ClickHouse中的物化视图
技术主题
技术原理
物化视图(Materialized View)是一种预先计算并缓存结果的视图,存储在磁盘上自动更新,空间换时间的思路。物化视图是一种优化技术,本质上就是为了加速查询操作,降低系统负载,提高查询性能。
细讲一:流程
1、当创建一个物化视图的时候,clickhouse会计算该视图的结果,并将结果存储在磁盘上。当查询该视图时,clickhouse会直接从磁盘上的结果中获取数据,而不需要重新计算。
2、可以进行跨表创建物化视图,执行查询操作进行更新,例如insert、update、delete。当数据源发生更改时,物化视图会自动更新。
因为除了要更新数据,还需要更新视图,物化视图的缺点是会增加数据更新和维护的开销。
3、需要注意一下,数据在进行删除的时候,物化视图中的数据不会出发删除操作,除了insert会触发视图机制,其他任何操作(删除/修改数据)、甚至删除基表,视图数据不会变化
细讲二:创建物化视图
create materialized view git.commits_mv
engine SummingMergeTree
order by (dt, author)
as select
toDate(time) as dt, author, count() as n from git.commits group by dt, author order by dt asc;
SummingMergeTree 表引擎主要用于只关心聚合后的数据,而不关心明细数据的场景,它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总到一行,可以显著的 减少存储空间并加快数据查询的速度。
需要注意的是:在使用物化视图(SummingMergeTree 引擎)的时候,也需要按照聚合查询来写 sql,因为虽然 SummingMergeTree 会自己预聚合,但是并不是实时的,具体执行聚合的时机并 不可控。
select dt, author, sum(n) from git.commits_mv group by dt ,author order by dt desc;
细讲三:物化视图的优缺点
特点:允许显式目标表(创建视图两种方式的一种to db.table)、累加式、写入触发器(预聚合触发器)、持久化(空间换时间)、join左表触发、源表数据的改变不会影响物化视图(如update, delete, drop partition)、空间换时间
优点:查询速度快,要是把物化视图这些规则全部写好,它比原数据查询快了很多,总的行数少了,因为都预计算好了。
缺点:它的本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去重、去更新这样的分析,在物化视图里面是不太好用的。在某些场景的使用也是有限的。(选择规划好使用场景)
而且如果一张表加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源,比如数据带宽占满、存储一下子增加了很多。(消耗存储)
细讲四:基表新增、删除、修改(视图用SummingMergeTree)
只有新增、会触发物化视图机制。
—基础表 人员工资表
drop table IF EXISTS user;
create table IF NOT EXISTS user(id UInt8, org String, gh String,name String,salary Decimal(20,2))engine=ReplacingMergeTree() order by (id,name) primary key id ;
insert into user values(1,'gw','zs','张三',1),(2,'yl','ls','李四',1);

—统计同名数量
drop VIEW IF EXISTS user_mv;
CREATE MATERIALIZED VIEW IF NOT EXISTS user_mv
ENGINE = SummingMergeTree(salary)
ORDER BY (org) POPULATE
AS
SELECT org, sum(salary) salary FROM user GROUP BY org ;
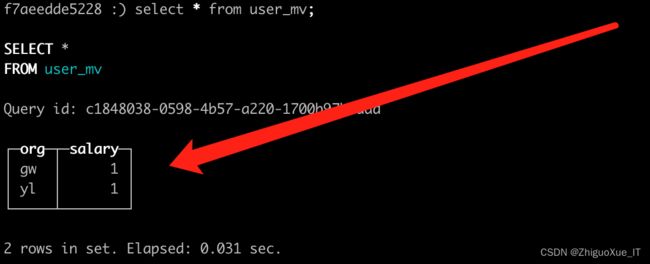
insert into user values(1,'gw','zs','张三',1);

–删除表和数据均不不影响视图内容,视图不是实时的触发

细讲五:基表新增、删除、修改(视图用AggregatingMergeTree)
只有新增、会触发物化视图机制
–创建表 t_merge_base 表,使用MergeTree引擎
create table IF NOT EXISTS t_merge_base(id UInt8,name String,age UInt8,loc String,dept String,workdays UInt8,salary Decimal32(2))engine = MergeTree() order by (id,age) primary key id partition by loc;
create materialized view IF NOT EXISTS view_aggregating_mt engine = AggregatingMergeTree() order by id as select id,name,sumState(salary) as ss from t_merge_base group by id ,name ;
–#向表 t_merge_base 中插入数据
insert into t_merge_base values (1,'张三',18,'北京','大数据',24,10000), (2,'李四',19,'上海','java',22,8000),(3,'王五',20,'北京','java',26,12000);

– #继续向表 t_merge_base中插入排序键相同的数据
insert into t_merge_base values (1,‘张三三’,18,‘北京’,‘前端’,22,5000);
