【中间件】消息队列中间件intro
中间件middleware
内容管理
-
- intro
- why use MQ
- MQ实现漫谈
- 主流消息队列
- QMQ Intro
- QMQ架构
- QMQ 存储模型
本文还是从理论层面分析消息队列中间件
cfeng现在处于理论分析阶段,以中间件例子,之前的blog对于中间件是从使用角度分享了相关的用法,现在就从理论层面分析中间件,后面再从理论出发尝试分析中间件以及实现中间件,这样我们才能更好的自定义相关的功能
intro
消息队列在如今的软件系统中扮演着重要的角色。cfeng之前work中使用RabbitMQ进行的服务通信和解耦,消息队列的发布/订阅模型常常用于服务解耦,众多开源实现(RabbitMQ、RocketMQ、Kafka、QMQ…),都是采用的分布式架构支持弹性高可用。
消息队列的概念很简单: Message Queue,就是消息传播过程中保存消息的一个队列。一端连接生产者,一端连接消费者。
why use MQ
为什么要使用MQ呢,首先就是考虑企业中的应用场景,比如实时索引更新、 异步化流程… 这些使用MQ就可以轻易解决。 MQ最主要的功能就是异步解耦、流量削峰…
-
异步: 消息生产者将消息投递到消息队列中,因为可靠性由MQ保证,所以生产者可以继续处理剩余的业务逻辑,提升可靠性,比如注册成功之后发送通知短信…
-
松耦合: 生产者和消费者不需要知道对方的存在,只需要事先定义好消息的格式,不需要知道对方的实现细节,相比RPC调用强耦合(被调用方异常或者响应慢可能产生回压,甚至雪崩),MQ可以为业务提升稳定性
cfeng之前work中各个后台系统的通信就采用的MQ进行异步通信,eg: 新增一个用户到系统,需要在主系统中同步,那么我直接在这个队列中增加一条insert的消息,主系统接收即可,因为是异步的,松耦合 后面这样也出现了问题,本身预算不足,MQ集群规模小,所以MQ的压力增大,后面又改成了PRC调用(Feign) -
数据分发: Fanout广播,不同的消费者组全量拷贝同一主体的消息队列(topic),并且彼此互不干扰,广播模式的MQ在很多场景下可以发挥重要作用,eg: 对于一个旅游列表变更提供方而言,那么机票、酒店、车票、火车票…等多个业务都不需要轮询旅游业务,就都可以收到变更事件
-
流量削峰: 消息队列具备积压能力。很多业务像秒杀具有潮汐效应,就是流量成峰谷状,如果实时性要求不高,那么就可以利用Queue的积压能力,进行削峰填谷,就可以不用增加硬件…
-
可靠投递: 消息队列本身需要考虑的问题就是可靠性,不能够丢失消息。一般成熟的MQ产品都是两次RPC + 一次转储实现整个流程。【生产者投递消息到MQ,MQ作为broker将消息通知给消费者】
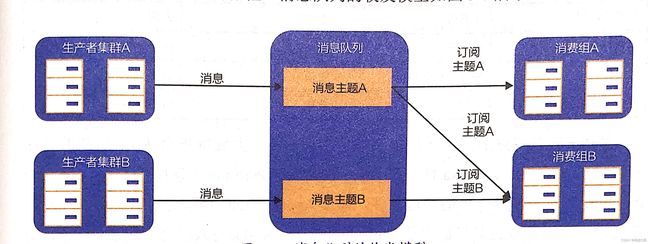
消息队列适用场景
上下游业务解耦: 订单支付完成后,核心业务完成,但是可能还需要给用户加积分发放优惠劵,这些不是核心逻辑,可靠性要求低,那么就可以引入MQ来进行解耦延迟通知: 用户订单下单后可能还没有支付,需要在30分钟内支付,未支付那就取消订单,可以使用延迟MQ实现大数据离线分析: 用户的行为日志通过实时系统进入MQ,当业务处于低峰期时且资源充裕,即可进行信息分析缓存同步: 类似实时价格变动事件,需要刷新缓存,可以通过MQ广播给消费者,这样就可以不用进行数据库轮询了【轮询会有实时性误差】
MQ实现漫谈
消息队列主要就是一个中间队列,具有积压消息的功能,同时作为系统间的解耦利器,一定是单独部署的。
NoSQL充当消息队列
如果只是需要一个地方进行消息的存取,那么客户端可以直接将消息比如写入MongoDB中,消费者从里面拖出来即可。没有任何的broker代理
一旦升级,涉及大量的客户端【因为代码耦合严重】,消费者之间的协调只能通过DB进行,会涉及DB的modify等操作,性能很低,没有弹性
producer ------> ---Mongo DB--- ------> Consumer
引入中间server充当broker
没有server导致MQ只是一个没有弹性的容器,好的MQ应该能够具有消息协调的功能的
producer -------> Broker --------> consumer
| |
Mongo DB
引入一个broker,生产者和消费者直接交互的是borker,那么broker就可以起一个协调作用,客户端很轻,只是和broker通讯,告诉borker需要发消息即可,升级只需要升级borker即可。
但是这里没有binding,一个topic绑定到一个mongo的表上,存储粒度为一个topic【mongo这边消息的清理思路: 分表-- 写了上一张表写下一张表,上一张表直接drop,不用一张表里面insert、delete】
再引入客户端和服务端SDK
上面的还是一个很基础的实现,因为消费者和生产者和Broker的交互性很低,所以borker的协调性很低,那么客户端和服务端引入SDK,制订一套完整的规则,引入binding,加上一些辅助组件,就可以形成一个综合的MQ
---------------------- ---> MetaServer -> ----------------------
| Producer | | | Consumer |
| HTTP Recelver | -----> Broker ----> | Http Deliver |
| APP | | | App |
---------------------- MySQL ---------------------
这个也不可能是真正的MQ的架构,只是一个比较抽象的想法。MQ作为成熟的产品,那么就需要具备优秀的性能。需要考虑很多方面的事情:
- 消息的写入: 消息怎么写入的更快(批量?..)
- 消息的投递的及时性: 延迟怎么降低 (partition Stick…, 截获代替轮询, Long Pulling…)
- 集群管理 …
主流消息队列
之前cfeng快速的讲解过Spring中使用RabbitMQ的方式【关键就是binding、exchange和queue,配置的时候一个binding就是将exchange和queue绑定,生产者发送消息的时候指定exchage和bindingKey就可投放到指定的Queue,消费者监听消费Queue中消息即可】
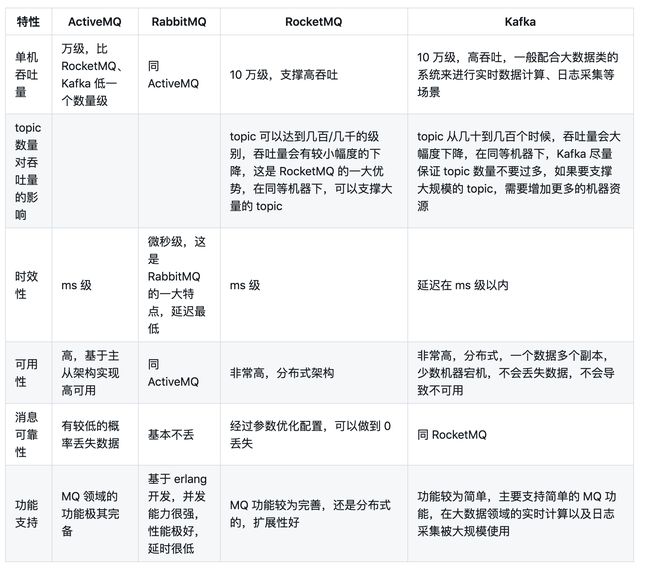
可以看到的是Kafka的可用性相比RabbitMQ是非常高的,拥有成熟生态(日志系统、流式系统…、活跃社区)
Kafka主要是Scala实现的,同时能够很好的集成到java生态中
RabbitMQ主要是Erlang实现的,cfeng之前work业务量小采用的该MQ
RocketMQ是ali利用java实现的,具备较高的可靠性
QMQ是qunar利用java是实现的,采用的无序消费存储模型
Kafka
Kafka将一个Topic分成多个Parition,每一个Partition作为一个Broker的物理文件,通过Apend only的方式实现文件顺序写的高性能,线性提高集群单topic的吞吐量。
但是,当Broker上所有的Topic的Partition总和过多时,会产生随机写
Partition 0 |0|1|2|3|4|5|6|7|.. <--------
Partition 1 |0|1|2|3|4|5|6|... <-------|---- Writes
Partition 2 |0|1|2|3|4|5|6|7|8|... <-------|
Old -----------------------> new 【Kfaka写入消息】
顺序访问和随机访问的性能不同, 随机访问时,需要小号磁头寻道和盘片旋转等待的时间;
SSD使用的是半导体闪存介质,随机访问和顺序访问的差异不大
硬盘/吞吐 顺序写 随机写 顺序读 随机读
SATA 125M 548K 124M 466K
SSD 592M 549M 404M 505M
【使用fio测试工具,每次访问4KB工具】测试开发机磁盘访问速度数据
RocketMQ
RocketMQ吸取了Kafka中多Partition消息文件会导致随机写的教训,采用的是单一消息文件 Commit Log, 将所有Topic的消息在物理上全部顺序追加到Commit Log文件中。
上述操作可以能增加消息写入的吞吐量,但是消费方在消费历史【操作系统Page Cache,正在发生IO条件为未命中Page Cache,实时消费基本不会引入IO】消息时候,会引入随机读。
RocketMQ是一主多从架构,主写从读,只有主节点提供写操作,从节点比较空闲,RocketMQ将历史消息消费通过重定向到从节点 , 来缓解随机读
无论是Kafka还是RocketMQ,都存在一个约束: 一个Partition只能绑定在一个Consumer上
因此: 消费者集群上限是Partition的数目;Partition的均衡性可能导致消费组个别机器的负载高、积压多。
eg: 一个Tpic(cfeng.fx.kafka.example)设置了3个partition(0,1,2),如果消费组(kafka.example.group)初始化两台机器,一台消费者消费一个partition,另一个消费者消费两个partition; 这个时候,如果消费能力不够,那么通过水平扩容消费者的方案 ❌; 此时Kafka | RocketMQ 只能通过 增加partition来进行Rebalance,但Rebalance之后只能对新生产的消息生效, 原本积压的消息不会被Rebalance; 可能会破环消息的顺序性,同时清理积压会对新的消息有积压耗时
partition 1 | | | | | | | | | | | -------- Consumer 1
partition 2 | | | | | | | | | | | -------- Consumer 2
partition 3 | | | | | | | | | | | -------- Consumer 3
生产者通过选定某个字段(如tenant_id)作为Partition Key来决定将消息投递到哪个Partition,因此Partition Key会影响消费速度
eg: 比如一个Partition Key分布不均匀时,就会出现某些Counsmer的消费速度达不到生产速度,也就是消费能力不足,导致消息积压
partition 1 | | | | -------- Consumer 1
partition 2 | | | | | -------- Consumer 2
partition 3 | | | | | | | | | | | | -------- Consumer 3
这里就发现 Consumer 3 的消费能力不足,出现消息积压,而Consumer 1和2则相对空闲
QMQ Intro
最近cfeng了解架构的时候,就经常浏览github寻找相关的资料进行辅助的study,在探索消息队列的时候,就在gitee上看到了qunar开源的QMQ【其和Hermes的区别就是Hermes是以MySQL作为消息持久化存储,而QMQ则是以磁盘文件进行存储】
QMQ相比其他的MQ比较小众,这里也就简单的探究一下这款MQ产品
事务消息 && 生产者消息可靠投递
一些业务比如订单类型业务对于可靠性的要求很高,一些场景如业务系统宕机或网络暂时不可用时,也需要确保消息可靠投递 — 如何解决?
QMQ的解决方案: 生产者侧引入持久化存储【MySQL、MongoDB…】,发送消息之前,先将消息持久化到存储中,之后再异步化发送消息,当Broker返回消息发送成功的结果之后,将消息从持久化存储中del,当生产者突然宕机,那么负责补发消息的watch dog会代理消息发送的工作
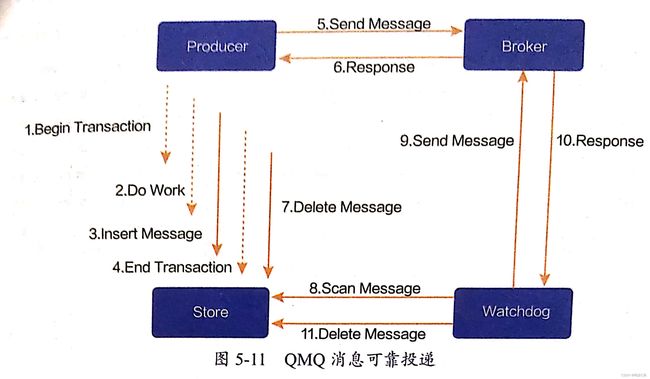
QMQ同时支持事务消息,依赖的是存储的本地事务,实现分布式事务还可以通过两阶段提交 Two-phase Commit ,但是两阶段提交的对于本地事务来说: 交互过多,流程复杂,性能较低, 并且业务系统大多依赖MySQL进行存储
延迟消息
这是很多MQ都支持的一个特性,比如超时30分钟未支付,订单取消就可以使用延迟MQ进行实现
定时重试
某些业务系统特定的流程,也就是状态机,只有当某个前置条件满足时才会消费这条消息,条件队列, 这个时候不能直接丢弃这种消息, QMQ可以设置定时重试的功能,让业务定时重新进行消费
同机房生产与消费
生产者采用同机房投递的策略,这样可以避免跨机房流量的产生; 消费者默认多机房消费; (消费者不用关心生产者机房部署结构)核心链路的业务支持单元化,只是消费本单元内的消息,可以实现单元隔离
消息检索追踪
消息检索追踪是非常必要的,应该实现离线任务按照时间回溯选择性重发、端到端耗时的长尾问题排查、未消费问题的排查重发、死信重发…
按照时间端筛选消息
记录每条消息的消息ID、创建时间、接收时间、broker组、详细信息,支持重发等操作
也就是MQ具有良好的消息治理功能
同时QMQ还支持广播消息、Server随意扩容等多种特性,再Spring中使用也是annotation化,非常便捷
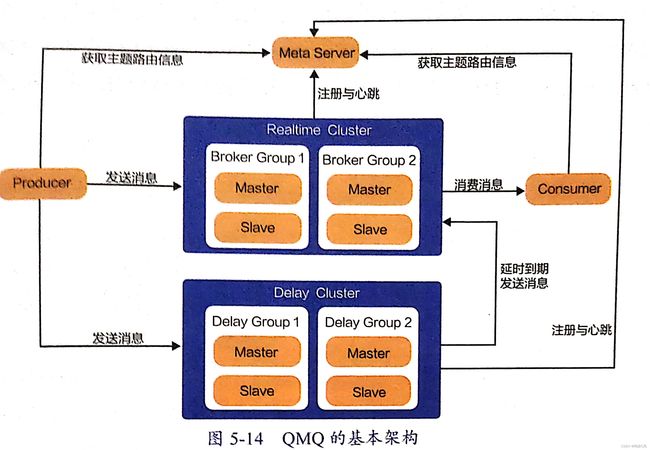
QMQ架构
QMQ服务端包含3个核心组件: Meta Server、 Broker、 Delay
-
Meta Server : 元信息管理服务, 用于消息路由控制下发,维持Broker和Server的心跳, 还有上下线挂历、消费者进度管理… 当Meta Server检测到Broker或者Delay的心跳失联,那就标记下线
-
Broker是QMQ存储核心, 用于接收消息并持久化到磁盘文件中,创建消息索引,管理消费进度,响应拉取请求。Broker实现HA采用的是主从模式, Master能接收读写请求, (仿照的PacificA实现主从切换…当Master宕机,自动选举新的Master继续服务)
-
Delay 是接收延迟消息并持久化到本地磁盘,当超过延迟时间后,消息将被投递到Broker。 Delay的HA也是采用的主从模式,副本保证消息的灾备。
可以看出延迟消息是剥离的单独的服务【RocketMQ是集成在Broker的逻辑中,RabbitMQ也是在Broker的逻辑中,但是是增加了死信交换机和死信队列】 QMQ考虑的因素: 1. 延迟和实时是两种消息类型,隔离可以不互相影响,提高可靠性 2. 在达到延迟时间时,消费者路由可能发生迁移,如果逻辑耦合在Broker中,那么就需要进行重定向,【单一职责最好】 RabbitMQ模型 RabbitMQ broker -------------------------- producre 1 ----> | exchange1 ---> quwuw1 |---> consumer1,2. | .... | producer 2 ----> | exchange2 ---> queue2 | ---> consumer n -------------------------
QMQ 存储模型
之前提到过Kafka和RocketMQ的存储模型中的Parition缺点,QMQ采用的是独特的无序消费存储模型, 同时有序模型和二者是相同的
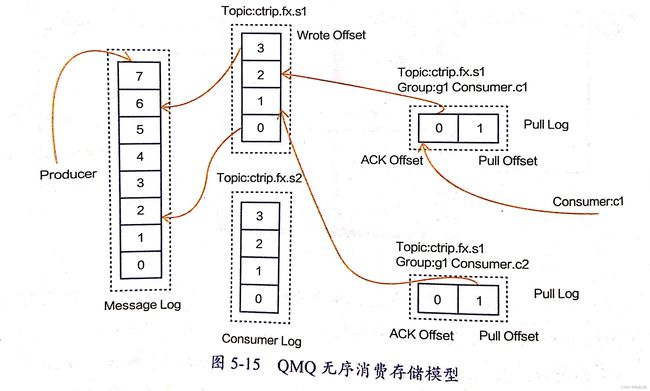
- Message Log 存储所有Topic的消息,消息顺序写入此文件中, 避免发生类似Kafka多partition文件造成文件随机写性能下降的问题
- Consumer Log 是以Topic为维度组织的Message Log的索引文件。索引记录固定长度,记录这个Topic的第X条消息在Message中的物理偏移量和消息大小 【感觉类似OS中的存储】
QMQ的无序存储模型中 不存在Q与单一Consumer的绑定关系,而是一个消费者组(consumer group)中的消费者合力消费一个Q,所以消费者组是支持动态扩容的
当没有了单一的consumer和Q的绑定关系:
每一个消费者的ACK和pull都是离散的,所以不能通过Q的ACK和pull(offset)来管理消费者的消费进度
QMQ 抽象一层Pull Log: 记录Consumer在Consumer Log中的offset, 当Consumer重启后,读取pull Log即可定位进行消费
当消费者拉取积压过久的消息,没有命中Page Cache时(提到),就会产生读磁盘操作,对于文件系统负担过重。 QMQ采用的时类似RocketMQ所有消息顺序写入Message Log,索引文件对应的物理偏移基本是块离散的,【一个物理块可能是多个消息Topic】 QMQ就给Message Log进行排序,排序后的Message Log再增加索引文件 ----- 相同主题Topic的消息是块连续,可以充分利用OS的预读特性,提升效率
后面Cfeng会结合QMQ的源码进行详细的分析,这里只是见到那提及QMQ整体上的架构,和RabbitMQ相比,可能更好的适配java生态