Elasticsearch 入门 核心概念 数据结构 分词器 javaAPI
ElasticSearch
- 1-今日内容
-
- 2-初识ElasticSearch
-
- 2.1-基于数据库查询的问题
- 2.2-倒排索引
-
- 2.2.1 评分TF/IDF/BM25计算
- 2.3-ES存储和查询的原理
- 3-安装ElasticSearch
-
- Kibana安装
- 4-ElasticSearch核心概念
-
- ES数据类型Mapping
-
- 1 概念:
- 2 查看mapping
- 3 ES数据类型
- 4 两种映射类型
- Dynamic field mapping:
- 整数 => long
- 浮点数 => float
- true || false =>boolean
- 日期 =>date
- 数组 => 取决于数组中的第一个有效值
- 对象 => object
- 字符串 => 如果不是数字和日期类型,那会被映射为text和keyword两个类型
- Expllcit field mapping:手动映射
- 5 映射参数
- 5 简单使用
- 5-脚本操作ES
-
- 5.1-RESTful风格介绍
- 5.2-操作索引
- 5.3-ES数据类型
- 5.4-操作映射
- 5.5-操作文档
- 6-分词器
-
- 6.2-ik分词器安装
- 1、环境准备
- 2、安装IK分词器
- 3、使用IK分词器
- 6.3-ik分词器使用
- 6.4使用IK分词器-查询文档
- 7-ElasticSearch JavaApi
-
- 7.1SpringBoot整合ES
1-今日内容
- 初识 ElasticSearch
- 安装 ElasticSearch
- ElasticSearch 核心概念
- 操作 ElasticSearch
- ElasticSearch JavaAPI
2-初识ElasticSearch
2.1-基于数据库查询的问题

2.2-倒排索引
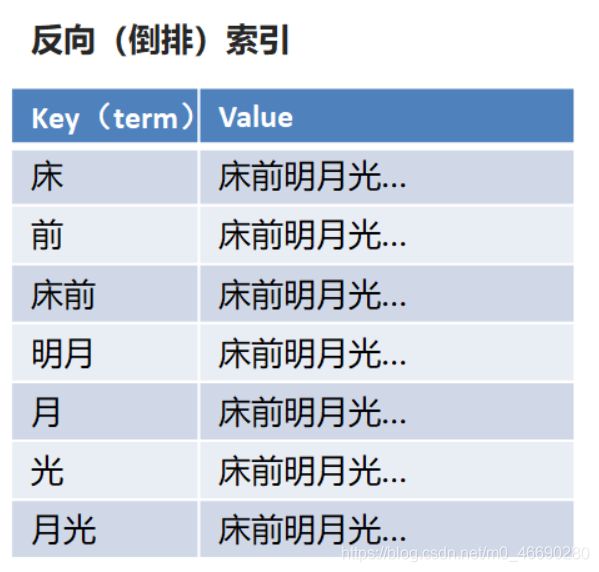
倒排索引:将文档进行分词,形成词条和id的对应关系即为反向索引。
以唐诗为例,所处包含“前”的诗句
正向索引:由《静夜思》–>窗前明月光—>“前”字
反向索引:“前”字–>窗前明月光–>《静夜思》
反向索引的实现就是对诗句进行分词,分成单个的词,由词推据,即为反向索引
“床前明月光”–> 分词
将一段文本按照一定的规则,拆分为不同的词条(term)

2.2.1 评分TF/IDF/BM25计算
每条搜索记录ES都会给出一个评分,ES有两个打分计算方式:
- TF: Term Frequency,即词频。它表示一个词在内容中出现的次数。定义:
TF = 某个词在文档中出现的次数 / 文档的总词数
某个词出现越多,表示越重要,如果某篇文章出现了elasticsearch多次, 而spring出现了两三次,
那很可能就是一篇关于elasticsearch的专业文章。
2. IDF: Inverse Document Frequency,即逆文档频率,它是一个表达词语重要性的指标。计算公式:
IDF=log(库中的文档数/(包含该词的文档数+1))
log为对数函数,如果所有文章内容都包涵某一个词,那这个词的IDF=log(1)=0, 重要性为零。停用词的IDF约等于0。
如果某个词只在很少的文章中出现,则IDF很大,其重要性也越高。为了避免分母为0,所以+1.
-
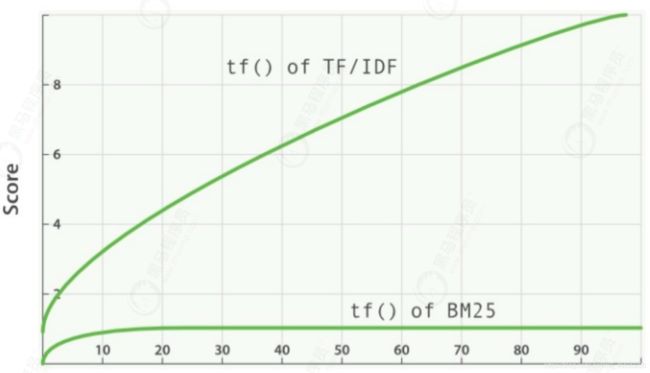
BM25
BM25 实质是对 TF-IDF 算法的改进,对于 TF-IDF 算法,TF(t) 部分的值越大,整个公式返回的值就会越大。
随着TF(t) 的逐步加大,该算法的返回值会趋于一个数值,BM25 就针对这点进行来优化。
例如, 某个文章的关键词出现的频率不断增多, 得分就会越来越高, 有的文章关键词出现40次,和有的文章关键词出现60次或80次, 但实际上出现40次的文章,可能就是所期望的结果。
-
查看ES评分计算:
增加explain标识为true,会列出计算执行计划:
GET hotel/_search
{
"explain": true,
"query":{
"match":{
"name":"北京市东城区七天酒店"
}
}
}
里面会详细记录评分细则:
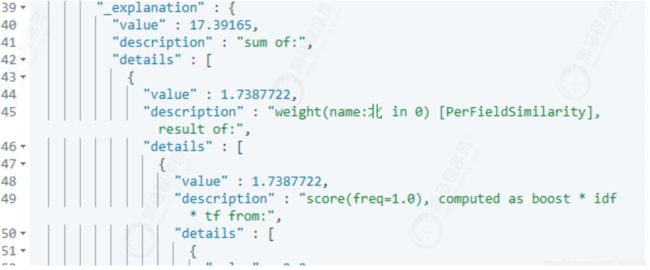
整个评分计算: boost * idf * tf (boost为放大系数, 默认为2.2)
BM25的计算在tf的描述中: (freq + k1 * (1 - b + b * dl / avgdl))
2.3-ES存储和查询的原理
index(索引):相当于mysql的库
映射:相当于mysql 的表结构
document(文档):相当于mysql的表中的数据
数据库查询存在的问题:
- 性能低:使用模糊查询,左边有通配符,不会走索引,会全表扫描,性能低
- 功能弱:如果以”华为手机“作为条件,查询不出来数据
Es使用倒排索引,对title 进行分词

3-安装ElasticSearch
1、上传ElasticSearch安装包
alt+p # 打开sftp窗口
# 上传es安装包
put e:/software/elasticsearch-7.4.0-linux-x86_64.tar.gz

2、执行解压操作 ,如下图
# 将elasticsearch-7.4.0-linux-x86_64.tar.gz解压到opt文件夹下. -C 大写
tar -zxvf elasticsearch-7.4.0-linux-x86_64.tar.gz -C /opt
3、创建普通用户
因为安全问题,Elasticsearch 不允许root用户直接运行,所以要创建新用户,在root用户中创建新用户,执行如下命令:
useradd itheima # 新增itheima用户
passwd itheima # 为itheima用户设置密码
5、为新用户授权,如下图
chown -R itheima:itheima /opt/elasticsearch-7.4.0 #文件夹所有者

将 /opt/elasticsearch-7.4.0文件夹授权给itheima用户,由上图可见,我们的文件夹权限赋给了itheima
6、修改elasticsearch.yml文件
vim /opt/elasticsearch-7.4.0/config/elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
cluster.name: my-application
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
cluster.name:配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称
node.name:节点名,elasticsearch会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
network.host:设置为0.0.0.0允许外网访问
http.port:Elasticsearch的http访问端口
cluster.initial_master_nodes:初始化新的集群时需要此配置来选举master
7、修改配置文件
新创建的itheima用户最大可创建文件数太小,最大虚拟内存太小,切换到root用户,编辑下列配置文件, 添加类似如下内容
# 切换到root用户
su root
#1. ===最大可创建文件数太小=======
vim /etc/security/limits.conf
# 在文件末尾中增加下面内容
itheima soft nofile 65536
itheima hard nofile 65536
# =====
vim /etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容
itheima soft nofile 65536
itheima hard nofile 65536
* hard nproc 4096
# 注:* 代表Linux所有用户名称
#2. ===最大虚拟内存太小=======
vim /etc/sysctl.conf
# 在文件中增加下面内容
vm.max_map_count=655360
# 重新加载,输入下面命令:
sysctl -p
指定JDK版本
- 最新版的ElasticSearch需要JDK11版本, 下载JDK11压缩包, 并进行解压。
- 修改环境配置文件
vi bin/elasticsearch-env
参照以下位置, 追加一行, 设置JAVA_HOME, 指定JDK11路径。
JAVA_HOME=/usr/local/jdk-11.0.11
# now set the path to java
if [ ! -z "$JAVA_HOME" ]; then
JAVA="$JAVA_HOME/bin/java"
else
if [ "$(uname -s)" = "Darwin" ]; then
# OSX has a different structure
JAVA="$ES_HOME/jdk/Contents/Home/bin/java"
else
JAVA="$ES_HOME/jdk/bin/java"
fi
fi
8、启动elasticsearch
su itheima # 切换到itheima用户启动
cd /opt/elasticsearch-7.4.0/bin
./elasticsearch #启动

通过上图我们可以看到elasticsearch已经成功启动
在访问elasticsearch前,请确保防火墙是关闭的,执行命令:
#暂时关闭防火墙
systemctl stop firewalld
# 或者
#永久设置防火墙状态
systemctl enable firewalld.service #打开防火墙永久性生效,重启后不会复原
systemctl disable firewalld.service #关闭防火墙,永久性生效,重启后不会复原
浏览器输入http://192.168.149.135:9200/,如下图

此时elasticsearch已成功启动:
重点几个关注下即可:
number" : "7.4.0" 表示elasticsearch版本
lucene_version" : "8.2.0" 表示lucene版本
name : 默认启动的时候指定了 ES 实例名称
cluster_name : 默认名为 elasticsearch
`访问地址:/_cat/health
启动状态有green、yellow和red。 green是代表启动正常。
Kibana安装
1、什么是Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。
2、上传kibana
CRT中克隆一个窗口,上传Kibana
put E:\software\kibana-7.4.0-linux-x86_64.tar.gz
2、解压kibana
tar -xzf kibana-7.4.0-linux-x86_64.tar.gz -C /opt
解压到当前目录(/opt)下
3、修改kibana配置
vim /opt/kibana-7.4.0-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "kibana-itcast"
elasticsearch.hosts: ["http://127.0.0.1:9200"]
elasticsearch.requestTimeout: 99999
server.port:http访问端口
server.host:ip地址,0.0.0.0表示可远程访问
server.name:kibana服务名
elasticsearch.hosts:elasticsearch地址
elasticsearch.requestTimeout:请求elasticsearch超时时间,默认为30000,此处可根据情况设置
4、启动kibana
由于kibana不建议使用root用户启动,如果用root启动,需要加–allow-root参数
# 切换到kibana的bin目录
cd /opt/kibana-7.4.0-linux-x86_64/bin
# 启动
./kibana --allow-root

启动成功。
5、访问kibana
1.浏览器输入http://192.168.149.135:5601/,如下图:
http://192.168.149.135:5601/

看到这个界面,说明Kibanan已成功安装。
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools:Console控制台(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
4-ElasticSearch核心概念
Elasticsearch是实时的分布式搜索分析引擎,内部使用Lucene做索引与搜索
- 实时性:新增到 ES 中的数据在1秒后就可以被检索到,这种新增数据对搜索的可见性称为“准 实时搜索”
- 分布式:意味着可以动态调整集群规模,弹性扩容
- 集群规模:可以扩展到上百台服务器,处理PB级结构化或非结构化数据
- 各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作
Lucene是Java语言编写的全文搜索框架,用于处理纯文本的数据,但它只是一个库,提供建立索引、执行搜索等接口,但不包含分布式服务,这些正是 ES 做的
ElasticSearch使用场景
ElasticSearch广泛应用于各行业领域, 比如维基百科, GitHub的代码搜索,电商网站的大数据日志统计分析, BI系统报表统计分析等。
- 提供分布式的搜索引擎和数据分析引擎
比如百度,网站的站内搜索,IT系统的检索, 数据分析比如热点词统计, 电商网站商品TOP
排名等。
- 全文检索,结构化检索,数据分析
支持全文检索, 比如查找包含指定名称的商品信息; 支持结构检索, 比如查找某个分类下的
所有商品信息;
还可以支持高级数据分析, 比如统计某个商品的点击次数, 某个商品有多少用户购买等等。
- 支持海量数据准实时的处理
采用分布式节点, 将数据分散到多台服务器上去存储和检索, 实现海量数据的处理, 比如统
计用户的行为日志, 能够在秒级别对数据进行检索和分析
ElasticSearch基本概念介绍
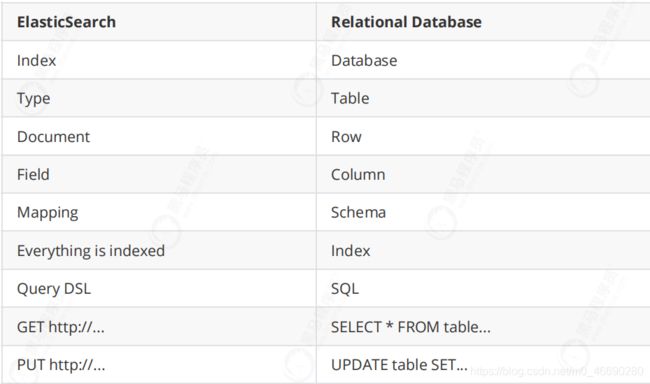
- 索引(Index)
相比传统的关系型数据库,索引相当于SQL中的一个【数据库】,或者一个数据存储方案
(schema)。
- 类型(Type)
一个索引内部可以定义一个或多个类型, 在传统关系数据库来说, 类型相当于【表】的概
念。
- 文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,采用JSON格式表
示。相当于传统数据库【行】概念
- 集群(Cluster)
集群是由一台及以上主机节点组成并提供存储及搜索服务, 多节点组成的集群拥有冗余能
力,它可以在一个或几个节点出现故障时保证服务的整体可用性。
- 节点(Node)
Node为集群中的单台节点,其可以为master节点亦可为slave节点(节点属性由集群内部选
举得出)并提供存储相关数据的功能
- 切片(shards)
切片是把一个大文件分割成多个小文件然后分散存储在集群中的多个节点上, 可以将其看作
mysql的分库分表概念。 Shard有两种类型:primary主片和replica副本,primary用于文档
存储,每个新的索引会自动创建5个Primary shard;Replica shard是Primary Shard的副
本,用于冗余数据及提高搜索性能。

注意: ES7之后Type被舍弃,只有Index(等同于数据库+表定义)和Document(文档,行记
录)。
ES数据类型Mapping
1 概念:
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。分词器、评分等概念在后面的课程讲解。
2 查看mapping
GET /index/_mappings
3 ES数据类型
① 常见类型
1) 数字类型:
long integer short byte double float half_float scaled_float unsigned_long
2) Keywords:
keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。Id应该用keyword
constant_keyword:始终包含相同值的关键字字段
wildcard:可针对类似grep的通配符查询优化日志行和类似的关键字值
关键字字段通常用于排序, 汇总和Term查询,例如term。
3) Dates(时间类型):包括date和 date_nanos
4) alias:为现有字段定义别名。
5) binary(二进制):binary
6) range(区间类型):integer_range、float_range、long_range、double_range、date_range
7) text:当一个字段是要被全文搜索的,比如Email内容、产品描述,这些字段应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索 引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。(解释一下为啥不会为text创建正排索引:大量堆空间,尤其是 在加载高基数text字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问 题。这就是默认情况下禁用字段数据的原因)
② 对象关系类型:
1) object:用于单个JSON对象
2) nested:用于JSON对象数组
3) flattened:允许将整个JSON对象索引为单个字段。
③ 结构化类型:
1) geo-point:纬度/经度积分
2) geo-shape:用于多边形等复杂形状
3) point:笛卡尔坐标点
2) shape:笛卡尔任意几何图形
④ 特殊类型:
1) IP地址:ip 用于IPv4和IPv6地址
2) completion:提供自动完成建议
3) tocken_count:计算字符串中令牌的数量
4) murmur3:在索引时计算值的哈希并将其存储在索引中
5) annotated-text:索引包含特殊标记的文本(通常用于标识命名实体)
6) percolator:接受来自query-dsl的查询
7) join:为同一索引内的文档定义父/子关系
8) rank features:记录数字功能以提高查询时的点击率。
9) dense vector:记录浮点值的密集向量。
10) sparse vector:记录浮点值的稀疏向量。
11) search-as-you-type:针对查询优化的文本字段,以实现按需输入的完成
12) histogram:histogram 用于百分位数聚合的预聚合数值。
13) constant keyword:keyword当所有文档都具有相同值时的情况的 专业化。
⑤ array(数组):在Elasticsearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值都必须具有 相同的数据类型。
⑥新增:
1) date_nanos:date plus 纳秒
2) features:
4 两种映射类型
-
Dynamic field mapping:
-
整数 => long
-
浮点数 => float
-
true || false =>boolean
-
日期 =>date
-
-
-
-
数组 => 取决于数组中的第一个有效值
-
对象 => object
-
字符串 => 如果不是数字和日期类型,那会被映射为text和keyword两个类型
除了上述字段类型之外,其他类型都必须显示映射,也就是必须手工指定,因为其他类型ES无法自动识别。
-
-
Expllcit field mapping:手动映射
PUT /product { "mappings": { "properties": { "field": { "mapping_parameter": "parameter_value" } } } }
5 映射参数
① index:是否对创建对当前字段创建倒排索引,默认true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在source元数据中展示
② analyzer:指定分析器(character filter、tokenizer、Token filters)。
③ boost:对当前字段相关度的评分权重,默认1
④ coerce:是否允许强制类型转换 true “1”=> 1 false “1”=< 1
⑤ copy_to:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询
⑥ doc_values:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘 空间(不支持text和annotated_text)
⑦ dynamic:控制是否可以动态添加新字段
1) true 新检测到的字段将添加到映射中。(默认)
2) false 新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式 添加新字段。
3) strict 如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射中
⑧ eager_global_ordinals:用于聚合的字段上,优化聚合性能。
1) Frozen indices(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据, Frozen indices的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能 是秒级或者分钟级。*eager_global_ordinals不适用于Frozen indices*
⑨ enable:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,让然可以检索并在_source元数据中展示,谨慎使用,该状态无法 修改。
PUT my_index
{
"mappings": {
"enabled": false
}
}
⑩ fielddata:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中
⑪ fields:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)
⑫ format:格式化
"date": {
"type": "date",
"format": "yyyy-MM-dd"
}
⑬ ignore_above:超过长度将被忽略
⑭ ignore_malformed:忽略类型错误
⑮ index_options:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段
⑯ Index_phrases:提升exact_value查询速度,但是要消耗更多磁盘空间
⑰ Index_prefixes:前缀搜索
1) min_chars:前缀最小长度,>0,默认2(包含)
2) max_chars:前缀最大长度,<20,默认5(包含)
⑱ meta:附加元数据
⑲ normalizer:
⑳ norms:是否禁用评分(在filter和聚合字段上应该禁用)。
21 null_value:为null值设置默认值
22 position_increment_gap:
23 proterties:除了mapping还可用于object的属性设置
24 search_analyzer:设置单独的查询时分析器:
25 similarity:为字段设置相关度算法,支持BM25、claassic(TF-IDF)、boolean
26 store:设置字段是否仅查询
27 term_vector:运维参数
5 简单使用
- String 类型
主要分为text与keyword两种类型。两者区别主要在于能否分词。 - text类型
会进行分词处理, 分词器默认采用的是standard。 - keyword类型
不会进行分词处理。在ES的倒排索引中存储的是完整的字符串。
- Date时间类型
数据库里的日期类型需要规范具体的传入格式, ES是可以控制,自适应处理。
传递不同的时间类型:
PUT my_date_index/_doc/1
{"date":"2021-01-01"}
PUT my_date_index/_doc/2
{"date":"2021-01-01T12:10:30Z"}
PUT my_date_index/_doc/3
{"date":1520071600001}
GET my_date_index/_search
查看日期数据:
GET my_date_index/_mapping

ES的Date类型允许可以使用的格式有:
yyyy-MM-dd HH:mm:ss
yyyy-MM-dd
epoch_millis(毫秒值)
- 复合类型
复杂类型主要有三种: Array、object、nested。
Array类型: 在Elasticsearch中,数组不需要声明专用的字段数据类型。但是,在数组中的所
有值都必须具有相同的数据类型。举例:
POST orders/_doc/1
{
"goodsName":["足球","篮球","兵乓球", 3]
}
POST orders/_doc/1
{
"goodsName":["足球","篮球","兵乓球"]
}
object类型: 用于存储单个JSON对象, 类似于JAVA中的对象类型, 可以有多个值, 比如
LIST,可以包含多个对象。
但是LIST只能作为整体, 不能独立的索引查询。举例:
# 新增第一组数据, 组别为美国,两个人。
POST my_index/_doc/1
{
"group" : "america",
"users" : [
{
"name" : "John",
"age" : "22"
},
{
"name" : "Alice",
"age" : "21"
}
]
}
# 新增第二组数据, 组别为英国, 两个人。
POST my_index/_doc/2
{
"group" : "england",
"users" : [
{
"name" : "lucy",
"age" : "21"
},
{
"name" : "John",
"age" : "32"
}
]
}
这两组数据都包含了name为John,age为21的数据,
采用这个搜索条件, 实际结果:
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "John"
}
},
{
"match": {
"users.age": 21
}
}
]
}
}
}
结果可以看到, 这两组数据都能找出,因为每一组数据都是作为一个整体进行搜索匹配, 而
非具体某一条数据。
Nested类型
用于存储多个JSON对象组成的数组, nested 类型是 object 类型中的一个特例,可以让对
象数组独立索引和查询。
举例:
创建nested类型的索引:
PUT my_index
{
"mappings": {
"properties": {
"users": {
"type": "nested"
}
}
}
}
发出查询请求:
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "users",
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "John"
}
},
{
"match": {
"users.age": "21"
}
}
]
}
}
}
}
]
}
}
}
采用以前的条件, 这个时候查不到任何结果, 将年龄改成22, 就可以找出对应的数据:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.89712,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.89712,
"_source" : {
"group" : "america",
"users" : [
{
"name" : "John",
"age" : "22"
},
{
"name" : "Alice",
"age" : "21"
}
]
}
}
]
}
}
- GEO地理位置类型
现在大部分APP都有基于位置搜索的功能, 比如交友、购物应用等。这些功能是基于GEO搜
索实现的。
对于GEO地理位置类型,分为地图:Geo-point, 和形状:Geo-shape 两种类型

创建地理位置索引:
PUT my_locations
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
添加地理位置数据:
# 采用object对象类型
PUT my_locations/_doc/1
{
"user": "张三",
"text": "Geo-point as an object",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
# 采用string类型
PUT my_locations/_doc/2
{
"user": "李四",
"text": "Geo-point as a string",
"location": "45.12,-75.34"
}
# 采用geohash类型(geohash算法可以将多维数据映射为一串字符)
PUT my_locations/_doc/3
{
"user": "王二麻子",
"text": "Geo-point as a geohash",
"location": "drm3btev3e86"
}
# 采用array数组类型
PUT my_locations/_doc/4
{
"user": "木头老七",
"text": "Geo-point as an array",
"location": [
-80.34,
51.12
]
}
需求:搜索出距离我{“lat” : 40,“lon” : -70} 200km范围内的人
GET my_locations/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"location": {
"lat": 40,
"lon": -70
}
}
}
}
}
}
5-脚本操作ES
5.1-RESTful风格介绍
1.ST(Representational State Transfer),表述性状态转移,是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful。就是一种定义接口的规范。
2.基于HTTP。
3.使用XML格式定义或JSON格式定义。
4.每一个URI代表1种资源。
5.客户端使用GET、POST、PUT、DELETE 4个表示操作方式的动词对服务端资源进行操作:
GET:用来获取资源
POST:用来新建资源(也可以用于更新资源)
PUT:用来更新资源
DELETE:用来删除资源

5.2-操作索引
PUT
http://ip:端口/索引名称
查询
GET http://ip:端口/索引名称 # 查询单个索引信息
GET http://ip:端口/索引名称1,索引名称2... # 查询多个索引信息
GET http://ip:端口/_all # 查询所有索引信息
•删除索引
DELETE http://ip:端口/索引名称
•关闭、打开索引
POST http://ip:端口/索引名称/_close
POST http://ip:端口/索引名称/_open
5.3-ES数据类型
- 简单数据类型
- 字符串
聚合:相当于mysql 中的sum(求和)
text:会分词,不支持聚合
keyword:不会分词,将全部内容作为一个词条,支持聚合
-
数值
-
布尔:boolean
-
二进制:binary
-
范围类型
integer_range, float_range, long_range, double_range, date_range
- 日期:date
- 复杂数据类型
•数组:[ ] Nested: nested (for arrays of JSON objects 数组类型的JSON对象)
•对象:{ } Object: object(for single JSON objects 单个JSON对象)
5.4-操作映射
PUT person
GET person
#添加映射
PUT /person/_mapping
{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
#创建索引并添加映射
#创建索引并添加映射
PUT /person1
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
GET person1/_mapping
添加字段
#添加字段
PUT /person1/_mapping
{
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
5.5-操作文档
•添加文档,指定id
POST /person1/_doc/2
{
"name":"张三",
"age":18,
"address":"北京"
}
GET /person1/_doc/1
•添加文档,不指定id
#添加文档,不指定id
POST /person1/_doc/
{
"name":"张三",
"age":18,
"address":"北京"
}
#查询所有文档
GET /person1/_search
#删除指定id文档
DELETE /person1/_doc/1
6-分词器
•IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包
•是一个基于Maven构建的项目
•具有60万字/秒的高速处理能力
•支持用户词典扩展定义
•下载地址:https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
安装包在资料文件夹中提供
6.2-ik分词器安装
1、环境准备
Elasticsearch 要使用 ik,就要先构建 ik 的 jar包,这里要用到 maven 包管理工具,而 maven 需要java 环境,而 Elasticsearch 内置了jdk, 所以可以将JAVA_HOME设置为Elasticsearch 内置的jdk
1)设置JAVA_HOME
vim /etc/profile
# 在profile文件末尾添加
#java environment
export JAVA_HOME=/opt/elasticsearch-7.4.0/jdk
export PATH=$PATH:${JAVA_HOME}/bin
# 保存退出后,重新加载profile
source /etc/profile
2)下载maven安装包
wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.1.1/binaries/apache-maven-3.6.3-bin.tar.gz
3)解压maven安装包
tar xzf apache-maven-3.6.3-bin.tar.gz
4)设置软连接
ln -s apache-maven-3.6.3 maven
5)设置path
打开文件
vim /etc/profile.d/maven.sh
将下面的内容复制到文件,保存
export MAVEN_HOME=/opt/maven
export PATH=${MAVEN_HOME}/bin:${PATH}
设置好Maven的路径之后,需要运行下面的命令使其生效
source /etc/profile.d/maven.sh
6)验证maven是否安装成功
mvn -v
2、安装IK分词器
1)下载IK
wget https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
执行如下图:
2)解压IK
由于这里是zip包不是gz包,所以我们需要使用unzip命令进行解压,如果本机环境没有安装unzip,请执行:
yum install zip
yum install unzip
解压IK
unzip v7.4.0.zip
3)编译jar包
# 切换到 elasticsearch-analysis-ik-7.4.0目录
cd elasticsearch-analysis-ik-7.4.0/
#打包
mvn package
4) jar包移动
package执行完毕后会在当前目录下生成target/releases目录,将其中的elasticsearch-analysis-ik-7.4.0.zip。拷贝到elasticsearch目录下的新建的目录plugins/analysis-ik,并解压
#切换目录
cd /opt/elasticsearch-7.4.0/plugins/
#新建目录
mkdir analysis-ik
cd analysis-ik
#执行拷贝
cp -R /opt/elasticsearch-analysis-ik-7.4.0/target/releases/elasticsearch-analysis-ik-7.4.0.zip /opt/elasticsearch-7.4.0/plugins/analysis-ik
#执行解压
unzip /opt/elasticsearch-7.4.0/plugins/analysis-ik/elasticsearch-analysis-ik-7.4.0.zip
5)拷贝辞典
将elasticsearch-analysis-ik-7.4.0目录下的config目录中的所有文件 拷贝到elasticsearch的config目录
cp -R /opt/elasticsearch-analysis-ik-7.4.0/config/* /opt/elasticsearch-7.4.0/config
记得一定要重启Elasticsearch!!!
3、使用IK分词器
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“乒乓球明年总冠军”拆分为“乒乓球、乒乓、球、明年、总冠军、冠军。
#方式一ik_max_word
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "乒乓球明年总冠军"
}
ik_max_word分词器执行如下:
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "乒乓",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "球",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "冠军",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}
2、ik_smart
会做最粗粒度的拆分,比如会将“乒乓球明年总冠军”拆分为乒乓球、明年、总冠军。
#方式二ik_smart
GET /_analyze
{
"analyzer": "ik_smart",
"text": "乒乓球明年总冠军"
}
ik_smart分词器执行如下:
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
由此可见 使用ik_smart可以将文本"text": "乒乓球明年总冠军"分成了【乒乓球】【明年】【总冠军】
这样看的话,这样的分词效果达到了我们的要求。
执行如下命令时如果出现 打包失败(501码)将maven镜像换成阿里云的
mvn package
/opt/apache-maven-3.6.3/conf/setting.xml
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
6.3-ik分词器使用
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“乒乓球明年总冠军”拆分为“乒乓球、乒乓、球、明年、总冠军、冠军。
#方式一ik_max_word
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "乒乓球明年总冠军"
}
ik_max_word分词器执行如下:
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "乒乓",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "球",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "冠军",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}
2、ik_smart
会做最粗粒度的拆分,比如会将“乒乓球明年总冠军”拆分为乒乓球、明年、总冠军。
#方式二ik_smart
GET /_analyze
{
"analyzer": "ik_smart",
"text": "乒乓球明年总冠军"
}
ik_smart分词器执行如下:
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
由此可见 使用ik_smart可以将文本"text": "乒乓球明年总冠军"分成了【乒乓球】【明年】【总冠军】
这样看的话,这样的分词效果达到了我们的要求。
6.4使用IK分词器-查询文档
•词条查询:term
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索
•全文查询:match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
1.创建索引,添加映射,并指定分词器为ik分词器
PUT person2
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
2.添加文档
POST /person2/_doc/1
{
"name":"张三",
"age":18,
"address":"北京海淀区"
}
POST /person2/_doc/2
{
"name":"李四",
"age":18,
"address":"北京朝阳区"
}
POST /person2/_doc/3
{
"name":"王五",
"age":18,
"address":"北京昌平区"
}
3.查询映射
GET person2
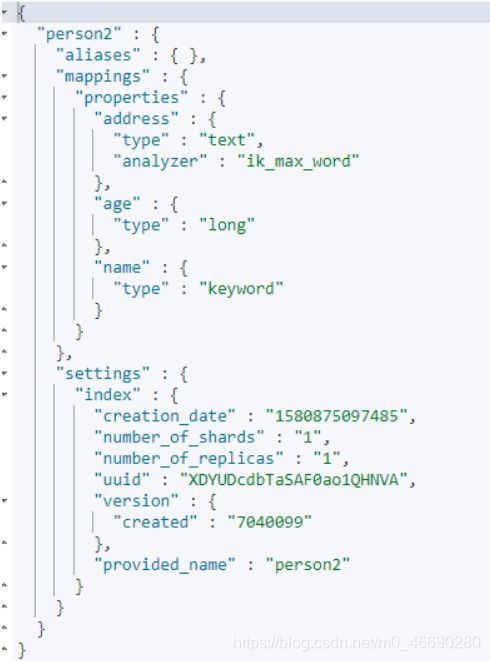
4.查看分词效果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "北京海淀"
}
5.词条查询:term
查询person2中匹配到"北京"两字的词条
GET /person2/_search
{
"query": {
"term": {
"address": {
"value": "北京"
}
}
}
}
6.全文查询:match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
GET /person2/_search
{
"query": {
"match": {
"address":"北京昌平"
}
}
}
7-ElasticSearch JavaApi
7.1SpringBoot整合ES
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.8.RELEASEversion>
<relativePath/>
parent>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.4.0version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
<version>7.4.0version>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>7.4.0version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.51version>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
config
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
private String host;
private int port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost(
"192.168.23.129",
9200,
"http"
)
));
}
}
Person
public class Person {
private String id;
private String name;
private int age;
private String address;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "Person{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
ElasticSearchApplication
@SpringBootApplication
public class ElasticSearchApplication {
public static void main(String[] args) {
SpringApplication.run(ElasticSearchApplication.class,args);
}
}
resources
elasticsearch:
host: 192.168.23.129
port: 9200
Elasticsearch
package com.itheima.elasticsearchdemo;
import com.alibaba.fastjson.JSON;
import com.itheima.domain.Person;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.cluster.metadata.MappingMetaData;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
@SpringBootTest
class ElasticsearchDemoApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
void contextLoads() {
/* //1.创建ES客户端对象
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost(
"192.168.149.135",
9200,
"http"
)
));*/
System.out.println(client);
}
/**
* 添加索引
*/
@Test
public void addIndex() throws IOException {
//1.使用client获取操作索引的对象
IndicesClient indicesClient = client.indices();
//2.具体操作,获取返回值
CreateIndexRequest createRequest = new CreateIndexRequest("itheima");
CreateIndexResponse response = indicesClient.create(createRequest, RequestOptions.DEFAULT);
//3.根据返回值判断结果
System.out.println(response.isAcknowledged());
}
/**
* 添加索引
*/
@Test
public void addIndexAndMapping() throws IOException {
//1.使用client获取操作索引的对象
IndicesClient indicesClient = client.indices();
//2.具体操作,获取返回值
CreateIndexRequest createRequest = new CreateIndexRequest("itcast");
//2.1 设置mappings
String mapping = "{\n" +
" \"properties\" : {\n" +
" \"address\" : {\n" +
" \"type\" : \"text\",\n" +
" \"analyzer\" : \"ik_max_word\"\n" +
" },\n" +
" \"age\" : {\n" +
" \"type\" : \"long\"\n" +
" },\n" +
" \"name\" : {\n" +
" \"type\" : \"keyword\"\n" +
" }\n" +
" }\n" +
" }";
createRequest.mapping(mapping,XContentType.JSON);
CreateIndexResponse response = indicesClient.create(createRequest, RequestOptions.DEFAULT);
//3.根据返回值判断结果
System.out.println(response.isAcknowledged());
}
/**
* 查询索引
*/
@Test
public void queryIndex() throws IOException {
IndicesClient indices = client.indices();
GetIndexRequest getReqeust = new GetIndexRequest("itcast");
GetIndexResponse response = indices.get(getReqeust, RequestOptions.DEFAULT);
//获取结果
Map<String, MappingMetaData> mappings = response.getMappings();
for (String key : mappings.keySet()) {
System.out.println(key+":" + mappings.get(key).getSourceAsMap());
}
}
/**
* 删除索引
*/
@Test
public void deleteIndex() throws IOException {
IndicesClient indices = client.indices();
DeleteIndexRequest deleteRequest = new DeleteIndexRequest("itheima");
AcknowledgedResponse response = indices.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
/**
* 判断索引是否存在
*/
@Test
public void existIndex() throws IOException {
IndicesClient indices = client.indices();
GetIndexRequest getRequest = new GetIndexRequest("itcast");
boolean exists = indices.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
/**
* 添加文档,使用map作为数据
*/
@Test
public void addDoc() throws IOException {
//数据对象,map
Map data = new HashMap();
data.put("address","北京昌平");
data.put("name","大胖");
data.put("age",20);
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("itcast").id("1").source(data);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}
/**
* 添加文档,使用对象作为数据
*/
@Test
public void addDoc2() throws IOException {
//数据对象,javaObject
Person p = new Person();
p.setId("2");
p.setName("小胖2222");
p.setAge(30);
p.setAddress("陕西西安");
//将对象转为json
String data = JSON.toJSONString(p);
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("itcast").id(p.getId()).source(data,XContentType.JSON);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}
/**
* 修改文档:添加文档时,如果id存在则修改,id不存在则添加
*/
@Test
public void updateDoc() throws IOException {
}
/**
* 根据id查询文档
*/
@Test
public void findDocById() throws IOException {
GetRequest getReqeust = new GetRequest("itcast","1");
//getReqeust.id("1");
GetResponse response = client.get(getReqeust, RequestOptions.DEFAULT);
//获取数据对应的json
System.out.println(response.getSourceAsString());
}
/**
* 根据id删除文档
*/
@Test
public void delDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("itcast","1");
DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
}