SCI、中科院1区算法应用:(BWO-CNN-BiGRU-Attention)白鲸优化深度学习-融合注意力机制预测程序代码!包含特征可视化,数据Excel导入,直接运行!
适用平台:Matlab2023版及以上
BWO 白鲸优化算法,于2022年发表在SCI、中科院1区期刊《Knowledge-Based Systems》上。


我们利用该高创新算法对我们的CNN-BiGRU-Attention时序和空间特征结合-融合注意力机制的回归预测程序代码中的超参数进行优化。
该论文进行了一系列实验,包括定性分析、定量分析和可扩展性测试。定性分析包括搜索历史、平衡因子曲线、轨迹、平均适应值曲线和收敛曲线等。结果表明,BWO在探索和更新能力之间提供了很好的平衡,定量分析涉及对30个基准函数的实验。此外,还进行了可扩展性测试,对比了BWO与其他15种元启发式算法在可扩展性方面的表现。


BWO算法的创新点主要体现在以下几个方面:
1. 受到白鲸行为的启发:BWO算法的设计灵感来自于白鲸的行为,包括了其游泳、觅食和死亡下沉等行为。通过模拟这些行为,BWO算法能够在优化问题中平衡探索和开发的能力。
2. 自适应的平衡因子和概率:BWO算法引入了自适应的平衡因子和概率来控制探索和开发的能力。这样可以根据问题的特性自动调整算法的行为,提高求解的效果。
3. 引入了Levy飞行机制:BWO算法引入了Levy飞行机制,用于增强全局收敛性。Levy飞行是一种随机游走的方式,可以帮助算法跳出局部最优解,提高求解的全局搜索能力。
4. 在各个方面的性能表现优秀:实验证明,BWO算法在解决一元和多元优化问题方面表现出色,在比较的15种其他元启发式算法中排名靠前。此外,BWO算法在可扩展性分析方面也表现出较高的排名。
综上,BWO算法通过模拟白鲸的行为并引入自适应平衡因子和概率以及Levy飞行机制,实现了在优化问题中平衡探索和开发的能力,并取得了良好的性能表现。这使得BWO算法在解决复杂的实际优化问题方面具有巨大的潜力。
CNN-BiGRU-Attention模型的创新性:
①结合卷积神经网络 (CNN) 和双向门控循环单元 (BiGRU):CNN 用于处理多变量时间序列的多通道输入,能够有效地捕捉输入特征之间的空间关系。BiGRU 是一种能够捕捉序列中长距离依赖关系的递归神经网络。通过双向性,BiGRU 可以同时考虑过去和未来的信息,提高了模型对时间序列动态变化的感知能力。
②引入自注意力机制 (Self-Attention): Self-Attention 机制使得模型能够更灵活地对不同时间步的输入信息进行加权。这有助于模型更加集中地关注对预测目标有更大影响的时间点。
自注意力机制还有助于处理时间序列中长期依赖关系,提高了模型在预测时对输入序列的全局信息的感知。
优化套用:基于白鲸优化算法(BWO)、卷积神经网络(CNN)和双向门控循环单元 (BiGRU)融合注意力机制的超前24步多变量时间序列回归预测算法。
功能:
1、多变量特征输入,单序列变量输出,输入前一天的特征,实现后一天的预测,超前24步预测。
2、通过BWO优化算法优化学习率、卷积核大小、神经元个数,这3个关键参数,以最小MAPE为目标函数。
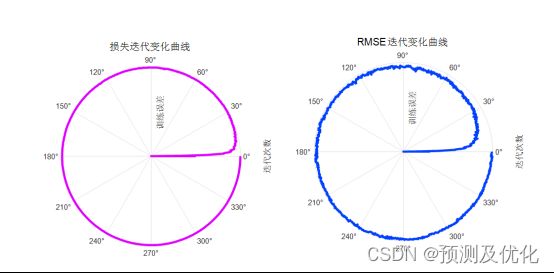
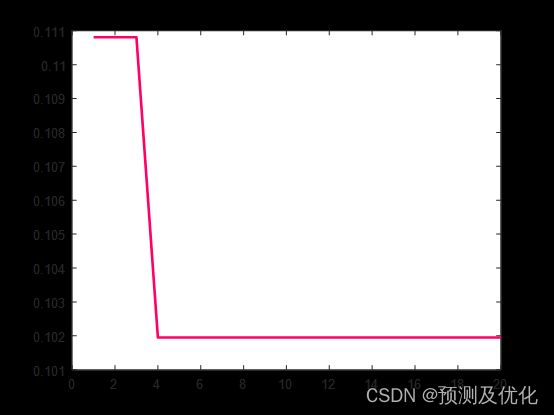
3、提供损失、RMSE迭代变化极坐标图;网络的特征可视化图;测试对比图;适应度曲线(若首轮精度最高,则适应度曲线为水平直线)。
4、提供MAPE、RMSE、MAE等计算结果展示。
适用领域:风速预测、光伏功率预测、发电功率预测、碳价预测等多种应用。
预测值与实际值对比:

训练特征可视化:

训练误差曲线的极坐标形式(误差由内到外越来越接近0)
适应度曲线:
%% 将优化目标参数传进来的值 转换为需要的超参数
learning_rate = x(1); %% 学习率
KerlSize = round(x(2)); %% 卷积核大小
NumNeurons = round(x(3)); %% 神经元个数
%% %% CNN-BiGRU-Attention网络搭建
lgraph = layerGraph();
% 添加层分支
% 将网络分支添加到层次图中。每个分支均为一个线性层组。
tempLayers = sequenceInputLayer([18 24 1],"Name","sequence");
lgraph = addLayers(lgraph,tempLayers);
tempLayers = [
convolution2dLayer(KerlSize,32,"Name","conv","Padding","same")
batchNormalizationLayer("Name","batchnorm")
reluLayer("Name","relu")
maxPooling2dLayer([3 3],"Name","maxpool","Padding","same")
flattenLayer("Name","flatten_1")
fullyConnectedLayer(25,"Name","fc_1")];
lgraph = addLayers(lgraph,tempLayers);
tempLayers = flattenLayer("Name","flatten");
lgraph = addLayers(lgraph,tempLayers);
tempLayers = gruLayer(NumNeurons,"Name","gru1");
lgraph = addLayers(lgraph,tempLayers);
tempLayers = [
FlipLayer("flip3")
gruLayer(NumNeurons,"Name","gru2")];
lgraph = addLayers(lgraph,tempLayers);
tempLayers = [
concatenationLayer(1,3,"Name","concat")
selfAttentionLayer(1,50,"Name","selfattention")
fullyConnectedLayer(24,"Name","fc")
regressionLayer("Name","regressionoutput")];
lgraph = addLayers(lgraph,tempLayers);
% 清理辅助变量
clear tempLayers;
% 连接层分支
% 连接网络的所有分支以创建网络图。
lgraph = connectLayers(lgraph,"sequence","conv");
lgraph = connectLayers(lgraph,"sequence","flatten");
lgraph = connectLayers(lgraph,"flatten","gru1");
lgraph = connectLayers(lgraph,"flatten","flip3");
lgraph = connectLayers(lgraph,"gru1","concat/in1");
lgraph = connectLayers(lgraph,"gru2","concat/in2");
lgraph = connectLayers(lgraph,"fc_1","concat/in3");
%% 设置训练参数
options = trainingOptions('adam', ... % adam 梯度下降算法
'MaxEpochs',300, ... % 最大训练次数 300
'GradientThreshold',1,... % 渐变的正阈值 1
'ExecutionEnvironment','cpu',... % 网络的执行环境 cpu
'InitialLearnRate',learning_rate,...% 初始学习率
'LearnRateSchedule','none',... % 训练期间降低整体学习率的方法 不降低
'Shuffle','every-epoch',... % 每次训练打乱数据集
'SequenceLength',24,... % 序列长度 24
'MiniBatchSize',20,... % 训练批次大小 每次训练样本个数20
'Verbose',true); % 有关训练进度的信息不打印到命令窗口中
%% 训练网络
[net,info] = trainNetwork(XTrain,YTrain, lgraph, options);
部分图片来源于网络,侵权联系删除!
欢迎感兴趣的小伙伴关注下方公众号获得完整版代码,小编会继续推送更有质量的学习资料、文章和程序代码!
