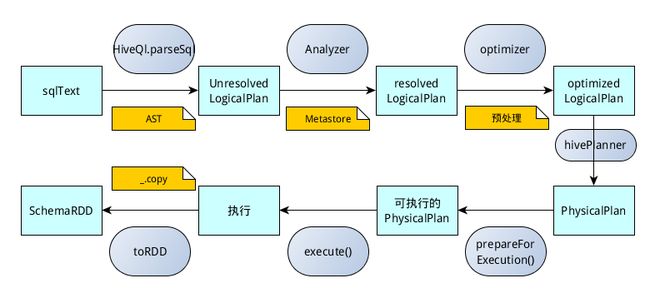
- core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
- catalyst处理查询语句的整个处理过程,包含解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
- hive对hive数据的处理
- hive-ThriftServer提供CLI和JDBC/ODBC接口
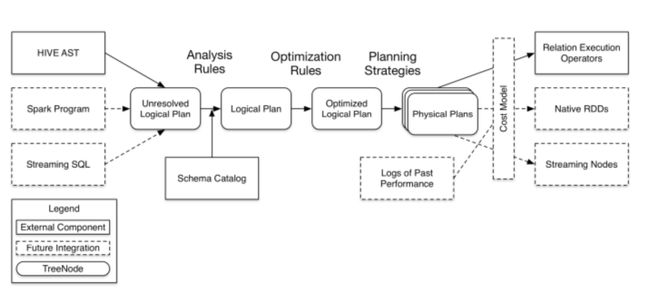
从上图看,catalyst基本的实现组件有:
- sqlParse。完毕sql语句的语法解析功能,眼下仅仅提供了一个简单的sql解析器;
- Analyzer,主要完毕绑定工作,将不同来源的Unresolved LogicalPlan和数据元数据(如hive metastore、Schema catalog)进行绑定。生成resolved LogicalPlan;
- optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan。
- Planner将LogicalPlan转换成PhysicalPlan;
- CostModel,主要依据过去的性能统计数据。选择最佳的物理运行计划
- 先将sql语句通过解析生成Tree,然后在不同阶段使用不同的Rule应用到Tree上。通过转换完毕各个组件的功能。
- Analyzer使用Analysis Rules,配合数据元数据(如hive metastore、Schema catalog),完好Unresolved LogicalPlan的属性而转换成resolved LogicalPlan;
- optimizer使用Optimization Rules,对resolved LogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan。
- Planner使用Planning Strategies,对optimized LogicalPlan