pandas 数据筛选与索取
转载于博客园
pandas的数据形式
基本操作
- 更改dataFrame中的某一列的类型
.astype()方法
import pandas as pd
df['列名'] = df['列名'].astype(np.int64)
- 更改
Series中的类型,同样使用.astype() - 在读取的时候更改
pd.read_csv("data", dtype = {"colname" : float})
- 删除pandas DataFrame的某一/几列:
方法1:
del DF['column-name']
方法2:
DF.drop('column_name',axis=1, inplace=True)
- 更改DataFrame的某些值(在原始数据中更改,注意数据备份),使用
.loc,.iloc
思路:先定位,再赋值
# loc和iloc 可以更换单行、单列、多行、多列的值
df1.loc[0,'age']=25 # 思路:先用loc找到要更改的值,再用赋值(=)的方法实现更换值
df1.iloc[0,2]=25 # iloc:用索引位置来查找
# at 、iat只能更换单个值
df1.at[0,'age']=25 # iat 用来取某个单值,参数只能用数字索引
df1.iat[0,2]=25 # at 用来取某个单值,参数只能用index和columns索引名称
print(df1)
- 插入新增列、行
# 类似与字典的赋值
df1['score']=[80,98,67,90]
import pandas as pd
df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['name','gender','age'])
print("----------在最后新增一列---------------")
print("-------案例1----------")
# 在数据框最后加上score一列,元素值分别为:80,98,67,90
df1['score']=[80,98,67,90] # 增加列的元素个数要跟原数据列的个数一样
print(df1)
print("-------案例2----------")
print("---------在指定位置新增列:用insert()--------")
# 在gender后面加一列城市
# 在具体某个位置插入一列可以用insert的方法
# 语法格式:列表.insert(index, obj)
# index --->对象 obj 需要插入的索引位置。
# obj ---> 要插入列表中的对象(列名)
col_name=df1.columns.tolist() # 将数据框的列名全部提取出来存放在列表里
print(col_name)
col_name.insert(2,'city') # 在列索引为2的位置插入一列,列名为:city,刚插入时不会有值,整列都是NaN
df1=df1.reindex(columns=col_name) # DataFrame.reindex() 对原行/列索引重新构建索引值
df1['city']=['北京','山西','湖北','澳门'] # 给city列赋值
print(df1)
print("----------新增行---------------")
# 重要!!先创建一个DataFrame,用来增加进数据框的最后一行
new=pd.DataFrame({'name':'lisa',
'gender':'F',
'city':'北京',
'age':19,
'score':100},
index=[1]) # 自定义索引为:1 ,这里也可以不设置index
print(new)
print("-------在原数据框df1最后一行新增一行,用append方法------------")
df1=df1.append(new,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增
print(df1)
- 更改
dataframe列名
#显示df每列的名称
df.columns.values
# 将第三列的列名改为'new name'
df.rename(columns={ df.columns[2]: "new name" }, inplace=True)
# 假如df一共有三列,你想把所有列名依次改为'col_1', 'col_2', 'col_3'
df.columns = ['col_1', 'col_2', 'col_3']
- 将空元素填充为固定值
.fillna()
df3.fillna(3, inplace=True)
案例1
清洗生存数据
清洗数据,希望得到这样的csv文件用来作生存分析
case_id,slide_id,censorship,suivival_months,oncotree_code,
'''
import pandas as pd
import os
import numpy as np
pt_path = '/home/hero/disk/CODE/Patch-GCN-master_old/GGH/WSI_graph'
src_path_csv = '/home/hero/disk/ubuntu_free/clin_shengyi.csv'
def run():
target_wsi_id = os.listdir(pt_path)
# 获取WSI文件的ID
target_wsi_id = [os.path.splitext(i)[0] for i in target_wsi_id]
# 读取CSV文件,并将id_name设置为索引列
src_csv = pd.read_csv(src_path_csv)
src_csv['id_name']=src_csv['id_name'].astype(str)
src_csv.set_index('id_name',inplace=True)
# 构建新的CSV文件
pd_new = src_csv.loc[target_wsi_id,['OS','OS_month']]
# 在新构建的CSV文件中添加case_id,slide_id,并填充上对应的数据
pd_new['case_id']=pd_new.index
pd_new['slide_id']=pd_new.index
# 更改列名 OS->censorship,OS_month->survival_month
pd_new.rename(columns={ 'OS': "censorship" }, inplace=True)
pd_new.rename(columns={ 'OS_month': "survival_months" }, inplace=True)
# 添加列oncotree_code,并用LUAD填充
pd_new['oncotree_code']=['LUAD']*len(pd_new.index)
# 将censorship中的值0,1互换
pd_new['censorship']=pd_new['censorship']+1
pd_new.loc[pd_new['censorship'].values==2,'censorship']=0
# save csv file
pd_new.to_csv('./GGH/clinl.csv')
if __name__=="__main__":
run()
案例2
一、导入数据
#导入pandas和numpy库
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
test=pd.read_excel("/Users/yaozhilin/Downloads/exercise.xlsx",sep="t")
test.head(5)#显示前五行

二、选取行或者列
test[:2]#选取行

三、基于.loc方法来索引
基于标签索引
1、行与列的list或者切片选取(.loc[:,[]]或.loc[[],:]等)
2、行的布尔值筛选与列的list或者切片选取进行条件筛选
注:因为基于标签索引,所以索引结果为前闭后闭
1、行和列的切片或者[]组合选取
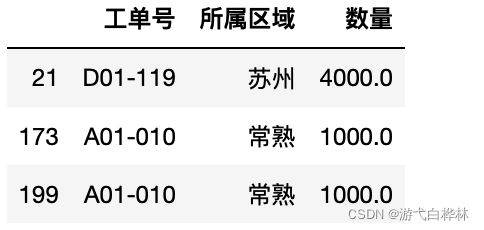
test.loc[:4,["工单号","所属区域","数量"]]#行-切片,列-list

2、行的布尔值筛选与列的list或者切片选取进行条件筛选
test.loc[test["数量"]>=800,["工单号","所属区域","数量"]]#行-布尔值,列-list
四、基于.iloc的方法
iloc:基于位置索引 是传统的前闭后开
正常索引与loc一样行和列可以随意切片或者是[]的形式
test.iloc[0:3,0:3]

布尔值索引筛选过滤:
因为loc是直接将标签和筛选值连在一起可以直接筛选,而iloc是基于位置的筛选不能直接识别筛选值
test["数量"].values#变为数组获取值的位置
test.iloc[test["数量"].values>=800,0:3]

五、多重索引
1、构建多重索引:
1)set_index、reset_index原表数据构建
test.set_index( keys,drop=True,append=False, inplace=False,verify_integrity=False) drop表示设置为新索引的列是否保存在原数据
append表示旧的索引是否保存
test.set_index(["所属区域","产品类别"],drop=True,append=True,inplace=True)
test
还原
test.reset_index(level=[1,2],inplace=True)2 test

2)zip创建
pd.MultiIndex.from_tuples、zip的用法:将两集合拆包组成新的配对集合
X=[1,2,3,4]
2 Y=['a','b','c','d']
3 XY=list(zip(X,Y))
4 print(XY)
[(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]
z1,z2=zip(*XY)
z1
(1, 2, 3, 4)
indexs=pd.MultiIndex.from_tuples(XY,names=["first","scend"])
df=pd.DataFrame(np.random.randn(4),columns=['A'],index=indexs)
df

2、loc常规按顺序索引
test.set_index([“所属区域”,“产品类别”],drop=True,inplace=True)
test.loc[(“苏州”,“睡袋”),“数量”]#indexs用(),且不能不写第一索引
所属区域 产品类别
苏州 睡袋 120.0
睡袋 160.0
睡袋 100.0
睡袋 360.0
睡袋 240.0
睡袋 120.0
.....
注:test.loc[(,“睡袋”)]
但是直接跳过第一索引会报错
可使用slice切片组合使用,但slice使用过程中所有索引与列均要显示指出
test.loc[(slice(None),"睡袋"),:]#冒号不能省略

清理数据V2
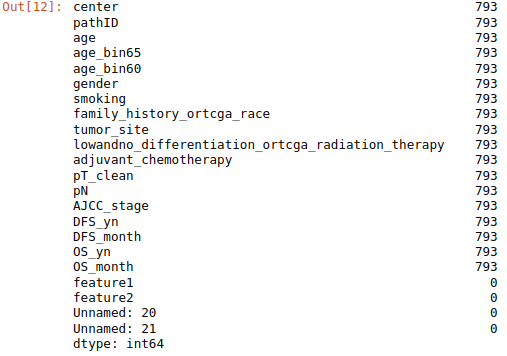
1. 查看所有的列名
df.columns
Index([‘center’, ‘pathID’, ‘age’, ‘age_bin65’, ‘age_bin60’, ‘gender’,
‘smoking’, ‘family_history_ortcga_race’, ‘tumor_site’,
‘lowandno_differentiation_ortcga_radiation_therapy’,
‘adjuvant_chemotherapy’, ‘pT_clean’, ‘pN’, ‘AJCC_stage’, ‘DFS_yn’,
‘DFS_month’, ‘OS_yn’, ‘OS_month’],
dtype=‘object’)
df.count()