NLP | Seq2Seq,Encoder-Decoder图文详解及代码
在本文中,概述序列到序列模型,这些模型在机器翻译,视频字幕,图像字幕,问答等不同任务中使用。
1.Sequence to Sequence序列到序列
1.1.序列建模问题
序列建模问题是指输入和/或输出是一系列数据(单词,字母...等)
考虑一个非常简单的问题,即预测电影评论是正面的还是负面的。在这里,我们的输入是一个单词序列,输出是0到1之间的单个数字。如果我们使用传统的 DNN,那么我们通常必须使用 BOW、Word2Vec 等技术将输入文本编码为固定长度的向量。但请注意,此处没有保留单词序列,因此当我们将输入向量输入到模型中时,它不知道单词的顺序,因此它缺少有关输入的非常重要的信息。
因此,为了解决这个问题,RNN出现了。实质上,对于任何输入 X = (x₀, x₁, x₂, ...xt) 具有可变数量的特征,在每个时间步长中,RNN 单元将项目/令牌 xt 作为输入并生成输出 ht,同时将一些信息传递到下一个时间步长。这些输出可以根据手头的问题使用。
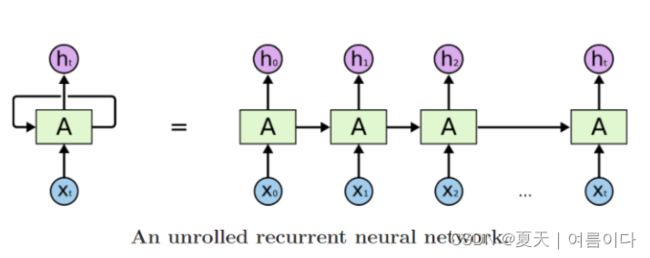
序列问题大致可分为以下几类:

- 每个矩形都是一个向量,箭头表示函数(例如矩阵乘法)。输入向量为红色,输出向量为蓝色,绿色向量保持 RNN 的状态。从左到右:(1)没有RNN的普通处理模式,从固定大小的输入到固定大小的输出(例如图像分类)。(2)序列输出(例如,图像字幕拍摄图像并输出一个单词句子)。(3)序列输入(例如,情感分析,其中给定的句子被归类为表达积极或消极的情绪)。(4)序列输入和序列输出(例如机器翻译:RNN用英语读取句子,然后用法语输出句子)。(5)同步序列输入和输出(例如,我们希望标记视频的每一帧的视频分类)。请注意,在每种情况下,长度序列都没有预先指定的约束,因为循环变换(绿色)是固定的,可以根据需要多次应用。
1.2.序列到序列问题
序列到序列(通常缩写为seq2seq)模型是一类特殊的递归神经网络架构,其中输入和输出都是一个序列。编码器-解码器模型最初是为了解决此类 Seq2Seq 问题而构建的。
示例:假如我们有一个语料库,输入英语,输出法语
Input: English sentence: “nice to meet you”
Output: French translation: “ravi de vous rencontrer”
- 将输入句子“nice to meet you”称为X ,也就是输入序列
- 将输出句子“ravi de vous rencontrer”称为Y_true/目标序列→这就是我们希望我们的模型预测的(ground truth)
- 将模型的预测输出句子称为Y_pred/预测序列
- 英语和法语句子的各个单词称为tokens
- 因此,给定输入序列“nice to meet you”,我们希望我们的模型预测目标序列/Y_true即“ravi de vous rencontrer”
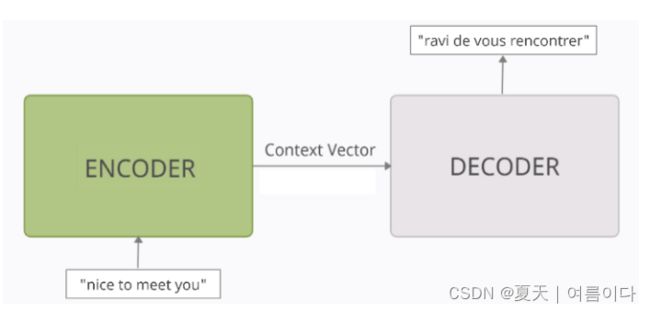
2.Encoder-Decoder编码器解码器
2.1.编码解码器原理
编码器 - 解码器模型可以被认为是两个块,编码器和解码器由一个向量连接,也可以称之为“上下文向量”。

- 编码器:编码器处理输入序列中的每个token。它试图将有关输入序列的所有信息塞入固定长度的向量中,即“上下文向量”。遍历所有token后,编码器将此向量传递到解码器上。
- 上下文向量:向量的构建方式是,它应该封装输入序列的整个含义,并帮助解码器做出准确的预测。
- 解码器:解码器读取上下文向量,并尝试逐个token预测目标序列token。
2.2.编码解码器内部结构
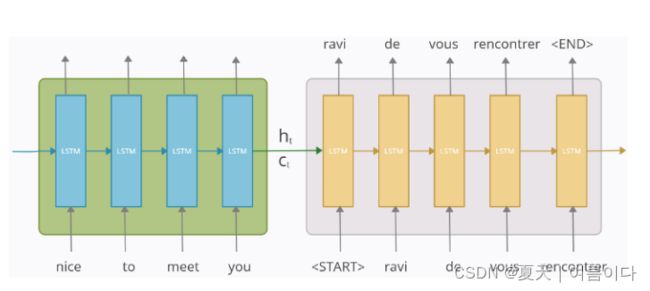
编码器模块
编码器部分是 LSTM 单元。随着时间的推移,它以输入序列输入,并尝试封装其所有信息并将其存储在其最终的内部状态ht(隐藏状态)和ct(单元状态)中。然后,内部状态被传递到解码器部分,它将使用它来尝试产生目标序列。这就是我们之前提到的“上下文向量”。
编码器部分每个时间步长处的输出全部被丢弃
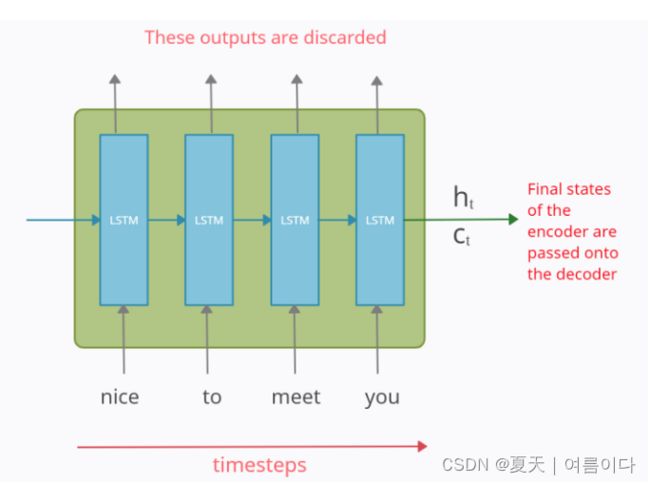
注意:上图是 LSTM/GRU 单元在时间轴上展开时的样子。它是单个LSTM / GRU单元在每个时间戳处采用单个单词/token。这里使用了 LSTM 而不是经典的 RNN,因为它们在处理长期依赖关系时效果更好。
解码器块
因此,在读取整个输入序列之后,编码器将内部状态传递给解码器,这就是输出序列预测的开始。

解码器模块也是一个 LSTM 单元。这里要注意的主要一点是,解码器的初始状态(h₀,c₀)被设置为编码器的最终状态(ht,ct)。它们充当“上下文”向量,并帮助解码器产生所需的目标序列。
现在解码器的工作方式是,它在任何时间步长t的输出都应该是目标序列/Y_true中的第t个字(“ravi de vous rencontrer”)。
在timestep 1
在第一个时间步长时馈送到解码器的输入是一个特殊符号“
在timestep 2
在时间步长2,第1个时间步长“ravi”的输出作为输入送到第2个timestep。第二个时间步长中的输出应该是目标序列中的第二个单词,即“de”
同样,每个时间步的输出作为输入馈送到下一个时间步长。这一直持续到得到“
请注意,这些特殊符号不必仅是“
注意: 上面提到的过程是理想解码器在测试阶段的工作方式。但在训练阶段,需要稍微不同的实现,以使其训练得更快。
3.训练和测试阶段:进入张量
3.1.矢量化我们的数据
需要对数据进行矢量化。原始数据是
- X = “nice to meet you” → Y_true = “ravi de vous rencontrer”
将特殊符号“
- X = “nice to meet you” → Y_true = “
ravi de vous rencontrer ”
接下来,使用单热编码 (ohe) 对输入和输出数据进行矢量化。让输入和输出表示为
- X = (x1, x2, x3, x4) → Y_true = (y0_true、 y1_true、 y2_true、 y3_true、 y4_true、 y5_true)
其中 xi 和 yi 分别表示输入序列和输出序列的 ohe 向量。它们可以显示为:
对于输入 X
'nice' → x1 : [1 0 0 0]
“to” → x2 : [0 1 0 0 ]
“meet” →x3 : [0 0 1 0]
“you” → x4 : [0 0 0 1]
对于输出Y_true
'ravi' → y1_true : [0 1 0 0 0 0]
'de'→ y2_true : [0 0 1 0 0 0]
“vous” → y3_true : [0 0 0 1 0 0]
“rencontrer” → y4_true : [0 0 0 0 1 0]
'
3.2.编码器的培训和测试
编码器的工作原理在训练和测试阶段都是相同的。它逐个接受输入序列的每个标记/字,并将最终状态发送到解码器。随着时间的推移,它的参数使用反向传播进行更新。

3.3.训练阶段的解码器:Teacher Forcing教师强制
解码器在训练和测试阶段的工作是不同的,与编码器部分不同。因此,将分别看到两者。
为了训练解码器模型,使用一种称为“教师强制”的技术,在这种技术中,将上一个时间步的真实输出/token(而不是预测的输出/token)作为当前时间步的输入。
这里,将输入序列馈送到编码器,编码器对其进行处理并将其最终的内部状态传递给解码器。现在对于解码器部分,如图。
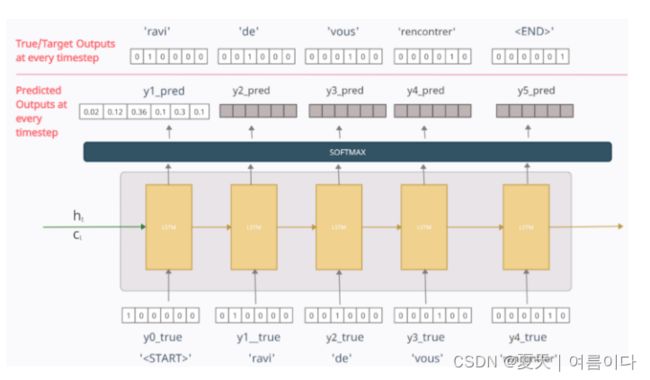
- 在解码器中,在任何时间步长 t 中,输出yt_pred是使用 Softmax 激活函数生成的输出数据集中整个词汇表的概率分布。具有最大概率的令牌被选为预测单词。
在时间步长 1
单词“
因此,引入了Teacher Forcing来纠正这一点。在其中,我们将上一个时间步长的真实输出/token(而不是预测输出)作为当前时间步长的输入。这意味着时间步长 2 的输入将y1_true=[0 1 0 0 0 0],而不是y1_pred。
现在,时间步长 2 处的输出将是一些随机向量y2_pred。但是在时间步长 3 中,我们将输入用作 y2_true=[0 0 1 0 0 0],而不是y2_pred。同样,在每个时间步长中,将使用上一个时间步长的真实输出。
最后,根据每个时间步的预测输出计算损失,并随着时间的推移反向传播误差以更新模型的参数。使用的损失函数是目标序列/Y_true和预测序列/Y_pred之间的分类交叉熵损失函数,使得
- Y_true = [y0_true、y1_true、y2_true、y3_true、y4_true、y5_true]
- Y_pred = [“<起点>”,y1_pred,y2_pred,y3_pred,y4_pred,y5_pred]
解码器的最终状态被丢弃.
3.4.测试阶段的解码器
在实际应用程序中,我们不会有Y_true,而只有 X。因此,我们不能使用我们在训练阶段所做的工作,因为我们没有目标序列/Y_true。因此,当我们测试模型时,来自上一个时间步长的预测输出(而不是与训练阶段不同的真实输出)将作为输入馈送到当前时间步长。休息与训练阶段完全相同。
假设我们已经训练了我们的模型,现在我们在训练它的单个句子上测试它。现在,如果我们很好地训练了模型,并且也只在单个句子上训练,那么它应该表现得几乎完美,但为了解释起见,说我们的模型没有训练好或部分训练,现在我们测试它。让场景由下图描述
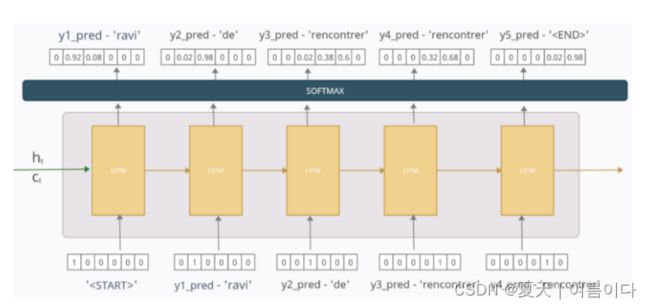
在时间步长 1
y1_pred = [0 0.92 0.08 0 0 0] 表示模型将输出序列中的第一个token/单词预测为“ravi”,概率为 0.92,因此现在在下一个时间步长中,此预测的单词/token将仅用作输入。
在时间步长 2
来自第一时间步长的预测单词/token“ravi”在这里用作输入。在这里,模型预测输出序列中的下一个单词/标记为“de”,概率为0.98,然后在时间步长3处用作输入
在每个时间步长中重复类似的过程,直到达到“
可视化效果为:

因此,根据我们训练的模型,测试时的预测序列是“ravi de rencontrer”。因此,尽管模型在第3次预测中不正确,但我们仍然将其作为下一个时间步的输入。模型的正确性取决于可用的数据量以及训练数据的程度。该模型可能会预测错误的输出,但尽管如此,相同的输出只会馈送到测试阶段的下一个时间步长。
3.5.嵌入层
解码器和编码器中的输入序列都通过嵌入层来减小输入词向量的维度,因为在实践中,单热编码向量可能会非常大,嵌入向量是更好的单词表示。对于编码器部分,这可以在下面显示,其中嵌入层将单词向量的维度从四个减少到三个。

此嵌入层可以像 Word2Vec 嵌入一样进行预训练,也可以使用模型本身进行训练。
3.6.测试时的最终可视化

参考文献
【1】Seq2Seq Model | Understand Seq2Seq Model Architecture (analyticsvidhya.com)
【2】Encoder-Decoder Seq2Seq Models, Clearly Explained!! | by Kriz Moses | Analytics Vidhya | Medium