大数据实训05--网站离线日志分析实战
用户行为分析
是指在获得网站访问量基本数据的情况下,对有关数据进行统计、分析,从中发现用户访问网站的规律,并将这些规律与网络营销策略等相结合,从而发现目前网络营销活动中可能存在的问题, 并为进一步修正或重新制定网络营销策略提供依据。这是狭义的只指网络上的用户行为分析。
要分析的KPI:浏览量PV、注册用户数、IP数、跳出用户数、访问页面详细统计
运行流程
数据源----数据采集(存到HDFS)-----数据清洗(MapReduce并行计算封装成jar包)---数据统计分析(hive)
数据转移(sqoop)----可视化展示
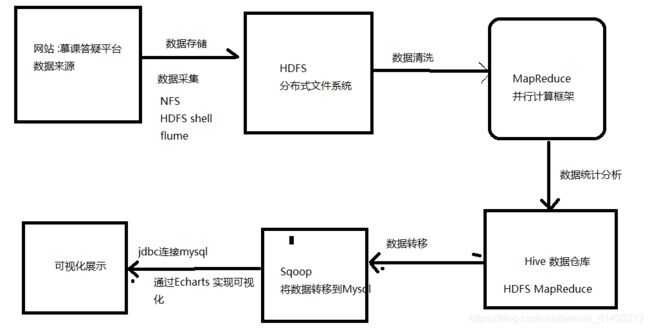
- 日志数据上传到HDFS(在此清晰的是当天的日志文件)
- 清洗数据
- 建立分区表
- 关联数据
- 统计分析,并通过sqoop转化数据
- 通过Echarts做可视化展示
开启Tomcat

建立分区表以日期作为分区的指标(将清洗后的数据存入到hive) 方便后续查看

添加时间分区

命令及SQL语句
#创建目录
hdfs dfs -mkdir -p /logs/bbs
-
# 上传文件hdfs
hdfs dfs -put /home/hpe/access_2017_05_31.log /logs/bbs/
#执行mapReduce程序
hadoop jar /home/LogCleanJob.jar /logs/bbs/access_2017_05_31.log /logs/bbs/cleaned/2017_05_31
#建立分区表以日期作为分区的指标(将清洗后的数据存入到hive)
create external table bbslogs(
ip string,
atime string,
url string)
partitioned by (logdate string)
row format delimited
fields terminated by '\t' location '/logs/bbs/cleaned';
#增加分区(针对2017_05_31的日志进行分区)
alter table bbslogs
add partition(logdate='2017_05_31') location '/logs/bbs/cleaned/2017_05_31';
#查询日志表中的数据
select * from bbslogs where atime='20170531011507';
#使用HQL统计关键指标
#(1) 每天的pv量
create table bbslogs_pv_2017_05_31 as select count(1) as PV from bbslogs where logdate='2017_05_31'
#(2) 每天注册用户数
create table bbslogs_register_2017_05_31 as select count(1) as REGUSER from
bbslogs where logdate='2017_05_31' and instr(url,'member.php?mod=register')>0
#(3)每天独立IP数
create table bbslogs_ip_2017_05_31 as select count(distinct ip) as IP from
bbslogs where logdate='2017_05_31'
#(4)用户跳出数
create table bbslogs_jumper_2017_05_31 as select count(1) as jumper from
(select count(ip) as times from bbslogs where logdate='2017_05_31' group by ip having times=1) e
# 汇总表(将所有关键指标放入一张汇总表中)
create table bbslogs_2017_05_31 as
select '2017_05_31',a.pv,b.reguser,c.ip,d.jumper
from bbslogs_pv_2017_05_31 a
join bbslogs_register_2017_05_31 b on 1=1
join bbslogs_ip_2017_05_31 c on 1=1
join bbslogs_jumper_2017_05_31 d on 1=1
#(5)访问页面详细统计
create table bbslogs_detail_2017_05_31 as select logdate,url,count(url) as count from
bbslogs where logdate='2017_05_31' group by url,logdate
#(6)每天不同时段PV量
create table bbslogs_day_pv_2017_05_31 as select v.logdate,v.hour,count(*)
from (select logdate,substr(atime,9,2) as hour from bbslogs WHERE logdate='2017_05_31') v
group by hour,logdate
#汇总表 数据转化 export to mysql
sqoop export --connect jdbc:mysql://192.168.228.100:3306/bbslogs --username root --password root --table bbs_logs_stat --fields-terminated-by '\001' --export-dir "/user/hive/warehouse/bbslogs_2017_05_31"
#每天不同时段pv量 转化 bbs_days_ pv
sqoop export --connect jdbc:mysql://192.168.228.100:3306/bbslogs --username root --password root --table bbs_days_pv --fields-terminated-by '\001' --export-dir "/user/hive/warehouse/bbslogs_day_pv_2017_05_31"
#详细页面pv量
sqoop export --connect jdbc:mysql://192.168.228.100:3306/bbslogs --username root --password root --table bbs_pv_detail --fields-terminated-by '\001' --export-dir "/user/hive/warehouse/bbslogs_detail_2017_05_31"
设计脚本文件自动执行系列操作
#!/bin/sh
yesterday=$(date --date='1 days ago' +%Y_%m_%d)
logdirdate=$(date --date='1 days ago' +%Y-%m-%d)
echo ${yesterday}
cd /home/hadoop-2.7.5/bin
# 上传文件hdfs
./hdfs dfs -put /home/apache-tomcat-8.0.53/logs/localhost_access_log.${logdirdate}.txt /logs/bbs/
#执行mapReduce程序
./hadoop jar /root/LogCleanJob.jar /logs/bbs/localhost_access_log.${logdirdate}.txt /logs/bbs/cleaned/${yesterday}
cd /home/hive-2.3/bin
# 增加分区
./hive -e "ALTER TABLE bbslogs ADD PARTITION(logdate='${yesterday}') LOCATION '/logs/bbs/cleaned/${yesterday}';"
#1每天的PV量
./hive -e "CREATE TABLE bbslogs_pv_${yesterday} AS SELECT COUNT(1) AS PV FROM bbslogs WHERE logdate='${yesterday}';"
#2每天的注册用户数
./hive -e "CREATE TABLE bbslogs_register_${yesterday} AS SELECT COUNT(1) AS REGUSER FROM bbslogs WHERE logdate='${yesterday}' AND INSTR(ur
l,'register')>0;"
#3每天的独立IP数
./hive -e "CREATE TABLE bbslogs_ip_${yesterday} AS SELECT COUNT(DISTINCT ip) AS IP FROM bbslogs WHERE logdate='${yesterday}';"
#4用户跳出数
./hive -e "CREATE TABLE bbslogs_jumper_${yesterday} AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM bbslogs WHERE logdat
e='${yesterday}' GROUP BY ip HAVING times=1) e;"
# 汇总表
./hive -e "CREATE TABLE bbslogs_${yesterday} AS SELECT '${yesterday}', a.pv, b.reguser, c.ip, d.jumper FROM bbslogs_pv_${yesterday} a JOIN
bbslogs_register_${yesterday} b ON 1=1 JOIN bbslogs_ip_${yesterday} c ON 1=1 JOIN bbslogs_jumper_${yesterday} d ON 1=1;"
#删除表
./hive -e "drop table bbslogs_pv_${yesterday};"
./hive -e "drop table bbslogs_register_${yesterday};"
./hive -e "drop table bbslogs_ip_${yesterday};"
./hive -e "drop table bbslogs_jumper_${yesterday}; "
#5访问页面详细统计
./hive -e "CREATE TABLE bbslogs_detail_${yesterday} AS SELECT logdate,url,COUNT(url) AS count FROM bbslogs WHERE logdate='${yesterday}' GR
OUP BY url,logdate; "
#6每天不同时段pv量
./hive -e "create table bbslogs_day_pv_${yesterday} AS select v.logdate,v.hour,count(*) from (select logdate,substr(atime,9,2) as hour fro
m bbslogs where logdate='${yesterday}') v group by hour,logdate;"可视化展示
